Recognition: 2 theorem links
· Lean TheoremMitigating Cross-Lingual Cultural Inconsistencies in LLMs via Consensus-Driven Preference Optimisation
Pith reviewed 2026-05-14 21:53 UTC · model grok-4.3
The pith
Consensus-driven preference optimization raises cross-language cultural consistency in multilingual LLMs by up to 0.10 points on a new metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
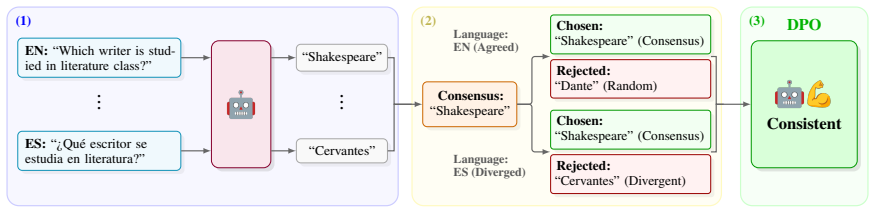
The central claim is that training multilingual LLMs with Cross-lingual Cultural Consistent Preference Optimisation (C-3PO) increases Singleton Fleiss's κ_S by as much as 0.10 points by aligning outputs to cross-language consensus, thereby reducing the tendency for prompt language to overwrite a fixed persona's cultural references.
What carries the argument
C-3PO, a consensus-driven preference optimisation framework that identifies shared responses across languages and uses them to create training pairs that reward cultural consistency independent of prompt language.
If this is right
- The same persona produces more stable cultural references when the user switches between languages.
- Lower-resource languages such as Indonesian and Persian show the largest consistency gains.
- Early-layer representations become less biased toward the prompt language's stereotypical culture.
- The approach outperforms both prompt engineering and representation-steering baselines on the κ_S metric.
Where Pith is reading between the lines
- The same consensus mechanism could be applied to reduce other prompt-language effects, such as differences in factual precision or stylistic tone.
- Intervening at the intermediate layers identified in the analysis might achieve similar consistency with less full-model retraining.
- One could test whether the gains persist when the consensus set includes languages that have genuinely different cultural norms on the query topic.
- The metric κ_S could serve as a general probe for other forms of output instability tied to input language.
Load-bearing premise
That the responses showing agreement across languages truly represent the right consistent behavior rather than an averaged compromise that erases legitimate cultural distinctions.
What would settle it
Apply C-3PO to a new set of ambiguous literature queries with fixed personas, then measure whether the rate of matching cultural references (such as author names) between English and Spanish prompts rises above the rate seen in the original unaligned model.
Figures











read the original abstract
Despite their impressive capabilities, multilingual large language models (MLLMs) frequently exhibit inconsistent behaviour when the prompt's language changes. While such adaptation is generally desirable, it becomes a critical failure when a user's identity is explicitly defined. For instance, given a fixed British persona and an ambiguous everyday knowledge query about literature, the prompt's language frequently overwrites the system persona -- yielding Shakespeare in English but Cervantes in Spanish. To robustly quantify this Cross-lingual Cultural Inconsistency, we introduce Singleton Fleiss's $\kappa_S$, a metric mathematically resilient to hallucinations. For mitigation, we propose Cross-lingual Cultural Consistent Preference Optimisation (C-3PO), a consensus-driven alignment framework. C-3PO achieves up to a 0.10-point absolute increase in $\kappa_S$ over unaligned models, outperforming strong prompting and representation steering baselines. Empirical evaluations show this inconsistency disproportionately affects lower-resource languages like Indonesian and Persian. A layer-wise interpretability analysis reveals the underlying mechanism: by early-decoding intermediate layer representations, we find that MLLMs implicitly personalise outputs towards the prompt language's stereotypical culture as forward-pass representations stabilise.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multilingual LLMs exhibit cross-lingual cultural inconsistency, where prompt language overwrites fixed personas (e.g., literature queries yielding Shakespeare in English but Cervantes in Spanish). It introduces Singleton Fleiss's κ_S as a metric mathematically resilient to hallucinations to quantify this inconsistency, proposes C-3PO as a consensus-driven preference optimization framework for mitigation, reports up to a 0.10 absolute κ_S gain over unaligned models and baselines (with larger effects in lower-resource languages like Indonesian and Persian), and provides layer-wise interpretability analysis showing early-decoding personalization to prompt-language culture as representations stabilize.
