Recognition: no theorem link
Search Your Block Floating Point Scales!
Pith reviewed 2026-05-13 05:48 UTC · model grok-4.3
The pith
A fine-grained search over block scales in microscaling formats reduces quantization error compared with the standard maximum-magnitude choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
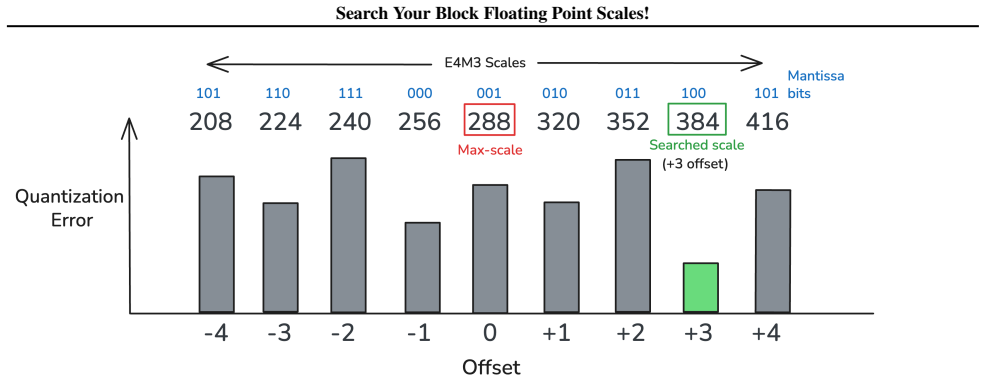
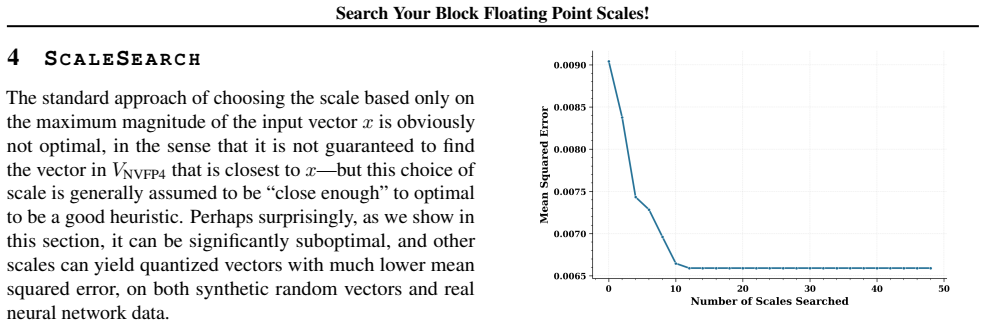
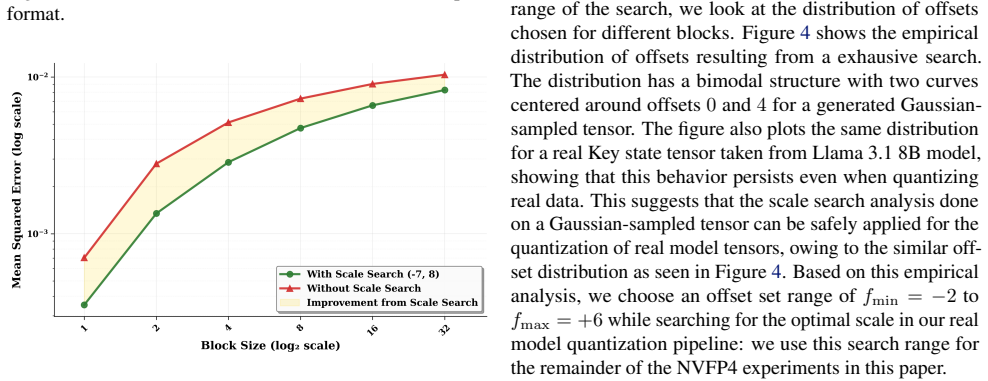
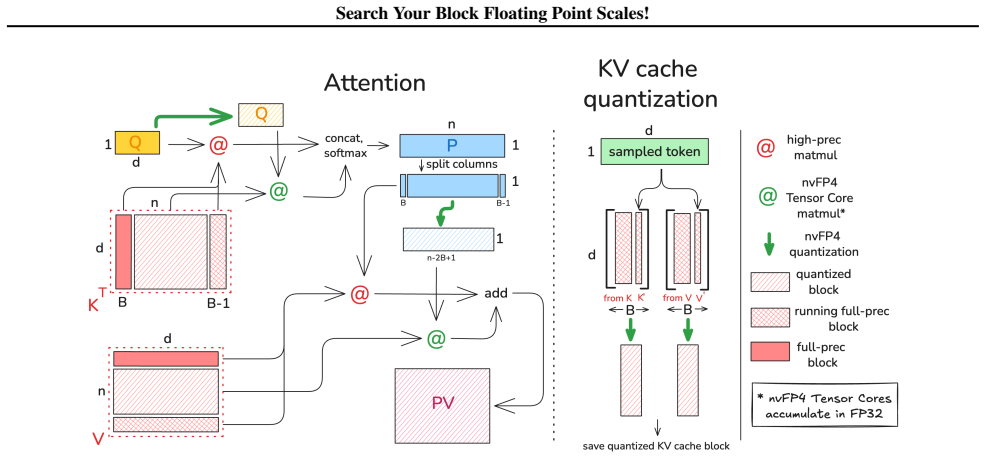
The central claim is that replacing the fixed max-magnitude scale in microscaling Block Floating Point with a searched scale that minimizes per-block quantization error, found by testing candidates against the mantissa representation, produces measurably lower overall error. The authors show the method works when combined with post-training quantization and when used inside ScaleSearchAttention, an NVFP4 attention kernel that adapts prior low-precision techniques to preserve near-baseline performance on causal language modeling. Reported gains include a 27 percent reduction in quantization error for NVFP4, up to 15-point accuracy lifts on MATH500 for Qwen3-8B, and up to 0.77-point perplexity
What carries the argument
ScaleSearch, a per-block enumeration of candidate scales that evaluates quantization error directly on the mantissa bits to select the scale minimizing error for the observed data distribution.
If this is right
- ScaleSearch integrates directly with post-training quantization to improve language-model accuracy on benchmarks such as MATH500.
- ScaleSearchAttention keeps causal language modeling perplexity within 0.77 points of the full-precision baseline while using NVFP4.
- Quantization error for NVFP4 drops by 27 percent relative to the conventional fixed-scale method.
- The approach works on models up to at least 70 billion parameters without requiring hardware changes beyond existing microscaling support.
Where Pith is reading between the lines
- If the search overhead proves small in practice, the same idea could be used to adjust scales dynamically when input statistics change during inference.
- Lower per-block error may allow 4-bit formats to be used in more layers without accuracy recovery steps such as fine-tuning.
- The method could be combined with calibration-data reduction techniques because the scale choice is derived from the tensor values themselves rather than from a separate optimizer.
Load-bearing premise
The search over candidate scales can be run quickly enough during quantization or inference that the added cost does not outweigh the accuracy gain, and the selected scales remain useful across varying inputs and models.
What would settle it
Apply ScaleSearch to the same tensors and models used in the paper and measure whether the resulting quantization error or downstream task accuracy is no better than the standard max-magnitude baseline; if error or accuracy stays the same or worsens, or if runtime increases by more than a small constant factor, the claimed benefit does not hold.
