Recognition: no theorem link
Model-based Bootstrap of Controlled Markov Chains
Pith reviewed 2026-05-13 03:12 UTC · model grok-4.3
The pith
A model-based bootstrap for transition kernels yields asymptotically valid confidence intervals for value and Q-functions in offline RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a model-based bootstrap for transition kernels in finite controlled Markov chains with possibly nonstationary or history-dependent control policies. Distributional consistency of the bootstrap transition estimator is established in both the single long-chain regime and the episodic offline RL regime through a novel bootstrap law of large numbers for visitation counts together with a martingale central limit theorem for bootstrap transition increments. The consistency is extended to offline policy evaluation and optimal policy recovery by the delta method after verifying Hadamard differentiability of the Bellman operators, thereby producing asymptotically valid confidence intervals
What carries the argument
The bootstrap transition estimator obtained by resampling visitation counts according to the empirical measure of a controlled Markov chain, together with the martingale central limit theorem applied to its increments.
If this is right
- The bootstrap transition estimator is distributionally consistent in both long single trajectories and episodic offline data.
- Asymptotically valid confidence intervals for value functions and Q-functions follow from the delta method once Bellman operators are shown to be Hadamard differentiable.
- Percentile intervals produced by the procedure achieve closer-to-nominal coverage than plug-in CLT or episodic bootstrap alternatives at small sample sizes.
- The method applies directly to offline policy evaluation and optimal policy recovery when the behavior policy is unknown.
Where Pith is reading between the lines
- The same resampling construction may be usable for uncertainty quantification in model-based planning algorithms beyond pure evaluation.
- Extensions to approximate dynamic programming or function approximation would require analogous differentiability arguments for the approximate Bellman operators.
- The approach offers a concrete way to import classical bootstrap theory into dependent-data settings that arise in sequential decision problems.
- Calibration checks on additional finite-state benchmarks could reveal the practical sample-size threshold at which the asymptotic guarantees become reliable.
Load-bearing premise
The novel bootstrap law of large numbers for visitation counts and the martingale central limit theorem for bootstrap increments continue to hold for finite controlled Markov chains under possibly nonstationary or history-dependent policies.
