Recognition: no theorem link
KV-Fold: One-Step KV-Cache Recurrence for Long-Context Inference
Pith reviewed 2026-05-13 05:21 UTC · model grok-4.3
The pith
Frozen pretrained transformers support stable KV-cache recurrence for long-context inference without training or model changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
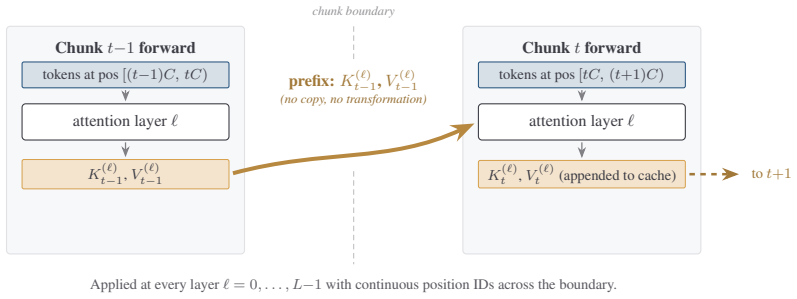
KV-Fold treats the key-value cache as the accumulator in a left fold over sequence chunks. At each step the model processes the next chunk conditioned on the accumulated cache, appends the newly produced keys and values, and passes the enlarged cache forward; the same one-step update is applied repeatedly. The induced recurrence is stable: per-step drift rises briefly and then saturates into a flat plateau that persists across deep chains. This plateau is insensitive to a 10,000x change in numerical precision, robust across chunk sizes, and consistent across model families. At the task level KV-Fold preserves exact information over long distances, achieving 100% exact-match retrieval on a 16
What carries the argument
The KV-cache concatenation primitive that appends new keys and values to the prefix cache from earlier chunks, turning each forward pass into a recurrence step that reuses the model's state across segments.
If this is right
- Frozen models can process contexts far beyond training length through repeated chunk-wise forward passes.
- Exact long-range information is preserved without trading off fidelity for memory bounds as in streaming approximations.
- Large contexts fit inside single 40GB GPU memory limits.
- The approach works consistently across model families and chunk sizes.
- Drift saturation supports scaling to hundreds of chunks without unbounded error growth.
Where Pith is reading between the lines
- The same cache-folding pattern could support generation or reasoning tasks over long documents by keeping the accumulated state active.
- Transformers may already encode an implicit capacity for stable state propagation that can be activated more broadly at inference time.
- Adaptive chunk sizing based on content could be combined with the method to optimize for varying sequence complexity.
- Applying the technique to tasks like long-document question answering would test whether the plateau behavior extends past synthetic retrieval.
Load-bearing premise
The observed saturation of per-step drift into a flat plateau will continue to hold for arbitrary chain depths and across all downstream tasks, not just needle-in-a-haystack retrieval.
What would settle it
An experiment that measures continued growth in drift or loss of retrieval accuracy when chain depth greatly exceeds 511 chunks or when the task requires integrating information across the full context rather than simple fact lookup.
Figures

read the original abstract
We introduce KV-Fold, a simple, training-free long-context inference protocol that treats the key-value (KV) cache as the accumulator in a left fold over sequence chunks. At each step, the model processes the next chunk conditioned on the accumulated cache, appends the newly produced keys and values, and passes the enlarged cache forward; the same one-step update is applied repeatedly, analogous to foldl in functional programming. Building on the KV cache concatenation primitive introduced for latent multi-agent communication, we repurpose it as a chunk-to-chunk recurrence for long-context inference. When processing chunk t, the model attends to the KV cache carried from earlier chunks as a prefix, reusing its internal state across segments without modifying or retraining the model. Despite its simplicity, the induced recurrence is stable: per-step drift rises briefly and then saturates into a flat plateau that persists across deep chains. This plateau is insensitive to a 10,000x change in numerical precision, robust across chunk sizes, and consistent across model families. At the task level, KV-Fold preserves exact information over long distances. On a needle-in-a-haystack benchmark, it achieves 100% exact-match retrieval across 152 trials spanning contexts from 16K to 128K tokens and chain depths up to 511 on Llama-3.1-8B, while remaining within the memory limits of a single 40GB GPU. Compared to streaming methods, which trade fidelity for bounded memory, KV-Fold maintains long-range retrieval while operating as a sequence of tractable forward passes. Overall, our results show that frozen pretrained transformers already support a stable form of KV-cache recurrence, providing a practical route to long-context inference without architectural changes or training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces KV-Fold, a training-free long-context inference protocol that treats the KV cache as the accumulator in a left fold over sequence chunks. At each step the model processes the next chunk conditioned on the accumulated cache, appends the new keys and values, and passes the enlarged cache forward. The central empirical claim is that the induced recurrence is stable: per-step drift rises briefly then saturates into a plateau insensitive to precision (10,000x range) and chunk size, yielding 100% exact-match retrieval on needle-in-a-haystack benchmarks for contexts up to 128K tokens and 511 steps on Llama-3.1-8B while remaining within single-GPU memory limits.