Figures




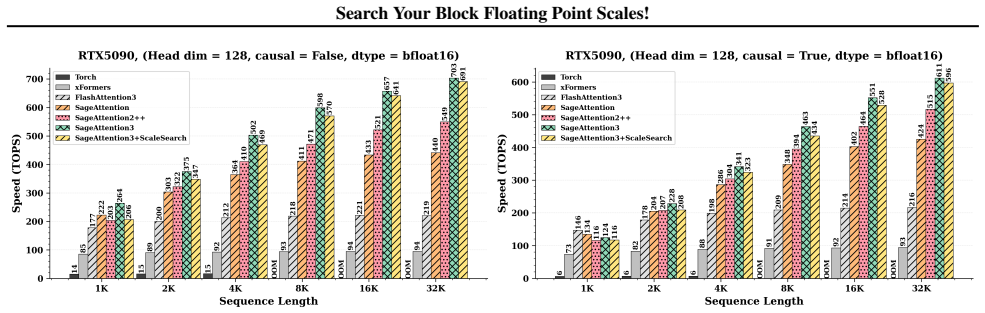
read the original abstract
Quantization has emerged as a standard technique for accelerating inference for generative models by enabling faster low-precision computations and reduced memory transfers. Recently, GPU accelerators have added first-class support for microscaling Block Floating Point (BFP) formats. Standard BFP algorithms use a fixed scale based on the maximum magnitude of the block. We observe that this scale choice can be suboptimal with respect to quantization errors. In this work, we propose ScaleSearch, an alternative strategy for selecting these scale factors: using a fine-grained search leveraging the mantissa bits in microscaling formats to minimize the quantization error for the given distribution. ScaleSearch can be integrated with existing quantization methods such as Post Training Quantization and low-precision attention, and is shown to improve their performance. Additionally, we introduce ScaleSearchAttention, an accelerated NVFP4-based attention algorithm, which uses ScaleSearch and adapted prior techniques to ensure near-0 performance loss for causal language modeling. Experiments show that ScaleSearch reduces quantization error by 27% for NVFP4 and improves language model PTQ by up to 15 points for MATH500 (Qwen3-8B), while ScaleSearchAttention improves Wikitext-2 PPL by upto 0.77 points for Llama 3.1 70B. The proposed methods closely match baseline performance while providing quantization accuracy improvements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ScaleSearch, a fine-grained search over scale factors in microscaling Block Floating Point (BFP) formats that exploits mantissa bits to minimize quantization error for a given tensor distribution, as an alternative to standard max-magnitude scaling. It shows how to integrate ScaleSearch into post-training quantization (PTQ) pipelines and introduces ScaleSearchAttention, an NVFP4-based attention algorithm that combines the search with prior techniques to achieve near-zero accuracy loss in causal language modeling. Experiments report a 27% reduction in quantization error for NVFP4, up to 15-point gains on MATH500 for Qwen3-8B under PTQ, and up to 0.77-point Wikitext-2 perplexity improvement for Llama 3.1 70B.
Significance. If the search overhead proves negligible and the gains prove robust, ScaleSearch would be a practical, hardware-agnostic improvement to existing BFP quantization flows, directly addressing the sub-optimality of max-magnitude scaling while preserving the inference speedups of low-precision arithmetic. The concrete error-reduction and downstream-task numbers are a strength; the explicit integration with PTQ and attention further increases potential impact.
major comments (3)
- [Abstract] Abstract and Experiments section: the central claim that ScaleSearch yields net benefit for inference-time quantization (including the 27% error reduction and task improvements) is load-bearing on search cost, yet no per-block operation count, asymptotic complexity, candidate-set size, or end-to-end latency numbers on the 70 B model are provided; without these, it is impossible to verify that the search does not offset the claimed acceleration.
- [Method] Method section: the description of how ScaleSearch leverages mantissa bits to generate and evaluate scale candidates is given at a high level only; no explicit error metric equation, search-space definition, or pseudocode is supplied, preventing assessment of whether the procedure is deterministic, reproducible, or parameter-free as implied.
- [Experiments] Experiments section: reported improvements (15 points on MATH500, 0.77 PPL on Wikitext-2) lack ablation studies, multiple random seeds, or statistical significance tests, so it is unclear whether the gains are attributable to ScaleSearch itself or to other unstated implementation choices.
minor comments (2)
- Define all acronyms (NVFP4, PTQ, BFP) on first use and ensure consistent capitalization of microscaling formats throughout.
