Recognition: 2 theorem links
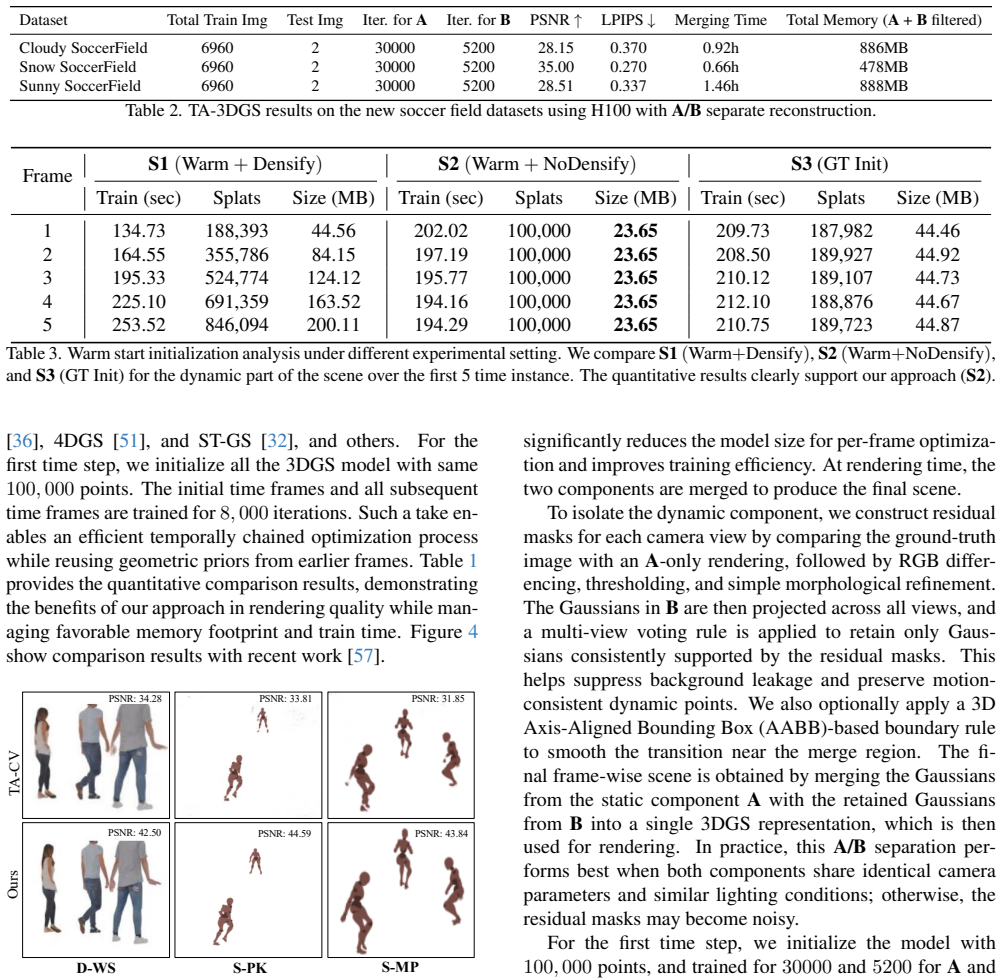
· Lean Theorem3D Gaussian Splatting for Efficient Retrospective Dynamic Scene Novel View Synthesis with a Standardized Benchmark
Pith reviewed 2026-05-13 06:26 UTC · model grok-4.3
The pith
Calibrated synchronized multi-view cameras let standard 3D Gaussian Splatting perform efficient retrospective dynamic scene novel view synthesis without any temporal deformation constraint.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By initializing the SfM-derived point cloud at the start time and propagating optimized Gaussians over time, efficient retrospective NVS can be achieved without imposing a temporal deformation constraint in a synchronized multi-view setting.
What carries the argument
Forward propagation of 3D Gaussians that are optimized independently at each time step, starting from an initial SfM point cloud, with no added temporal deformation or coupling term.
If this is right
- Dynamic-scene NVS pipelines become lighter because no separate motion network or deformation field is required.
- The same 3DGS optimization routine used for static scenes can be reused directly for retrospective dynamic capture.
- Benchmarking of NeRF and 3DGS methods becomes reproducible once the Blender dataset generator supplies identical camera rigs and coordinate conventions.
- Applications that record events with fixed multi-camera rigs gain a practical route to high-quality novel-view replay without complex temporal modeling.
