Recognition: 2 theorem links
· Lean TheoremORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging
Pith reviewed 2026-05-13 05:03 UTC · model grok-4.3
The pith
ORBIT preserves foundational language capabilities during generative retrieval fine-tuning by using origin-regulated weight averaging to constrain parameter drift beyond a distance threshold.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
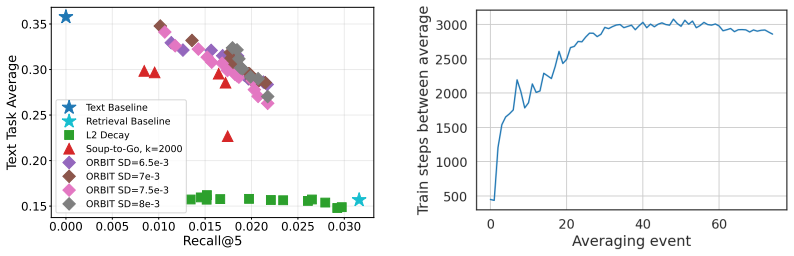
Our results show that ORBIT retains substantial text and retrieval performance by outperforming both common continual learning baselines and related regularization methods that also employ weight averaging.
Load-bearing premise
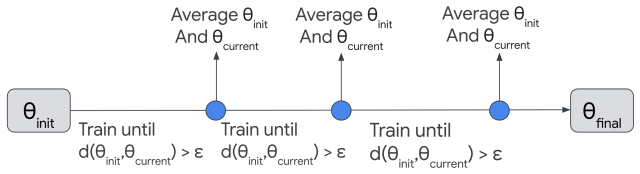
That actively constraining model drift via weight averaging triggered by inter-model distance exceeding a threshold will preserve general language capabilities without substantially harming the fine-tuned generative retrieval performance.
Figures

read the original abstract
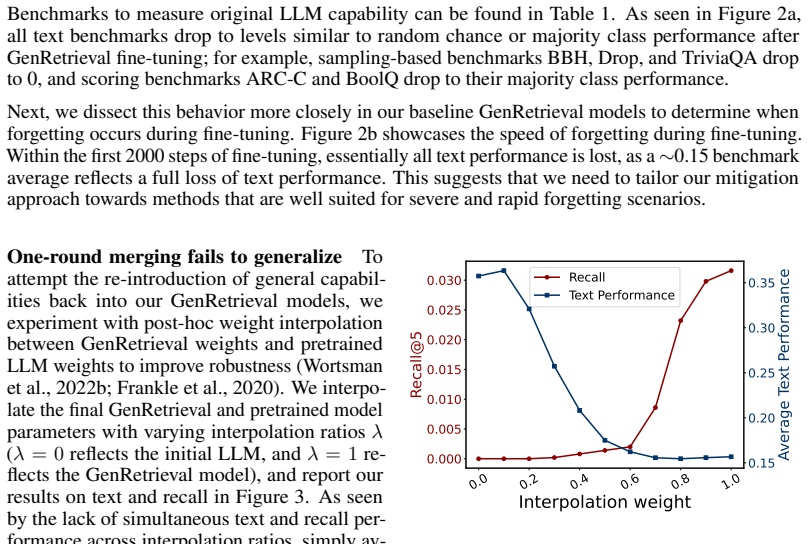
Despite the rapid advancements in large language model (LLM) development, fine-tuning them for specific tasks often results in the catastrophic forgetting of their general, language-based reasoning abilities. This work investigates and addresses this challenge in the context of the Generative Retrieval (GenRetrieval) task. During GenRetrieval fine-tuning, we find this forgetting occurs rapidly and correlates with the distance between the fine-tuned and original model parameters. Given these observations, we propose ORBIT, a novel approach that actively tracks the distance between fine-tuned and initial model weights, and uses a weight averaging strategy to constrain model drift during GenRetrieval fine-tuning when this inter-model distance exceeds a maximum threshold. Our results show that ORBIT retains substantial text and retrieval performance by outperforming both common continual learning baselines and related regularization methods that also employ weight averaging.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper observes that fine-tuning LLMs for Generative Retrieval leads to rapid catastrophic forgetting of general language capabilities, with forgetting correlating to the parameter distance from the original model. It proposes ORBIT, which monitors this inter-model distance and applies weight averaging to pull the fine-tuned model back toward the origin whenever the distance exceeds a tunable threshold, thereby constraining drift during continued training.