Significance. If the results hold, the work would offer a meaningful advance in multilingual LLM alignment by supplying both a new inconsistency metric and a practical consensus-based optimization method. The emphasis on lower-resource languages and the interpretability component add value by addressing equity and mechanistic understanding. The 0.10 κ_S improvement, if robustly verified, could inform future preference optimization techniques beyond standard RLHF or prompting.
major comments (3)
- [§4] §4 (evaluation protocol): the central claim that the 0.10 κ_S increase demonstrates mitigation of inconsistency rather than erasure of legitimate cultural variation requires explicit verification that the query set contains only items with culture-independent ground truth; without this check (or an ablation on divergent items such as historical framing), higher κ_S may simply reflect reduced output diversity.
- [§3.1] Definition of κ_S (likely §3.1): the assertion that Singleton Fleiss's κ_S is 'mathematically resilient to hallucinations' and isolates language-induced drift is load-bearing for the metric's validity, yet the exact formula, derivation steps, and proof of resilience against confounding perspective differences are not supplied in sufficient detail to allow independent confirmation.
- [Results section] Table 2 or results section: the outperformance over prompting and representation-steering baselines is reported as a 0.10 gain, but the manuscript supplies no statistical tests, confidence intervals, or data-split details; this prevents assessment of whether the improvement is reliable or merely an artifact of the chosen consensus data.
minor comments (2)
- [§5.2] The layer-wise interpretability analysis would be strengthened by reporting exact layer indices where representation stabilization occurs and by including quantitative stability metrics rather than qualitative description.
- [§3] Notation for κ_S should be defined with an explicit equation early in the text to avoid ambiguity when comparing across languages and models.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which have helped us identify areas for clarification and strengthening. We address each major point below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (evaluation protocol): the central claim that the 0.10 κ_S increase demonstrates mitigation of inconsistency rather than erasure of legitimate cultural variation requires explicit verification that the query set contains only items with culture-independent ground truth; without this check (or an ablation on divergent items such as historical framing), higher κ_S may simply reflect reduced output diversity.
Authors: We agree that explicitly distinguishing mitigation of inconsistency from reduced output diversity is essential. Our query set was constructed from factual, culture-independent items (e.g., everyday knowledge queries with a fixed persona) where ground truth does not legitimately vary by language. In the revision we will add an explicit verification subsection describing this selection process and include a new ablation on divergent items (such as historical framing questions) to demonstrate that the observed κ_S gains reflect reduced language-induced drift rather than loss of legitimate variation. revision: yes
-
Referee: [§3.1] Definition of κ_S (likely §3.1): the assertion that Singleton Fleiss's κ_S is 'mathematically resilient to hallucinations' and isolates language-induced drift is load-bearing for the metric's validity, yet the exact formula, derivation steps, and proof of resilience against confounding perspective differences are not supplied in sufficient detail to allow independent confirmation.
Authors: We accept that the current presentation lacks sufficient mathematical detail. The revised manuscript will include the precise formula for Singleton Fleiss's κ_S, the full derivation steps, and a formal argument (with supporting lemmas) demonstrating its resilience to hallucinations and its isolation of language-induced drift from other sources of variation such as perspective differences. revision: yes
-
Referee: [Results section] Table 2 or results section: the outperformance over prompting and representation-steering baselines is reported as a 0.10 gain, but the manuscript supplies no statistical tests, confidence intervals, or data-split details; this prevents assessment of whether the improvement is reliable or merely an artifact of the chosen consensus data.