Where Pith is reading between the lines
- The approach may generalize to any capture rig that can enforce sub-frame synchronization and accurate extrinsic calibration.
- Removing the temporal term reduces the risk of over-smoothing fast motion, which could be tested by comparing rendering sharpness on high-speed actions.
- The dataset framework could be extended to generate ground-truth depth and segmentation maps, enabling direct quantitative evaluation of geometry quality beyond image metrics.
Load-bearing premise
Calibrated and synchronized multi-view cameras already supply enough spatial consistency that explicit temporal coupling is unnecessary.
What would settle it
A controlled experiment in which the same dynamic scene is captured once with perfect synchronization and once with small time offsets between cameras; if the unsynchronized version shows clear degradation while the synchronized version remains accurate, the claim is supported, and the reverse would falsify it.
Figures
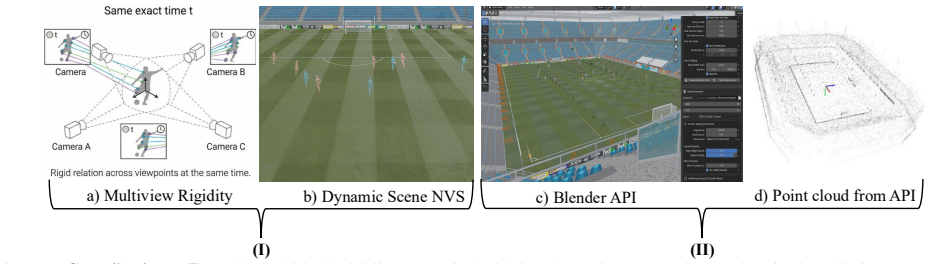


read the original abstract
Retrospective novel view synthesis (NVS) of dynamic scenes is fundamental to applications such as sports. Recent dynamic 3D Gaussian Splatting (3DGS) approaches introduce temporally coupled formulations to enforce motion coherence across time. In this paper, we argue that, in a synchronized multi-view (MV) setting typical of sports, the dynamic scene at each time step is already strongly geometrically constrained. We posit that the availability of calibrated, synchronized viewpoints provides sufficient spatial consistency, and therefore, explicit temporal coupling, or complex multi-body constraints seems unnecessary for retrospective NVS. To this end, we propose an approach tailored for synchronized MV dynamic scene. By initializing the SfM-derived point cloud at the start time and propagating optimized Gaussians over time, we show that efficient retrospective NVS can be achieved without imposing a temporal deformation constraint. Complementing our methodological contribution, we introduce a Dynamic MV dataset framework built on Blender for reproducible NeRF and 3DGS research. The framework generates high-quality, synchronized camera rigs and exports training-ready datasets in standard formats, eliminating inconsistencies in coordinate conventions and data pipelines. Using the framework, we construct a dynamic benchmark suite and evaluate representative NeRF and 3DGS approaches under controlled conditions. Together, we show that, under a synchronized MV setup, efficient retrospective dynamic scene NVS can be achieved using 3DGS. At the same time, the dataset-generation framework enables reproducible and principled benchmarking of dynamic NVS methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in synchronized multi-view captures of dynamic scenes, per-timestep geometric constraints from calibrated viewpoints suffice for 3D Gaussian Splatting-based retrospective novel view synthesis, rendering explicit temporal deformation fields or multi-body constraints unnecessary. The method initializes an SfM point cloud at the first timestep and propagates optimized Gaussians forward in time solely to warm-start independent per-frame optimizations (no cross-time losses or shared parameters). It also contributes a Blender-based Dynamic MV dataset framework that generates synchronized camera rigs and exports training-ready data in standard formats, then uses this to build a benchmark suite evaluating representative NeRF and 3DGS baselines under controlled conditions.
