Recognition: unknown
Stress-Testing the Reasoning Competence of LLMs With Proofs Under Minimal Formalism
Pith reviewed 2026-05-14 20:59 UTC · model grok-4.3
The pith
Frontier LLMs perform well on foundational proof tasks but fail at those requiring global combinatorial reasoning or low-level proof synthesis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using the ProofGrid benchmark with its instrumented proof-checking pipeline, the authors demonstrate that current large language models exhibit rapid progress on foundational reasoning but substantial limitations persist on structurally rich tasks that demand global combinatorial reasoning or low-level proof synthesis.
What carries the argument
ProofGrid benchmark suite expressed in NDL, a compact natural-deduction language, together with an instrumented proof-checking pipeline that locates the first substantive reasoning failure while tolerating minor surface deviations.
If this is right
- Frontier models succeed on foundational tasks but struggle with global combinatorial reasoning and low-level proof synthesis.
- Models display epistemic instability, generating flawed proofs while correctly rejecting similar inferences in isolation.
- The Epistemic Stability Index quantifies inconsistency between generated proofs and isolated local judgments.
- 2PL IRT analyses, Wright maps, and normalized Fisher-information measures provide fine-grained assessment of task difficulty and model discrimination.
Where Pith is reading between the lines
- Minimal-formalism tasks may isolate core reasoning more cleanly than benchmarks that permit pattern matching or external tool use.
- The benchmark could serve as a stable yardstick for measuring incremental gains in LLM reasoning over successive model releases.
- Hybrid systems that pair LLMs with formal checkers might close the observed gaps in proof synthesis and gap-filling.
Load-bearing premise
That performance on these minimal-formalism proof tasks reliably indicates general reasoning competence without being confounded by domain knowledge, solver delegation, or long-context effects.
What would settle it
Demonstrating that one or more current frontier models can consistently solve the challenge tasks requiring global combinatorial reasoning or low-level proof synthesis would falsify the claim of substantial remaining limits.
Figures

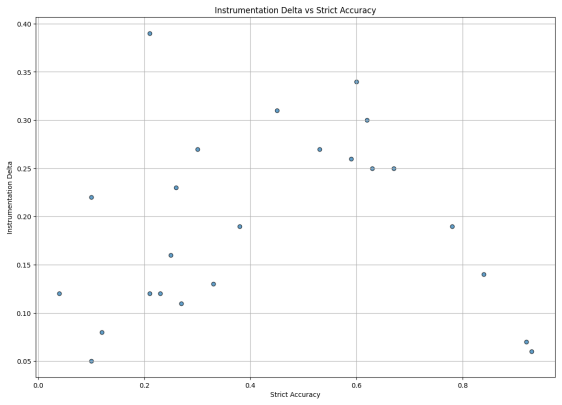




















































read the original abstract
We introduce ProofGrid, a benchmark suite for evaluating LLM reasoning through machine-checkable proofs rather than final answers alone. ProofGrid contains 15 tasks spanning proof writing, proof checking, proof masking, and proof gap-filling. Tasks are expressed in minimal formal notation, especially NDL, a compact natural-deduction language that fits in short prompts and supports precise, auditable verification. This yields mechanical, reproducible, and fine-grained evaluation rather than judgments by humans or LLMs. ProofGrid covers a calibrated difficulty spectrum, from foundational reasoning tests to structurally rich challenge tasks that no current model solves, while minimizing reliance on domain knowledge, solver delegation, and long-context artifacts. We also develop a comparative framework for reasoning benchmarks and use it to situate ProofGrid relative to existing work in terms of representation, verification guarantees, and reasoning depth. Methodologically, we introduce an instrumented proof-checking pipeline that tolerates minor surface deviations while locating the first substantive reasoning failure, improving measurement resolution and separating proof planning from low-level execution noise. Using this pipeline, we evaluate a broad range of open and proprietary models. Results show rapid progress but substantial remaining limits: frontier models perform well on several foundational tasks, yet difficult tasks, especially those requiring global combinatorial reasoning or low-level proof synthesis, remain far from solved. We also identify epistemic instability, where models generate flawed proofs yet correctly reject those local inferences in isolation, and formalize this with an Epistemic Stability Index. Finally, we complement accuracy with 2PL IRT analyses, Wright maps, and a normalized task-discrimination measure based on Fisher information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ProofGrid, a benchmark of 15 tasks for evaluating LLM reasoning via machine-checkable proofs expressed in minimal natural-deduction notation (NDL). Tasks span proof writing, checking, masking, and gap-filling; an instrumented checker locates the first substantive failure. Evaluations across open and proprietary models show frontier systems succeeding on foundational tasks while failing on those requiring global combinatorial reasoning or low-level synthesis. The authors introduce an Epistemic Stability Index to quantify inconsistency between generated proofs and isolated inferences, and supplement accuracy metrics with 2PL IRT, Wright maps, and Fisher-information-based discrimination measures. A comparative framework situates ProofGrid against prior benchmarks on representation, verification, and reasoning depth.