Authors: We agree that statistical rigor is required. In the revision we will add paired statistical tests (e.g., Wilcoxon signed-rank), 95% confidence intervals for all reported κ_S gains, and explicit details on data splits, consensus data construction, and cross-validation procedures to allow readers to assess the reliability of the 0.10 improvement. revision: yes
Circularity Check
No circularity: empirical gains measured by newly introduced metric
full rationale
The paper introduces Singleton Fleiss's κ_S as a new metric for cross-lingual inconsistency and C-3PO as a consensus-driven preference optimization method. The central result (0.10-point κ_S increase) is reported as an empirical outcome from applying C-3PO to MLLMs and comparing against baselines. No equations, definitions, or steps in the provided text reduce the claimed prediction or improvement to the inputs by construction. No self-citations are invoked to establish uniqueness or load-bearing premises, and the metric is not defined circularly in terms of the optimization result. The derivation relies on external consensus data and evaluations, remaining self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe introduce Singleton Fleiss’s κ_S ... C-3PO, a consensus-driven alignment framework
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearlayer-wise interpretability analysis ... forward-pass representations stabilise
Reference graph
Works this paper leans on
-
[1]
Amit Agarwal, Hansa Meghwani, Hitesh Laxmichand Patel, Tao Sheng, Sujith Ravi, and Dan Roth. 2025. https://doi.org/10.18653/v1/2025.emnlp-industry.9 Aligning LLMs for Multilingual Consistency in Enterprise Applications . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing : Industry Track , pages 117--137, Suzhou (Chi...
-
[2]
Mengyu Bu, Shaolei Zhang, Zhongjun He, Hua Wu, and Yang Feng. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.328 AlignX : Advancing Multilingual Large Language Models with Multilingual Representation Alignment . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 6460--6489, Suzhou, China. Association for C...
-
[3]
Bram Bulté and Ayla Rigouts Terryn. 2025. https://doi.org/10.1162/COLI.a.583 LLMs and Cultural Values : The Impact of Prompt Language and Explicit Cultural Framing . Computational Linguistics, pages 1--85
-
[4]
Menglong Cui, Pengzhi Gao, Wei Liu, Jian Luan, and Bin Wang. 2025. https://doi.org/10.18653/v1/2025.naacl-long.280 Multilingual Machine Translation with Open Large Language Models at Practical Scale : An Empirical Study . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics : Human L...
-
[5]
Constanza Fierro and Anders Søgaard. 2022. https://doi.org/10.18653/v1/2022.findings-acl.240 Factual Consistency of Multilingual Pretrained Language Models . In Findings of the Association for Computational Linguistics : ACL 2022 , pages 3046--3052, Dublin, Ireland. Association for Computational Linguistics
-
[6]
Joseph L. Fleiss. 1971. https://doi.org/10.1037/h0031619 Measuring nominal scale agreement among many raters. Psychological Bulletin, 76(5):378--382
-
[7]
Asma Ghandeharioun, Ann Yuan, Marius Guerard, Emily Reif, Michael A. Lepori, and Lucas Dixon. 2024. https://papers.nips.cc/paper_files/paper/2024/hash/e40d5118ee8f837729fa877add71c38f-Abstract-Conference.html Who's asking? User personas and the mechanics of latent misalignment . In Advances in Neural Information Processing Systems 37 ( NeurIPS 2024): Main...
work page 2024
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://doi.org/10.48550/arXiv.2407.21783 Th...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[9]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 LoRA : Low - Rank Adaptation of Large Language Models . In 10th International Conference on Learning Representations ( ICLR 2022) , Online. Curran Associates, Inc
work page 2022
-
[10]
Maxim Ifergan, Leshem Choshen, Roee Aharoni, Idan Szpektor, and Omri Abend. 2025. https://aclanthology.org/2025.findings-naacl.475/ Beneath the Surface of Consistency : Exploring Cross -lingual Knowledge Representation Sharing in LLMs . In Findings of the Association for Computational Linguistics : NAACL 2025 , pages 4630--4644, Albuquerque, New Mexico. A...