Significance. If the empirical results hold, the work would be significant for simplifying dynamic NVS pipelines in controlled MV settings such as sports capture, by showing that standard 3DGS per-frame optimization can suffice without added temporal machinery. The dataset-generation framework is a clear strength, directly addressing reproducibility issues in dynamic NeRF/3DGS research through standardized exports and controlled conditions. These elements together support more efficient and falsifiable benchmarking.
major comments (1)
- [Abstract and evaluation section] Abstract and evaluation section: the central claim that 'efficient retrospective NVS can be achieved without imposing a temporal deformation constraint' is presented as demonstrated via the benchmark, yet no quantitative metrics (PSNR, SSIM, LPIPS, runtime, or error analysis) or comparisons against temporally-coupled baselines are supplied. This is load-bearing because the argument that spatial consistency alone suffices rests entirely on empirical verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the significance of the Dynamic MV dataset framework. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and evaluation section] Abstract and evaluation section: the central claim that 'efficient retrospective NVS can be achieved without imposing a temporal deformation constraint' is presented as demonstrated via the benchmark, yet no quantitative metrics (PSNR, SSIM, LPIPS, runtime, or error analysis) or comparisons against temporally-coupled baselines are supplied. This is load-bearing because the argument that spatial consistency alone suffices rests entirely on empirical verification.
Authors: We agree that quantitative empirical verification is essential to support the central claim. The evaluation section of the manuscript reports results from the new benchmark suite, including representative NeRF and 3DGS baselines evaluated under controlled synchronized multi-view conditions. However, we acknowledge that the presentation of specific metrics (PSNR, SSIM, LPIPS), runtime measurements, error analysis, and explicit comparisons to temporally-coupled dynamic 3DGS methods (e.g., those using deformation fields) is not as detailed or prominent as needed. In the revised manuscript we will expand the evaluation section with dedicated quantitative tables, runtime analysis, and direct comparisons against temporally-coupled baselines to more rigorously demonstrate that per-frame 3DGS optimization suffices under strong spatial constraints from synchronized calibrated views. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation consists of a standard SfM initialization at t=0 followed by per-frame 3DGS optimization with Gaussian propagation used only as a warm-start. No equations reduce a claimed prediction to a fitted input by construction, no temporal deformation parameters are defined in terms of the target result, and no uniqueness theorems or ansatzes are imported via self-citation. The central claim (synchronized MV geometry suffices without explicit temporal coupling) is an empirical and architectural choice, not a self-referential definition. The new benchmark dataset is an independent contribution for evaluation and does not participate in the method's derivation chain. The pipeline remains self-contained against external 3DGS and SfM baselines.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Calibrated synchronized multi-view provides sufficient spatial consistency for dynamic scenes without needing temporal coupling
invented entities (1)
-
Dynamic MV dataset framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearthe dynamic scene at each time step is already strongly geometrically constrained
Reference graph
Works this paper leans on
-
[1]
Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. Neural point-based graph- ics. InComputer Vision–ECCV 2020: 16th European Con- ference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, pages 696–712. Springer, 2020
work page 2020
-
[2]
Learning neural light fields with ray-space embedding
Benjamin Attal, Jia-Bin Huang, Michael Zollh ¨ofer, Johannes Kopf, and Changil Kim. Learning neural light fields with ray-space embedding. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 19819–19829, 2022
work page 2022
-
[3]
Hyperreel: High-fidelity 6-dof video with ray- conditioned sampling
Benjamin Attal, Jia-Bin Huang, Christian Richardt, Michael Zollhoefer, Johannes Kopf, Matthew O’Toole, and Changil Kim. Hyperreel: High-fidelity 6-dof video with ray- conditioned sampling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16610–16620, 2023
work page 2023
-
[4]
4d visualization of dynamic events from unconstrained multi-view videos
