Recognition: 2 theorem links
· Lean TheoremAligning Flow Map Policies with Optimal Q-Guidance
Pith reviewed 2026-05-13 04:59 UTC · model grok-4.3
The pith
Flow map policies adapt to online RL via a derived closed-form optimal Q-guidance target.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
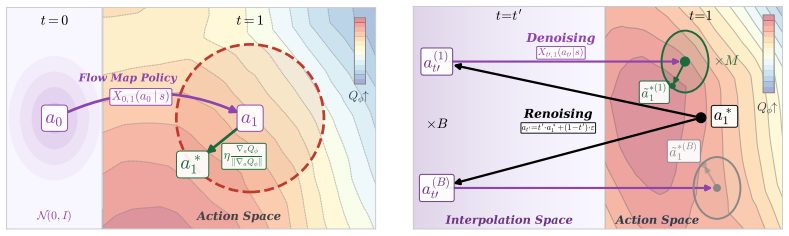
Flow map policies are defined as a class of generative policies that learn to take arbitrary-size jumps, including single-step jumps, across the generative dynamics of flow-based policies. Offline-to-online adaptation is cast as a trust-region optimization problem whose objective is to increase the critic's Q-value subject to a proximity constraint on the policy. Solving this problem yields the closed-form FLOW MAP Q-GUIDANCE (FMQ) target, which the authors prove is optimal for the given constraint. The same framework introduces Q-GUIDED BEAM SEARCH, a stochastic sampler that combines renoising with beam search to refine actions iteratively at test time.
What carries the argument
FLOW MAP Q-GUIDANCE (FMQ), the closed-form optimal learning target obtained by exactly solving the critic-guided trust-region problem that maximizes Q-value improvement while keeping the adapted flow map policy close to its offline predecessor.
Load-bearing premise
The flow dynamics must allow accurate learning of arbitrary-size jumps, and the trust-region problem with Q-value improvement must admit an exact closed-form solution without hidden approximations or data-dependent fitting.
What would settle it
An experiment in which the FMQ target produces no measurable Q-value increase or in which the closed-form expression deviates from the numerically solved optimum under the same trust-region constraint would falsify the central optimality claim.
Figures










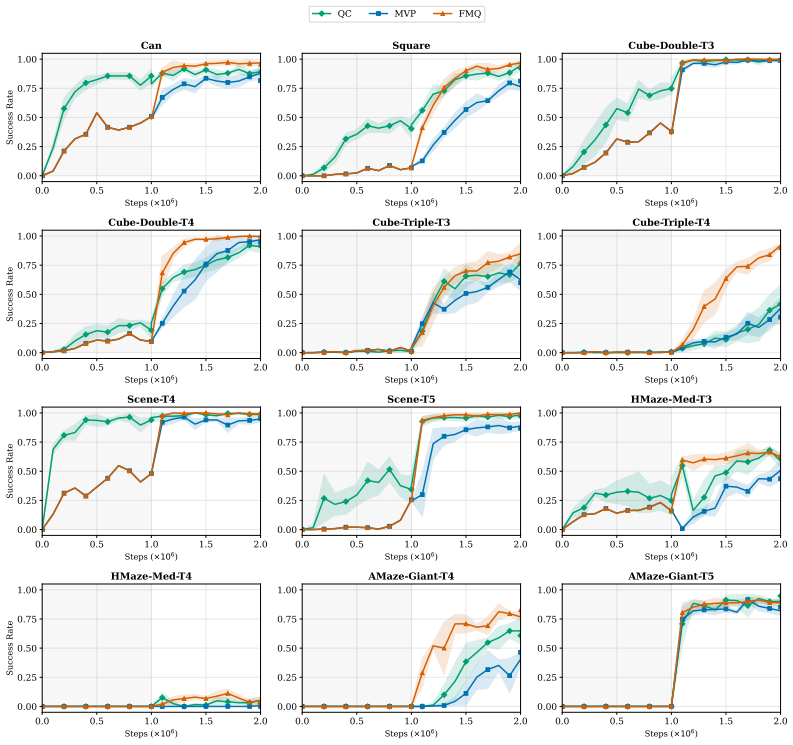

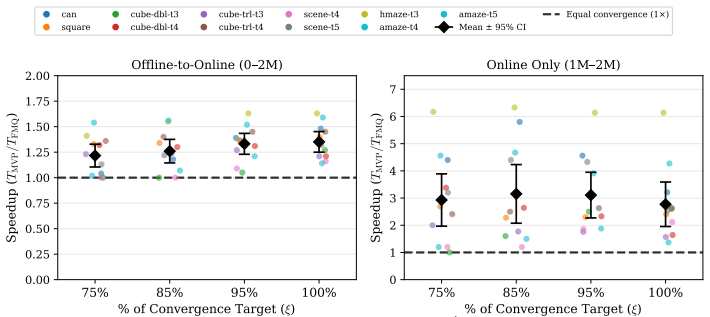
read the original abstract
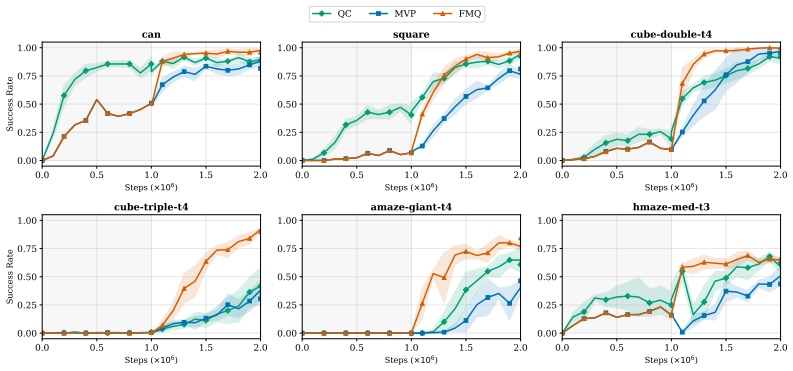
