Recognition: no theorem link
Formalize, Don't Optimize: The Heuristic Trap in LLM-Generated Combinatorial Solvers
Pith reviewed 2026-05-13 04:56 UTC · model grok-4.3
The pith
LLMs perform better at formalizing combinatorial problems for verified solvers than at optimizing search code themselves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prompting LLMs for search optimization in generated solvers yields small median speed-ups of 1.03-1.12x but a strongly bimodal outcome, with frequent slowdowns and sharp drops in correctness on a long tail of instances, because the models substitute local approximations for complete search in native Python, inject unverified bounds in Python plus OR-Tools, or add redundant declarative machinery in MiniZinc plus OR-Tools.
What carries the argument
The heuristic trap, in which efficiency-oriented prompts cause LLMs to replace complete search procedures with incomplete or incorrect heuristics across the three solver-construction paradigms.
If this is right
- LLM-generated solvers reach higher overall correctness when they target a solver API such as OR-Tools instead of writing native search code.
- Native Python output is the most likely to produce schema-valid but unverified solutions.
- Declarative modeling in MiniZinc yields lower coverage than the Python API despite sharing the same underlying solver.
- Any LLM-authored search optimization must be audited or verified before use to avoid the observed regressions.
Where Pith is reading between the lines
- The same formalize-first pattern may apply to LLM code generation in other domains that require exhaustive search or constraint satisfaction.
- Automated static or dynamic checks for heuristic soundness could be inserted into LLM solver pipelines to catch the trap early.
- Scaling experiments on newer models could test whether the heuristic trap weakens or changes form as base capabilities improve.
Load-bearing premise
The three evaluated paradigms of native Python, Python plus OR-Tools, and MiniZinc plus OR-Tools cover the relevant space of LLM solver generation and the CP-SynC-XL instances are representative enough for the effects to hold more broadly.
What would settle it
An experiment on a fresh collection of combinatorial problems that shows optimization prompts produce consistent speed-ups of 1.5x or more with no measurable drop in correctness would falsify the central claim.
Figures
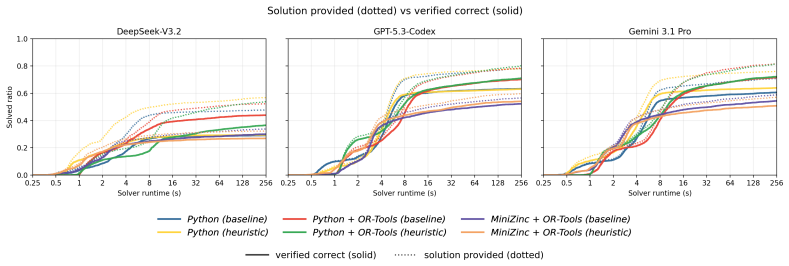






read the original abstract
Large Language Models (LLMs) struggle to solve complex combinatorial problems through direct reasoning, so recent neuro-symbolic systems increasingly use them to synthesize executable solvers. A central design question is how the LLM should represent the solver, and whether it should also attempt to optimize search. We introduce CP-SynC-XL, a benchmark of 100 combinatorial problems (4,577 instances), and evaluate three solver-construction paradigms: native algorithmic search (Python), constraint modeling through a Python solver API (Python + OR-Tools), and declarative constraint modeling (MiniZinc + OR-Tools). We find a consistent representational divergence: Python + OR-Tools attains the highest correctness across LLMs, while MiniZinc + OR-Tools has lower absolute coverage despite using the same OR-Tools back-end. Native Python is the most likely to return a schema-valid solution that fails verification, whereas solver-backed paths preserve higher conditional fidelity. On the heuristic axis, prompting for search optimization yields only small median speed-ups (1.03-1.12x) and a strongly bimodal effect: many instances slow down, and correctness drops sharply on a long tail of problems. A paired code-level audit traces these regressions to a recurring heuristic trap. Under an efficiency-oriented prompt, the LLM may replace complete search with local approximations (Python), inject unverified bounds (Python + OR-Tools), or add redundant declarative machinery that overwhelms or over-constrains the model (MiniZinc + OR-Tools). These findings support a conservative design principle for LLM-generated combinatorial solvers: use the LLM primarily to formalize variables, constraints, and objectives for verified solvers, and separately check any LLM-authored search optimization before use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CP-SynC-XL benchmark (100 combinatorial problems, 4577 instances) and evaluates three LLM solver-generation paradigms (native Python algorithmic search, Python+OR-Tools constraint modeling, and MiniZinc+OR-Tools declarative modeling). It reports that prompting for search optimization produces only small median speed-ups (1.03-1.12x) with a bimodal distribution of slowdowns on many instances and sharp correctness drops on a long tail, traced via code audit to recurring heuristic traps (local approximations, unverified bounds, redundant constraints). The central recommendation is to restrict LLMs to formalizing variables/constraints/objectives for verified solvers while separately validating any LLM-authored optimizations.
