Recognition: 2 theorem links
· Lean TheoremTask-Adaptive Embedding Refinement via Test-time LLM Guidance
Pith reviewed 2026-05-13 03:54 UTC · model grok-4.3
The pith
Refining query embeddings with LLM feedback on a few documents boosts zero-shot search and classification performance across models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
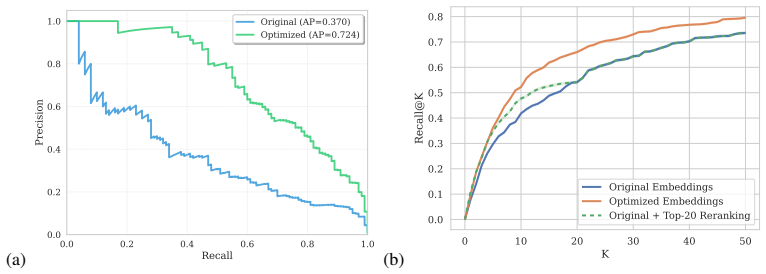
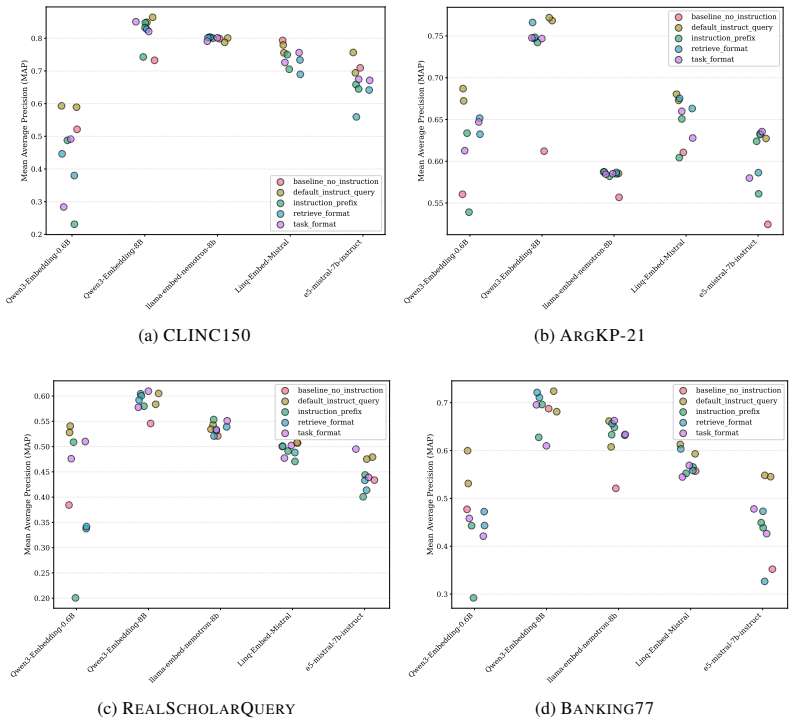
We explore the effectiveness of an LLM-guided query refinement paradigm for extending the usability of embedding models to challenging zero-shot search and classification tasks. Our approach refines the embedding representation of a user query using feedback from a generative LLM on a small set of documents, enabling embeddings to adapt in real time to the target task. Empirical results indicate that LLM-guided query refinement yields consistent gains across all models and datasets, with relative improvements of up to +25% in literature search, intent detection, key-point matching, and nuanced query-instruction following. The refined queries improve ranking quality and induce clearer binary
What carries the argument
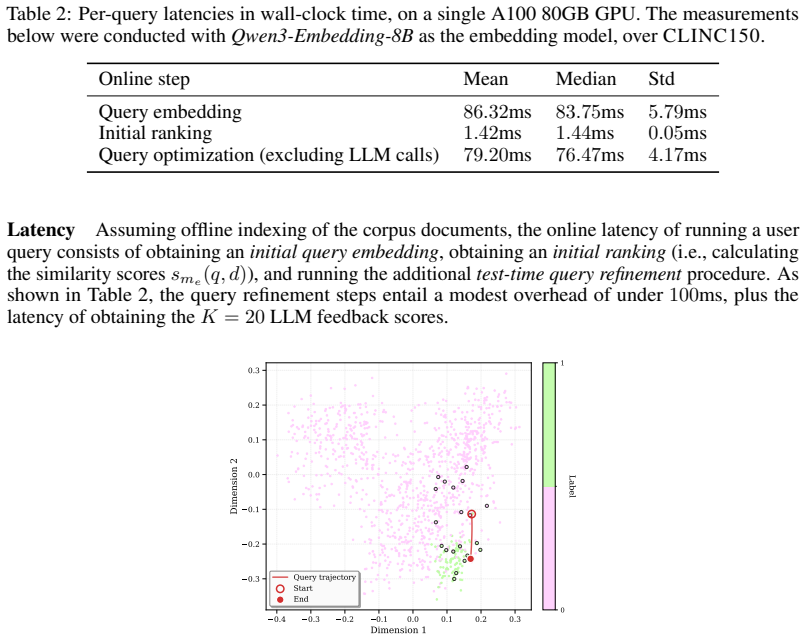
The LLM-guided query refinement mechanism that adjusts the query embedding vector based on generative feedback from a small document sample at test time.
