Recognition: no theorem link
AlphaGRPO: Unlocking Self-Reflective Multimodal Generation in UMMs via Decompositional Verifiable Reward
Pith reviewed 2026-05-13 05:49 UTC · model grok-4.3
The pith
Applying group relative policy optimization with decompositional rewards lets unified multimodal models reason about implicit user intents and self-correct image generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
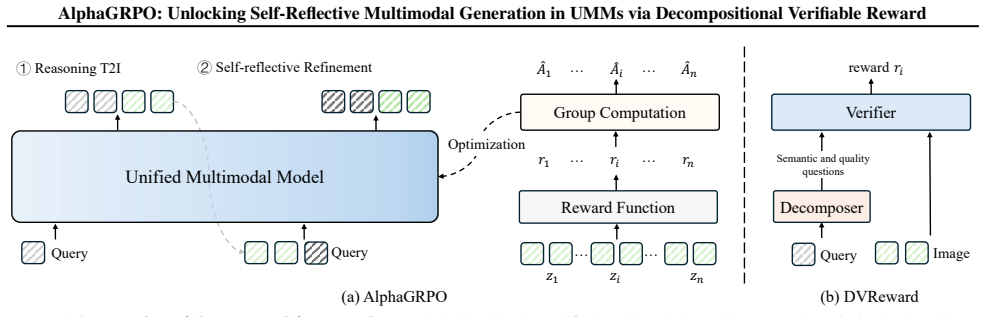
AlphaGRPO combines Group Relative Policy Optimization with the Decompositional Verifiable Reward to unlock intrinsic self-reflective capabilities in AR-Diffusion Unified Multimodal Models. The reward decomposes user requests into atomic verifiable semantic and quality questions that a general MLLM evaluates, supplying stable and interpretable supervision for Reasoning Text-to-Image Generation and Self-Reflective Refinement. This produces robust gains on GenEval, TIIF-Bench, DPG-Bench, and WISE and transfers to editing tasks on GEdit without any editing-specific training, showing that reinforcement learning can harness the model's inherent understanding to guide high-fidelity multimodal image
What carries the argument
Decompositional Verifiable Reward, which uses an LLM to break complex user requests into atomic verifiable questions scored by a general MLLM to supply stable feedback for GRPO updates in AR-Diffusion UMMs.
If this is right
- Unified multimodal models gain the ability to infer and act on implicit user intents during text-to-image generation.
- Self-diagnosis and autonomous correction of output misalignments become part of the generation process through reinforcement learning.
- Performance rises across multiple standard generation benchmarks without task-specific fine-tuning stages.
- Generation improvements transfer to image editing tasks even when the model receives no editing examples during training.
- Self-reflective capabilities emerge without a separate cold-start training phase.
Where Pith is reading between the lines
- The decomposition approach could reduce dependence on large curated alignment datasets by leveraging internal model capabilities instead.
- Similar verifiable decomposition techniques might extend to video or audio generation domains where prompt complexity is also high.
- If the atomic questions remain reliable at scale, the method could support more transparent debugging of generation failures.
Load-bearing premise
An LLM can reliably decompose complex real-world user requests into atomic, verifiable semantic and quality questions that a general MLLM can evaluate without bias or instability.
What would settle it
Training with AlphaGRPO on a collection of ambiguous prompts where the LLM decompositions yield inconsistent questions, then measuring that the resulting images show no improvement or lower alignment scores than non-RL baselines on the same prompts.
Figures








read the original abstract
In this paper, we propose AlphaGRPO, a novel framework that applies Group Relative Policy Optimization (GRPO) to AR-Diffusion Unified Multimodal Models (UMMs) to enhance multimodal generation capabilities without an additional cold-start stage. Our approach unlocks the model's intrinsic potential to perform advanced reasoning tasks: Reasoning Text-to-Image Generation, where the model actively infers implicit user intents, and Self-Reflective Refinement, where it autonomously diagnoses and corrects misalignments in generated outputs. To address the challenge of providing stable supervision for real-world multimodal generation, we introduce the Decompositional Verifiable Reward (DVReward). Unlike holistic scalar rewards, DVReward utilizes an LLM to decompose complex user requests into atomic, verifiable semantic and quality questions, which are then evaluated by a general MLLM to provide reliable and interpretable feedback. Extensive experiments demonstrate that AlphaGRPO yields robust improvements across multimodal generation benchmarks, including GenEval, TIIF-Bench, DPG-Bench and WISE, while also achieving significant gains in editing tasks on GEdit without training on editing tasks. These results validate that our self-reflective reinforcement approach effectively leverages inherent understanding to guide high-fidelity generation. Project page: https://huangrh99.github.io/AlphaGRPO/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AlphaGRPO, a framework that applies Group Relative Policy Optimization (GRPO) to AR-Diffusion Unified Multimodal Models (UMMs) to improve multimodal generation without a cold-start stage. It introduces Decompositional Verifiable Reward (DVReward), which uses an LLM to decompose complex user prompts into atomic verifiable semantic and quality questions that are then scored by a general MLLM. The central claims are robust performance gains on GenEval, TIIF-Bench, DPG-Bench, and WISE, plus significant zero-shot gains on GEdit editing tasks despite no editing-specific training, enabling self-reflective reasoning and refinement in generation.