Significance. If the observed patterns hold beyond the tested conditions, the work offers a concrete, empirically grounded design principle for neuro-symbolic combinatorial solvers that prioritizes verifiability over LLM-driven heuristic invention. The scale of the benchmark, the cross-paradigm consistency, and the paired code-level audit that maps regressions to specific failure modes constitute a substantive contribution to the literature on LLM code synthesis for optimization problems.
major comments (2)
- [Benchmark section] Benchmark section: No quantitative diversity metrics, coverage arguments, or explicit instance-selection criteria are provided for CP-SynC-XL, which is load-bearing for the claim that the heuristic trap is a general property of LLM-generated solvers rather than an artifact of the chosen problem distribution.
- [Results section] Results section: The abstract and reported findings omit details on statistical tests, error bars, prompt-sensitivity analysis, and the exact LLMs/models used, making it impossible to assess the robustness of the bimodal slowdown and long-tail correctness-drop claims that underpin the design recommendation.
minor comments (1)
- [Evaluation setup] The three evaluated paradigms are clearly described, but the manuscript would benefit from a brief explicit statement of why other common routes (e.g., direct SMT-LIB or Gurobi Python API) were excluded.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point-by-point below, indicating planned revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Benchmark section] Benchmark section: No quantitative diversity metrics, coverage arguments, or explicit instance-selection criteria are provided for CP-SynC-XL, which is load-bearing for the claim that the heuristic trap is a general property of LLM-generated solvers rather than an artifact of the chosen problem distribution.
Authors: We agree that additional details on benchmark construction would strengthen the generality argument. The current manuscript reports only aggregate statistics (100 problems, 4,577 instances) without quantitative diversity measures or selection criteria. In revision we will add a subsection describing problem categories, instance generation methods, quantitative metrics (e.g., distributions of variable counts, constraint densities, and objective types), and coverage arguments referencing standard combinatorial taxonomies. These additions will directly address potential concerns about distribution artifacts. revision: yes
-
Referee: [Results section] Results section: The abstract and reported findings omit details on statistical tests, error bars, prompt-sensitivity analysis, and the exact LLMs/models used, making it impossible to assess the robustness of the bimodal slowdown and long-tail correctness-drop claims that underpin the design recommendation.
Authors: We acknowledge that the abstract and main results section currently lack explicit statistical tests, error bars, and prompt-sensitivity analysis, which limits assessment of robustness. The experimental setup section identifies the LLMs evaluated, but we will move and expand these details into the results section, adding statistical tests for the reported speed-up and correctness distributions, error bars on medians, and a prompt-sensitivity study across template variations. These changes will be incorporated without altering the core empirical patterns. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with independent experimental results
full rationale
The paper is an empirical study that introduces the CP-SynC-XL benchmark and reports observed performance differences (correctness, speed-ups, bimodal effects) across three solver-generation paradigms, supported by code audits. No mathematical derivations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described claims; all central findings reduce directly to experimental measurements and manual inspection rather than to any input by construction. The design recommendation follows from the data without circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three solver-construction paradigms (native algorithmic search in Python, constraint modeling via Python solver API, and declarative modeling in MiniZinc) adequately represent the main approaches for LLM-generated combinatorial solvers.