- Add a small table or figure caption clarifying the exact number of scale candidates evaluated per block for each format tested.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: the central claim that ScaleSearch yields net benefit for inference-time quantization (including the 27% error reduction and task improvements) is load-bearing on search cost, yet no per-block operation count, asymptotic complexity, candidate-set size, or end-to-end latency numbers on the 70 B model are provided; without these, it is impossible to verify that the search does not offset the claimed acceleration.
Authors: We agree that explicit quantification of search overhead is necessary to support the net-benefit claim for inference. In the revised manuscript we will add per-block operation counts, asymptotic complexity analysis, the exact candidate-set size, and end-to-end latency measurements on the Llama 3.1 70B model. Preliminary internal measurements indicate the search remains lightweight because it operates on small fixed-size blocks with a modest number of mantissa-derived candidates, but we will include the concrete numbers requested. revision: yes
-
Referee: [Method] Method section: the description of how ScaleSearch leverages mantissa bits to generate and evaluate scale candidates is given at a high level only; no explicit error metric equation, search-space definition, or pseudocode is supplied, preventing assessment of whether the procedure is deterministic, reproducible, or parameter-free as implied.
Authors: We accept that the current method description is insufficiently detailed. We will expand the Method section to include the explicit quantization-error metric, a formal definition of the search space over scale candidates, and pseudocode for the ScaleSearch procedure. These additions will make clear that the algorithm is deterministic and requires no extra hyperparameters beyond the block size and format already specified. revision: yes
-
Referee: [Experiments] Experiments section: reported improvements (15 points on MATH500, 0.77 PPL on Wikitext-2) lack ablation studies, multiple random seeds, or statistical significance tests, so it is unclear whether the gains are attributable to ScaleSearch itself or to other unstated implementation choices.
Authors: We agree that stronger empirical validation is warranted. We will add ablation studies that isolate the contribution of ScaleSearch, report results across multiple random seeds for the smaller models, and include statistical significance tests where appropriate. For the 70B-scale experiments, computational limits prevented extensive repeated runs; we will explicitly state this constraint and report any available variance measures. revision: partial
Circularity Check
No circularity: ScaleSearch is an explicit search procedure minimizing a defined error metric
full rationale
The paper's core contribution is an algorithmic search over candidate scales (leveraging mantissa bits) to minimize a standard quantization error for a given tensor distribution. This is not derived from prior equations in the paper or self-citations; it is presented as a direct optimization step that can be plugged into PTQ or attention. No step reduces a 'prediction' to a fitted parameter by construction, no uniqueness theorem is invoked from self-citations, and no ansatz is smuggled in. The reported improvements (e.g., 27% error reduction, PPL gains) are empirical measurements against baselines, not tautological. The method is self-contained against external benchmarks of quantization error and does not rely on load-bearing self-references.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions about typical weight and activation distributions in language models and the appropriateness of mean-squared or similar quantization error metrics.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Generating Long Sequences with Sparse Transformers
Generating long sequences with sparse transformers , author=. arXiv preprint arXiv:1904.10509 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[4]
Advances in neural information processing systems , volume=
Big bird: Transformers for longer sequences , author=. Advances in neural information processing systems , volume=
-
[5]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen (Henry) and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[7]
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
work page 2024
-
[8]
Advances in Neural Information Processing Systems , volume=
Zipcache: Accurate and efficient kv cache quantization with salient token identification , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Advances in Neural Information Processing Systems , volume=