Significance. If the minimal-formalism design and instrumented pipeline genuinely isolate reasoning competence, the work supplies a reproducible, auditable evaluation instrument that advances formal-methods approaches to LLM assessment and supplies concrete, falsifiable evidence of remaining limits on combinatorial and synthesis tasks.
major comments (2)
- [Section 4] Section 4 and the comparative framework: the central claim that performance gaps reflect reasoning competence rather than pretraining artifacts, prompt-length effects, or residual domain cues rests on the assertion that minimal NDL minimizes those confounds, yet no ablations (NDL vs. equivalent natural-language prompts, fixed vs. variable context length, or solver-delegation controls) are reported. Without these quantitative checks the interpretation of the reported limits on global-combinatorial and low-level-synthesis tasks remains under-supported.
- [Epistemic Stability Index] Epistemic Stability Index definition and measurement: the index is introduced to capture the observed inconsistency between flawed proof generation and correct rejection of the same local inferences in isolation, but the manuscript does not supply the precise formula, the aggregation method across tasks, or statistical validation that the index is independent of the instrumented checker’s tolerance parameters.
minor comments (2)
- [Abstract] Abstract: the phrase 'rapid progress' is used without accompanying quantitative deltas, model identifiers, or task-level accuracy figures, reducing immediate readability.
- [Task definitions] The manuscript would benefit from an explicit table listing the 15 tasks, their NDL encodings, and the precise verification criteria applied by the instrumented checker.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional evidence and clarity would strengthen the manuscript's claims about isolating reasoning competence. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Section 4] Section 4 and the comparative framework: the central claim that performance gaps reflect reasoning competence rather than pretraining artifacts, prompt-length effects, or residual domain cues rests on the assertion that minimal NDL minimizes those confounds, yet no ablations (NDL vs. equivalent natural-language prompts, fixed vs. variable context length, or solver-delegation controls) are reported. Without these quantitative checks the interpretation of the reported limits on global-combinatorial and low-level-synthesis tasks remains under-supported.
Authors: We agree that the interpretation of the performance gaps would be more robust with explicit ablations. The manuscript's design rationale emphasizes that minimal NDL reduces prompt length and domain cues compared to natural-language formulations, and the instrumented checker separates planning from execution noise. However, we acknowledge that without direct quantitative comparisons these claims rest on design arguments rather than empirical controls. In the revision we will add a new subsection (likely 4.3) reporting ablations on a representative subset of tasks: (i) NDL vs. equivalent natural-language prompts, (ii) fixed vs. variable context lengths, and (iii) a solver-delegation control where models are allowed to call external provers. These results will be used to quantify the contribution of each confound and to support the claim that the observed limits on combinatorial and synthesis tasks primarily reflect reasoning competence. revision: yes
-
Referee: [Epistemic Stability Index] Epistemic Stability Index definition and measurement: the index is introduced to capture the observed inconsistency between flawed proof generation and correct rejection of the same local inferences in isolation, but the manuscript does not supply the precise formula, the aggregation method across tasks, or statistical validation that the index is independent of the instrumented checker’s tolerance parameters.