If this is right
- Embedding models can be deployed effectively in settings where full LLM inference at corpus scale is too costly.
- Task-specific adaptation occurs without retraining or fine-tuning the embedding model.
- Ranking and classification quality improve due to better separation in the embedding space for nuanced queries.
- The range of zero-shot tasks where embeddings outperform or match generative pipelines expands significantly.
Where Pith is reading between the lines
- This test-time adaptation might apply to other embedding-based systems beyond text, such as in recommendation or retrieval-augmented generation.
- Repeated refinement steps could be explored if the initial small set provides insufficient guidance.
- It suggests a hybrid approach where LLMs are used sparingly only for query adaptation rather than full generation.
Load-bearing premise
Feedback from the LLM on a small set of documents accurately captures the task requirements without bias or error that would affect the larger corpus.
What would settle it
A controlled test where the refinement is applied but performance decreases on a benchmark due to misleading LLM feedback from the sample documents.
Figures

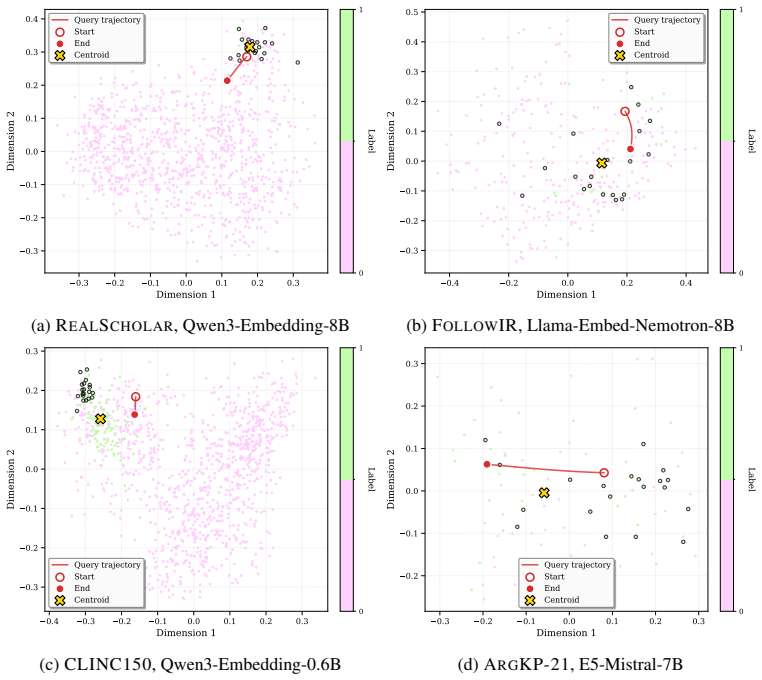
read the original abstract
We explore the effectiveness of an LLM-guided query refinement paradigm for extending the usability of embedding models to challenging zero-shot search and classification tasks. Our approach refines the embedding representation of a user query using feedback from a generative LLM on a small set of documents, enabling embeddings to adapt in real time to the target task. We conduct extensive experiments with state-of-the-art text embedding models across a diverse set of challenging search and classification benchmarks. Empirical results indicate that LLM-guided query refinement yields consistent gains across all models and datasets, with relative improvements of up to +25% in literature search, intent detection, key-point matching, and nuanced query-instruction following. The refined queries improve ranking quality and induce clearer binary separation across the corpus, enabling the embedding space to better reflect the nuanced, task-specific constraints of each ad-hoc user query. Importantly, this expands the range of practical settings in which embedding models can be effectively deployed, making them a compelling alternative when costly LLM pipelines are not viable at corpus-scale. We release our experimental code for reproducibility, at https://github.com/IBM/task-aware-embedding-refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a test-time adaptation method for text embedding models in which an LLM generates feedback on a small set of initially retrieved documents to refine the query embedding representation. This refined embedding is then used for zero-shot search and classification tasks. Experiments across state-of-the-art embedding models and diverse benchmarks (literature search, intent detection, key-point matching, nuanced query-instruction following) report consistent relative gains of up to +25%, with improved ranking quality and clearer separation in the embedding space. The authors release code for reproducibility.
