Recognition: no theorem link
MEME: Multi-entity & Evolving Memory Evaluation
Pith reviewed 2026-05-13 05:07 UTC · model grok-4.3
The pith
Current memory systems for LLM agents fail at reasoning over dependencies between multiple evolving entities, even when static retrieval works.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
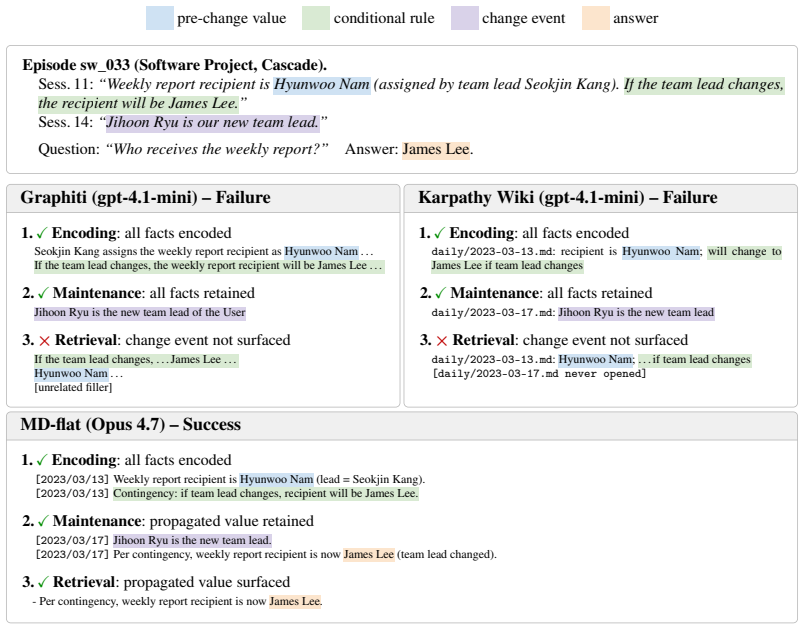
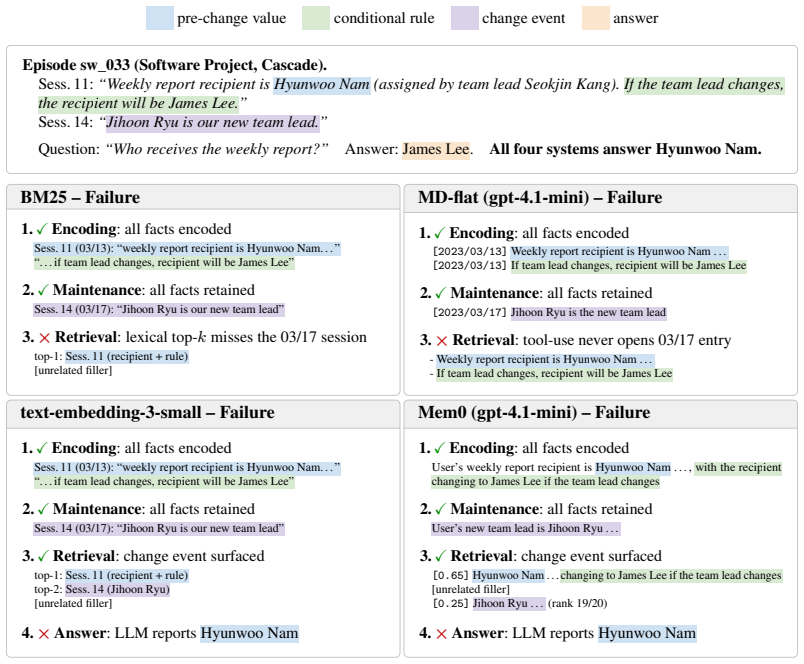
All tested memory systems, regardless of paradigm, prove unable to perform dependency reasoning when multiple entities change state across sessions; Cascade and Absence tasks expose average accuracies of 3% and 1% while static retrieval remains adequate.
What carries the argument
The MEME benchmark's six tasks, especially the dependency-reasoning tasks Cascade and Absence, which require tracking how updates to one entity affect others and how missing information propagates.
