Recognition: 2 theorem links
· Lean TheoremQuestion Difficulty Estimation for Large Language Models via Answer Plausibility Scoring
Pith reviewed 2026-05-13 05:24 UTC · model grok-4.3
The pith
Entropy of plausibility scores over candidate answers estimates question difficulty for large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Q-DAPS estimates difficulty by computing the entropy of plausibility scores assigned to a set of candidate answers for each question. Greater entropy signals higher difficulty because the model treats multiple answers as comparably plausible, indicating deeper reasoning challenges. This measure outperforms prior baselines on four QA datasets, holds steady across hyperparameter and model variations, and matches human assessments of difficulty.
What carries the argument
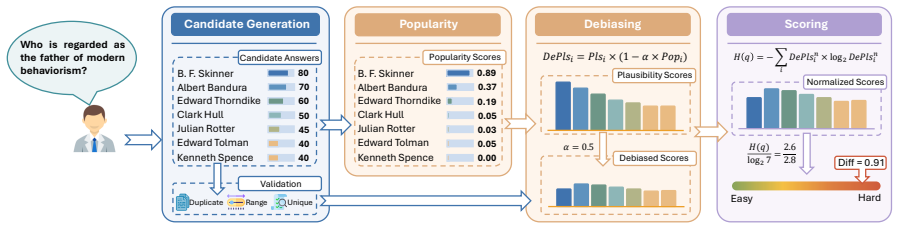
Q-DAPS, which derives a difficulty score directly from the entropy of the distribution of plausibility scores over candidate answers.
If this is right
- Q-DAPS outperforms existing baselines on TriviaQA, NQ, MuSiQue, and QASC.
- The method remains robust across hyperparameter changes, question types, model sizes, and plausibility estimation approaches.
- Q-DAPS difficulty estimates align closely with human judgments.
- Ablation studies confirm reliability in realistic evaluation settings.
Where Pith is reading between the lines
- The approach could support curriculum construction by ranking questions according to model-specific difficulty.
- It offers a route to diagnose which reasoning patterns cause models to assign similar plausibility to several answers.
- Scalability allows difficulty labeling of very large question collections without additional human annotation.
Load-bearing premise
The entropy of plausibility scores over candidate answers captures the reasoning challenges posed to LLMs rather than merely reflecting surface-level answer distributions or calibration artifacts.
What would settle it
A large-scale test in which Q-DAPS scores fail to predict actual LLM accuracy rates on held-out questions or diverge from human difficulty ratings on a new dataset would falsify the central claim.
Figures











read the original abstract
Estimating question difficulty is a critical component in evaluating and improving large language models (LLMs) for question answering (QA). Existing approaches often rely on readability formulas, retrieval-based signals, or popularity statistics, which may not fully capture the reasoning challenges posed to modern LLMs. In this paper, we introduce Q-DAPS (Question Difficulty based on Answer Plausibility Scores) method, a novel approach that estimates question difficulty by computing the entropy of plausibility scores over candidate answers. We systematically evaluate Q-DAPS across four prominent QA datasets-TriviaQA, NQ, MuSiQue, and QASC-demonstrating that it consistently outperforms baselines. Moreover, Q-DAPS shows strong robustness across hyperparameter variations and question types. Extensive ablation studies further show that Q-DAPS remains robust across different plausibility estimation paradigms, model sizes, and realistic settings. Human evaluations further confirm strong alignment between Q-DAPS's difficulty estimates and human judgments of question difficulty. Overall, Q-DAPS provides an interpretable, scalable, and bias-resilient approach to question difficulty estimation in modern QA systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Q-DAPS, a method for estimating question difficulty for LLMs in QA by computing the entropy of plausibility scores over candidate answers. It evaluates the approach on four datasets (TriviaQA, NQ, MuSiQue, QASC), claiming consistent outperformance over baselines, robustness across hyperparameters, question types, plausibility paradigms, and model sizes, plus alignment with human difficulty judgments. The method is positioned as more interpretable and bias-resilient than readability formulas, retrieval signals, or popularity statistics.
Significance. If the empirical results hold with proper controls and quantitative detail, Q-DAPS could offer a scalable way to assess LLM-specific reasoning load in QA, aiding dataset curation and model evaluation beyond surface features. The claimed robustness and human alignment would add practical value, but the absence of metrics, error bars, or baseline specifications in the provided abstract makes it impossible to gauge the contribution's strength at present.
major comments (2)
- [Abstract] Abstract: the central claims of 'consistent outperformance' and 'strong robustness' are asserted without any quantitative results, error bars, baseline implementation details, or statistical tests. This omission is load-bearing because it prevents verification of whether Q-DAPS actually improves on existing methods or merely reflects post-hoc choices.
- [Method] Method (entropy of plausibility scores): the assumption that this entropy isolates reasoning challenges posed to LLMs is not secured against confounds such as model calibration artifacts, training-data answer frequency, or lexical cues in the candidate sets. Without explicit controls or ablations separating these factors, the difficulty estimates risk capturing surface distributions rather than multi-step reasoning load, undermining the core claim.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., average improvement or correlation coefficient) to support the performance claims.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'consistent outperformance' and 'strong robustness' are asserted without any quantitative results, error bars, baseline implementation details, or statistical tests. This omission is load-bearing because it prevents verification of whether Q-DAPS actually improves on existing methods or merely reflects post-hoc choices.
