Recognition: no theorem link
Letting the neural code speak: Automated characterization of monkey visual neurons through human language
Pith reviewed 2026-05-13 02:05 UTC · model grok-4.3
The pith
Natural language descriptions capture the selectivity of most neurons in macaque V1 and V4.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
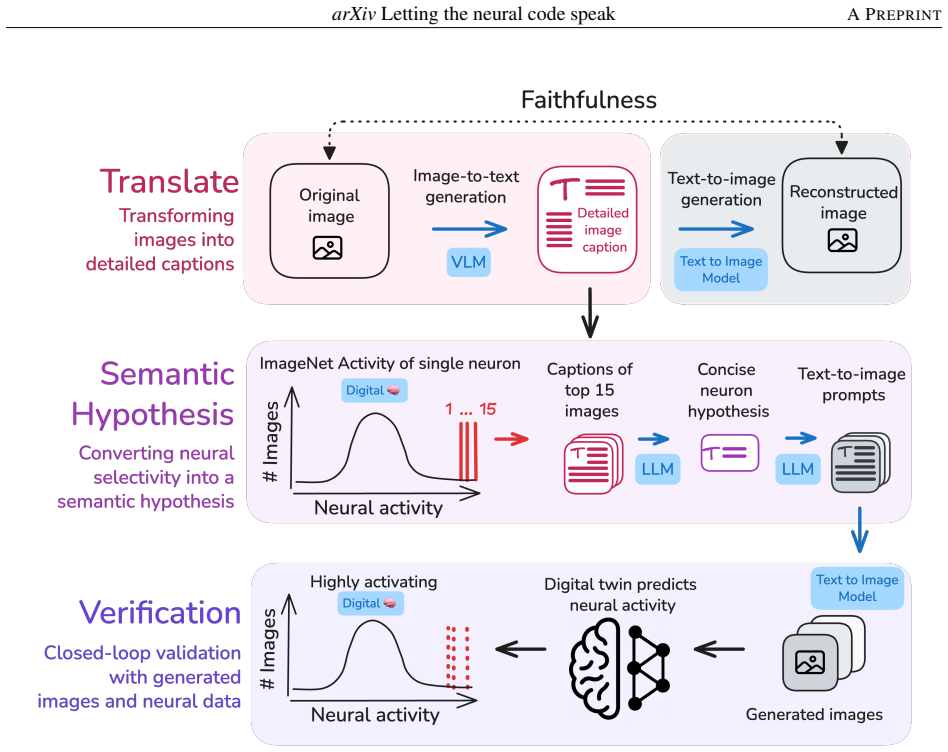
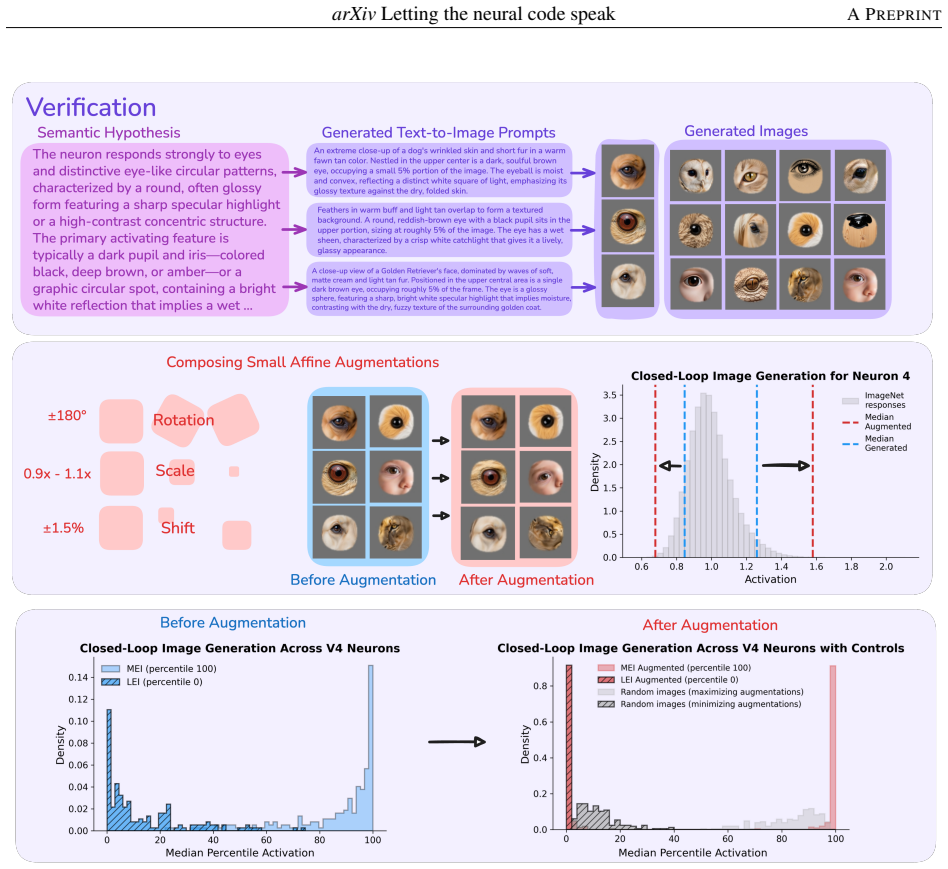
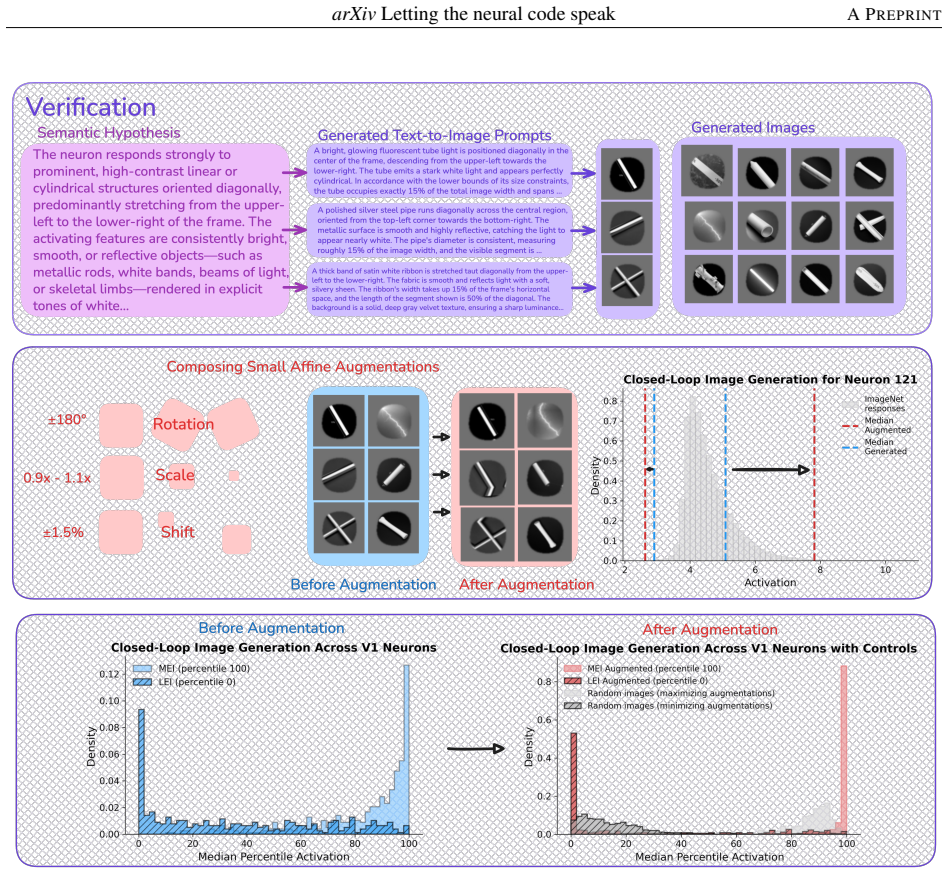
Across macaque V1 and V4, the selectivity of most neurons is captured by concise, verifiable semantic descriptions. Using digital twins, the method translates high- and low-activating images into dense captions, generates a semantic hypothesis and synthesized images, and verifies the hypothesis in silico. In V4, images from activating and suppressing hypotheses drove 96.1% of neurons above the 95th and 97.6% below the 5th percentile of natural-image responses, respectively.