If this is right
- Standard memory paradigms cannot scale to agent environments that require tracking dependencies across entities.
- Common engineering fixes such as prompt tuning or stronger base models leave the core failure untouched.
- Closing the gap currently demands configurations whose cost grows by an order of magnitude.
- Benchmarks limited to single-entity updates miss the dominant failure mode in longer-lived agent settings.
Where Pith is reading between the lines
- Agent designers may need hybrid memory that combines vector retrieval with explicit symbolic tracking of entity relationships.
- The cost-performance trade-off shown here could limit deployment of autonomous agents in domains that require reliable long-term memory.
- Extending the benchmark to include real-world interaction logs would test whether the controlled episodes generalize.
Load-bearing premise
The six tasks and 100 controlled episodes capture the essential difficulties that appear in real persistent multi-entity environments.
What would settle it
A practical, low-cost memory system that reaches substantially higher accuracy on Cascade and Absence tasks under default conditions would show the collapse is not inherent to current approaches.
Figures



























read the original abstract
LLM-based agents increasingly operate in persistent environments where they must store, update, and reason over information across many sessions. While prior benchmarks evaluate only single-entity updates, MEME defines six tasks spanning the full space defined by the multi-entity and evolving axes, including three not scored by prior work: Cascade and Absence (dependency reasoning) and Deletion (post-removal state). Evaluating six memory systems spanning three memory paradigms on 100 controlled episodes, we find that all systems collapse on dependency reasoning under the default configuration (Cascade: 3%, Absence: 1% in average accuracy) despite adequate static retrieval performance. Prompt optimization, deeper retrieval, reduced filler noise, and most stronger LLMs fail to close this gap. Only a file-based agent paired with Claude Opus 4.7 as its internal LLM partially closes the gap, but at ~70x the baseline cost, indicating closure currently depends on configurations that are not practical at scale. Code and data are available on the project page: https://seokwonjung-jay.github.io/meme-eval/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MEME, a benchmark for LLM-agent memory systems in persistent multi-entity and evolving environments. It defines six tasks spanning the multi-entity and evolving axes (including three novel tasks: Cascade and Absence for dependency reasoning, and Deletion for post-removal state), evaluates six memory systems across three paradigms on 100 controlled episodes, and reports that all systems collapse on dependency reasoning (Cascade: 3%, Absence: 1% average accuracy) despite adequate static retrieval. Prompt optimization, deeper retrieval, reduced filler noise, and most stronger LLMs fail to close the gap; only a high-cost file-based agent with Claude Opus 4.7 shows partial improvement.
Significance. If the 100 episodes and task definitions accurately instantiate the core difficulties of real-world persistent multi-entity agent environments, the work would be significant in demonstrating a systematic limitation of current memory paradigms on dependency reasoning and in motivating new architectures. The public release of code and data is a clear strength for reproducibility.
major comments (3)
- [Abstract] Abstract: The central empirical claim that all six systems collapse on dependency reasoning (Cascade 3%, Absence 1%) is load-bearing, yet the manuscript supplies no details on episode construction, statistical variance across the 100 episodes, exact definitions of the six memory systems, or the quantitative criteria used to establish 'adequate static retrieval performance'. These omissions prevent assessment of whether the reported numbers are robust or sensitive to implementation choices.
- [Abstract / Task definitions] The interpretation that current memory paradigms fundamentally fail at dependency reasoning requires that the Cascade, Absence, and Deletion tasks (and their 100 controlled episodes) represent the core challenges agents encounter in naturalistic multi-entity evolving settings. The manuscript provides no external validation—such as comparison against real agent interaction traces, expert review of dependency-chain realism, or sensitivity analysis to filler noise and update patterns—to rule out the possibility that the observed collapse is an artifact of the benchmark design.
