Recognition: 2 theorem links
· Lean TheoremDiscrete Flow Matching for Offline-to-Online Reinforcement Learning
Pith reviewed 2026-05-13 05:41 UTC · model grok-4.3
The pith
A path-space penalty on full trajectories lets discrete RL policies improve online while retaining offline knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
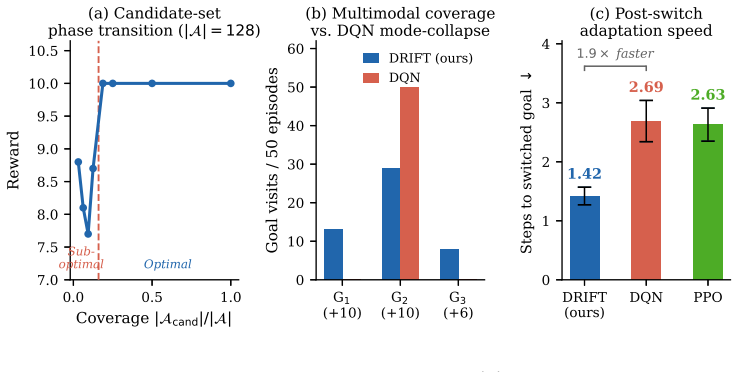
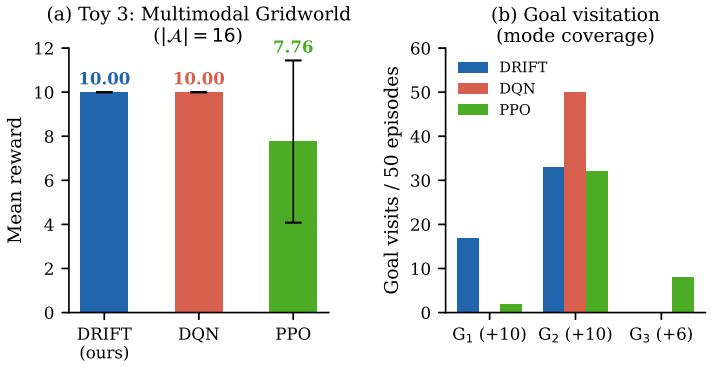
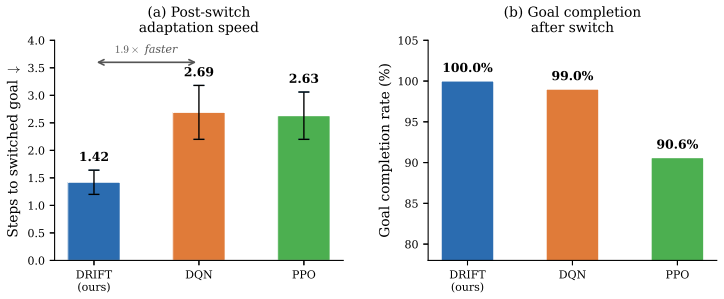
The central discovery is that updating an offline pretrained CTMC policy via advantage-weighted discrete flow matching, combined with a path-space penalty on the full trajectory distribution and a candidate-set approximation for large spaces, enables stable offline-to-online RL. The path-space penalty preserves useful knowledge by acting on the entire distribution rather than final actions alone. Theoretical results establish that candidate-set error is bounded by missing target mass and generator error decreases with increased high-probability coverage. Experiments confirm consistent improvement on discrete RL benchmarks and superior Jericho scores with a simple encoder.
What carries the argument
the path-space penalty that regularizes the full CTMC trajectory distribution to preserve pretrained knowledge during online updates
If this is right
- Stable improvement from offline to online across all tasks tested
- Highest average performance on the Jericho benchmark using a simple GRU encoder
- Outperforms language model based methods on the same tasks
- The path-space penalty stays bounded throughout fine-tuning
- The CTMC generator adapts quicker to reward changes than deterministic alternatives
Where Pith is reading between the lines
- The approach may extend to other discrete control problems where retaining offline behaviors is important during adaptation.
- If candidate coverage is high, the approximation could enable scaling to even larger action spaces with minimal loss in accuracy.
Load-bearing premise
Regularizing the full trajectory distribution via the path-space penalty is enough to prevent loss of useful pretrained behaviors when the policy starts interacting online.
What would settle it
Running the fine-tuning without the path-space penalty and observing degradation in performance on tasks that rely on offline knowledge would falsify the preservation claim; similarly, if generator error fails to decrease with larger candidate sets covering more probability mass.