Significance. If the stability generalizes, the result would be significant: it demonstrates that frozen pretrained transformers already support a practical, parameter-free form of KV-cache recurrence for long-context inference without architectural modification or retraining. The simplicity of the left-fold construction, the reported plateau across model families, and the contrast with fidelity-sacrificing streaming methods are strengths. The absence of invented entities or fitted parameters further supports reproducibility.
major comments (2)
- [Experiments / Abstract] The evaluation establishing 100% exact-match retrieval and the drift plateau is confined to needle-in-a-haystack retrieval (Abstract and Experiments section). This task permits the model to attend primarily to a single distant token while largely ignoring the remainder of the cache. No measurements are reported on tasks that require full-history integration at every generation step (e.g., summarization, LongBench-style multi-hop QA, or generative reasoning), leaving open whether the observed plateau is an artifact of sparse retrieval attention patterns rather than a general property of the recurrence.
- [Method / Experiments] The manuscript refers to 'per-step drift' and its saturation into a plateau but does not specify the quantitative metric (e.g., hidden-state L2 distance, attention entropy, output-token divergence, or cache-value deviation). Without this definition or accompanying measurements of attention entropy or hidden-state evolution on non-retrieval tasks, it is impossible to determine whether the plateau indicates genuine stability or merely insensitivity of the chosen proxy under retrieval conditions.
minor comments (2)
- [Method] The description of the KV-cache concatenation primitive and its reuse as chunk-to-chunk recurrence would benefit from an explicit algorithmic listing (e.g., pseudocode) showing the exact conditioning and append steps.
- [Experiments] The paper should clarify the precise protocol for measuring 'exact-match retrieval' across the 152 trials (token position, prompt template, and success criterion) to allow independent reproduction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below, clarifying the scope of our claims and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments / Abstract] The evaluation establishing 100% exact-match retrieval and the drift plateau is confined to needle-in-a-haystack retrieval (Abstract and Experiments section). This task permits the model to attend primarily to a single distant token while largely ignoring the remainder of the cache. No measurements are reported on tasks that require full-history integration at every generation step (e.g., summarization, LongBench-style multi-hop QA, or generative reasoning), leaving open whether the observed plateau is an artifact of sparse retrieval attention patterns rather than a general property of the recurrence.
Authors: We acknowledge that the primary empirical results focus on needle-in-a-haystack retrieval, a standard benchmark for long-context information preservation. This task directly tests whether information from arbitrary positions remains accessible after many folding steps, which is the core requirement for the claimed stability of the KV-cache recurrence. The consistent 100% exact-match across 152 trials and up to 511 steps indicates that the accumulated cache does not degrade in a way that prevents retrieval, even as the model must locate the needle amid distractors. We agree that tasks demanding dense, step-by-step integration of the full history (such as summarization or multi-hop QA) would provide stronger evidence of generality. Since our current experiments do not include such tasks, we will revise the manuscript to explicitly state this limitation in the Experiments and Discussion sections and suggest it as an avenue for future work. No new experiments will be added in this revision. revision: partial
-
Referee: [Method / Experiments] The manuscript refers to 'per-step drift' and its saturation into a plateau but does not specify the quantitative metric (e.g., hidden-state L2 distance, attention entropy, output-token divergence, or cache-value deviation). Without this definition or accompanying measurements of attention entropy or hidden-state evolution on non-retrieval tasks, it is impossible to determine whether the plateau indicates genuine stability or merely insensitivity of the chosen proxy under retrieval conditions.