What carries the argument
The closed-loop framework that converts neuron responses into language hypotheses via digital twins, then renders those hypotheses back into images for in-silico verification.
If this is right
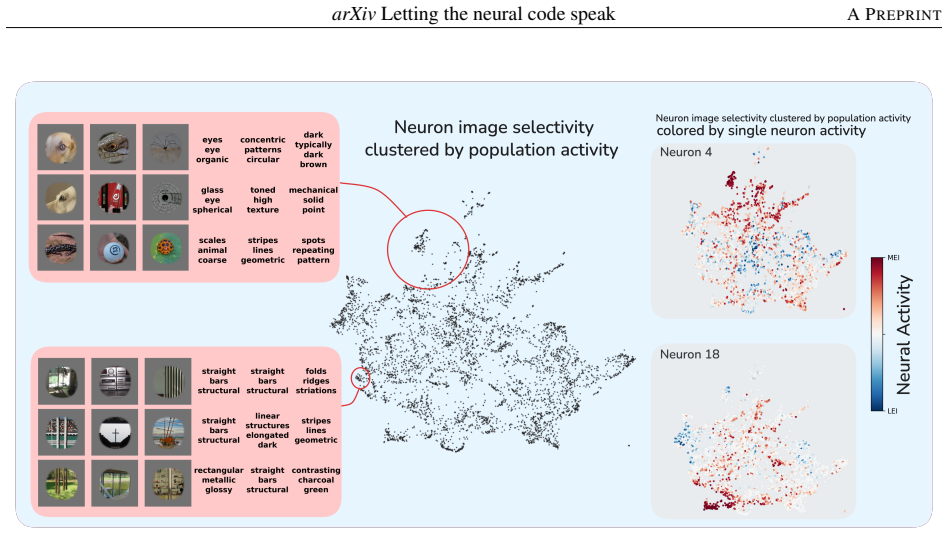
- V4 neurons respond to conjunctions of form, color, and texture that language can name, while V1 responses align more with oriented edges and spatial frequency.
- Representational similarity analysis shows vision embeddings align more closely with neural activity than language embeddings, yet rendering hypotheses back to images recovers much of the lost alignment.
- The method produces testable predictions at scale without requiring new biological experiments for initial hypothesis generation.
- Linguistic compression of neural selectivity is lossy but remains semantically faithful for verification purposes.
Where Pith is reading between the lines
- The same language-based loop could be applied to areas beyond V4 where no simple mathematical models exist, potentially revealing higher-order feature combinations.
- If the digital twins generalize well, this framework might accelerate discovery by letting researchers query neural populations with natural language rather than exhaustive image searches.
- The partial mismatch between language and vision embeddings suggests that some visual features driving neurons may resist concise verbal description and require additional modalities for full capture.
Load-bearing premise
The digital-twin models of V1 and V4 accurately reproduce how real biological neurons respond to the novel synthetic images generated from the language hypotheses.
What would settle it
Presenting the language-generated activating and suppressing images to real V4 neurons and finding that they fail to drive responses above the 95th or below the 5th percentile of natural images would falsify the claim that semantic descriptions capture selectivity.
Figures


read the original abstract
Understanding what individual neurons encode is a core question in neuroscience. In primary visual cortex (V1), mathematical models (e.g., Gabor functions) capture neural selectivity, but no comparable framework exists for higher areas. We show that natural language can fill this role: across macaque V1 and V4, the selectivity of most neurons is captured by concise, verifiable semantic descriptions. Using digital twins of V1 and V4, we develop a closed-loop framework that translates each neuron's high- and low-activating images into dense captions, generates a semantic hypothesis and synthesized images, and verifies the hypothesis in silico. Descriptions range from oriented edges and spatial frequency in V1 to conjunctions of form, color, and texture in V4. In V4, images generated from activating and suppressing hypotheses drove 96.1% of neurons above the 95th and 97.6% below the 5th percentile of natural-image responses, respectively (vs. ~10\% for random images); V1 activation results matched V4, while V1 suppression was less describable in language. Representational similarity analysis reveals partial alignment between neural activity, vision embeddings, and language embeddings, with vision most aligned to neural activity; alignment lost in the text bottleneck is recovered when hypotheses are rendered back into images, showing that linguistic compression is lossy yet semantically faithful. Together, these results show that combining generative models with neural digital twins enables interpretable, testable descriptions of neural function at scale, toward agentic scientific discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a closed-loop framework using digital twins of macaque V1 and V4 neurons to automatically generate concise natural-language semantic descriptions of each neuron's selectivity. High- and low-activating natural images are captioned, a semantic hypothesis is formed via language models, new images are synthesized from the hypothesis, and the hypothesis is verified in silico by querying the digital twins; the authors report that activating images drive 96.1% of V4 neurons above the 95th percentile of natural-image responses and suppressing images drive 97.6% below the 5th percentile (versus ~10% for random images), with comparable activation but weaker suppression results in V1. Representational similarity analysis is used to compare neural activity, vision embeddings, and language embeddings.