What would settle it
An experiment on RiverSwim or an analogous finite CMC in which the empirical coverage of the bootstrap percentile intervals deviates substantially from the nominal 95 percent level at sample sizes where the asymptotic regime should already be active.
Figures



read the original abstract
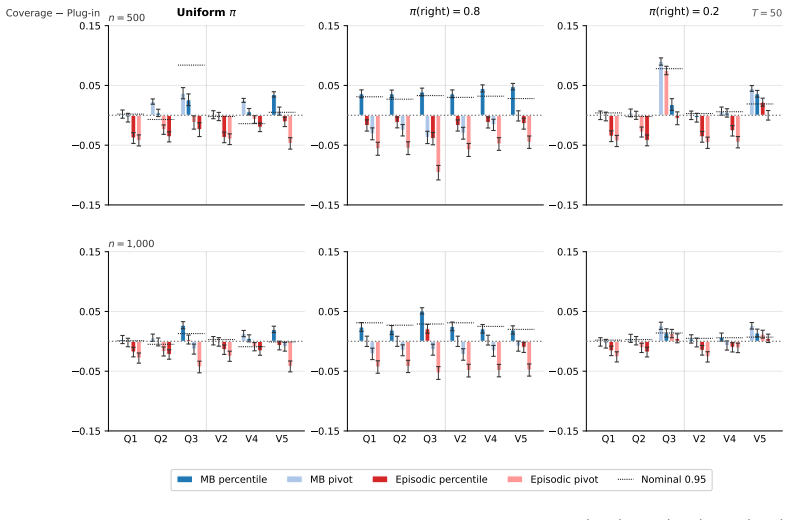
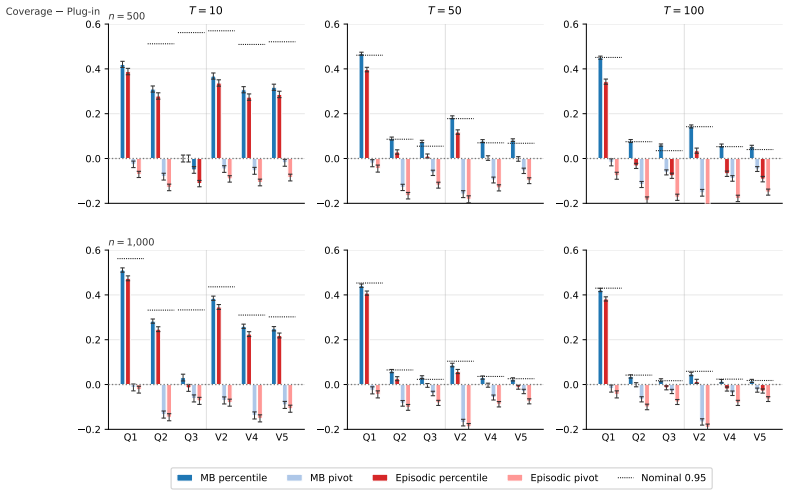
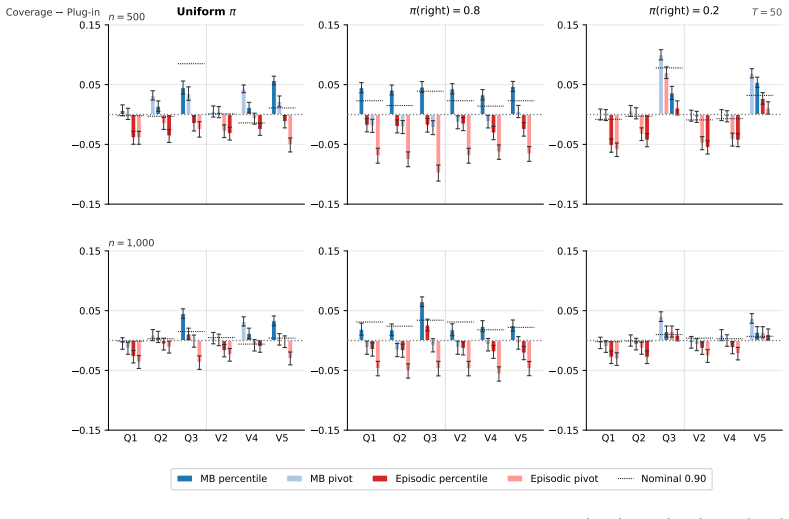
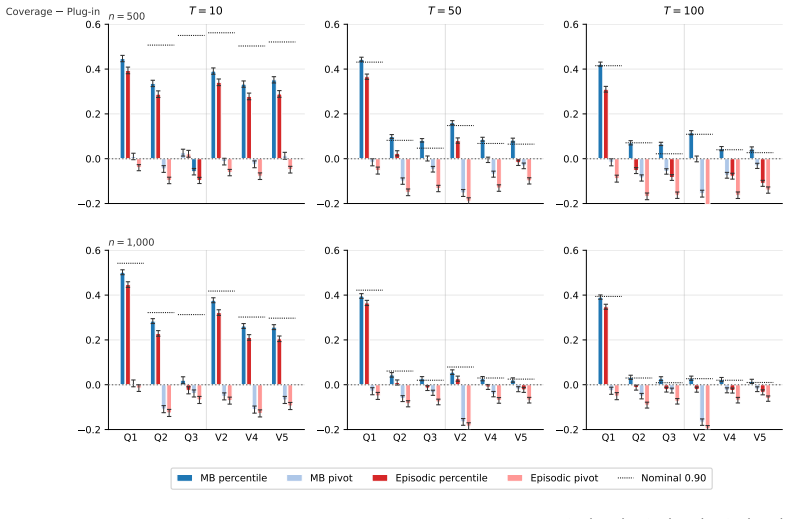
We propose and analyze a model-based bootstrap for transition kernels in finite controlled Markov chains (CMCs) with possibly nonstationary or history-dependent control policies, a setting that arises naturally in offline reinforcement learning (RL) when the behavior policy generating the data is unknown. We establish distributional consistency of the bootstrap transition estimator in both a single long-chain regime and the episodic offline RL regime. The key technical tools are a novel bootstrap law of large numbers (LLN) for the visitation counts and a novel use of the martingale central limit theorem (CLT) for the bootstrap transition increments. We extend bootstrap distributional consistency to the downstream targets of offline policy evaluation (OPE) and optimal policy recovery (OPR) via the delta method by verifying Hadamard differentiability of the Bellman operators, yielding asymptotically valid confidence intervals for value and $Q$-functions. Experiments on the RiverSwim problem show that the proposed bootstrap confidence intervals (CIs), especially the percentile CIs, outperform the episodic bootstrap and plug-in CLT CIs, and are often close to nominal ($50\%$, $90\%$, $95\%$) coverage, while the baselines are poorly calibrated at small sample sizes and short episode lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a model-based bootstrap for transition kernels in finite controlled Markov chains (CMCs) under possibly nonstationary or history-dependent policies. It establishes distributional consistency of the bootstrap estimator in single long-chain and episodic offline RL regimes via a novel bootstrap LLN for visitation counts and martingale CLT for increments. Consistency is extended to offline policy evaluation (OPE) and optimal policy recovery (OPR) using the delta method after verifying Hadamard differentiability of the Bellman operators, yielding asymptotically valid CIs for value and Q-functions. Experiments on RiverSwim show the percentile bootstrap CIs achieve near-nominal coverage and outperform episodic bootstrap and plug-in CLT baselines at small samples.