Reference graph
Works this paper leans on
-
[1]
A Knapsack by Any Other Name: Presentation impacts LLM performance on NP -hard problems
Duchnowski, Alex and Pavlick, Ellie and Koller, Alexander. A Knapsack by Any Other Name: Presentation impacts LLM performance on NP -hard problems. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.352
-
[2]
International Conference on Learning and Intelligent Optimization , pages=
Do LLMs Understand Constraint Programming? Zero-Shot Constraint Programming Model Generation Using LLMs , author=. International Conference on Learning and Intelligent Optimization , pages=. 2025 , organization=
work page 2025
-
[3]
CP-SynC: Multi-Agent Zero-Shot Constraint Modeling in MiniZinc with Synthesized Checkers
CP-SynC: Multi-Agent Zero-Shot Constraint Modeling in MiniZinc with Synthesized Checkers , author=. 2026 , eprint=. doi:10.48550/arXiv.2605.01675 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.01675 2026
-
[4]
Fan, Lizhou and Hua, Wenyue and Li, Lingyao and Ling, Haoyang and Zhang, Yongfeng. NPH ard E val: Dynamic Benchmark on Reasoning Ability of Large Language Models via Complexity Classes. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.225
-
[5]
Polynomial-Time Reasoning at the Edge of
Haoyu Wang and Tao Li and Zhiwei Deng and Yaqing Wang and Xinyi Wu and Deepak Ramachandran and Dan Roth , year=. Polynomial-Time Reasoning at the Edge of
-
[6]
Haoyu Wang and Dan Roth , year=
-
[7]
Reasoning in a Combinatorial and Constrained World: Benchmarking LLMs on Natural-Language Combinatorial Optimization , author=. arXiv preprint arXiv:2602.02188 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
International conference on principles and practice of constraint programming , pages=
MiniZinc: Towards a standard CP modelling language , author=. International conference on principles and practice of constraint programming , pages=. 2007 , organization=
work page 2007
-
[9]
The CP-SAT-LP Solver , booktitle =
Perron, Laurent and Didier, Fr\'. The CP-SAT-LP Solver , booktitle =. 2023 , volume =. doi:10.4230/LIPIcs.CP.2023.3 , annote =
-
[10]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models , author=. arXiv preprint arXiv:2410.05229 , year=
-
[13]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
arXiv preprint arXiv:2506.06941 , year=
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity , author=. arXiv preprint arXiv:2506.06941 , year=
-
[15]
A uto CT : Automating Interpretable Clinical Trial Prediction with LLM Agents
Liu, Fengze and Wang, Haoyu and Cho, Joonhyuk and Roth, Dan and Lo, Andrew. A uto CT : Automating Interpretable Clinical Trial Prediction with LLM Agents. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1575
-
[16]
arXiv preprint arXiv:2310.13227 , year=
Toolchain*: Efficient action space navigation in large language models with a* search , author=. arXiv preprint arXiv:2310.13227 , year=
-
[17]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[19]
The Twelfth International Conference on Learning Representations , year=
Large Language Models as Optimizers , author=. The Twelfth International Conference on Learning Representations , year=
-
[20]
Hilbert: Recursively Building Formal Proofs with Informal Reasoning , booktitle =
Sumanth Varambally and Thomas Voice and Yanchao Sun and Zhifeng Chen and Rose Yu and Ke Ye , year =. Hilbert: Recursively Building Formal Proofs with Informal Reasoning , booktitle =
-
[21]
arXiv preprint arXiv:2506.06052 , year=
Cp-bench: Evaluating large language models for constraint modelling , author=. arXiv preprint arXiv:2506.06052 , year=
-
[22]
arXiv preprint arXiv:2009.00326 , year=
PYCSP3: modeling combinatorial constrained problems in python , author=. arXiv preprint arXiv:2009.00326 , year=
-
[23]
Advances in neural information processing systems , volume=
Faith and fate: Limits of transformers on compositionality , author=. Advances in neural information processing systems , volume=
-
[24]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
work page 2023
-
[25]
Advances in Neural Information Processing Systems , volume=
Satlm: Satisfiability-aided language models using declarative prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
International conference on machine learning , pages=
Pal: Program-aided language models , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[27]
NeurIPS 2022 competition track , pages=
Nl4opt competition: Formulating optimization problems based on their natural language descriptions , author=. NeurIPS 2022 competition track , pages=. 2023 , organization=
work page 2022
-
[28]
arXiv preprint arXiv:2402.10172 , year=
Optimus: Scalable optimization modeling with (mi) lp solvers and large language models , author=. arXiv preprint arXiv:2402.10172 , year=
-
[29]
Mathematical discoveries from program search with large language models , author=. Nature , volume=. 2024 , publisher=
work page 2024
-
[30]
Eureka: Human- level reward design via coding large language models,
Eureka: Human-level reward design via coding large language models , author=. arXiv preprint arXiv:2310.12931 , year=
-
[31]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model,
Evolution of heuristics: Towards efficient automatic algorithm design using large language model , author=. arXiv preprint arXiv:2401.02051 , year=
-
[32]
Silver, David and Huang, Aja and Maddison, Chris J and Guez, Arthur and Sifre, Laurent and Van Den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and others , journal=. Mastering the game of. 2016 , publisher=
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.