- [Abstract / Evaluation] The claim that prompt optimization, deeper retrieval, reduced filler noise, and most stronger LLMs 'fail to close this gap' is presented without reporting the specific interventions tested, their quantitative effects on Cascade/Absence accuracy, or the exact set of stronger LLMs evaluated. This makes it impossible to determine the scope of the failure or whether the gap is truly unbridgeable within practical configurations.
minor comments (2)
- [Abstract] The abstract refers to 'three memory paradigms' without naming them; an explicit list in the introduction or a table summarizing the six systems would improve clarity.
- [Abstract] The paper states that code and data are available on the project page; confirming that the repository includes the exact episode generator, task definitions, and evaluation scripts would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that all six systems collapse on dependency reasoning (Cascade 3%, Absence 1%) is load-bearing, yet the manuscript supplies no details on episode construction, statistical variance across the 100 episodes, exact definitions of the six memory systems, or the quantitative criteria used to establish 'adequate static retrieval performance'. These omissions prevent assessment of whether the reported numbers are robust or sensitive to implementation choices.
Authors: We agree the abstract is too concise and omits key context. The full manuscript details episode construction and the 100 controlled episodes in the benchmark design section, reports statistical variance (standard deviations) alongside the accuracy figures in the evaluation tables, defines the six memory systems in the systems under test section, and specifies the criteria for adequate static retrieval based on control-task performance in the results analysis. In the revision we will expand the abstract with brief descriptions of episode construction, variance reporting, system definitions, and the static-retrieval criterion. revision: yes
-
Referee: [Abstract / Task definitions] The interpretation that current memory paradigms fundamentally fail at dependency reasoning requires that the Cascade, Absence, and Deletion tasks (and their 100 controlled episodes) represent the core challenges agents encounter in naturalistic multi-entity evolving settings. The manuscript provides no external validation—such as comparison against real agent interaction traces, expert review of dependency-chain realism, or sensitivity analysis to filler noise and update patterns—to rule out the possibility that the observed collapse is an artifact of the benchmark design.
Authors: The tasks were constructed to isolate the multi-entity and evolving axes defined in the problem formulation section, with controlled episodes that systematically vary dependency chains, filler content, and update patterns. We did not conduct external validation against real agent traces or expert review of realism. We will add an explicit limitations paragraph discussing this design choice and include any available sensitivity results on filler noise and update patterns. revision: partial
-
Referee: [Abstract / Evaluation] The claim that prompt optimization, deeper retrieval, reduced filler noise, and most stronger LLMs 'fail to close this gap' is presented without reporting the specific interventions tested, their quantitative effects on Cascade/Absence accuracy, or the exact set of stronger LLMs evaluated. This makes it impossible to determine the scope of the failure or whether the gap is truly unbridgeable within practical configurations.
Authors: The abstract summarizes findings from the ablation experiments. In the revision we will add a concise table or paragraph reporting the specific interventions tested, their measured effects on Cascade and Absence accuracy, and the exact set of stronger LLMs evaluated, so readers can assess the scope of the observed gap. revision: yes
- External validation of task realism via real agent interaction traces or expert review, which was not performed in the current study.