Significance. If the digital twins prove reliable on the synthetic images, the work would offer a scalable route to interpretable characterizations of visual selectivity in higher areas where Gabor-style models are inadequate, and would illustrate how generative language and image models can be combined with neural digital twins for automated hypothesis generation and testing. The partial alignment results between modalities, with vision closest to neural activity and recovery upon re-rendering, provide additional insight into semantic compression.
major comments (3)
- [Results section describing V4 activation and suppression verification] The central performance claims (96.1% activation and 97.6% suppression in V4) rest entirely on in-silico queries of the digital twins applied to LLM-generated synthetic images that lie outside the natural-image distribution on which the twins were trained. No section reports direct biological recordings on these novel images, nor any quantitative metric (e.g., held-out correlation, response-distribution match, or generalization error) confirming that twin predictions remain faithful for the particular conjunctions of form, color, and texture produced by the language model.
- [Methods section on digital-twin construction] The manuscript provides no quantitative details on the digital-twin models themselves: number of neurons recorded and modeled, training data composition, architecture, regularization, or performance on held-out natural images. Without these, the reliability of the in-silico verification step cannot be assessed, and the reported percentages may reflect model idiosyncrasies rather than biological selectivity.
- [Results section on representational similarity analysis] The representational similarity analysis claims that 'alignment lost in the text bottleneck is recovered when hypotheses are rendered back into images' and that this demonstrates semantic faithfulness. The specific distance metrics, number of stimuli, statistical controls, and comparison to null models are not detailed enough to evaluate whether the recovery is attributable to semantic content rather than low-level image statistics.
minor comments (2)
- [Abstract] The abstract states 'vs. ~10% for random images' without specifying the exact percentile thresholds, number of random images, or statistical test; this comparison should be made explicit.
- [Figure captions] Figure legends and captions should explicitly state the number of neurons, number of images per condition, and exact percentile definitions used for the activation and suppression results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, providing clarifications and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Results section describing V4 activation and suppression verification] The central performance claims (96.1% activation and 97.6% suppression in V4) rest entirely on in-silico queries of the digital twins applied to LLM-generated synthetic images that lie outside the natural-image distribution on which the twins were trained. No section reports direct biological recordings on these novel images, nor any quantitative metric (e.g., held-out correlation, response-distribution match, or generalization error) confirming that twin predictions remain faithful for the particular conjunctions of form, color, and texture produced by the language model.
Authors: We acknowledge that the verification relies on in-silico queries and that direct biological recordings on the LLM-generated synthetic images are not reported. The framework is intentionally designed for scalable automated testing via digital twins rather than exhaustive new recordings for each hypothesis. We will add quantitative validation metrics for the twins (held-out correlation and response-distribution statistics on natural images) and explicitly discuss the generalization assumption as a limitation, with suggestions for future wet-lab confirmation. revision: partial
-
Referee: [Methods section on digital-twin construction] The manuscript provides no quantitative details on the digital-twin models themselves: number of neurons recorded and modeled, training data composition, architecture, regularization, or performance on held-out natural images. Without these, the reliability of the in-silico verification step cannot be assessed, and the reported percentages may reflect model idiosyncrasies rather than biological selectivity.