Significance. If the central claims hold, the work offers a practical advance for uncertainty quantification in offline RL with unknown behavior policies by delivering asymptotically valid CIs without requiring knowledge of the data-generating policy. The novel bootstrap LLN and martingale CLT application are clear technical strengths, as is the empirical demonstration of improved calibration over baselines. The delta-method extension, if justified, would broaden applicability to policy optimization targets.
major comments (2)
- [delta-method extension to OPR (following the Bellman operator differentiability verification)] The extension to OPR via the delta method relies on Hadamard differentiability of the map from transition kernel P to the optimal value function v*. In finite CMCs, this map fails to be Hadamard differentiable at any P where, for some state, two or more actions attain the same maximal Q-value, because a directional perturbation can switch the argmax and the directional derivative limit does not exist independently of path. The manuscript asserts verification of the required differentiability but supplies no explicit non-degeneracy condition (unique optimal action or strict Q-value inequality) that would restore it. This is load-bearing for the OPR consistency claim in the stated generality of nonstationary/history-dependent policies.
- [Section 3 (bootstrap consistency theorems)] The novel bootstrap LLN for visitation counts and the martingale CLT for bootstrap increments are central to both the long-chain and episodic consistency results, yet the manuscript provides only high-level statements of the conditions under which they hold for history-dependent policies. Without an explicit assumption list or proof sketch that covers the episodic offline RL regime (where episode lengths are short and policies may be nonstationary), the support for the distributional consistency claims cannot be fully assessed.
minor comments (2)
- [Experiments section] The RiverSwim experiments report coverage but omit the number of independent runs and standard errors on the empirical coverage probabilities; adding these would strengthen the comparison to baselines.
- [Preliminaries / bootstrap construction] Notation for the resampling scheme in the model-based bootstrap could be clarified with a short pseudocode box or explicit definition of the bootstrap weights.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and outline targeted revisions to strengthen the presentation and rigor.
read point-by-point responses
-
Referee: [delta-method extension to OPR (following the Bellman operator differentiability verification)] The extension to OPR via the delta method relies on Hadamard differentiability of the map from transition kernel P to the optimal value function v*. In finite CMCs, this map fails to be Hadamard differentiable at any P where, for some state, two or more actions attain the same maximal Q-value, because a directional perturbation can switch the argmax and the directional derivative limit does not exist independently of path. The manuscript asserts verification of the required differentiability but supplies no explicit non-degeneracy condition (unique optimal action or strict Q-value inequality) that would restore it. This is load-bearing for the OPR consistency claim in the stated generality of nonstationary/history-dependent policies.
Authors: We agree that Hadamard differentiability of the map from transition kernel to optimal value function requires a non-degeneracy condition; without it, the directional derivative may fail to exist when argmax switches occur. The manuscript's verification of differentiability for the Bellman operators was performed under the implicit assumption that optimal actions are unique or Q-values are strictly separated at relevant states. To make this explicit and restore the claimed consistency for OPR, we will revise the relevant theorem statements and discussion to include this standard non-degeneracy condition, which is common in the RL literature for such results. revision: yes
-
Referee: [Section 3 (bootstrap consistency theorems)] The novel bootstrap LLN for visitation counts and the martingale CLT for bootstrap increments are central to both the long-chain and episodic consistency results, yet the manuscript provides only high-level statements of the conditions under which they hold for history-dependent policies. Without an explicit assumption list or proof sketch that covers the episodic offline RL regime (where episode lengths are short and policies may be nonstationary), the support for the distributional consistency claims cannot be fully assessed.