Authors: We apologize for the lack of an explicit definition of 'per-step drift' in the current manuscript. The term describes the observed deviation in model behavior (manifested through retrieval accuracy and numerical sensitivity) as the cache is iteratively folded; the plateau is evidenced by retrieval remaining at 100% exact match and by the result being insensitive to a 10,000x precision range. To resolve the ambiguity, we will add a precise definition and quantitative description of the drift metric in a new subsection of the Method section in the revised manuscript. This will include the specific proxy used in our experiments and any supporting measurements that can be reported without new runs. revision: yes
Circularity Check
No circularity: empirical stability of KV-Fold shown directly via measurements
full rationale
The paper introduces KV-Fold as a simple, training-free protocol that reuses standard KV-cache concatenation for chunk-wise recurrence. Its central claim—that frozen transformers exhibit stable per-step drift that saturates into a plateau—is supported solely by direct experimental observations (drift curves, precision insensitivity, 100% needle retrieval up to 128K/511 steps). No equations, fitted parameters, or uniqueness theorems are presented; there is no derivation that reduces the result to its own inputs by construction. References to prior concatenation primitives are external setup, not load-bearing self-citations that justify the stability finding. The protocol and its measured behavior are independent of any circular loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Concatenated KV cache from prior chunks can be used directly as a prefix for the current chunk without any model modification or fine-tuning.
Reference graph
Works this paper leans on
-
[1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin. Attention Is All You Need.NeurIPS, 2017
work page 2017
-
[2]
J. Su, Y . Lu, S. Pan, A. Murtadha, B. Wen, Y . Liu. RoFormer: Enhanced Transformer with Rotary Position Embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[3]
Y . Tay, M. Dehghani, D. Bahri, D. Metzler. Efficient Transformers: A Survey.ACM Computing Surveys, 55(6):109:1 to 109:28, 2022
work page 2022
-
[4]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, C. Ré. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.NeurIPS, 2022
work page 2022
-
[5]
T. Dao. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning.ICLR, 2024
work page 2024
-
[6]
H. Liu, M. Zaharia, P. Abbeel. Ring Attention with Blockwise Transformers for Near-Infinite Context. ICLR, 2024
work page 2024
-
[7]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, I. Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention.SOSP, 2023. 10
work page 2023
-
[8]
Latent collaboration in multi-agent systems
Y . Zou, et al. LatentMAS: KV-Cache Communication for Lightweight Multi-Agent Systems. arXiv:2511.20639, 2025
-
[9]
G. Xiao, Y . Tian, B. Chen, S. Han, M. Lewis. Efficient Streaming Language Models with Attention Sinks. ICLR, 2024
work page 2024
-
[10]
C. Han, Q. Wang, H. Peng, W. Xiong, Y . Chen, H. Ji, S. Wang. LM-Infinite: Zero-Shot Extreme Length Generalization for Large Language Models.NAACL, 2024
work page 2024
- [11]
-
[12]
Z. Liu, A. Desai, F. Liao, W. Wang, V . Xie, Z. Xu, A. Kyrillidis, A. Shrivastava. Scissorhands: Exploiting the Persistence of Importance Hypothesis for LLM KV Cache Compression at Test Time.NeurIPS, 2023
work page 2023
-
[13]
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, D. Chen. SnapKV: LLM Knows What You are Looking for Before Generation.arXiv:2404.14469, 2024
work page internal anchor Pith review arXiv 2024
-
[14]