Authors: We agree that the abstract would be strengthened by including key quantitative highlights. The full manuscript reports specific performance gains (e.g., entropy-based difficulty estimates outperforming readability, retrieval, and popularity baselines on TriviaQA, NQ, MuSiQue, and QASC), along with robustness checks across hyperparameters, question types, plausibility paradigms, and model sizes, plus human alignment results and statistical comparisons. We will revise the abstract to incorporate representative quantitative results, references to the experimental sections, and notes on the evaluation protocol. revision: yes
-
Referee: [Method] Method (entropy of plausibility scores): the assumption that this entropy isolates reasoning challenges posed to LLMs is not secured against confounds such as model calibration artifacts, training-data answer frequency, or lexical cues in the candidate sets. Without explicit controls or ablations separating these factors, the difficulty estimates risk capturing surface distributions rather than multi-step reasoning load, undermining the core claim.
Authors: We appreciate this concern about potential confounds. The manuscript already contains extensive ablations showing that Q-DAPS remains stable across multiple plausibility estimation paradigms, model sizes, and realistic settings, which partially addresses calibration and lexical issues by demonstrating consistency beyond single-model artifacts. Evaluations on four diverse datasets further reduce the risk of dataset-specific frequency biases. That said, we will add an explicit discussion subsection on these confounds, including any additional correlation analyses with answer frequency and lexical features, and note limitations where direct isolation is not feasible. revision: partial
Circularity Check
No circularity: Q-DAPS is a direct definition evaluated empirically
full rationale
The paper defines question difficulty directly as the entropy of plausibility scores over candidate answers and then reports empirical performance on four fixed QA datasets against baselines, plus robustness checks and human alignment. No step claims a derivation, prediction, or uniqueness result that reduces by construction to a fitted parameter, self-citation chain, or renamed input; the central quantity is introduced as a new signal rather than recovered from the evaluation data or prior author work. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Plausibility scores computed by LLMs reflect the reasoning challenges of a question
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearQ-DAPS estimates question difficulty by computing the entropy of plausibility scores over candidate answers... H(q) = −∑ DePls_norm_i × log2 DePls_norm_i ... Diff_q = H(q) / log2 N
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and J-cost orbit unclearWe hypothesize that the entropy of normalized plausibility scores provides an effective signal for estimating question difficulty.
Reference graph
Works this paper leans on
-
[1]
Measuring retrieval complexity in question answering systems. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14636–14650, Bangkok, Thailand. Association for Computational Linguistics. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelte...
work page 2024
-
[2]
How knowledge popularity influences and enhances llm knowledge boundary perception. OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Ale- man, Diogo Almeida, Janko Altenschmidt, Sam Alt- man, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haim- ing Bao, and Others. 20...
work page 2024
-
[3]
Qwen2.5 technical report. Vatsal Raina and Mark Gales. 2024. Question difficulty ranking for multiple-choice reading comprehension. Vatsal Raina, Adian Liusie, and Mark Gales. 2023. As- sessing distractors in multiple-choice tests. InPro- ceedings of the 4th Workshop on Evaluation and Com- parison of NLP Systems, pages 12–22, Bali, Indone- sia. Associatio...
work page 2024
-
[4]
Applications of entropy in data analysis and machine learning: A review.Entropy, 26(12). C. E. Shannon. 1948. A mathematical theory of commu- nication.Bell System Technical Journal, 27(3):379– 423. C. Spearman. 1904. The proof and measurement of as- sociation between two things.The American Journal of Psychology, 15(1):72–101. Shuchang Tao, Liuyi Yao, Han...
work page 1948
-
[5]
Gemma 3 technical report. Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhu- patiraju, Léonard Hussenot, Thomas Mesnard, and Others. 2024. Gemma 2: Improving open language models at a practical size. Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher...
work page 2024
-
[6]
or to request clarification (Chi et al., 2024). Finally,Difficultymeasures how challenging a question is to answer, ranging from straightforward fact-based queries (Padó, 2017) to complex reason- ing problems (Xu et al., 2024). A.1 Difficulty Question difficulty can be assessed from differ- ent perspectives. One common perspective fo- cuses onreadability....