Significance. If the empirical gains prove robust and the DVReward mechanism supplies stable, unbiased supervision independent of the trained model, the work would meaningfully advance self-reflective capabilities in unified multimodal models. The zero-shot transfer to editing tasks and avoidance of cold-start training are notable strengths that suggest effective leverage of intrinsic model understanding. The approach could influence future RL-based training for generation tasks, provided the reward decomposition is shown to be reliable.
major comments (2)
- [DVReward subsection] DVReward subsection: No inter-rater agreement, test-retest reliability, or ablation replacing the LLM decomposer with fixed templates is reported. This is load-bearing for the central claim, as inconsistent decomposition would render the GRPO signal unstable and the reported benchmark gains potentially artifactual.
- [Experiments section] Experiments section: The manuscript supplies no ablation isolating GRPO + DVReward from standard RLHF baselines using the same MLLM evaluator, nor quantitative results with error bars or statistical tests on the claimed gains across GenEval, TIIF-Bench, DPG-Bench, and WISE. This prevents assessment of whether the self-reflective advantage is real or tied to the specific LLM/MLLM pair.
minor comments (1)
- [Abstract] The abstract would be strengthened by summarizing at least one key quantitative result (e.g., absolute or relative improvement on GenEval) rather than stating only that gains are 'robust'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of validating DVReward reliability and providing more rigorous experimental controls. We address each major comment point-by-point below and will revise the manuscript to incorporate the suggested analyses.
read point-by-point responses
-
Referee: [DVReward subsection] DVReward subsection: No inter-rater agreement, test-retest reliability, or ablation replacing the LLM decomposer with fixed templates is reported. This is load-bearing for the central claim, as inconsistent decomposition would render the GRPO signal unstable and the reported benchmark gains potentially artifactual.
Authors: We agree that explicit reliability metrics for the decomposition step would strengthen the central claim regarding stable supervision. The atomic questions are deliberately formulated to be simple, objective, and directly answerable by a general MLLM, which reduces the scope for inconsistency. Nevertheless, to directly address the concern, we will add an ablation in the revised manuscript that replaces the LLM decomposer with fixed, hand-crafted templates based on common prompt patterns. We will also report inter-rater agreement (e.g., Cohen's kappa) between two different LLMs on a held-out set of 200 prompts to quantify decomposition stability. revision: yes
-
Referee: [Experiments section] Experiments section: The manuscript supplies no ablation isolating GRPO + DVReward from standard RLHF baselines using the same MLLM evaluator, nor quantitative results with error bars or statistical tests on the claimed gains across GenEval, TIIF-Bench, DPG-Bench, and WISE. This prevents assessment of whether the self-reflective advantage is real or tied to the specific LLM/MLLM pair.
Authors: We acknowledge that a direct ablation against standard RLHF using the identical MLLM evaluator, together with error bars and statistical tests, would allow clearer attribution of gains. Our existing baselines already include several RL-based methods, but we will add the requested RLHF control in the revision. We will also report standard deviations across three random seeds and include paired statistical tests (e.g., Wilcoxon signed-rank) for all benchmark improvements. The zero-shot GEdit gains, obtained without any editing-specific training, provide supporting evidence that the self-reflective behavior is not merely an artifact of the particular evaluator pair. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces AlphaGRPO as an application of GRPO to AR-Diffusion UMMs paired with a new DVReward mechanism that decomposes prompts via an external LLM and scores them via a separate general MLLM. No equations, derivations, or load-bearing steps in the abstract or described method reduce by construction to the inputs, fitted parameters renamed as predictions, or self-citation chains. The empirical claims rest on benchmark improvements (GenEval, TIIF-Bench, etc.) that are externally falsifiable and do not presuppose the target result. The framework is therefore self-contained against independent evaluation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unified multimodal models possess intrinsic potential to perform advanced reasoning tasks such as inferring implicit intents and self-diagnosing misalignments.
invented entities (1)
-
Decompositional Verifiable Reward (DVReward)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
URL https://arxiv.org/abs/2409.0 4429. Xiao, S., Wang, Y ., Zhou, J., Yuan, H., Xing, X., Yan, R., Li, C., Wang, S., Huang, T., and Liu, Z. Omnigen: Unified image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 13294–13304, 2025. Xie, J., Mao, W., Bai, Z., Zhang, D. J., Wang, W., Lin, K. Q., Gu, Y ., Chen, Z., Yang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Is the ship moving through the sky?
-
[3]
Is the ship geometrically coherent with a structurally plausible hull and super- structure?
-
[4]
Is the ship clearly defined and visually distinct from the surrounding sky without fusion or blending artifacts?
-
[5]
Does the ship exhibit a consistent blue coloration across its surface with realistic material variation, such as paint sheen or weathering?
-
[6]
Does the ship’s orientation and motion cues, such as implied speed or wake effects, suggest dynamic movement through the air?
-
[7]
A glowing cluster is on the right
Is the lighting on the ship consistent with the surrounding sky environment, supporting its presence in aerial space? A blue toilet is on the left. A glowing cluster is on the right. 1. Is there a toilet?
-
[8]
Is there a glowing cluster?
-
[9]
Is the toilet on the left?
-
[10]
Is the glowing cluster on the right?
-
[11]
Is the toilet geometrically accurate with a properly formed bowl, tank, and base structure?
-
[12]
Is the toilet clearly separated from its surroundings without visual fusion or distortion artifacts?
-
[13]
Does the glowing cluster emit a consistent and visually distinct luminosity that suggests an internal light source?
-
[14]
Is the cluster composed of coherent, non-melting elements that maintain structural integrity?
-
[15]
Is the blue color of the toilet consistent across its surface with realistic material shading and hue fidelity? 6 12 18 24 30 36 42 48 Number of Questions per Prompt 0 200 400 600 800Number of Prompts Figure 7.Distribution of the question numbers in the synthe- sized prompt. A.4. Analysis of Efficiency of DVReward Because DVReward uses an external MLLM ve...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.