Figures




read the original abstract
Many reinforcement learning (RL) tasks have discrete action spaces, but most generative policy methods based on diffusion and flow matching are designed for continuous control. Meanwhile, generative policies usually rely heavily on offline datasets and offline-to-online RL is itself challenging, as the policy must improve from new interaction without losing useful behavior learned from static data. To address those challenges, we introduce DRIFT, an online fine-tuning method that updates an offline pretrained continuous-time Markov chain (CTMC) policy with an advantage-weighted discrete flow matching loss. To preserve useful pretrained knowledge, we add a path-space penalty that regularizes the full CTMC trajectory distribution, rather than only the final action distribution. For large discrete action spaces, we introduce a candidate-set approximation that updates the actor over a small subset of actions sampled from reference-policy rollouts and uniform exploration. Our theoretical analysis shows that the candidate-set error is controlled by missing target probability mass, and the induced CTMC generator error decreases as the candidate set covers more high-probability actions. Experiments on prevailing discrete action RL task show that our method provides stable offline-to-online improvement across all tasks, achieving the highest average score on Jericho with a simple GRU encoder while outperforming methods that use pretrained language models. Controlled experiments further confirm that the path-space penalty remains bounded during fine-tuning and that the CTMC generator adapts to shifted rewards faster than deterministic baselines. The candidate-set mechanism is supported by a stability analysis showing that the generator error decreases exponentially with candidate coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DRIFT, a method for offline-to-online RL in discrete action spaces. It pretrains a continuous-time Markov chain (CTMC) policy via discrete flow matching on offline data, then fine-tunes it online using an advantage-weighted discrete flow matching loss. A path-space penalty regularizes the full trajectory distribution to preserve pretrained knowledge, while a candidate-set approximation (sampling from offline rollouts plus uniform exploration) enables scaling to large action spaces. Theoretical analysis claims the candidate-set error is bounded by missing target probability mass and decreases exponentially with coverage of high-probability actions; experiments report stable improvement across tasks, highest average score on Jericho using a simple GRU encoder, and outperformance of pretrained-LM baselines, with controlled experiments confirming bounded path-space penalty and faster adaptation than deterministic baselines.
Significance. If the theoretical error bounds and experimental stability hold under policy shift, the work would provide a principled mechanism for stable fine-tuning of generative discrete policies without catastrophic forgetting of offline behavior. The path-space regularization and candidate-set analysis could influence future discrete-action generative RL methods, particularly in text-based or combinatorial domains where pretrained knowledge is valuable.
major comments (2)
- [Theoretical analysis] Theoretical analysis (as summarized in the abstract and §3): the candidate-set approximation error is claimed to be controlled by missing target probability mass with exponential decrease in generator error as coverage of high-probability actions increases. However, candidates are sampled once from the fixed offline reference policy; the analysis does not address how the bound evolves when online fine-tuning shifts the target distribution and new high-advantage actions appear outside the initial candidate set. This directly affects the stability guarantee for offline-to-online improvement.
- [Experiments] §4 (Experiments): the claim of stable improvement and highest Jericho score is presented without reported tables of per-task returns, variance across seeds, or direct comparison metrics against the pretrained-LM baselines. The controlled experiments on path-space penalty boundedness and faster CTMC adaptation are referenced but lack quantitative details (e.g., penalty values over fine-tuning steps or adaptation speed metrics) needed to verify the supporting claims.
minor comments (2)
- [Method] Notation for the CTMC generator and flow-matching loss should be introduced with explicit equations early in the method section to aid readability.
- [Abstract] The abstract states 'prevailing discrete action RL task' (singular); this should be corrected to 'tasks' for grammatical consistency.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review of our manuscript. The comments highlight important aspects of the theoretical analysis and experimental presentation that we will address in the revision. We respond to each major comment below.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis (as summarized in the abstract and §3): the candidate-set approximation error is claimed to be controlled by missing target probability mass with exponential decrease in generator error as coverage of high-probability actions increases. However, candidates are sampled once from the fixed offline reference policy; the analysis does not address how the bound evolves when online fine-tuning shifts the target distribution and new high-advantage actions appear outside the initial candidate set. This directly affects the stability guarantee for offline-to-online improvement.