Z. Cai, Y . Zhang, B. Gao, Y . Liu, T. Liu, K. Lu, W. Xiong, Y . Dong, B. Chang, J. Hu, W. Xiao. PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling.arXiv:2406.02069, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
S. Ge, Y . Zhang, L. Liu, M. Zhang, J. Han, J. Gao. Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs.ICLR, 2024
work page 2024
-
[16]
Z. Liu, J. Yuan, H. Jin, S. Zhong, Z. Xu, V . Braverman, B. Chen, X. Hu. KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache.ICML, 2024
work page 2024
- [17]
- [18]
-
[19]
S. Chen, S. Wong, L. Chen, Y . Tian. Extending Context Window of Large Language Models via Positional Interpolation.arXiv:2306.15595, 2023
work page internal anchor Pith review arXiv 2023
-
[20]
B. Peng, J. Quesnelle, H. Fan, E. Shippole. YaRN: Efficient Context Window Extension of Large Language Models.ICLR, 2024
work page 2024
-
[21]
Y . Ding, L. L. Zhang, C. Zhang, Y . Xu, N. Shang, J. Xu, F. Yang, M. Yang. LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens.ICML, 2024
work page 2024
-
[22]
Z. Dai, Z. Yang, Y . Yang, J. Carbonell, Q. V . Le, R. Salakhutdinov. Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.ACL, 2019
work page 2019
-
[23]
J. W. Rae, A. Potapenko, S. M. Jayakumar, T. P. Lillicrap. Compressive Transformers for Long-Range Sequence Modelling.ICLR, 2020
work page 2020
-
[24]
Y . Wu, M. N. Rabe, D. Hutchins, C. Szegedy. Memorizing Transformers.ICLR, 2022
work page 2022
-
[25]
A. Bulatov, Y . Kuratov, M. S. Burtsev. Recurrent Memory Transformer.NeurIPS, 2022
work page 2022
-
[26]
D. Hutchins, I. Schlag, Y . Wu, E. Dyer, B. Neyshabur. Block-Recurrent Transformers.NeurIPS, 2022
work page 2022
- [27]
-
[28]
T. Munkhdalai, M. Faruqui, S. Gopal. Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention.arXiv:2404.07143, 2024
-
[29]
Longformer: The Long-Document Transformer
I. Beltagy, M. E. Peters, A. Cohan. Longformer: The Long-Document Transformer.arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
- [30]
-
[31]
Generating Long Sequences with Sparse Transformers
R. Child, S. Gray, A. Radford, I. Sutskever. Generating Long Sequences with Sparse Transformers. arXiv:1904.10509, 2019. 11
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[32]
A. Katharopoulos, A. Vyas, N. Pappas, F. Fleuret. Transformers are RNNs: Fast Autoregressive Trans- formers with Linear Attention.ICML, 2020
work page 2020
-
[33]
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, D. Belanger, L. Colwell, A. Weller. Rethinking Attention with Performers.ICLR, 2021
work page 2021
-
[34]
A. Gu, K. Goel, C. Ré. Efficiently Modeling Long Sequences with Structured State Spaces.ICLR, 2022
work page 2022
-
[35]
A. Gu, T. Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces.COLM, 2024
work page 2024
-
[36]
G. Kamradt. Needle In A Haystack: Pressure Testing LLMs.GitHub, 2023. https://github.com/ gkamradt/LLMTest_NeedleInAHaystack
work page 2023
- [37]
-
[38]
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y . Dong, J. Tang, J. Li. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding.ACL, 2024
work page 2024
-
[39]
A. Yang, B. Yang, B. Hui, B. Zheng, B. Yu, et al. (Qwen Team). Qwen2.5 Technical Report. arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
N. Muennighoff, L. Soldaini, D. Groeneveld, K. Lo, J. Morrison, S. Min, W. Shi, P. Walsh, O. Tafjord, N. Lambert, Y . Gu, S. Arora, A. Bhagia, D. Schwenk, D. Wadden, A. Wettig, B. Hui, T. Dettmers, D. Kiela, A. Farhadi, N. A. Smith, P. W. Koh, A. Singh, H. Hajishirzi. OLMoE: Open Mixture-of-Experts Language Models.ICLR, 2025
work page 2025
-
[41]
A. Grattafiori, A. Dubey, A. Jauhri, et al. (Meta AI). The Llama 3 Herd of Models.arXiv:2407.21783, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.