Significance. If the empirical results hold, ORBIT offers a lightweight, distance-triggered regularization strategy that preserves foundational capabilities better than standard continual-learning baselines and other weight-averaging regularizers while retaining GenRetrieval performance. The approach is grounded in an observed correlation rather than an ad-hoc assumption, and the dual evaluation on language and retrieval metrics strengthens the practical claim.
minor comments (3)
- The abstract states performance claims without any quantitative numbers, error bars, or dataset details; moving a concise summary of the key metrics (e.g., the reported gains on language and retrieval benchmarks) into the abstract would improve readability.
- The description of the threshold as a 'maximum inter-model distance' leaves the exact distance metric (Euclidean, cosine, etc.) and its normalization unspecified in the high-level overview; a brief clarification in the method section would remove ambiguity.
- No ablation on the sensitivity of the threshold hyper-parameter is mentioned; adding a short sensitivity plot or table would help readers assess robustness without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on ORBIT and for recommending minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity; empirical heuristic with independent validation
full rationale
The manuscript describes an observation (correlation between parameter distance and forgetting) that motivates a practical threshold-based weight-averaging rule. No equations, derivations, or first-principles claims appear; the method is presented as a tunable regularization heuristic whose performance is assessed on separate language and retrieval benchmarks against external baselines. No self-citation chain, fitted-input-as-prediction, or ansatz smuggling is present. The central claim therefore remains an empirical result rather than a reduction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- maximum inter-model distance threshold
axioms (1)
- domain assumption Forgetting of foundational language capabilities correlates with distance between fine-tuned and original model parameters
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwhen this inter-model distance exceeds a maximum threshold... θ∗t+1 = (θ∗t+1 + θinit)/2
-
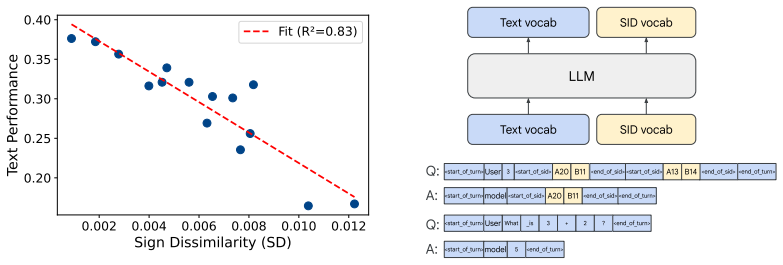
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearSign Dissimilarity (SD) ... fraction of parameters that have undergone a meaningful change
Reference graph
Works this paper leans on
-
[1]
N., Zhang, C., Vechev, M., and Toutanova, K
Alexandrov, A., Raychev, V., M \"u ller, M. N., Zhang, C., Vechev, M., and Toutanova, K. Mitigating catastrophic forgetting in language transfer via model merging. arXiv preprint arXiv:2407.08699, 2024
-
[2]
Dam: Dynamic adapter merging for continual video qa learning
Cheng, F., Wang, Z., Sung, Y.-L., Lin, Y.-B., Bansal, M., and Bertasius, G. Dam: Dynamic adapter merging for continual video qa learning. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp.\ 6805--6817. IEEE, 2025
work page 2025
-
[3]
Dziadzio, S., Udandarao, V., Roth, K., Prabhu, A., Akata, Z., Albanie, S., and Bethge, M. How to merge your multimodal models over time? In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 20479--20491, 2025
work page 2025
-
[4]
Frankle, J., Dziugaite, G. K., Roy, D., and Carbin, M. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pp.\ 3259--3269. PMLR, 2020
work page 2020
-
[5]
Gemma, T., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ram \'e , A., Rivi \`e re, M., et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Knowledge is a region in weight space for fine-tuned language models
Gueta, A., Venezian, E., Raffel, C., Slonim, N., Katz, Y., and Choshen, L. Knowledge is a region in weight space for fine-tuned language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 1350--1370, 2023
work page 2023
-
[7]
He, R. and McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In proceedings of the 25th international conference on world wide web, pp.\ 507--517, 2016
work page 2016
-
[8]
J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[9]
A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114 0 (13): 0 3521--3526, 2017
work page 2017
-
[10]
K., Frankle, J., Kakade, S., and Paul, M
Kleiman, A., Dziugaite, G. K., Frankle, J., Kakade, S., and Paul, M. Soup to go: mitigating forgetting during continual learning with model averaging. arXiv preprint arXiv:2501.05559, 2025
-
[11]
Magmax: Leveraging model merging for seamless continual learning
Marczak, D., Twardowski, B., Trzci \'n ski, T., and Cygert, S. Magmax: Leveraging model merging for seamless continual learning. In European Conference on Computer Vision, pp.\ 379--395. Springer, 2024
work page 2024
-
[12]
E., Roy, S., Tartaglione, E., and Lathuili \`e re, S
Marouf, I. E., Roy, S., Tartaglione, E., and Lathuili \`e re, S. Weighted ensemble models are strong continual learners. In European Conference on Computer Vision, pp.\ 306--324. Springer, 2024
work page 2024
-
[13]
H., Constant, N., Ma, J., Hall, K., Cer, D., and Yang, Y
Ni, J., Abrego, G. H., Constant, N., Ma, J., Hall, K., Cer, D., and Yang, Y. Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. In Findings of the Association for Computational Linguistics: ACL 2022, pp.\ 1864--1874, 2022
work page 2022
-
[14]
Recommender systems with generative retrieval
Rajput, S., Mehta, N., Singh, A., Hulikal Keshavan, R., Vu, T., Heldt, L., Hong, L., Tay, Y., Tran, V., Samost, J., Kula, M., Chi, E., and Sathiamoorthy, M. Recommender systems with generative retrieval. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems, volume 36, pp.\ 1...