Authors: We appreciate this observation regarding the scope of the analysis. Section 3 derives a bound on the candidate-set approximation error for a given target distribution, showing that the error depends on the missing probability mass and that the induced CTMC generator error decreases exponentially with increased coverage of high-probability actions. The analysis is stated for a fixed target, and we agree that it does not explicitly characterize how the bound changes as the target distribution shifts during online fine-tuning or when new high-advantage actions emerge outside the initial candidate set. In the revised manuscript we will add a clarifying paragraph in §3 that states this assumption explicitly and discusses its implications for offline-to-online transfer. We will also include additional empirical results demonstrating that the approximation remains stable in practice as the policy adapts. A complete dynamic analysis of the bound under shifting targets is beyond the current scope and is noted as future work. revision: partial
-
Referee: [Experiments] §4 (Experiments): the claim of stable improvement and highest Jericho score is presented without reported tables of per-task returns, variance across seeds, or direct comparison metrics against the pretrained-LM baselines. The controlled experiments on path-space penalty boundedness and faster CTMC adaptation are referenced but lack quantitative details (e.g., penalty values over fine-tuning steps or adaptation speed metrics) needed to verify the supporting claims.
Authors: We agree that the experimental section would be strengthened by more detailed quantitative reporting. In the revised manuscript we will expand §4 to include tables of per-task returns (means and standard deviations across seeds) together with explicit numerical comparison metrics against the pretrained-LM baselines. For the controlled experiments we will add figures and tables reporting the path-space penalty values at successive fine-tuning steps as well as quantitative adaptation-speed metrics (e.g., steps required to reach performance thresholds). These additions will directly support the claims of stability and faster adaptation. revision: yes
Circularity Check
No circularity: derivation chain remains self-contained
full rationale
The paper derives the candidate-set error bound directly from CTMC generator properties and missing target mass, presented as an independent theoretical result rather than a redefinition of fitted quantities. The path-space penalty is introduced as an explicit regularization on the full trajectory distribution, and the advantage-weighted discrete flow matching loss is a forward update rule. No equation reduces by construction to its own inputs, no prediction is statistically forced by a prior fit, and no load-bearing uniqueness theorem or ansatz is smuggled via self-citation. The offline-to-online stability claims rest on the stated coverage assumption and experimental verification, keeping the chain independent of its outputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOur theoretical analysis shows that the candidate-set error is controlled by missing target probability mass, and the induced CTMC generator error decreases as the candidate set covers more high-probability actions.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearthe path-space KL divergence between path measures Puθ and Puref admits a tractable decomposition via the Radon–Nikodym derivative
Reference graph
Works this paper leans on
-
[1]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Advances in Neural Information Processing Systems , volume=
Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Conference on Robot Learning , pages=
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble , author=. Conference on Robot Learning , pages=. 2022 , organization=
work page 2022
-
[4]
The Eleventh International Conference on Learning Representations , year=
Diffusion Policies as an Expressive Policy Class for Offline Reinforcement Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[5]
The Thirteenth International Conference on Learning Representations , year=
Energy-Weighted Flow Matching for Offline Reinforcement Learning , author=. The Thirteenth International Conference on Learning Representations , year=
-
[6]
arXiv preprint arXiv:2602.06138 , year=
Flow Matching for Offline Reinforcement Learning with Discrete Actions , author=. arXiv preprint arXiv:2602.06138 , year=
work page internal anchor Pith review arXiv
-
[7]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[8]
arXiv preprint arXiv:2507.21053 , year=
Flow matching policy gradients , author=. arXiv preprint arXiv:2507.21053 , year=
-
[9]
Proceedings of the AAAI conference on artificial intelligence , volume=
Adaptive policy learning for offline-to-online reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[10]
International Conference on Machine Learning , pages=
Generative Flows on Discrete State-Spaces: Enabling Multimodal Flows with Applications to Protein Co-Design , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[11]
Advances in Neural Information Processing Systems , volume=
Discrete flow matching , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
The Thirteenth International Conference on Learning Representations , year=
Generator Matching: Generative modeling with arbitrary Markov processes , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
Flow matching guide and code , author=. arXiv preprint arXiv:2412.06264 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
-
[15]
Playing Atari with Deep Reinforcement Learning
Playing atari with deep reinforcement learning , author=. arXiv preprint arXiv:1312.5602 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning with double q-learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
Proceedings of the AAAI conference on artificial intelligence , volume=
Rainbow: Combining improvements in deep reinforcement learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[18]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
International conference on machine learning , pages=
Asynchronous methods for deep reinforcement learning , author=. International conference on machine learning , pages=. 2016 , organization=
work page 2016
-
[20]
International Conference on Learning Representations , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations , year=
-
[21]