work page 2024
-
[7]
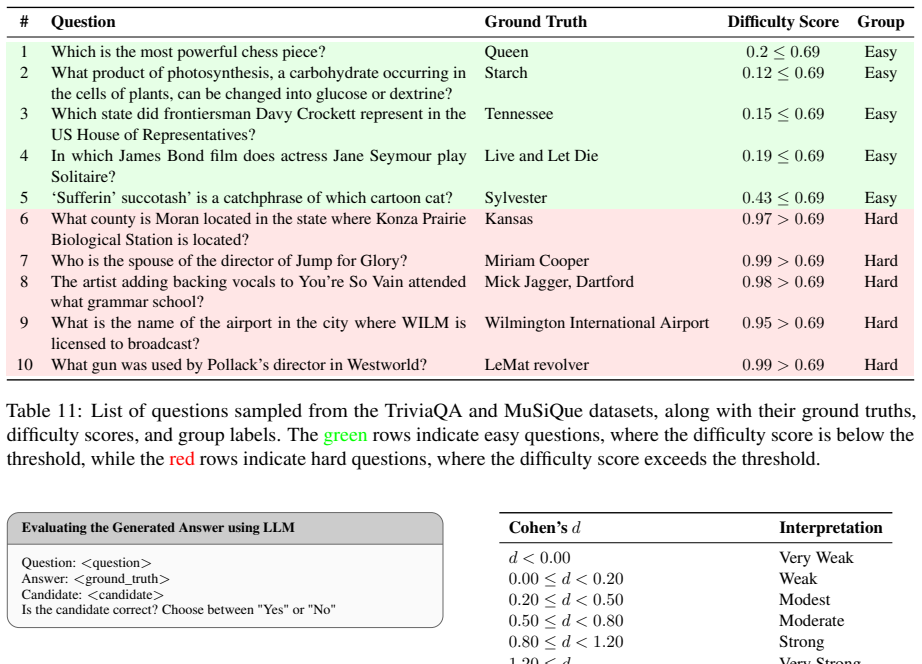
As shown in Table 8, there are no duplicate answers
No Duplicates:We compare the generated candidate answers using a semantic equality function. As shown in Table 8, there are no duplicate answers
-
[8]
Table 8 confirms this con- dition is satisfied
Range of Plausibility Scores:We verify that all plausibility scores fall within the valid range of 0 to 100. Table 8 confirms this con- dition is satisfied
-
[9]
Table 8 confirms this requirement is met
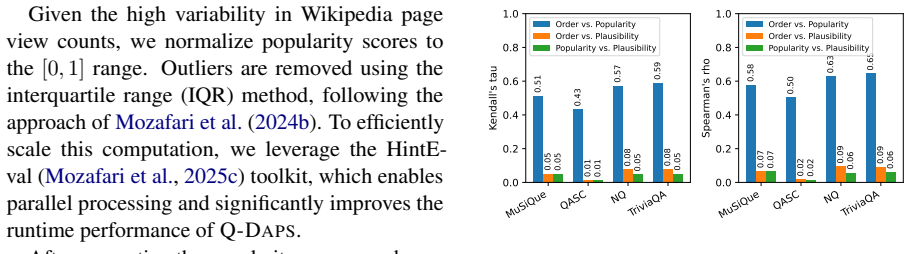
Number of Candidate Answers:We check that the LLM produced exactly 20 candidate answers as requested. Table 8 confirms this requirement is met. B.2 Popularity Debiasing In this stage, we employ the HintEval toolkit (Mozafari et al., 2025c) to compute the popularity 8 of each candidate answer. The Popularitycomponent retrieves the popularity scores from Wi...
work page 1948
-
[10]
is a compact yet capable model optimized for fast inference and moderate computational ef- ficiency.Gemma 3 4B(Team et al., 2025) is a lightweight transformer model designed for effi- cient language processing while maintaining com- petitive performance on standard NLP benchmarks. Medium LMsMistral 7B(Jiang et al., 2023) is a high-performance, decoder-onl...
work page 2025
-
[11]
is an improved version of LLaMA designed for enhanced reasoning and generalization in lan- guage tasks. Large LMsMistral 24B(Jiang et al., 2023) is a larger variant designed for high-capacity reason- ing and advanced generative performance, with a strong ability to follow complex instructions. Gemma 2 27B(Team et al., 2024) is a mid-scale model offering a...
work page 2023
-
[13]
A detailed explanation of the reasoning behind the plausibility score. Format your response as a JSON object, where the candidate is represented as: [ { "Candidate Answer": "<candidate_answer>", "PlausibilityScore": <plausibility_score>, "Justification": "<justification>" } ] The output must be a valid JSON object only. Figure 10: The placeholder <questio...
work page 1952
-
[14]
A non-zero plausibility score as a number between 0 and 100
-
[15]
A detailed explanation of the reasoning behind the plausibility score. Format your response as a JSON list, where each candidate is represented as: [ { "Candidate Answer": "<candidate_answer>", "PlausibilityScore": <plausibility_score>, "Justification": "<justification>" } ] The output must be a valid JSON list only. Figure 16: The placeholder <question> ...
work page 2024
-
[16]
We use our standard prompt for generating candidate answers and plausibility scores, as 10We use 10 candidates for clearer visualization and analy- sis compared to all 20. shown in Figure 3. This prompt explicitly instructs the LLM not to include the correct answer as a candidate, while still providing it in the prompt to guide plausibility estimates
-
[17]
The modified prompt used for this setting is shown in Figure 16
We modify the prompt to remove the instruc- tion excluding the correct answer, allowing the LLM to rely on its knowledge to iden- tify and potentially include the correct answer among the candidates. The modified prompt used for this setting is shown in Figure 16. To ensure consistency and reproducibility, we set the temperature to zero in both scenarios,...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.