Aayush Bansal, Minh V o, Yaser Sheikh, Deva Ramanan, and Srinivasa Narasimhan. 4d visualization of dynamic events from unconstrained multi-view videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5366–5375, 2020
work page 2020
-
[5]
Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields
Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 5855–5864, 2021
work page 2021
-
[6]
Mip-nerf 360: Unbounded anti-aliased neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5470–5479, 2022
work page 2022
-
[7]
Mojtaba Bemana, Karol Myszkowski, Hans-Peter Seidel, and Tobias Ritschel. X-fields: Implicit neural view-, light- and time-image interpolation.ACM Transactions on Graph- ics (TOG), 39(6):1–15, 2020
work page 2020
-
[8]
Blender Foundation, Stichting Blender Foundation, Amsterdam, 2022
Blender Online Community.Blender - a 3D modelling and rendering package. Blender Foundation, Stichting Blender Foundation, Amsterdam, 2022
work page 2022
-
[9]
Michael Broxton, John Flynn, Ryan Overbeck, Daniel Erick- son, Peter Hedman, Matthew Duvall, Jason Dourgarian, Jay Busch, Matt Whalen, and Paul Debevec. Immersive light field video with a layered mesh representation.ACM Trans- actions on Graphics (TOG), 39(4):86–1, 2020
work page 2020
-
[10]
Unstructured lumigraph ren- dering
Chris Buehler, Michael Bosse, Leonard McMillan, Steven Gortler, and Michael Cohen. Unstructured lumigraph ren- dering. InProceedings of the 28th annual conference on Computer graphics and interactive techniques, pages 425– 432, 2001
work page 2001
-
[11]
Hexplane: A fast representa- tion for dynamic scenes
Ang Cao and Justin Johnson. Hexplane: A fast representa- tion for dynamic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 130–141, 2023
work page 2023
-
[12]
Tensorf: Tensorial radiance fields
Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. Tensorf: Tensorial radiance fields. InEuropean con- ference on computer vision, pages 333–350. Springer, 2022
work page 2022
-
[13]
A neural rendering framework for free-viewpoint relighting
Zhang Chen, Anpei Chen, Guli Zhang, Chengyuan Wang, Yu Ji, Kiriakos N Kutulakos, and Jingyi Yu. A neural rendering framework for free-viewpoint relighting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5599–5610, 2020
work page 2020
-
[14]
Ben Fei, Jingyi Xu, Rui Zhang, Qingyuan Zhou, Weidong Yang, and Ying He. 3d gaussian splatting as new era: A survey.IEEE Transactions on Visualization and Computer Graphics, 2024
work page 2024
-
[15]
Signet: Ef- ficient neural representation for light fields
Brandon Yushan Feng and Amitabh Varshney. Signet: Ef- ficient neural representation for light fields. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 14224–14233, 2021
work page 2021
-
[16]
K-planes: Explicit radiance fields in space, time, and appearance
Sara Fridovich-Keil, Giacomo Meanti, Frederik Rahbæk Warburg, Benjamin Recht, and Angjoo Kanazawa. K-planes: Explicit radiance fields in space, time, and appearance. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 12479–12488, 2023
work page 2023
-
[17]
Sharath Girish, Tianye Li, Amrita Mazumdar, Abhinav Shri- vastava, Shalini De Mello, et al. Queen: Quantized efficient encoding of dynamic gaussians for streaming free-viewpoint videos.Advances in Neural Information Processing Systems, 37:43435–43467, 2024
work page 2024
-
[18]
Neural implicit dense semantic slam
Yasaman Haghighi, Suryansh Kumar, Jean-Philippe Thiran, and Luc Van Gool. Neural implicit dense semantic slam. arXiv preprint arXiv:2304.14560, 2023
-
[19]
Cambridge university press, 2003
Richard Hartley.Multiple view geometry in computer vision. Cambridge university press, 2003
work page 2003
-
[20]
Ro- bustifying the multi-scale representation of neural radiance fields
Nishant Jain, Suryansh Kumar, and Luc Van Gool. Ro- bustifying the multi-scale representation of neural radiance fields. In33rd British Machine Vision Conference Proceed- ings, page 578. BMV A Press, 2022
work page 2022
-
[21]
Enhanced stable view synthesis
Nishant Jain, Suryansh Kumar, and Luc Van Gool. Enhanced stable view synthesis. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 13208–13217, 2023
work page 2023
-
[22]
Nishant Jain, Suryansh Kumar, and Luc Van Gool. Learning robust multi-scale representation for neural radiance fields from unposed images.International Journal of Computer Vision, 132(4):1310–1335, 2024
work page 2024
-
[23]
Panoptic studio: A massively multiview system for social motion capture
Hanbyul Joo, Hao Liu, Lei Tan, Lin Gui, Bart Nabbe, Iain Matthews, Takeo Kanade, Shohei Nobuhara, and Yaser Sheikh. Panoptic studio: A massively multiview system for social motion capture. InProceedings of the IEEE inter- national conference on computer vision, pages 3334–3342, 2015