Significance. If the empirical results hold under rigorous verification, the approach would meaningfully extend the practical range of embedding models to ad-hoc, nuanced tasks that currently require full LLM pipelines, while preserving the efficiency and scalability advantages of embeddings. The test-time refinement paradigm offers a lightweight way to inject task-specific constraints without retraining or corpus-scale LLM inference.
major comments (2)
- Abstract: the central claim of 'consistent gains across all models and datasets' with relative improvements 'up to +25%' is load-bearing for the paper's contribution, yet the abstract supplies no information on the number or identity of baselines, statistical significance tests, data splits, or controls for confounds such as query difficulty or document-set size; this prevents assessment of whether the reported gains are robust.
- Method and Experiments (general): the refinement step assumes that LLM feedback derived from a small retrieved document set is representative and low-bias for the full unseen corpus. No ablations on sample size, feedback-quality metrics, or per-query failure cases are referenced, leaving the generalization argument—the weakest link in the chain—unsupported by the available description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating the revisions we will incorporate to improve clarity and support for our claims.
read point-by-point responses
-
Referee: Abstract: the central claim of 'consistent gains across all models and datasets' with relative improvements 'up to +25%' is load-bearing for the paper's contribution, yet the abstract supplies no information on the number or identity of baselines, statistical significance tests, data splits, or controls for confounds such as query difficulty or document-set size; this prevents assessment of whether the reported gains are robust.
Authors: We agree the abstract is too concise on these points. In the revision we will expand it to specify the number of embedding models and benchmarks evaluated, note that gains are statistically significant (with details and p-values in Section 4), and briefly reference the use of standard splits plus controls for query difficulty and document-set size. Full experimental protocols, baselines, and confound analyses remain in Sections 3–4, but the abstract will now point to them explicitly. revision: yes
-
Referee: Method and Experiments (general): the refinement step assumes that LLM feedback derived from a small retrieved document set is representative and low-bias for the full unseen corpus. No ablations on sample size, feedback-quality metrics, or per-query failure cases are referenced, leaving the generalization argument—the weakest link in the chain—unsupported by the available description.
Authors: We acknowledge that the current description does not include these supporting analyses. In the revised manuscript we will add a dedicated subsection with (i) ablations varying the initial document sample size (5–20 documents), (ii) quantitative feedback-quality metrics (e.g., LLM-assigned relevance and consistency scores), and (iii) a per-query failure-case study with concrete examples of queries where refinement yielded limited or negative gains. These additions will directly address the generalization concern. revision: yes
Circularity Check
No circularity: purely empirical method with independent validation
full rationale
The paper introduces a practical test-time refinement procedure that uses LLM feedback on a small retrieved set to adjust query embeddings, then measures end-to-end ranking and classification gains on held-out benchmarks. No equations, first-principles derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. All reported improvements (+25% relative) are direct experimental outcomes on external datasets, not reductions to the method's own inputs by construction. Any self-citations are incidental and not load-bearing for the central empirical claim.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe minimize L(t) = KL(p_mt(q) || p_me(z(t))) ... z(t+1) ← z(t) − α ∇z L(t)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearrefines the embedding representation of a user query using feedback from a generative LLM on a small set of documents
Reference graph
Works this paper leans on
-
[1]
Task-aware retrieval with instructions
Akari Asai, Timo Schick, Patrick Lewis, Xilun Chen, Gautier Izacard, Sebastian Riedel, Hannaneh Hajishirzi, and Wen-tau Yih. Task-aware retrieval with instructions. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2023, pages 3650–3675, Toronto, Canada, July 2023. As- sociation ...