work page 2025
-
[11]
Fan Jiang, Tom Drummond, and Trevor Cohn. 2025. https://doi.org/10.1162/tacl_a_00750 Few- Shot Multilingual Open - Domain QA from Five Examples . Transactions of the Association for Computational Linguistics, 13:481--504
-
[12]
Viet Lai, Chien Nguyen, Nghia Ngo, Thuat Nguyen, Franck Dernoncourt, Ryan Rossi, and Thien Nguyen. 2023. https://doi.org/10.18653/v1/2023.emnlp-demo.28 Okapi: Instruction -tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Proces...
-
[13]
Chen Cecilia Liu, Iryna Gurevych, and Anna Korhonen. 2025. https://doi.org/10.1162/tacl_a_00760 Culturally Aware and Adapted NLP : A Taxonomy and a Survey of the State of the Art . Transactions of the Association for Computational Linguistics, 13:652--689
-
[14]
Lu, Lesley Luyang Song, and Lu Doris Zhang
Jackson G. Lu, Lesley Luyang Song, and Lu Doris Zhang. 2025. https://doi.org/10.1038/s41562-025-02242-1 Cultural tendencies in generative AI . Nature Human Behaviour, (9):2360--2369. Publisher: Nature Publishing Group
-
[15]
Marius Mosbach, Tiago Pimentel, Shauli Ravfogel, Dietrich Klakow, and Yanai Elazar. 2023. https://doi.org/10.18653/v1/2023.findings-acl.779 Few-shot Fine -tuning vs. In -context Learning : A Fair Comparison and Evaluation . In Findings of the Association for Computational Linguistics : ACL 2023 , pages 12284--12314, Toronto, Canada. Association for Comput...
-
[16]
Putri, Dimosthenis Antypas, Hsuvas Borkakoty, Eunsu Kim, Carla Perez-Almendros, Abinew A
Junho Myung, Nayeon Lee, Yi Zhou, Jiho Jin, Rifki A. Putri, Dimosthenis Antypas, Hsuvas Borkakoty, Eunsu Kim, Carla Perez-Almendros, Abinew A. Ayele, Víctor Gutiérrez-Basulto, Yazmín Ibáñez-García, Hwaran Lee, Shamsuddeen H. Muhammad, Kiwoong Park, Anar S. Rzayev, Nina White, Seid M. Yimam, Mohammad T. Pilehvar, and 3 others. 2024. https://doi.org/10.5220...
-
[17]
Vera Neplenbroek, Arianna Bisazza, and Raquel Fernández. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1029 Reading Between the Prompts : How Stereotypes Shape LLM 's Implicit Personalization . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 20367--20400, Suzhou, China. Association for Computational Li...
-
[18]
Siddhesh Pawar, Junyeong Park, Jiho Jin, Arnav Arora, Junho Myung, Srishti Yadav, Faiz Ghifari Haznitrama, Inhwa Song, Alice Oh, and Isabelle Augenstein. 2025 a . https://doi.org/10.1162/COLI.a.14 Survey of Cultural Awareness in Language Models : Text and Beyond . Computational Linguistics, 51(3):907--1004
-
[19]
Siddhesh Milind Pawar, Arnav Arora, Lucie-Aimée Kaffee, and Isabelle Augenstein. 2025 b . https://doi.org/10.18653/v1/2025.findings-emnlp.1207 Presumed Cultural Identity : How Names Shape LLM Responses . In Findings of the Association for Computational Linguistics : EMNLP 2025 , pages 22147--22172, Suzhou, China. Association for Computational Linguistics
-
[20]
Jirui Qi, Raquel Fernández, and Arianna Bisazza. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.658 Cross- Lingual Consistency of Factual Knowledge in Multilingual Language Models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 10650--10666, Singapore. Association for Computational Linguistics
-
[21]
Qwen, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, and 24 others. 2025. https://doi.org/10.48550/arXiv.2412.15115 Qwen2.5 Technical Report . arXiv preprint. ArXiv:2412.15115 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2025
-
[22]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html Direct Preference Optimization : Your Language Model is Secretly a Reward Model . In Advances in Neural Information Processing Sys...