work page 2023
-
[15]
Early weight averaging meets high learning rates for llm pre-training
Sanyal, S., Neerkaje, A., Kaddour, J., Kumar, A., and Sanghavi, S. Early weight averaging meets high learning rates for llm pre-training. arXiv preprint arXiv:2306.03241, 2023
-
[16]
K., Arnab, A., Iscen, A., Castro, P
Sokar, G., Dziugaite, G. K., Arnab, A., Iscen, A., Castro, P. S., and Schmid, C. Continual learning in vision-language models via aligned model merging. arXiv preprint arXiv:2506.03189, 2025
-
[17]
Learning to tokenize for generative retrieval
Sun, W., Yan, L., Chen, Z., Wang, S., Zhu, H., Ren, P., Chen, Z., Yin, D., Rijke, M., and Ren, Z. Learning to tokenize for generative retrieval. Advances in Neural Information Processing Systems, 36: 0 46345--46361, 2023
work page 2023
-
[18]
An empirical study of multimodal model merging
Sung, Y.-L., Li, L., Lin, K., Gan, Z., Bansal, M., and Wang, L. An empirical study of multimodal model merging. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp.\ 1563--1575, 2023
work page 2023
-
[19]
Transformer memory as a differentiable search index
Tay, Y., Tran, V., Dehghani, M., Ni, J., Bahri, D., Mehta, H., Qin, Z., Hui, K., Zhao, Z., Gupta, J., et al. Transformer memory as a differentiable search index. Advances in Neural Information Processing Systems, 35: 0 21831--21843, 2022
work page 2022
-
[20]
Lines: Post-training layer scaling prevents forgetting and enhances model merging
Wang, K., Dimitriadis, N., Favero, A., Ortiz-Jimenez, G., Fleuret, F., and Frossard, P. Lines: Post-training layer scaling prevents forgetting and enhances model merging. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=J5sUOvlLbQ
work page 2025
-
[21]
Y., Roelofs, R., Gontijo-Lopes, R., Morcos, A
Wortsman, M., Ilharco, G., Gadre, S. Y., Roelofs, R., Gontijo-Lopes, R., Morcos, A. S., Namkoong, H., Farhadi, A., Carmon, Y., Kornblith, S., et al. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In International conference on machine learning, pp.\ 23965--23998. PMLR, 2022 a
work page 2022
-
[22]
W., Li, M., Kornblith, S., Roelofs, R., Lopes, R
Wortsman, M., Ilharco, G., Kim, J. W., Li, M., Kornblith, S., Roelofs, R., Lopes, R. G., Hajishirzi, H., Farhadi, A., Namkoong, H., et al. Robust fine-tuning of zero-shot models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 7959--7971, 2022 b
work page 2022
-
[23]
Yadav, P., Tam, D., Choshen, L., Raffel, C. A., and Bansal, M. Ties-merging: Resolving interference when merging models. Advances in Neural Information Processing Systems, 36: 0 7093--7115, 2023
work page 2023
-
[24]
Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities
Yang, E., Shen, L., Guo, G., Wang, X., Cao, X., Zhang, J., and Tao, D. Model merging in llms, mllms, and beyond: Methods, theories, applications and opportunities. arXiv preprint arXiv:2408.07666, 2024
-
[25]
Soundstream: An end-to-end neural audio codec
Zeghidour, N., Luebs, A., Omran, A., Skoglund, J., and Tagliasacchi, M. Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30: 0 495--507, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.