Generative policies based on expressive model classes, such as diffusion and flow matching, are well-suited to complex control problems with highly multimodal action distributions. Their expressivity, however, comes at a significant inference cost: generating each action typically requires simulating many steps of the generative process, compounding latency across sequential decision-making rollouts. We introduce flow map policies, a novel class of generative policies designed for fast action generation by learning to take arbitrary-size jumps including one-step jumps-across the generative dynamics of existing flow-based policies. We instantiate flow map policies for offline-to-online reinforcement learning (RL) and formulate online adaptation as a trust-region optimization problem that improves the critic's Q-value while remaining close to the offline policy. We theoretically derive FLOW MAP Q-GUIDANCE (FMQ), a principled closed-form learning target that is optimal for adapting offline flow map policies under a critic-guided trust-region constraint. We further introduce Q-GUIDED BEAM SEARCH (QGBS), a stochastic flow-map sampler that combines renoising with beam search to enable iterative inference-time refinement. Across 12 challenging robotic manipulation and locomotion tasks from OGBench and RoboMimic, FMQ achieves state-of-the-art performance in offline-to-online RL, outperforming the previous one-step policy MVP by a relative improvement of 21.3% on the average success rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces flow map policies as a novel class of generative policies that learn to perform arbitrary-size jumps (including one-step) across the dynamics of existing flow-based models, enabling fast inference for complex control tasks. For offline-to-online RL, adaptation is cast as a trust-region problem that maximizes critic Q-value improvement while staying close to the offline policy; the authors derive FLOW MAP Q-GUIDANCE (FMQ) as a closed-form optimal learning target for this problem and introduce Q-GUIDED BEAM SEARCH (QGBS) for stochastic inference-time refinement. Experiments across 12 robotic manipulation and locomotion tasks from OGBench and RoboMimic report state-of-the-art results, with a 21.3% relative gain in average success rate over the prior one-step baseline MVP.