Authors: We agree that these details are essential for assessing reliability. In the revised Methods section we will report the number of V1 and V4 neurons recorded and modeled, the size and composition of the natural-image training sets, the model architectures and regularization procedures, and performance metrics (e.g., held-out Pearson correlation and response-distribution match) on natural images. revision: yes
-
Referee: [Results section on representational similarity analysis] The representational similarity analysis claims that 'alignment lost in the text bottleneck is recovered when hypotheses are rendered back into images' and that this demonstrates semantic faithfulness. The specific distance metrics, number of stimuli, statistical controls, and comparison to null models are not detailed enough to evaluate whether the recovery is attributable to semantic content rather than low-level image statistics.
Authors: We will expand both the Methods and Results sections to specify the distance metrics (e.g., cosine similarity on normalized embeddings), the exact number of stimuli per comparison, the statistical controls employed, and the null-model procedures (including shuffled and low-level-statistic-matched controls). These additions will allow readers to confirm that the reported recovery reflects semantic rather than low-level image properties. revision: yes
Circularity Check
In-silico verification of semantic hypotheses is performed by querying digital twins fitted to the same neural data
specific steps
-
fitted input called prediction
[Abstract]
"Using digital twins of V1 and V4, we develop a closed-loop framework that translates each neuron's high- and low-activating images into dense captions, generates a semantic hypothesis and synthesized images, and verifies the hypothesis in silico. ... In V4, images generated from activating and suppressing hypotheses drove 96.1% of neurons above the 95th and 97.6% below the 5th percentile of natural-image responses, respectively (vs. ~10% for random images)"
The percentile-driving claims are computed by evaluating the synthesized images inside the digital twins. Because the twins are fitted to the same neural data used to identify the original high/low-activating images and to generate the hypotheses, the high success rates quantify agreement with the fitted model rather than an external measurement of biological selectivity.
full rationale
The paper's central quantitative result (96.1% and 97.6% of V4 neurons driven above/below response percentiles) is obtained by feeding LLM-generated synthetic images into digital-twin models whose parameters were fit to the original neural recordings. This makes the reported verification a measure of consistency inside the fitted model rather than an independent biological test, matching the fitted-input-called-prediction pattern. No other circular steps (self-citations, self-definitional equations, or imported uniqueness theorems) appear in the provided text.
Axiom & Free-Parameter Ledger
free parameters (2)
- Digital-twin model parameters
- Captioning and generation model hyperparameters
axioms (2)
- domain assumption Digital twins accurately predict responses to novel synthetic images outside the training distribution
- domain assumption Natural language is sufficiently expressive to capture the selectivity of V1 and V4 neurons
Reference graph
Works this paper leans on
-
[1]
Revisiting the Platonic Representation Hypothesis: An Aristotelian View , author=. 2026 , eprint=
work page 2026
-
[2]
Evolving images for visual neurons using a deep generative network reveals coding principles and neuronal preferences , author=. Cell , volume=. 2019 , publisher=
work page 2019
-
[3]
Interpreting the retinal neural code for natural scenes: From computations to neurons
Maheswaranathan, Niru and McIntosh, Lane T and Tanaka, Hidenori and Grant, Satchel and Kastner, David B and Melander, Joshua B and Nayebi, Aran and Brezovec, Luke E and Wang, Julia H and Ganguli, Surya and Baccus, Stephen A. Interpreting the retinal neural code for natural scenes: From computations to neurons. Neuron
-
[4]
Neural representational geometry underlies few-shot concept learning
Sorscher, Ben and Ganguli, Surya and Sompolinsky, Haim. Neural representational geometry underlies few-shot concept learning. Proc. Natl. Acad. Sci. U. S. A
-
[5]
Multimodal neurons in artificial neural networks , author=. Distill , volume=
-
[6]
Semantic reconstruction of continuous language from non-invasive brain recordings , author=. Nature Neuroscience , volume=. 2023 , publisher=
work page 2023
-
[7]
Proceedings of the National Academy of Sciences , volume=
The neural architecture of language: Integrative modeling converges on predictive processing , author=. Proceedings of the National Academy of Sciences , volume=
-
[8]
arXiv preprint arXiv:2510.02182 , year=
Uncovering semantic selectivity of latent groups in higher visual cortex with mutual information-guided diffusion , author=. arXiv preprint arXiv:2510.02182 , year=
-
[9]
Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=