Minicache: Kv cache compression in depth dimension for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Model Tells You What to Discard: Adaptive
Suyu Ge and Yunan Zhang and Liyuan Liu and Minjia Zhang and Jiawei Han and Jianfeng Gao , booktitle=. Model Tells You What to Discard: Adaptive. 2024 , url=
work page 2024
-
[11]
Yuhong Li and Yingbing Huang and Bowen Yang and Bharat Venkitesh and Acyr Locatelli and Hanchen Ye and Tianle Cai and Patrick Lewis and Deming Chen , booktitle=. Snap. 2024 , url=
work page 2024
-
[12]
Mahoney and Kurt Keutzer and Amir Gholami , booktitle=
Rishabh Tiwari and Haocheng Xi and Aditya Tomar and Coleman Richard Charles Hooper and Sehoon Kim and Maxwell Horton and Mahyar Najibi and Michael W. Mahoney and Kurt Keutzer and Amir Gholami , booktitle=. QuantSpec: Self-Speculative Decoding with Hierarchical Quantized. 2025 , url=
work page 2025
-
[13]
Xing Li and Zeyu XING and Yiming Li and Linping Qu and Hui-Ling Zhen and Yiwu Yao and Wulong Liu and Sinno Jialin Pan and Mingxuan Yuan , booktitle=. 2025 , url=
work page 2025
-
[14]
Forty-second International Conference on Machine Learning , year=
Cache Me If You Must: Adaptive Key-Value Quantization for Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[16]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
- [17]
- [18]
-
[19]
Mahoney and Sophia Shao and Kurt Keutzer and Amir Gholami , booktitle=
Coleman Richard Charles Hooper and Sehoon Kim and Hiva Mohammadzadeh and Michael W. Mahoney and Sophia Shao and Kurt Keutzer and Amir Gholami , booktitle=. 2024 , url=
work page 2024
-
[20]
Saleh Ashkboos and Amirkeivan Mohtashami and Maximilian L. Croci and Bo Li and Pashmina Cameron and Martin Jaggi and Dan Alistarh and Torsten Hoefler and James Hensman , booktitle=. QuaRot: Outlier-Free 4-Bit Inference in Rotated. 2024 , url=
work page 2024
-
[21]
GEAR: An Efficient KV Cache Compression Recipe for Near-Lossless Generative Inference of LLM , author=. 2024 , eprint=
work page 2024
-
[25]
International Conference on Learning Representations , year =
Reformer: The Efficient Transformer , author =. International Conference on Learning Representations , year =
-
[26]
No Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization , author=. 2024 , eprint=
work page 2024
-
[27]
Payman Behnam and Yaosheng Fu and Ritchie Zhao and Po-An Tsai and Zhiding Yu and Alexey Tumanov , booktitle=. Rocket. 2025 , url=
work page 2025
-
[29]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , author=. 2023 , eprint=
work page 2023
- [30]
-
[31]
Transactions on Machine Learning Research , issn=
Emergent Abilities of Large Language Models , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
work page 2022
- [32]
-
[33]
Matrix Multiplication Background User's Guide , author=
-
[35]
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , title =. 2022 , isbn =
work page 2022
-
[36]
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference , year=
Jacob, Benoit and Kligys, Skirmantas and Chen, Bo and Zhu, Menglong and Tang, Matthew and Howard andrew and Adam, Hartwig and Kalenichenko, Dmitry , booktitle=. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference , year=
-
[37]
International Conference on Learning Representations , year=
Training with Quantization Noise for Extreme Model Compression , author=. International Conference on Learning Representations , year=
-
[38]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills , author=. 2023 , eprint=
work page 2023
-
[39]
International conference on machine learning , pages=
Sparsegpt: Massive language models can be accurately pruned in one-shot , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[40]
Advances in neural information processing systems , volume=
Zeroquant: Efficient and affordable post-training quantization for large-scale transformers , author=. Advances in neural information processing systems , volume=
-
[41]
AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration , url =
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song , booktitle =. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration , url =
- [42]
-
[43]
arXiv preprint arXiv:2306.11695 , year=
A simple and effective pruning approach for large language models , author=. arXiv preprint arXiv:2306.11695 , year=
-
[45]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
Learning to compress prompts with gist tokens , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[49]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. arXiv preprint arXiv:2307.08691 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Advances in Neural Information Processing Systems , volume=