Authors: We appreciate the referee highlighting the missing formal details. The Epistemic Stability Index is intended to quantify the discrepancy between a model's ability to reject incorrect local inferences when presented in isolation versus its tendency to produce globally flawed proofs. In the current draft the definition is described only at a high level. In the revised manuscript we will insert a precise definition in Section 3: ESI = (1/T) * sum_t (C_t / E_t), where C_t is the number of correctly rejected isolated inferences for task t, E_t is the number of substantive errors in the generated proof for task t, and T is the number of tasks; aggregation is performed as a difficulty-weighted average using the 2PL IRT discrimination parameters already reported. We will also add a sensitivity analysis demonstrating that ESI values remain stable across the range of checker tolerance parameters used in the evaluation (0.05–0.15). These additions will be accompanied by the exact pseudocode and a small table of validation results. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with independent results
full rationale
The paper introduces ProofGrid as a benchmark suite and reports direct experimental outcomes from evaluating LLMs on machine-checkable proof tasks in minimal NDL notation. No derivation chain exists that reduces predictions or results to fitted inputs, self-definitions, or self-citation load-bearing premises. The Epistemic Stability Index is newly formalized from observed model behavior, 2PL IRT analyses apply standard psychometrics to the collected data, and the comparative framework situates the benchmark without invoking prior author results as uniqueness theorems. All central claims rest on reproducible verification pipelines and model outputs rather than any construction that equates outputs to inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Minimal formal notation (NDL) suffices to evaluate reasoning competence while minimizing domain knowledge and long-context effects
invented entities (2)
-
ProofGrid
no independent evidence
-
Epistemic Stability Index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Karl Popper: Critical Assessments of Leading Philosophers , publisher =
Alan Musgrave , title =. Karl Popper: Critical Assessments of Leading Philosophers , publisher =. 2003 , pages =
2003
-
[2]
Journal for General Philosophy of Science , year =
Musgrave, Alan , title =. Journal for General Philosophy of Science , year =
-
[3]
Argumentation , year =
Deductivism Within Pragma-Dialectics , author =. Argumentation , year =
-
[4]
1985 , publisher=
Item Response Theory: Principles and Applications , author=. 1985 , publisher=
1985
-
[5]
Handbook of Item Response Theory Modeling: Applications to Typical Performance Assessment , publisher =
-
[6]
Recherches sur la th
Herbrand, Jacques , year =. Recherches sur la th. Travaux de la Soci
-
[7]
1972 , publisher=
Introduction to Combinatory Logic , author=. 1972 , publisher=
1972
-
[8]
A tutorial on
Ly, Alexander and Myung, Jay and Pitt, Mark , journal=. A tutorial on. 2017 , doi=
2017
-
[9]
2013 , publisher=
Item Response Theory: Principles and Applications , author=. 2013 , publisher=
2013
-
[10]
Comptes Rendus des S
Tarski, Alfred , title =. Comptes Rendus des S. 1930 , note =
1930
-
[11]
IEEE Trans
Bengio, Yoshua and Courville, Aaron and Vincent, Pascal , title =. IEEE Trans. Pattern Anal. Mach. Intell. , pages =. 2013 , issue_date =
2013
-
[12]
International Conference on Learning Representations (ICLR) , year=
Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , booktitle =. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , url =
-
[14]
2010 , publisher=
Introduction to Mathematical Logic , author=. 2010 , publisher=
2010
-
[15]
Hambleton and Hariharan Swaminathan and H
Ronald K. Hambleton and Hariharan Swaminathan and H. Jane Rogers , title =
-
[16]
, title =
Spearman, C. , title =. The American Journal of Psychology , year =
-
[17]
Psychological Bulletin , volume=
The measurement of adult intelligence , author=. Psychological Bulletin , volume=. 1943 , publisher=
1943
-
[18]
1998 , publisher=
Universal Nonverbal Intelligence Test , author=. 1998 , publisher=
1998
-
[19]
and Dumont, Ron and Kaufman, Alan S
Walrath, Robert and Willis, John O. and Dumont, Ron and Kaufman, Alan S. , title =. The Cambridge Handbook of Intelligence , editor =. 2020 , publisher =
2020
-
[20]
Intelligence , volume=