Real-time segmentation of on-line handwritten arabic script , author=. Frontiers in Handwriting Recognition (ICFHR), 2014 14th International Conference on , pages=. 2014 , organization=
work page 2014
-
[10]
Jones, J. P. and Palmer, L. A. , journal=. An evaluation of the two-dimensional
-
[11]
Journal of the Optical Society of America A , volume=
Uncertainty relation for resolution in space, spatial frequency, and orientation optimized by two-dimensional visual cortical filters , author=. Journal of the Optical Society of America A , volume=
-
[12]
Emergence of simple-cell receptive field properties by learning a sparse code for natural images , author=. Nature , volume=. 1996 , publisher=
work page 1996
-
[13]
Annual Review of Neuroscience , volume=
Natural image statistics and neural representation , author=. Annual Review of Neuroscience , volume=. 2001 , publisher=
work page 2001
-
[14]
Quantitative analysis of cat retinal ganglion cell response to visual stimuli , author=. Vision Research , volume=. 1965 , publisher=
work page 1965
-
[15]
Journal of Neurophysiology , volume=
Coding visual images of objects in the inferotemporal cortex of the macaque monkey , author=. Journal of Neurophysiology , volume=
- [16]
-
[17]
Pasupathy, A. and Connor, C. E. , journal=. Population coding of shape in area. 2002 , publisher=
work page 2002
-
[18]
A cortical region consisting entirely of face-selective cells , author=. Science , volume=. 2006 , publisher=
work page 2006
-
[19]
Annual Review of Neuroscience , volume=
Mechanisms of face perception , author=. Annual Review of Neuroscience , volume=. 2010 , publisher=
work page 2010
-
[20]
Metamers of the ventral stream , author=. Nature Neuroscience , volume=. 2011 , publisher=
work page 2011
-
[21]
Underlying principles of visual shape selectivity in posterior inferotemporal cortex , author=. Nature Neuroscience , volume=. 2004 , publisher=
work page 2004
-
[22]
Cold Spring Harbor Symposia on Quantitative Biology , volume=
Representation of naturalistic image structure in the primate visual cortex , author=. Cold Spring Harbor Symposia on Quantitative Biology , volume=. 2014 , publisher=
work page 2014
-
[23]
Oliver, Michael and Winter, Michele and Dupré la Tour, Tom and Eickenberg, Michael and Gallant, Jack L. , journal=. A biologically-inspired hierarchical convolutional energy model predicts. 2024 , doi=
work page 2024
-
[24]
Nature Machine Intelligence , volume=
Better models of human high-level visual cortex emerge from natural language supervision with a large and diverse dataset , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[25]
Luo, Andrew and Henderson, Margot and Tarr, Michael J. and Wehbe, Leila , booktitle=
-
[26]
Wasserman, Navve and Cosarinsky, Matias and Golbari, Yuval and Oliva, Aude and Torralba, Antonio and Rott Shaham, Tamar and Irani, Michal , journal=. 2025 , month=
work page 2025
-
[27]
International Conference on Learning Representations (ICLR) , year=
Rethinking Language-Alignment in Human Visual Cortex with Syntax Manipulation and Word Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[28]
Nature Machine Intelligence , volume=
High-level visual representations in the human brain are aligned with large language models , author=. Nature Machine Intelligence , volume=. 2025 , publisher=
work page 2025
-
[29]
Invariant visual representation by single neurons in the human brain , author=. Nature , volume=. 2005 , publisher=
work page 2005
-
[30]
Proceedings of the National Academy of Sciences , volume=
Human single-neuron responses at the threshold of conscious recognition , author=. Proceedings of the National Academy of Sciences , volume=. 2008 , publisher=
work page 2008
-
[31]
Frontiers in Systems Neuroscience , volume=
Representational similarity analysis -- connecting the branches of systems neuroscience , author=. Frontiers in Systems Neuroscience , volume=. 2008 , publisher=
work page 2008
-
[32]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Interpretable convolutional neural networks , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Proceedings of the National Academy of Sciences , volume=
Understanding the role of individual units in a deep neural network , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
work page 2020
-
[34]
Proceedings of the European Conference on Computer Vision , pages=
Interpretable basis decomposition for visual explanation , author=. Proceedings of the European Conference on Computer Vision , pages=. 2018 , organization=
work page 2018
-
[35]
Proceedings of the National Academy of Sciences , volume=
Performance-optimized hierarchical models predict neural responses in higher visual cortex , author=. Proceedings of the National Academy of Sciences , volume=. 2014 , publisher=
work page 2014
-
[36]
The UK Biobank resource with deep phenotyping and genomic data
Bycroft, Clare and Freeman, Colin and Petkova, Desislava and Band, Gavin and Elliott, Lloyd T and Sharp, Kevin and Motyer, Allan and Vukcevic, Damjan and Delaneau, Olivier and O'Connell, Jared and Cortes, Adrian and Welsh, Samantha and Young, Alan and Effingham, Mark and McVean, Gil and Leslie, Stephen and Allen, Naomi and Donnelly, Peter and Marchini, Jo...