-
[2]
Yauhen Babakhin, Radek Osmulski, Ronay Ak, Gabriel Moreira, Mengyao Xu, Benedikt Schifferer, Bo Liu, and Even Oldridge. Llama-Embed-Nemotron-8B: A universal text em- bedding model for multilingual and cross-lingual tasks.arXiv:2511.07025, 2025. URL https://arxiv.org/abs/2511.07025
-
[3]
From arguments to key points: Towards automatic argument summarization
Roy Bar-Haim, Lilach Eden, Roni Friedman, Yoav Kantor, Dan Lahav, and Noam Slonim. From arguments to key points: Towards automatic argument summarization. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4029–4039, Online, July
-
[4]
doi: 10.18653/v1/2020.acl-main.371
Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.371. URL https://aclanthology.org/2020.acl-main.371/
-
[5]
A full-text learning to rank dataset for medical information retrieval
Vera Boteva, Demian Gholipour, Artem Sokolov, and Stefan Riezler. A full-text learning to rank dataset for medical information retrieval. InEuropean Conference on Information Retrieval, pages 716–722. Springer, 2016. URL https://doi.org/10.1007/978-3-319-30671-1_ 58
-
[6]
Quantifying attention flow in transformers
Iñigo Casanueva, Tadas Temˇcinas, Daniela Gerz, Matthew Henderson, and Ivan Vuli´c. Efficient intent detection with dual sentence encoders. In Tsung-Hsien Wen, Asli Celikyilmaz, Zhou Yu, Alexandros Papangelis, Mihail Eric, Anuj Kumar, Iñigo Casanueva, and Rushin Shah, editors, Proceedings of the 2nd Workshop on Natural Language Processing for Conversation...
-
[7]
John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Brian Strope, and Ray Kurzweil
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Brian Strope, and Ray Kurzweil. Universal sentence encoder for English. In Eduardo Blanco and Wei Lu, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demon-...
-
[8]
Sandrine Chausson, Marion Fourcade, David J Harding, Björn Ross, and Grégory Renard. The insight-inference loop: Efficient text classification via natural language inference and threshold-tuning.Sociological Methods & Research, page 00491241251326819, 2025. URL https://doi.org/10.1177/00491241251326819
-
[9]
Linq-Embed-Mistral technical report.arXiv:2412.03223, 2024
Chanyeol Choi, Junseong Kim, Seolhwa Lee, Jihoon Kwon, Sangmo Gu, Yejin Kim, Minkyung Cho, and Jy-yong Sohn. Linq-Embed-Mistral technical report.arXiv:2412.03223, 2024. URL https://arxiv.org/abs/2412.03223
-
[10]
Active learning with statistical models.The Journal of Artificial Intelligence Research, 4:129, 1996
DA Cohn, Z Ghahramani, and MI Jordan. Active learning with statistical models.The Journal of Artificial Intelligence Research, 4:129, 1996. 10
work page 1996
-
[11]
Welcome to the real world: Efficient, incremental and scalable key point analysis
Lilach Eden, Yoav Kantor, Matan Orbach, Yoav Katz, Noam Slonim, and Roy Bar-Haim. Welcome to the real world: Efficient, incremental and scalable key point analysis. In Mingxuan Wang and Imed Zitouni, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 483–491, Singapore, December 2023. Asso...
-
[12]
Active Learning for BERT: An Empirical Study
Liat Ein-Dor, Alon Halfon, Ariel Gera, Eyal Shnarch, Lena Dankin, Leshem Choshen, Marina Danilevsky, Ranit Aharonov, Yoav Katz, and Noam Slonim. Active Learning for BERT: An Empirical Study. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 7...
work page 2020
-
[13]
MMTEB: Massive mul- tilingual text embedding benchmark
Kenneth Enevoldsen, Isaac Chung, Imene Kerboua, Márton Kardos, Ashwin Mathur, David Stap, Jay Gala, Wissam Siblini, Dominik Krzemi´nski, Genta Indra Winata, Saba Sturua, Saiteja Utpala, Mathieu Ciancone, Marion Schaeffer, Diganta Misra, Shreeya Dhakal, Jonathan Rys- trøm, Roman Solomatin, Ömer Veysel Ça˘gatan, Akash Kundu, Martin Bernstorff, Shitao Xiao, ...
work page 2025
-
[14]
Overview of the 2021 key point analysis shared task
Roni Friedman, Lena Dankin, Yufang Hou, Ranit Aharonov, Yoav Katz, and Noam Slonim. Overview of the 2021 key point analysis shared task. In Khalid Al-Khatib, Yufang Hou, and Manfred Stede, editors,Proceedings of the 8th Workshop on Argument Mining, pages 154–164, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi...