Significance. If the closed-form optimality of FMQ holds without hidden approximations, the work offers a principled way to achieve both expressivity and low-latency inference in generative RL policies, directly addressing a key practical bottleneck. The empirical gains on challenging multimodal tasks suggest immediate applicability in robotics. Credit is due for the new policy class and the attempt at an exact trust-region solution, which could influence future work on guided generative models if the derivation is fully substantiated.
major comments (2)
- [§3] §3 (theoretical derivation of FMQ): The central claim that the critic-guided trust-region problem admits an exact closed-form optimal solution for flow-map policies must be supported by explicit equations showing the optimization objective, the trust-region constraint, and the resulting target. It is unclear whether this solution remains exact once the flow map is learned via regression on jump sizes or when expectations over the generative process are involved; any data-dependent fitting or implicit approximation would contradict the 'closed-form' and 'optimal' assertions and undermine the theoretical contribution.
- [§4] §4 (flow map parameterization and dynamics): The assumption that learned flow-map dynamics support accurate arbitrary-size jumps while preserving the exact structure needed for the Q-guidance derivation is load-bearing. If the flow is parameterized such that one-step jumps or the Q-improvement objective require numerical solves or Monte-Carlo estimates, the optimality guarantee does not follow directly from the trust-region formulation.
minor comments (2)
- [Introduction] The abstract and introduction introduce several new acronyms (FMQ, QGBS) and entities without immediate comparison to prior flow-matching or diffusion-policy literature; a short related-work paragraph clarifying distinctions would improve readability.
- [§5] Experimental results report a 21.3% relative improvement but omit variance, number of seeds, or statistical tests; adding these in §5 would strengthen the empirical claims without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting the need for greater clarity on the theoretical foundations of FMQ. We address each major comment below with direct references to the manuscript's derivations and parameterization. We commit to revisions that make the equations and assumptions fully explicit while preserving the exactness of the closed-form result under the stated conditions.
read point-by-point responses
-
Referee: [§3] §3 (theoretical derivation of FMQ): The central claim that the critic-guided trust-region problem admits an exact closed-form optimal solution for flow-map policies must be supported by explicit equations showing the optimization objective, the trust-region constraint, and the resulting target. It is unclear whether this solution remains exact once the flow map is learned via regression on jump sizes or when expectations over the generative process are involved; any data-dependent fitting or implicit approximation would contradict the 'closed-form' and 'optimal' assertions and undermine the theoretical contribution.
Authors: Section 3 formulates the problem as the constrained optimization max_π E_{a ∼ π_θ} [Q(s, a)] subject to D_KL(π_θ || π_off) ≤ ε, where π_θ is the flow-map policy. We solve this exactly by substituting the flow-map jump parameterization into the objective and applying the method of Lagrange multipliers, yielding the closed-form FMQ target that shifts the regression target by a term proportional to ∇_a Q. The derivation is exact with respect to any fixed flow map; the regression step learns an approximation to the map but does not alter the optimality of the target once the map is given. Expectations over the generative process are eliminated analytically because the flow-map structure permits direct evaluation of the jump without sampling. We will revise §3 to include a boxed statement of the objective, constraint, and FMQ solution together with the full derivation steps. revision: partial
-
Referee: [§4] §4 (flow map parameterization and dynamics): The assumption that learned flow-map dynamics support accurate arbitrary-size jumps while preserving the exact structure needed for the Q-guidance derivation is load-bearing. If the flow is parameterized such that one-step jumps or the Q-improvement objective require numerical solves or Monte-Carlo estimates, the optimality guarantee does not follow directly from the trust-region formulation.