work page 2015
-
[24]
Uncertainty-aware deep multi-view photometric stereo
Berk Kaya, Suryansh Kumar, Carlos Oliveira, Vittorio Fer- rari, and Luc Van Gool. Uncertainty-aware deep multi-view photometric stereo. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 12601–12611, 2022
work page 2022
-
[25]
Neural radiance fields approach to deep multi-view photometric stereo
Berk Kaya, Suryansh Kumar, Francesco Sarno, Vittorio Fer- rari, and Luc Van Gool. Neural radiance fields approach to deep multi-view photometric stereo. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 1965–1977, 2022
work page 1965
-
[26]
3d gaussian splatting for real-time 9 radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time 9 radiance field rendering.ACM Trans. Graph., 42(4):139–1, 2023
work page 2023
-
[27]
Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splat- ting as markov chain monte carlo.Advances in Neural Infor- mation Processing Systems, 37:80965–80986, 2024
work page 2024
-
[28]
Streaming radiance fields for 3d video synthesis
Lingzhi Li, Zhen Shen, zhongshu wang, Li Shen, and Ping Tan. Streaming radiance fields for 3d video synthesis. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[29]
Neural 3d video synthesis from multi-view video
Tianye Li, Mira Slavcheva, Michael Zollhoefer, Simon Green, Christoph Lassner, Changil Kim, Tanner Schmidt, Steven Lovegrove, Michael Goesele, Richard Newcombe, et al. Neural 3d video synthesis from multi-view video. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 5521–5531, 2022
work page 2022
-
[30]
Neural scene flow fields for space-time view synthesis of dy- namic scenes
Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dy- namic scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6498– 6508, 2021
work page 2021
-
[31]
Neulf: Efficient novel view synthesis with neural 4d light field
Zhong Li, Liangchen Song, Celong Liu, Junsong Yuan, and Yi Xu. Neulf: Efficient novel view synthesis with neural 4d light field. InEGSR (ST), pages 59–69, 2022
work page 2022
-
[32]
Spacetime gaus- sian feature splatting for real-time dynamic view synthesis
Zhan Li, Zhang Chen, Zhong Li, and Yi Xu. Spacetime gaus- sian feature splatting for real-time dynamic view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8508–8520, 2024
work page 2024
-
[33]
Gaussian-flow: 4d reconstruction with dynamic 3d gaus- sian particle
Youtian Lin, Zuozhuo Dai, Siyu Zhu, and Yao Yao. Gaussian-flow: 4d reconstruction with dynamic 3d gaus- sian particle. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21136– 21145, 2024
work page 2024
-
[34]
Neural vol- umes: learning dynamic renderable volumes from images
Stephen Lombardi, Tomas Simon, Jason Saragih, Gabriel Schwartz, Andreas Lehrmann, and Yaser Sheikh. Neural vol- umes: learning dynamic renderable volumes from images. ACM Transactions on Graphics (TOG), 38(4):1–14, 2019
work page 2019
-
[35]
Mix- ture of volumetric primitives for efficient neural rendering
Stephen Lombardi, Tomas Simon, Gabriel Schwartz, Michael Zollhoefer, Yaser Sheikh, and Jason Saragih. Mix- ture of volumetric primitives for efficient neural rendering. ACM Transactions on Graphics (ToG), 40(4):1–13, 2021
work page 2021
-
[36]
Dynamic 3d gaussians: Tracking by per- sistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by per- sistent dynamic view synthesis. In2024 International Con- ference on 3D Vision (3DV), pages 800–809. IEEE, 2024
work page 2024
-
[37]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[38]
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
work page 2022
-
[39]
Donerf: Towards real- time rendering of compact neural radiance fields using depth oracle networks
Thomas Neff, Pascal Stadlbauer, Mathias Parger, Andreas Kurz, Joerg H Mueller, Chakravarty R Alla Chaitanya, Anton Kaplanyan, and Markus Steinberger. Donerf: Towards real- time rendering of compact neural radiance fields using depth oracle networks. InComputer Graphics Forum, pages 45–
-
[40]
Wiley Online Library, 2021
work page 2021
-
[41]
Nerfies: Deformable neural radiance fields
Keunhong Park, Utkarsh Sinha, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Steven M Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5865–5874, 2021
work page 2021
-
[42]
Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin- Brualla, and Steven M Seitz. Hypernerf: A higher- dimensional representation for topologically varying neural radiance fields.ACM Transactions on Graphics (TOG), 40: 1 – 12, 2021
work page 2021
-
[43]
D-nerf: Neural radiance fields for dynamic scenes
Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 10318–10327, 2021
work page 2021