Advances in neural information processing systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[22]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Awac: Accelerating online reinforcement learning with offline datasets , author=. arXiv preprint arXiv:2006.09359 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[23]
The Thirteenth International Conference on Learning Representations , year=
Fine-Tuning Discrete Diffusion Models via Reward Optimization with Applications to DNA and Protein Design , author=. The Thirteenth International Conference on Learning Representations , year=
-
[24]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Idql: Implicit q-learning as an actor-critic method with diffusion policies , author=. arXiv preprint arXiv:2304.10573 , year=
work page internal anchor Pith review arXiv
-
[25]
International Conference on Machine Learning , year=
Flow Q-Learning , author=. International Conference on Machine Learning , year=
-
[26]
The Eleventh International Conference on Learning Representations , year=
Policy Expansion for Bridging Offline-to-Online Reinforcement Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
State Proficiency-Based Adaptive Fine-Tuning for Offline-to-Online Reinforcement Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[28]
Journal of artificial intelligence research , volume=
The arcade learning environment: An evaluation platform for general agents , author=. Journal of artificial intelligence research , volume=
-
[29]
arXiv preprint arXiv:1903.03176 , year=
Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments , author=. arXiv preprint arXiv:1903.03176 , year=
-
[30]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
D4rl: Datasets for deep data-driven reinforcement learning , author=. arXiv preprint arXiv:2004.07219 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
- [31]
-
[32]
2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
MuJoCo: A physics engine for model-based control , author=. 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=. 2012 , organization=
work page 2012
- [33]
-
[34]
Scaling limits of interacting particle systems , author=. 2013 , publisher=
work page 2013
-
[35]
Fine-Tuning Language Models from Human Preferences
Fine-tuning language models from human preferences , author=. arXiv preprint arXiv:1909.08593 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[36]
Advances in Neural Information Processing Systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
International conference on machine learning , pages=
Trust region policy optimization , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
- [38]
-
[39]
The Eleventh International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[40]
arXiv preprint arXiv:2209.14577 , year=
Rectified flow: A marginal preserving approach to optimal transport , author=. arXiv preprint arXiv:2209.14577 , year=
-
[41]
Advances in Neural Information Processing Systems , volume=
Denoising Diffusion Probabilistic Models , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
The Eleventh International Conference on Learning Representations , year=
Offline Reinforcement Learning via High-Fidelity Generative Behavior Modeling , author=. The Eleventh International Conference on Learning Representations , year=
-
[43]
Advances in Neural Information Processing Systems , volume=
Efficient diffusion policies for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
International Conference on Machine Learning , pages=
Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[45]
Guided flows for generative modeling and decision making.arXiv preprint arXiv:2311.13443, 2023
Guided flows for generative modeling and decision making , author=. arXiv preprint arXiv:2311.13443 , year=
-
[46]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[47]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
The Thirteenth International Conference on Learning Representations , year=
OGBench: Benchmarking Offline Goal-Conditioned RL , author=. The Thirteenth International Conference on Learning Representations , year=
-
[49]
Advances in neural information processing systems , volume=
Decision transformer: Reinforcement learning via sequence modeling , author=. Advances in neural information processing systems , volume=
-
[50]
international conference on machine learning , pages=
Online decision transformer , author=. international conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[51]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[52]
International conference on machine learning , pages=
Addressing function approximation error in actor-critic methods , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[53]
International Conference on Machine Learning , pages=
Offline-to-Online Reinforcement Learning with Classifier-Free Diffusion Generation , author=. International Conference on Machine Learning , pages=. 2025 , organization=
work page 2025
-
[54]
Advances in neural information processing systems , volume=
Linearly-solvable Markov decision problems , author=. Advances in neural information processing systems , volume=
-
[55]
International conference on machine learning , pages=
Reinforcement learning with deep energy-based policies , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[56]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Relative entropy policy search , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
- [57]
-
[58]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Interactive fiction games: A colossal adventure , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[59]
Deep reinforcement learning with a natural language action space , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[60]
Keep calm and explore: Language models for action generation in text-based games , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
work page 2020
-
[61]
International Conference on Learning Representations , year=
Graph Constrained Reinforcement Learning for Natural Language Action Spaces , author=. International Conference on Learning Representations , year=
-
[62]
International Conference on Learning Representations , year=
Multi-Stage Episodic Control for Strategic Exploration in Text Games , author=. International Conference on Learning Representations , year=
-
[63]
Self-imitation learning for action generation in text-based games , author=. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages=
-
[64]
International Conference on Learning Representations , year=
Score-Based Generative Modeling through Stochastic Differential Equations , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.