Authors: The flow map is parameterized as a direct regressor from (state, jump size, noise) to the jumped state, trained on integrated trajectories from the base flow model; this permits exact one-step evaluation by setting the jump size to the full horizon without any numerical integration or Monte-Carlo sampling at inference or guidance time. The Q-guidance modifies only the regression target in closed form and does not invoke additional solves. The optimality therefore holds exactly for the learned parameterization. We will add a clarifying paragraph and an appendix figure in the revision that explicitly shows the absence of numerical solves in both the one-step jump and the FMQ target computation. revision: partial
Circularity Check
No significant circularity detected in FMQ derivation
full rationale
The paper presents a theoretical derivation of FLOW MAP Q-GUIDANCE (FMQ) as the closed-form solution to a critic-guided trust-region optimization problem over flow-map jumps. This is a standard RL-style derivation where the optimal target is obtained by solving the stated objective (max Q improvement subject to policy closeness) under the given flow dynamics. No equations or steps reduce the claimed optimality to a fitted parameter, self-citation, or input by construction; the result follows from the math of the trust-region problem rather than re-labeling data-dependent fits. The derivation is self-contained against the paper's own assumptions about exact closed-form solvability, warranting a score of 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing flow-based policies admit extension to arbitrary-size jumps that can be learned directly
- ad hoc to paper The critic-guided trust-region problem for policy adaptation possesses a closed-form optimal solution
invented entities (3)
-
Flow map policies
no independent evidence
-
FLOW MAP Q-GUIDANCE (FMQ)
no independent evidence
-
Q-GUIDED BEAM SEARCH (QGBS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearTheorem 3.2 … u^*_{r,1}(a_r|s) = u^{ref}_{r,1}(a_r|s) + η ∇_a Q_ϕ(s,a_1) / ||∇_a Q_ϕ(s,a_1)||_2
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearflow map policy … X_{r,t}(a_r|s) = a_r + (t-r) u_{r,t}(a_r|s)
Reference graph
Works this paper leans on
-
[1]
R. Agarwal, M. Schwarzer, P. S. Castro, A. C. Courville, and M. Bellemare. Deep reinforcement learning at the edge of the statistical precipice.Advances in neural information processing systems, 34:29304–29320, 2021.(Cited on page
work page 2021
-
[2]
URL https://arxiv.org/abs/2303.08797.(Cited on pages 1 and
work page internal anchor Pith review Pith/arXiv arXiv
- [3]
-
[4]
T. Chen, Z. Wang, and M. Zhou. Diffusion policies creating a trust region for offline reinforcement learning.Advances in Neural Information Processing Systems, 37:50098–50125, 2024.(Cited on page
work page 2024
-
[5]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023.(Cited on page
work page 2023
-
[6]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025.(Cited on page
work page 2025
-
[7]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
O.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 1(2), 2023.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Z. Ding and C. Jin. Consistency models as a rich and efficient policy class for reinforcement learning. arXiv preprint arXiv:2309.16984, 2023.(Cited on page
-
[9]
J. Fu, A. Kumar, O. Nachum, G. Tucker, and S. Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[10]
S. Fujimoto and S. S. Gu. A minimalist approach to offline reinforcement learning. InAdvances in Neural Information Processing Systems, volume 34, pages 20132–20145, 2021.(Cited on page
work page 2021
-
[11]
S. Fujimoto, D. Meger, and D. Precup. Off-policy deep reinforcement learning without exploration. InInternational Conference on Machine Learning, pages 2052–2062. PMLR, 2019.(Cited on page
work page 2052