Authors: The bootstrap LLN for visitation counts and martingale CLT for increments are formulated to hold for history-dependent policies in both the single long-chain and episodic regimes. We acknowledge that the high-level presentation in Section 3 may limit full assessment of the episodic case with short episodes. We will add an explicit enumerated list of assumptions in Section 3 and include a concise proof sketch that directly addresses the episodic offline RL setting, covering nonstationary policies and finite episode lengths. revision: yes
Circularity Check
No circularity; standard probabilistic tools applied to new setting
full rationale
The derivation chain begins with a model-based bootstrap for transition kernels in finite CMCs, establishes distributional consistency via a bootstrap LLN for visitation counts and martingale CLT for increments (both presented as novel applications rather than reductions), and extends to OPE/OPR targets using the delta method after claiming verification of Hadamard differentiability of Bellman operators. No quoted step reduces by construction to a fitted input, self-definition, or self-citation chain; the differentiability verification is asserted as an independent technical check rather than an ansatz or imported uniqueness result. The work remains self-contained against external benchmarks (bootstrap theory, martingale CLT, delta method) without renaming known results or smuggling assumptions via prior self-citations.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption The controlled Markov chain has finite state and action spaces.
- ad hoc to paper The bootstrap law of large numbers holds for visitation counts under the resampling scheme.
- domain assumption Hadamard differentiability of the Bellman operators holds.
Reference graph
Works this paper leans on
-
[1]
M. K. S. Faradonbeh, A. Tewari, and G. Michailidis. On applications of bootstrap in continuous space reinforcement learning. In2019 IEEE 58th Conference on Decision and Control (CDC), pages 1977–1984. IEEE,
work page 1977
-
[2]
I. Kostrikov and O. Nachum. Statistical bootstrapping for uncertainty estimation in off-policy evaluation.arXiv preprint arXiv:2007.13609,
-
[3]
J. Modayil and B. Kuipers. Towards bootstrap learning for object discovery. InAAAI-2004 workshop on anchoring symbols to sensor data,
work page 2004
-
[4]
P. Nakkiran, B. Neyshabur, and H. Sedghi. The deep bootstrap framework: Good online learners are good offline generalizers.arXiv preprint arXiv:2010.08127,
- [5]
-
[6]
11 A Sufficient Conditions for Assumption 2 Assumption 2 requires a uniform bound on the cumulative weak ¯η-mixing coefficients of the joint state–action process {(Xi, Ai)}i≥0, which can be difficult to verify directly. Following Su et al. [2026], Banerjee et al. [2025], we give two separate conditions—one for the action process and one for the state proc...
work page 2026
-
[7]
TV . Thus ¯θi,j measures the rate at which the state process forgets its initial state–action pair, extending Dobrushin’s coefficients [Dobrushin, 1956] to the controlled setting. We now impose a summability condition on these coefficients. Assumption 5(Mixing of States).There exists a constantC θ ≥0such that sup i≥1 ∞X j=i+1 ¯θi,j ≤C θ. Neither assumptio...
work page 1956
-
[8]
B Auxiliary Lemmas for Theorem 1 B.1 Consistency of the Empirical Behavior Policy Before we introduce the consistency of the empirical behavior policy, we introduce some requisite notation. We define a stationary behavior policy ¯πb(a|s) :=p (a) s /ps, where ps :=P a′∈A p(a′) s is the sum of the ergodic occupation measure by actions. We now state the cons...
work page 2026
-
[9]
Proof. We proceed in five steps. Let N0 be the (a.s. finite) random index beyond which all the entrywise convergences invoked in Steps 1–4 have taken effect simultaneously; its finiteness follows from the fact that each individual a.s. convergence has a finite threshold, and a finite maximum of a.s.-finite random variables is a.s. finite. All statements b...
work page 2026
-
[10]
Suppose the bound holds for some m≥0 , i.e. ∥δzK ∗mr n −ˆp∗∥TV ≤(1−δ) m. Applying the TV contraction with µ1 =δ zK ∗mr n and µ2 = ˆp∗, and rewritingK ∗(m+1)r n =K ∗mr n K ∗r n , we have δzK ∗(m+1)r n −ˆp∗ TV = (δzK ∗mr n )K ∗r n −ˆp∗K ∗r n TV ≤(1−δ) δzK ∗mr n −ˆp∗ TV ≤(1−δ) m+1, where the second inequality applies the induction hypothesis. Hence for allm≥...