-
[15]
A large-scale study of reranker relevance feedback at inference
Revanth Gangi Reddy, Pradeep Dasigi, Md Arafat Sultan, Arman Cohan, Avirup Sil, Heng Ji, and Hannaneh Hajishirzi. A large-scale study of reranker relevance feedback at inference. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’25, page 3010–3014, New York, NY , USA, 2025. Associati...
-
[16]
Precise zero-shot dense retrieval without relevance labels
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, ed- itors,Proceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1762–1777, Toronto, Canada, July 2023. Asso- ciation for C...
-
[17]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic, November 2021. Assoc...
-
[18]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. Retrieval-augmented generation for large language models: A survey.arXiv:2312.10997, 2024. URLhttps://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Michael Gusenbauer and Neal R Haddaway. Which academic search systems are suitable for systematic reviews or meta-analyses? evaluating retrieval qualities of google scholar, pubmed, and 26 other resources.Research synthesis methods, 11(2):181–217, 2020
work page 2020
-
[20]
PaSa: An LLM agent for comprehensive academic paper search
Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, and Weinan E. PaSa: An LLM agent for comprehensive academic paper search. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 116...
-
[21]
Dense passage retrieval for open-domain question answering,
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen tau Yih. Dense passage retrieval for open-domain question answering,
- [22]
-
[23]
ColBERT: Efficient and effective passage search via con- textualized late interaction over bert
Omar Khattab and Matei Zaharia. ColBERT: Efficient and effective passage search via con- textualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, page 39–48, New York, NY , USA, 2020. Association for Computing Machinery. ISBN 9781450380164. doi: 10...
-
[24]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.International Conference on Learning Representations, 2015. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K
Stefan Larson, Anish Mahendran, Joseph J. Peper, Christopher Clarke, Andrew Lee, Parker Hill, Jonathan K. Kummerfeld, Kevin Leach, Michael A. Laurenzano, Lingjia Tang, and Jason Mars. An evaluation dataset for intent classification and out-of-scope prediction, 2019. URL https://arxiv.org/abs/1909.02027
-
[26]
NV-embed: Improved techniques for training LLMs as generalist embedding models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. NV-embed: Improved techniques for training LLMs as generalist embedding models. InThe Thirteenth International Conference on Learning Representations,
-
[27]
URLhttps://openreview.net/forum?id=lgsyLSsDRe
-
[28]
Gemini embedding: Generalizable embeddings from gemini.arXiv:2503.07891, 2025
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, Gustavo Hernández Ábrego, Zhe Li, Kaifeng Chen, Henrique Schechter Vera, Xiaoqi Ren, Shanfeng Zhang, Daniel Salz, Michael Boratko, Jay Han, Blair Chen, Shuo Huang, Vikram Rao, Paul Suganthan, Feng Han, Andreas Doumanoglou, Nithi Gupta, Fedor Moiseev, Cathy Yip, Aashi Jain...
-
[29]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. InProceed- ings of the 34th International Conference on Neural Information Processing Systems, NIPS ’...
work page 2020
-
[30]
Making text embedders few-shot learners
Chaofan Li, Minghao Qin, Shitao Xiao, Jianlyu Chen, Kun Luo, Defu Lian, Yingxia Shao, and Zheng Liu. Making text embedders few-shot learners. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=wfLuiDjQ0u
work page 2025
-
[31]
Review of intent detection methods in the human-machine dialogue system
Jiao Liu, Yanling Li, and Min Lin. Review of intent detection methods in the human-machine dialogue system. InJournal of Physics: Conference Series, volume 1267. IOP Publishing, 2019. 12
work page 2019
-
[32]
MTEB: Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive text embedding benchmark. In Andreas Vlachos and Isabelle Augenstein, editors,Proceedings of the 17th Conference of the European Chapter of the Association for Computational Lin- guistics, pages 2014–2037, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics....