-
[12]
D. Garg, J. Hejna, M. Geist, and S. Ermon. Extreme q-learning: Maxent rl without entropy. In International Conference on Learning Representations, 2023.(Cited on page
work page 2023
-
[13]
URLhttps://arxiv.org/abs/2505.13447.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
P. Hansen-Estruch, I. Kostrikov, M. Janner, J. G. Kuba, and S. Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573, 2023.(Cited on page
work page internal anchor Pith review arXiv 2023
- [15]
-
[16]
Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps
P. Holderrieth, D. Chen, L. Eyring, I. Shah, G. Anantharaman, Y . He, Z. Akata, T. Jaakkola, N. M. Boffi, and M. Simchowitz. Diamond maps: Efficient reward alignment via stochastic flow maps. arXiv preprint arXiv:2602.05993, 2026.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
N. Jaques, A. Ghandeharioun, J. H. Shen, C. Ferguson, A. Lapedriza, N. Jones, S. Gu, and R. Picard. Way off-policy batch deep reinforcement learning of implicit human preferences in dialog.arXiv preprint arXiv:1907.00456, 2019.(Cited on page
-
[18]
G. Kahn, A. Villaflor, P. Abbeel, and S. Levine. Composable action-conditioned predictors: Flexible off-policy learning for robot navigation. InConference on robot learning, pages 806–816. PMLR, 2018.(Cited on page
work page 2018
-
[19]
B. Kang, X. Ma, C. Du, T. Pang, and S. Yan. Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023.(Cited on page
work page 2023
-
[20]
I. Kostrikov, A. Nair, and S. Levine. Offline reinforcement learning with implicit q-learning. In International Conference on Learning Representations, 2022.(Cited on page
work page 2022
-
[21]
A. Kumar. Data-driven deep reinforcement learning.Berkeley Artificial Intelligence Research (BAIR), Tech. Rep, 2019.(Cited on page
work page 2019
- [22]
-
[23]
J. Lee, C. Paduraru, D. J. Mankowitz, N. Heess, D. Precup, K.-E. Kim, and A. Guez. Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble. InConference on Robot Learning, pages 1602–1612. PMLR, 2022.(Cited on page
work page 2022
-
[24]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020.(Cited on pages 1 and
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[25]
Q. Li, Z. Zhou, and S. Levine. Reinforcement learning with action chunking.arXiv preprint arXiv:2507.07969, 2025.(Cited on pages 6, 9, and
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022.(Cited on pages 1 and
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022.(Cited on pages 1 and
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Martín-Martín. What matters in learning from offline human demonstrations for robot manipulation.arXiv preprint arXiv:2108.03298, 2021.(Cited on page
work page internal anchor Pith review arXiv 2021
-
[29]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
A. Nair and M. r. l. w. o. d. Dalal. Accelerating online reinforcement learning with offline datasets. arXiv preprint arXiv:2006.09359, 2020.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[30]
M. Nakamoto, Y . Zhai, A. Singh, M. Radin, A. Kumar, C. Finn, and S. Levine. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning. InAdvances in Neural Information Processing Systems, volume 36, 2023.(Cited on page
work page 2023
-
[31]
T. X. Nguyen and C. D. Yoo. One-step flow q-learning: Addressing the diffusion policy bottleneck in offline reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026.(Cited on page
work page 2026
- [32]
-
[33]
S. Park, Q. Li, and S. Levine. Flow q-learning. InInternational Conference on Machine Learning (ICML), 2025.(Cited on pages 2 and
work page 2025
-
[34]
T. Pearce, T. Rashid, A. Kanervisto, D. Bignell, M. Sun, R. Georgescu, S. V . Macua, S. Z. Tan, I. Mo- mennejad, K. Hofmann, and S. Devlin. Imitating human behaviour with diffusion models.ArXiv, abs/2301.10677,
-
[35]
S. Peluchetti. Non-denoising forward-time diffusions.arXiv preprint arXiv:2312.14589, 2023.(Cited on page