work page 2025
-
[11]
Banerjee et al. [2025, Lemma 3] then implies that Assumption 2 holds for the bootstrap CMC, and∥∆∗ n∥ ≤0+ 2C∗ρ∗ 1−ρ∗ +1 = C ∗ ∆ for alln≥N 0 a.s. This completes the proof. 16 B.4 Continuity of the Stationary Distribution Map Lemma 6(Continuity of the Stationary Distribution Map).On the almost sure event of Lemma 5, ˆp∗(a) s a.s. − − →p(a) s for every(s, a...
work page 2025
-
[12]
Then by Meyer [1980, Theorem 4.1], the limiting probability vector of an ergodic chain is a continuous function of the transition matrix. Since K ∗ n →K entrywise a.s. by Lemma 5 Step 1, we conclude ˆp∗(a) s a.s. − − →p(a) s for every (s, a)∈ S × A. B.5 Bootstrap Visitation Count Law of Large Numbers Lemma 7(Bootstrap Visitation Count LLN).For each(s, a)∈...
work page 1980
-
[13]
under K ∗ n. Then µ∗ n = n−1X i=0 (ν∗ nK ∗i n )(s, a), hence µ∗ n −nˆp∗(a) s = Pn−1 i=0 [(ν∗ nK ∗i n )(s, a)−ˆp∗(a) s ]. By Lemma 5 (Step 4), supz ∥K ∗i n (z,·)− ˆp∗∥TV ≤C ∗ρi ∗ for alln≥N 0 a.s. Sinceν ∗ n is a probability measure, ∥ν∗ nK ∗i n −ˆp∗∥TV ≤ X z ν∗ n(z) K ∗i n (z,·)−ˆp ∗ TV ≤C ∗ρi ∗. Therefore, for alln≥N 0 a.s., µ∗ n −nˆp∗(a) s ≤ ∞X i=0 C∗ρi...
work page 2025
-
[14]
We now derive the asymptotic variance of S∗,sat n by analyzing the predictable quadratic variationPn−1 i=0 E[(d∗,sat n,i+1)2 | F n,i]. Using E[(ξ∗ i )2 | F n,i] =1{X ∗ i =s, A ∗ i =a} ˆM(a) s,t (1− ˆM(a) s,t ), 19 we have E (d∗,sat n,i+1)2 | F n,i = 1{X ∗ i =s, A ∗ i =a} n(p (a) s )2 ˆM(a) s,t 1− ˆM(a) s,t . Summing overi= 0, . . . , n−1, we get n−1X i=0 ...
work page 2026
-
[15]
We next compute the predictable quadratic variation. We expand( ˜d∗ n,i+1)2 = P s,a,t usat d∗,sat n,i+1 2 to get E ( ˜d∗ n,i+1)2 | F n,i = X s,a,t X s′,a′,t′ usat us′a′t′ E d∗,sat n,i+1 d∗,s′a′t′ n,i+1 | F n,i . We observe that when(s, a)̸= (s ′, a′), 1{X ∗ i =s, A ∗ i =a} ·1{X ∗ i =s ′, A∗ i =a ′}= 0, since the chain occupies a single state–action pair a...
work page 2000
-
[16]
The proof of Proposition 2 is as follows
The bootstrap delta method [Van der Vaart, 2000, Theorem 23.9] then states: if √n(ˆθ∗ − ˆθ) d − →L conditionally on Dn in probability, and ϕ is Hadamard differentiable at θ tangentially to a subspace D0, then √n(ϕ(ˆθ∗)−ϕ( ˆθ)) d − →ϕ′ θ(L)conditionally onD n in probability. The proof of Proposition 2 is as follows. Proof. OPE targets Vπ and Qπ.We first de...
work page 2000
-
[17]
visited far less frequently than downstream states (near state 1). Moreover, at its left-most state 1, the optimal policy is nearly degenerate, with Q⋆(1,0)≈Q ⋆(1,1) , thus the optimal action is only weakly identifiable. This places the problem near the boundary of optimal policy degeneracy and the transition probabilities for rarely visited state–action ...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.