Circularity Check
No circularity: direct empirical benchmark with measured results
full rationale
The paper is a controlled empirical evaluation that defines six tasks (Cascade, Absence, Deletion, etc.) and measures accuracy of six memory systems across 100 episodes. No derivation chain, equations, or first-principles predictions exist; reported numbers (e.g., Cascade 3%, Absence 1%) are direct experimental outputs, not quantities fitted or renamed from inputs. Task construction and episode design are explicit and independent of the measured outcomes. No self-citations are invoked to justify core claims, and no ansatz or uniqueness theorem reduces the results to prior author work. The evaluation is self-contained against its own benchmark definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Chhikara, P., Khant, D., Aryan, S., Singh, T., and Yadav, D. Mem0: Building production-ready AI agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Cohen, J. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
work page 1960
-
[3]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropolitansky, D., Ness, R. O., and Larson, J. From local to global: A graph RAG approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B. RULER: What’s the real context size of your long-context language models?arXiv preprint arXiv:2404.06654, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Evaluating memory in LLM agents via incremental multi-turn interactions
Hu, Y ., Wang, Y ., and McAuley, J. Evaluating memory in LLM agents via incremental multi-turn interactions. InThe Fourteenth International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[6]
Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., and Grave, E. Unsupervised dense information retrieval with contrastive learning.Transactions on Machine Learning Research, 2022
work page 2022
-
[7]
Karpathy, A. LLM knowledge base. https://gist.github.com/karpathy/ 442a6bf555914893e9891c11519de94f, 2026
work page 2026
-
[8]
T., Moazam, H., Miller, H., Zaharia, M., and Potts, C
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., Vardhamanan, S., Haq, S., Sharma, A., Joshi, T. T., Moazam, H., Miller, H., Zaharia, M., and Potts, C. DSPy: Compiling declarative lan- guage model calls into self-improving pipelines. InThe Twelfth International Conference on Learning Representations (ICLR), 2024
work page 2024
- [9]
-
[10]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Maharana, A., Lee, D.-H., Tulyakov, S., Bansal, M., Barbieri, F., and Fang, Y . Evaluating very long-term conversational memory of LLM agents.arXiv preprint arXiv:2402.17753, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Modarressi, A., Deilamsalehy, H., Dernoncourt, F., Bui, T., Rossi, R. A., Yoon, S., and Schütze, H. NoLiMa: Long-context evaluation beyond literal matching. InProceedings of the 42nd International Conference on Machine Learning (ICML), 2025
work page 2025
-
[12]
MemGPT: Towards LLMs as Operating Systems
Packer, C., Wooders, S., Lin, K., Fang, V ., Patil, S. G., Stoica, I., and Gonzalez, J. E. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Rasmussen, P., Paliychuk, P., Beauvais, T., Ryan, J., and Chalef, D. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
ShareGPT52K.https://huggingface.co/datasets/RyokoAI/ShareGPT52K, 2023
RyokoAI. ShareGPT52K.https://huggingface.co/datasets/RyokoAI/ShareGPT52K, 2023
work page 2023
-
[15]
MemBench: Towards more comprehensive evaluation on the memory of LLM-based agents
Tan, H., Zhang, Z., Ma, C., Chen, X., Dai, Q., and Dong, Z. MemBench: Towards more comprehensive evaluation on the memory of LLM-based agents. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 19336–19352, 2025
work page 2025
-
[16]
LongMemEval: Benchmarking chat assistants on long-term interactive memory
Wu, D., Wang, H., Yu, W., Zhang, Y ., Chang, K.-W., and Yu, D. LongMemEval: Benchmarking chat assistants on long-term interactive memory. InThe Thirteenth International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[17]
Zhang, Z., Bo, X., Ma, C., Li, R., Chen, X., Dai, Q., Zhu, J., Dong, Z., and Wen, J.-R. A survey on the memory mechanism of large language model based agents.arXiv preprint arXiv:2404.13501, 2024
-
[18]
W., Salakhutdinov, R., and Manning, C
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W. W., Salakhutdinov, R., and Manning, C. D. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018
work page 2018
-
[19]
Zhong, Z., Wu, Z., Manning, C. D., Potts, C., and Chen, D. MQuAKE: Assessing knowledge editing in language models via multi-hop questions. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
work page 2023
-
[20]
Cohen, R., Biran, E., Yoran, O., Globerson, A., and Geva, M. Evaluating the ripple effects of knowledge editing in language models.Transactions of the Association for Computational Linguistics, 12:283–298, 2024. 10
work page 2024
-
[21]
Trivedi, H., Balasubramanian, N., Khot, T., and Sabharwal, A. MuSiQue: Multihop questions via single hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[22]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[23]
{target_fact} — this depends on where {source_entity_phrase}; if I move, this would change
Zheng, L., Chiang, W.-L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 11 A Operational Costs We report token usage at three pipeline stages:Ingest(LL...