Flashattention-3: Fast and accurate attention with asynchrony and low-precision , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
International conference on machine learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[54]
Optimizing Large Language Model Training Using
Ruizhe Wang and Yeyun Gong and Xiao Liu and Guoshuai Zhao and Ziyue Yang and Baining Guo and Zheng-Jun Zha and Peng CHENG , booktitle=. Optimizing Large Language Model Training Using. 2025 , url=
work page 2025
-
[55]
Red Hat AI and vLLM Project , year=
-
[56]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[57]
FP4 All the Way: Fully Quantized Training of LLMs , author=. 2025 , eprint=
work page 2025
-
[58]
Joldes, Mioara and Muller, Jean-Michel and Popescu, Valentina , title =. ACM Trans. Math. Softw. , month = oct, articleno =. 2017 , issue_date =. doi:10.1145/3121432 , abstract =
- [59]
-
[60]
Omniquant: Omnidirectionally calibrated quan- tization for large language models,
Omniquant: Omnidirectionally calibrated quantization for large language models , author=. arXiv preprint arXiv:2308.13137 , year=
-
[61]
Benchmarking Large Language Models for News Summarization
Zhang, Tianyi and Ladhak, Faisal and Durmus, Esin and Liang, Percy and McKeown, Kathleen and Hashimoto, Tatsunori B. Benchmarking Large Language Models for News Summarization. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00632
- [62]
-
[63]
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models , author=. 2025 , eprint=
work page 2025
-
[64]
TensorRT Documentation , author=
-
[65]
Wikitext-2 dataset , author=
-
[66]
Large Language Model The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author=. 2025 , url=
work page 2025
-
[67]
Introducing NVFP4 for Efficient and Accurate Low-Precision Inference , author=. 2025 , url=
work page 2025
- [68]
-
[70]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=
-
[72]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Fixed Point Quantization of Deep Convolutional Networks , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
work page 2016
-
[73]
Low-power computer vision , pages=
A survey of quantization methods for efficient neural network inference , author=. Low-power computer vision , pages=. 2022 , publisher=
work page 2022
-
[74]
Proceedings of the 50th Annual International Symposium on Computer Architecture , pages=
With shared microexponents, a little shifting goes a long way , author=. Proceedings of the 50th Annual International Symposium on Computer Architecture , pages=
-
[75]
Working with Quantized Types , author=
-
[76]
Quantization , author=
-
[78]
Advances in neural information processing systems , volume=
Pushing the limits of narrow precision inferencing at cloud scale with microsoft floating point , author=. Advances in neural information processing systems , volume=
-
[80]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Quantization and training of neural networks for efficient integer-arithmetic-only inference , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[81]
Advances in Neural Information Processing Systems , volume=
Training dnns with hybrid block floating point , author=. Advances in Neural Information Processing Systems , volume=
-
[82]
2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA) , pages=
Fast: Dnn training under variable precision block floating point with stochastic rounding , author=. 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA) , pages=. 2022 , organization=
work page 2022
-
[83]
NVIDIA Blackwell Delivers World-Record DeepSeek-R1 Inference Performance , author=. 2025 , url=
work page 2025
-
[85]
Advances in Neural Information Processing Systems , volume=
Quip: 2-bit quantization of large language models with guarantees , author=. Advances in Neural Information Processing Systems , volume=
-
[86]
SageAttention2: Efficient Attention with Smoothing Q and Per-thread Quantization , author=
-
[89]
Introducing gpt-oss , author=
-
[90]
Transactions of the Association for Computational Linguistics , volume=
In-context retrieval-augmented language models , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
work page 2023
-
[91]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[92]
Linformer: Self-Attention with Linear Complexity
Linformer: Self-attention with linear complexity , author=. arXiv preprint arXiv:2006.04768 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[93]
GitHub repository , howpublished=
Mochi 1 , author=. GitHub repository , howpublished=. 2024 , publisher =
work page 2024
-
[94]
Qwen Technical Report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [95]
- [96]
- [97]
-
[98]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. 2023 , eprint=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.