work page 2023
-
[23]
Lucas Resck, Isabelle Augenstein, and Anna Korhonen. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1033 Explainability and Interpretability of Multilingual Large Language Models : A Survey . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 20465--20497, Suzhou, China. Association for Computational Linguistics
-
[24]
Arij Riabi, Virginie Mouilleron, Menel Mahamdi, Wissam Antoun, and Djamé Seddah. 2025. https://aclanthology.org/2025.coling-main.578/ Beyond Dataset Creation : Critical View of Annotation Variation and Bias Probing of a Dataset for Online Radical Content Detection . In Proceedings of the 31st International Conference on Computational Linguistics , pages 8...
work page 2025
-
[25]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, Léonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ramé, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Casbon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, and 179 others. 2024. https://doi.org/10.48550/arXiv.2408.00118 ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00118 2024
-
[26]
Griffiths, and Arvind Narayanan
Veniamin Veselovsky, Berke Argin, Benedikt Stroebl, Chris Wendler, Robert West, James Evans, Thomas L. Griffiths, and Arvind Narayanan. 2025. https://doi.org/10.48550/arXiv.2504.10191 Localized Cultural Knowledge is Conserved and Controllable in Large Language Models . arXiv preprint. ArXiv:2504.10191 [cs]
-
[27]
Mingyang Wang, Heike Adel, Lukas Lange, Yihong Liu, Ercong Nie, Jannik Strötgen, and Hinrich Schuetze. 2025. https://doi.org/10.18653/v1/2025.acl-long.253 Lost in Multilinguality : Dissecting Cross -lingual Factual Inconsistency in Transformer Language Models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Vo...
-
[28]
Linjuan Wu, Hao-Ran Wei, Huan Lin, Tianhao Li, Baosong Yang, Fei Huang, and Weiming Lu. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1380 Enhancing LLM Language Adaption through Cross -lingual In - Context Pre -training . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages 27152--27166, Suzhou, China. Ass...
-
[29]
Jiahao Ying, Wei Tang, Yiran Zhao, Yixin Cao, Yu Rong, and Wenxuan Zhang. 2025. https://doi.org/10.18653/v1/2025.acl-long.1082 Disentangling Language and Culture for Evaluating Multilingual Large Language Models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 22230--22251, Vien...
-
[30]
Haeun Yu, Seogyeong Jeong, Siddhesh Pawar, Jisu Shin, Jiho Jin, Junho Myung, Alice Oh, and Isabelle Augenstein. 2026. https://doi.org/10.48550/arXiv.2508.08879 Entangled in Representations : Mechanistic Investigation of Cultural Biases in Large Language Models . arXiv preprint. ArXiv:2508.08879 [cs]
-
[31]
Wajdi Zaghouani and Md. Rafiul Biswas. 2025. https://aclanthology.org/2025.ranlp-1.162/ EmoHopeSpeech : An Annotated Dataset of Emotions and Hope Speech in English and Arabic . In Proceedings of the 15th International Conference on Recent Advances in Natural Language Processing - Natural Language Processing in the Generative AI Era , pages 1406--1412, Var...
work page 2025
-
[32]
Li Zhou, Taelin Karidi, Wanlong Liu, Nicolas Garneau, Yong Cao, Wenyu Chen, Haizhou Li, and Daniel Hershcovich. 2025. https://doi.org/10.18653/v1/2025.naacl-long.496 Does Mapo Tofu Contain Coffee ? Probing LLMs for Food -related Cultural Knowledge . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.