-
[36]
P. Potaptchik, A. Saravanan, A. Mammadov, A. Prat, M. S. Albergo, and Y . W. Teh. Meta flow maps enable scalable reward alignment.arXiv preprint arXiv:2601.14430, 2026.(Cited on page
-
[37]
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015.(Cited on page
work page 2015
-
[38]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[39]
Y . Song, Y . Zhou, A. Sekhari, J. A. Bagnell, A. Krishnamurthy, and W. Sun. Hybrid rl: Using both offline and online data can make rl efficient. InInternational Conference on Learning Representations, 2023.(Cited on page
work page 2023
-
[40]
MIT press Cambridge, 1998.(Cited on page
work page 1998
-
[41]
D. Tarasov, V . Kurenkov, A. Nikulin, and S. Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning.Advances in Neural Information Processing Systems, 36:11592–11620, 2023.(Cited on page
work page 2023
-
[42]
A. Tong, K. Fatras, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, G. Wolf, and Y . Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.arXiv preprint arXiv:2302.00482, 2023.(Cited on page
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [43]
-
[44]
Z. Wang, J. J. Hunt, and M. Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. InInternational Conference on Learning Representations, 2023.(Cited on page
work page 2023
-
[45]
Y . Wu, G. Tucker, and O. Nachum. Behavior regularized offline reinforcement learning.arXiv preprint arXiv:1911.11361, 2019.(Cited on page
work page internal anchor Pith review arXiv 1911
- [46]
-
[47]
T. Yu, G. Thomas, L. Yu, S. Ermon, J. Zou, S. Levine, C. Finn, and T. Ma. Mopo: Model-based offline policy optimization. InAdvances in Neural Information Processing Systems, volume 33, pages 14129–14142, 2020.(Cited on page
work page 2020
-
[48]
G. Zhan, Y . Jiang, S. E. Li, Y . Lyu, X. Zhang, and Y . Yin. A transformation-aggregation frame- work for state representation of autonomous driving systems.IEEE Transactions on Intelligent Transportation Systems, 25(7):7311–7322, 2024.(Cited on page
work page 2024
-
[49]
G. Zhan, X. An, Y . Jiang, J. Duan, H. Zhao, and S. E. Li. Physics informed neural pose estimation for real-time shape reconstruction of soft continuum robots.IEEE Robotics and Automation Letters, 2025.(Cited on page
work page 2025
- [50]
- [51]
- [52]
-
[53]
+λ ∗(u∗ r,1(ar |s)−u ref r,1(ar |s)) = 0(Stationarity) (23) Assuming ∇aQϕ(s, a 1)̸= 0 , stationarity equation 23 requires λ∗ >0 . Complementary slack- ness equation 22 then forces the constraint to be active: ∥u∗ r,1(ar |s)−u ref r,1(ar |s)∥ 2 =η(24) Taking the norm of the stationarity condition gives λ∗η=∥∇ aQϕ(s, a 1)∥2, so λ∗ = ∥∇aQϕ(s, a 1)∥2/η. Subst...
work page 2026
-
[54]
We now leverage and rewrite eq. (30) succinctly: ∇θL(θ) = 2E ∇θuθ r,t(ar |s) T uθ r,t(ar |s)−sg uθ r,t(ar |s) + (t−r) d dr ur,t(ar |s) . This loss gradient matches the Mean Flow Policies’ loss gradient, with the main distinction being the usage of the ground truth velocity v∗ r as opposed to the network’s predictionuθ r,r. Furthermore, the instantaneous v...
work page 2026
-
[55]
NFE =M(1 +KB) , where M is the number of initial candidates, K the number of renoising steps, and B the number of completions per candidate; K=0 reduces to standard best-of- M. The per-environment results confirm that the gains from renoising ( K=1) are consistent across task domains—manipulation, multi-object rearrangement, and locomotion—with the most n...
work page 2018
-
[56]
QC [Li et al., 2025] trains a standard CFM velocity field vθ(at, t|s) with the straight-line interpo- lation objective. At inference, the ODE is integrated from t=0 to t=1 with 10 Euler steps, producing 22 Table 7: Inference procedures. NFE = network forward evaluations per action. Method Action selection StepsNNFE QC Best-of-N(Euler)10 32 320 MVP Best-of...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.