-
[37]
Highly accurate protein structure prediction with AlphaFold
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and Žídek, Augustin and Potapenko, Anna and Bridgland, Alex and Meyer, Clemens and Kohl, Simon A A and Ballard, Andrew J and Cowie, Andrew and Romera-Paredes, Bernardino and Nikolov, Stanislav and J...
-
[38]
Foundation model of neural activity predicts response to new stimulus types
Wang, Eric Y and Fahey, Paul G and Ding, Zhuokun and Papadopoulos, Stelios and Ponder, Kayla and Weis, Marissa A and Chang, Andersen and Muhammad, Taliah and Patel, Saumil and Ding, Zhiwei and Tran, Dat and Fu, Jiakun and Schneider-Mizell, Casey M and MICrONS Consortium and Reid, R Clay and Collman, Forrest and da Costa, Nuno Maçarico and Franke, Katrin a...
-
[39]
Accurate medium-range global weather forecasting with 3D neural networks
Bi, Kaifeng and Xie, Lingxi and Zhang, Hengheng and Chen, Xin and Gu, Xiaotao and Tian, Qi. Accurate medium-range global weather forecasting with 3D neural networks. Nature
-
[40]
Demas, Jeffrey and Manley, Jason and Tejera, Frank and Barber, Kevin and Kim, Hyewon and Traub, Francisca Martínez and Chen, Brandon and Vaziri, Alipasha. High-speed, cortex-wide volumetric recording of neuroactivity at cellular resolution using light beads microscopy. Nat. Methods
-
[41]
Neuropixels 2.0: A miniaturized high-density probe for stable, long-term brain recordings
Steinmetz, Nicholas A and Aydin, Cagatay and Lebedeva, Anna and Okun, Michael and Pachitariu, Marius and Bauza, Marius and Beau, Maxime and Bhagat, Jai and Böhm, Claudia and Broux, Martijn and Chen, Susu and Colonell, Jennifer and Gardner, Richard J and Karsh, Bill and Kloosterman, Fabian and Kostadinov, Dimitar and Mora-Lopez, Carolina and O'Callaghan, J...
- [42]
-
[43]
The Linear Representation Hypothesis and the Geometry of Large Language Models , author=. 2024 , eprint=
work page 2024
- [44]
-
[45]
Functional connectomics spanning multiple areas of mouse visual cortex
MICrONS Consortium. Functional connectomics spanning multiple areas of mouse visual cortex. Nature
-
[46]
and Hong, Ha and Yamins, Daniel L
Cadieu, Charles F. and Hong, Ha and Yamins, Daniel L. K. and Pinto, Nicolas and Ardila, Diego and Solomon, Ethan A. and Majaj, Najib J. and DiCarlo, James J. , journal=. Deep neural networks rival the representation of primate. 2014 , publisher=
work page 2014
-
[47]
Neural population control via deep image synthesis , author=. Science , volume=. 2019 , publisher=
work page 2019
-
[48]
Inception loops discover what excites neurons most using deep predictive models , author=. Nature Neuroscience , volume=. 2019 , publisher=
work page 2019
-
[49]
Dual-feature selectivity enables bidirectional coding in visual cortical neurons
Franke, Katrin and Karantzas, Nikos and Willeke, Konstantin and Diamantaki, Maria and Ramakrishnan, Kandan and Bedel, Hasan Atakan and Elumalai, Pavithra and Restivo, Kelli and Fahey, Paul and Nealley, Cate and Shinn, Tori and Garcia, Gabrielle and Patel, Saumil and Ecker, Alexander and Walker, Edgar Y and Froudarakis, Emmanouil and Sanborn, Sophia and Si...