-
[44]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 4104–4113, 2016
work page 2016
-
[45]
Steven M Seitz and Charles R Dyer. View morphing. InPro- ceedings of the 23rd annual conference on Computer graph- ics and interactive techniques, pages 21–30, 1996
work page 1996
-
[46]
Tensor4d: Efficient neural 4d decomposition for high-fidelity dynamic reconstruction and rendering
Ruizhi Shao, Zerong Zheng, Hanzhang Tu, Boning Liu, Hongwen Zhang, and Yebin Liu. Tensor4d: Efficient neural 4d decomposition for high-fidelity dynamic reconstruction and rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16632– 16642, 2023
work page 2023
-
[47]
Mohammed Suhail, Carlos Esteves, Leonid Sigal, and Ameesh Makadia. Light field neural rendering. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8269–8279, 2022
work page 2022
-
[48]
Nerfstudio: A modular framework for neural radiance field development
Matthew Tancik, Ethan Weber, Evonne Ng, Ruilong Li, Brent Yi, Justin Kerr, Terrance Wang, Alexander Kristof- fersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, and Angjoo Kanazawa. Nerfstudio: A modular framework for neural radiance field development. InACM SIGGRAPH 2023 Conference Proceedings, 2023
work page 2023
-
[49]
Justus Thies, Michael Zollh ¨ofer, and Matthias Nießner. De- ferred neural rendering: Image synthesis using neural tex- tures.Acm Transactions on Graphics (TOG), 38(4):1–12, 2019
work page 2019
-
[50]
R2l: Distilling neural radiance field to neural light field for efficient novel view synthesis
Huan Wang, Jian Ren, Zeng Huang, Kyle Olszewski, Men- glei Chai, Yun Fu, and Sergey Tulyakov. R2l: Distilling neural radiance field to neural light field for efficient novel view synthesis. InEuropean Conference on Computer Vi- sion, pages 612–629. Springer, 2022
work page 2022
-
[51]
Freetimegs: Free gaussian primitives at anytime any- where for dynamic scene reconstruction
Yifan Wang, Peishan Yang, Zhen Xu, Jiaming Sun, Zhan- hua Zhang, Yong Chen, Hujun Bao, Sida Peng, and Xiaowei Zhou. Freetimegs: Free gaussian primitives at anytime any- where for dynamic scene reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21750–21760, 2025
work page 2025
-
[52]
10 4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 10 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 20310–20320, 2024
work page 2024
-
[53]
Neural radiance fields for the real world: A survey.arXiv preprint arXiv:2501.13104, 2025
Wenhui Xiao, Remi Chierchia, Rodrigo Santa Cruz, Xuesong Li, David Ahmedt-Aristizabal, Olivier Salvado, Clinton Fookes, and Leo Lebrat. Neural radiance fields for the real world: A survey.arXiv preprint arXiv:2501.13104, 2025
-
[54]
Neural fields in visual computing and beyond
Yiheng Xie, Towaki Takikawa, Shunsuke Saito, Or Litany, Shiqin Yan, Numair Khan, Federico Tombari, James Tomp- kin, Vincent Sitzmann, and Srinath Sridhar. Neural fields in visual computing and beyond. InComputer graphics forum, pages 641–676. Wiley Online Library, 2022
work page 2022
-
[55]
Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20331–20341, 2024
work page 2024
-
[56]
Real- time photorealistic dynamic scene representation and render- ing with 4d gaussian splatting
Zeyu Yang, Hongye Yang, Zijie Pan, and Li Zhang. Real- time photorealistic dynamic scene representation and render- ing with 4d gaussian splatting. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[57]
Yunxiao Zhang, William Stone, and Suryansh Kumar. Time- archival camera virtualization for sports and visual perfor- mances.Computer Vision and Image Understanding, 267: 104714, 2026
work page 2026
-
[58]
Yunxiao Zhang, William Stone, and Suryansh Kumar. Time- archival camera virtualization for sports and visual perfor- mances.arXiv preprint arXiv:2602.15181, 2026. 11 3D Gaussian Splatting for Efficient Retrospective Dynamic Scene Novel View Synthesis with a Standardized Benchmark Supplementary Material
-
[59]
More Detail on Blender API While Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have achieved remarkable progress in novel view synthesis , preparing multi-view datasets across different methods remains a bottleneck due to varying for- mat requirements and coordinate system conventions To al- leviate the extensive manual setup and debuggin...
-
[60]
Additional Ablation Studies Here, we provide additional analyses supporting the two central claims of the paper: (i) our time-archival 3DGS formulation preserves the practical efficiency of Gaussian splatting for retrospective rendering, and (ii) warm-start training primarily exploits local temporal smoothness rather than any implicit temporal coupling in...
work page 1920
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.