work page 2023
-
[24]
Enumerate all possible gold-fact sentences by applying each entity’s value pool to its fact template
-
[25]
For each gold fact, retrieve the top-K=10candidate fillers using a hybrid of BM25 lexical scoring andtext-embedding-3-smalldense similarity
-
[26]
The judge flags three conflict types:A(CONTRADICTION),B(ALTERNATIVE), andC (ENTITY_CONFUSION)
Judge each (gold fact, filler) pair with GPT-4o-mini using the prompt in Section D.6. The judge flags three conflict types:A(CONTRADICTION),B(ALTERNATIVE), andC (ENTITY_CONFUSION). Fillers flagged for any type are removed from the pool
-
[27]
At episode assembly time, a keyword-based blocklist derived from the current episode’s gold entities acts as a final safety net. 14 Assistant:“Hi! How can I help you today?” User:“My hobby is pottery. I’ve been getting into it more lately. Do you know any good techniques for beginners?” Assistant:“One effective technique for beginners is hand-building, wh...
-
[28]
Each fact must include its entity keyword (e.g., “My health condition is...”, “My financial goal is...”). The entity concept must appear in your message
-
[29]
If a fact mentions a dependency (“depends on”, “determined by”, “if X changes”), you MUST preserve the full dependency language including the conditional part. The reader must understand that if the source changes, the target would change too. Do NOT weaken “depends on X; if X changes, this would change” to just “tied to X” or “since we use X”
-
[30]
If” (conditional), use ONLY “will
If a fact starts with “If” (conditional), use ONLY “will” as the modal: “If X changes, Y will be Z”. NEVER use “would/might/probably/consider”. NEVER state it as accomplished (“I switched to Z”)
-
[31]
I don’t have personal experiences
If a fact is marked with [CHANGED], state the new value as a definitive current fact. Do NOT hedge or speculate. You are a HUMAN user, not an AI. Never say anything that implies you are an AI, a language model, or that you have a training data cutoff. Never repeat a previous message verbatim. Each message must be unique. When ALL facts have been conveyed ...
-
[32]
VERBALIZATION ACCURACY Is the gold fact’s value present in the conversation (exactly or close paraphrase)?
-
[33]
IF-THEN CONDITIONAL FORM (only for facts with is_if_then=true) Must contain “if” conditional structure. Trigger entity (dependency_source) must be explicitly mentioned. Modal must be “will” (not “would/might/probably”) → flag WEAK_MODAL. Must NOT be stated as accomplished fact→flag CONDITIONAL_VIOLATED
-
[34]
ENTITY KEYWORD PRESENCE The question asks about an entity using certain words (e.g., “What’s my financial goal?”). Those words or a natural synonym must appear in the conversation where the fact is introduced. FAIL if entity concept never mentioned (e.g., “I’m paying off debt” without “financial goal”)
-
[35]
CASCADE-U DEPENDENCY (only for facts with has_dependency=true AND is_if_then=false) Is the causal link STRONGLY explicit? The message must contain language like “depends on”, “determined by”, or “if X changes, Y would change”. FAIL if dependency is only implied (“since we use X”, “tied to X”) rather than explicitly conditional (“depends on X; if X changes...
-
[36]
Yes — ” prefix? (flag PREFIX_ISSUE) Output JSON array of issues: {“entity
GOLD ANSWER FORMAT Does before-delete gold have “Yes — ” prefix? (flag PREFIX_ISSUE) Output JSON array of issues: {“entity”: “...”, “fact_index”: N, “check”: “VERBALIZATION|IF_THEN|KEYWORD|CASCADE_U_DEP|GOLD_FORMAT”, “severity”: “HIGH|MEDIUM|LOW”, “issue”: “brief description”} Severity: HIGH = makes task unsolvable. MEDIUM = may cause false pass/fail. LOW...
work page 2023
-
[37]
on all six main-table systems and 100 episodes; internal LLM held at gpt-4.1-mini. Trivial-pass filtering applied to Cascade, Absence, Deletion.Boldmarks the best per task column. System Answering LLM ER Agg Tr Del Cas Abs Overall BM25 gpt-4.1-mini1.000.05 0.160.270.02 0.00 0.25 Sonnet 4 0.70 0.09 0.11 0.19 0.01 0.12 0.20 text-embedding-3-small gpt-4.1-mi...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.