-
[50]
Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=
Fast classification of handwritten on-line Arabic characters , author=. Soft Computing and Pattern Recognition (SoCPaR), 2014 6th International Conference of , pages=. 2014 , organization=
work page 2014
-
[51]
arXiv preprint arXiv:1804.09028 , year=
Estimate and Replace: A Novel Approach to Integrating Deep Neural Networks with Existing Applications , author=. arXiv preprint arXiv:1804.09028 , year=
-
[52]
Interpreting Neurons in Deep Vision Networks with Language Models , author=. TMLR , year=
-
[53]
Advances in Neural Information Processing Systems , volume=
Compositional explanations of neurons , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Network dissection: Quantifying interpretability of deep visual representations , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[55]
Clip-dissect: Automatic description of neuron representations in deep vision networks,
Clip-dissect: Automatic description of neuron representations in deep vision networks , author=. arXiv preprint arXiv:2204.10965 , year=
-
[56]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[57]
International Conference on Machine Learning , pages=
Identifying interpretable subspaces in image representations , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[58]
International Conference on Learning Representations , year=
Natural language descriptions of deep visual features , author=. International Conference on Learning Representations , year=
-
[59]
Rigorously assessing natural language explanations of neurons , author=. Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP , pages=
-
[60]
Advances in Neural Information Processing Systems , volume=
Find: A function description benchmark for evaluating interpretability methods , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
work page 2009
-
[62]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Understanding deep image representations by inverting them , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
- [63]
-
[64]
European conference on computer vision , pages=
Visualizing and understanding convolutional networks , author=. European conference on computer vision , pages=. 2014 , organization=
work page 2014
-
[65]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Rich feature hierarchies for accurate object detection and semantic segmentation , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[66]
arXiv preprint arXiv:1506.02078 , year=
Visualizing and understanding recurrent networks , author=. arXiv preprint arXiv:1506.02078 , year=
-
[67]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
What is one grain of sand in the desert? analyzing individual neurons in deep nlp models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
- [68]
-
[69]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Toward a visual concept vocabulary for gan latent space , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[70]
Interpreting clip's image representation via text-based decomposition , author=. arXiv preprint arXiv:2310.05916 , year=
-
[71]
Forty-first International Conference on Machine Learning , year=
A multimodal automated interpretability agent , author=. Forty-first International Conference on Machine Learning , year=
-
[72]
Proceedings of the 40th International Conference on Machine Learning , pages =
Identifying Interpretable Subspaces in Image Representations , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[73]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[74]
arXiv preprint arXiv:1707.08139 , year=
Analogs of linguistic structure in deep representations , author=. arXiv preprint arXiv:1707.08139 , year=
-
[75]
A tale of two tails: Preferred and anti-preferred natural stimuli in visual cortex
Gondur, Rabia and Stan, Patricia L and Smith, Matthew A and Cowley, Benjamin R. A tale of two tails: Preferred and anti-preferred natural stimuli in visual cortex. The Fourteenth International Conference on Learning Representations
-
[76]
The importance of mixed selectivity in complex cognitive tasks
Rigotti, Mattia and Barak, Omri and Warden, Melissa R and Wang, Xiao-Jing and Daw, Nathaniel D and Miller, Earl K and Fusi, Stefano. The importance of mixed selectivity in complex cognitive tasks. Nature
- [77]
-
[78]
International Conference on Learning Representations (ICLR) , year=
Local vs distributed representations: What is the right basis for interpretability? , author=. International Conference on Learning Representations (ICLR) , year=. 2411.03993 , archivePrefix=
-
[79]
Willeke, Konstantin F and Restivo, Kelli and Franke, Katrin and Nix, Arne F and Cadena, Santiago A and Shinn, Tori and Nealley, Cate and Rodriguez, Gabrielle and Patel, Saumil and Ecker, Alexander S and Sinz, Fabian H and Tolias, Andreas S. Deep learning-driven characterization of single cell tuning in primate visual area V4 supports topological organizat...
-
[80]
What's ``up'' with vision-language models? Investigating their struggle with spatial reasoning
Kamath, Amita and Hessel, Jack and Chang, Kai-Wei. What's ``up'' with vision-language models? Investigating their struggle with spatial reasoning. arXiv [cs.CL]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.