-
[33]
Jens Van Nooten, Andriy Kosar, Guy De Pauw, and Walter Daelemans. One size does not fit all: Exploring variable thresholds for distance-based multi-label text classification, 2025. URL https://arxiv.org/abs/2510.11160
-
[34]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, V...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Sentence- BERT : Sentence embeddings using S iamese BERT -networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT- networks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3982–3992,...
-
[36]
URL https://aclantholo gy.org/2023.acl-long.557/
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction- finetuned text embeddings. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, pages 1102–1121, Toronto...
-
[37]
BRIGHT: A realistic and challenging benchmark for reasoning- intensive retrieval
Hongjin Su, Howard Yen, Mengzhou Xia, Weijia Shi, Niklas Muennighoff, Han yu Wang, Liu Haisu, Quan Shi, Zachary S Siegel, Michael Tang, Ruoxi Sun, Jinsung Yoon, Sercan O Arik, Danqi Chen, and Tao Yu. BRIGHT: A realistic and challenging benchmark for reasoning- intensive retrieval. InThe Thirteenth International Conference on Learning Representations,
-
[38]
URLhttps://openreview.net/forum?id=ykuc5q381b
-
[39]
doi: 10.18653/v1/ 2024.findings-acl.586
Weiwei Sun, Zhengliang Shi, Wu Jiu Long, Lingyong Yan, Xinyu Ma, Yiding Liu, Min Cao, Dawei Yin, and Zhaochun Ren. MAIR: A massive benchmark for evaluating instructed retrieval. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14044–14067, Miami, Flo...
-
[40]
Optimizing test-time query representations for dense retrieval
Mujeen Sung, Jungsoo Park, Jaewoo Kang, Danqi Chen, and Jinhyuk Lee. Optimizing test-time query representations for dense retrieval. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Findings of the Association for Computational Linguistics: ACL 2023, pages 5731–5746, Toronto, Canada, July 2023. Association for Computational Linguistics. URL...
work page 2023
-
[41]
BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URLhttps://openreview.net/forum?id=wCu6T5xFjeJ
work page 2021
-
[42]
Guided Query Refinement: Multimodal Hybrid Retrieval with Test-Time Optimization
Omri Uzan, Asaf Yehudai, Roi Pony, Eyal Shnarch, and Ariel Gera. Guided query refinement: Multimodal hybrid retrieval with test-time optimization.arXiv:2510.05038, 2025. URL https://arxiv.org/abs/2510.05038
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Improving text embeddings with large language models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Improving text embeddings with large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11897–11916, Bangkok, Thailand, August 2024....
-
[44]
F ollow IR : Evaluating and teaching information retrieval models to follow instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, and Luca Soldaini. FollowIR: Evaluating and teaching infor- mation retrieval models to follow instructions. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for...
-
[45]
Improving query representations for dense retrieval with pseudo relevance feedback
HongChien Yu, Chenyan Xiong, and Jamie Callan. Improving query representations for dense retrieval with pseudo relevance feedback. InProceedings of the 30th ACM International Conference on Information & Knowledge Management, CIKM ’21, page 3592–3596, New York, NY , USA, 2021. Association for Computing Machinery. ISBN 9781450384469. doi: 10.1145/3459637.34...
-
[46]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv:2506.05176, 2025. URLhttps://arxiv.org/abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
A survey of active learning for natural language processing
Zhisong Zhang, Emma Strubell, and Eduard Hovy. A survey of active learning for natural language processing. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6166– 6190, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Lingu...
-
[48]
A setwise approach for effective and highly efficient zero-shot ranking with large language models
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. A setwise approach for effective and highly efficient zero-shot ranking with large language models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, page 38–47. ACM, July 2024. doi: 10.1145/3626772.3657813. URL ht...
-
[49]
Guido Zuccon, Shengyao Zhuang, and Xueguang Ma. R2LLMs: Retrieval and ranking with LLMs. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 4106–4109, 2025. URL https://ielab.io/ tutorials/r2llms.html. 14 A Dataset Details The details of the datasets used in this work are provided in Ta...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.