CHC theory and the human cognitive abilities project: Standing on the shoulders of the giants of psychometric intelligence research , author=. Intelligence , volume=. 2009 , publisher=
2009
-
[21]
1939 , publisher=
The Measurement of Adult Intelligence , author=. 1939 , publisher=
1939
-
[22]
Intelligence , volume=
Raven's is not a pure measure of general intelligence: Implications for g factor theory and the brief measurement of g , author=. Intelligence , volume=. 2015 , publisher=
2015
-
[23]
McGrew, Kevin S. and Schneider, W. Joel and Decker, Scott L. and Bulut, Okan , journal=. A Psychometric Network Analysis of. 2023 , publisher=. doi:10.3390/jintelligence11010019 , url=
-
[24]
European Journal of Psychological Assessment , year =
Beauducel, André and Kersting, Martin , title =. European Journal of Psychological Assessment , year =. doi:10.1027//1015-5759.18.2.97 , url =
-
[25]
and Kell, Harrison J
Lakin, Joni M. and Kell, Harrison J. , title =. The Cambridge Handbook of Intelligence , editor =. 2020 , publisher =
2020
-
[26]
1993 , publisher=
Human Cognitive Abilities: A Survey of Factor-Analytic Studies , author=. 1993 , publisher=
1993
-
[27]
Journal of Educational Psychology , volume=
Theory of fluid and crystallized intelligence: A critical experiment , author=. Journal of Educational Psychology , volume=. 1963 , publisher=
1963
-
[28]
1927 , publisher =
Spearman, Charles , title =. 1927 , publisher =
1927
-
[29]
Ramirez and H
M. Ramirez and H. Geffner , title =. Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence (AAAI-10) , year =
-
[30]
C. L. Baker and R. Saxe and J. B. Tenenbaum , journal =. Action understanding as inverse planning , year =
-
[31]
Heim, Irene and Kratzer, Angelika , isbn =
-
[32]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[33]
2025 , eprint=
Dissecting Logical Reasoning in LLMs: A Fine-Grained Evaluation and Supervision Study , author=. 2025 , eprint=
2025
-
[34]
2025 , eprint=
TRAIL: Trace Reasoning and Agentic Issue Localization , author=. 2025 , eprint=
2025
-
[35]
AgentBench: Evaluating LLMs as Agents , url =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , booktitle...
-
[36]
Susan M. Barnett and Stephen J. Ceci , title =. 2002 , publisher =. doi:10.1037/0033-2909.128.4.612 , url =
-
[37]
2023 , publisher=
Introduction to Transfer Learning: Algorithms and Practice , author=. 2023 , publisher=
2023
-
[38]
2017 , publisher =
Konstantine Arkoudas and David Musser , title =. 2017 , publisher =
2017
-
[39]
Proceedings of the 22nd International Conference on Automated Deduction , pages =
Weidenbach, Christoph and Dimova, Dilyana and Fietzke, Arnaud and Kumar, Rohit and Suda, Martin and Wischnewski, Patrick , title =. Proceedings of the 22nd International Conference on Automated Deduction , pages =. 2009 , isbn =
2009
-
[40]
Publications Manual , year = "1983", publisher =
1983
-
[41]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[42]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[43]
2006 , url =
Geoff Sutcliffe and Stephan Schulz and Koen Claessen and Allen Van Gelder , editor =. 2006 , url =
2006
-
[44]
Explaining Answers with Entailment Trees
Dalvi, Bhavana and Jansen, Peter and Tafjord, Oyvind and Xie, Zhengnan and Smith, Hannah and Pipatanangkura, Leighanna and Clark, Peter. Explaining Answers with Entailment Trees. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.585
-
[45]
2005 , publisher =
Bos, Johan and Markert, Katja , editor =. 2005 , publisher =
2005
-
[46]
Kamp, Hans , booktitle =
-
[47]
Mathematical proceedings of the Cambridge philosophical society , volume=
On the structure of abstract algebras , author=. Mathematical proceedings of the Cambridge philosophical society , volume=. 1935 , organization=
1935
-
[48]
Tversky and D
A. Tversky and D. Kahneman , journal =
-
[49]
L ogic A sker: Evaluating and Improving the Logical Reasoning Ability of Large Language Models
Wan, Yuxuan and Wang, Wenxuan and Yang, Yiliu and Yuan, Youliang and Huang, Jen-tse and He, Pinjia and Jiao, Wenxiang and Lyu, Michael. L ogic A sker: Evaluating and Improving the Logical Reasoning Ability of Large Language Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.128
-
[50]
L ogi C o T : Logical Chain-of-Thought Instruction Tuning
Liu, Hanmeng and Teng, Zhiyang and Cui, Leyang and Zhang, Chaoli and Zhou, Qiji and Zhang, Yue. L ogi C o T : Logical Chain-of-Thought Instruction Tuning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.191
-
[51]
Proceedings of ICLR 2022 workshop on Objects, Structure and Causality , year=
Onta\. Proceedings of ICLR 2022 workshop on Objects, Structure and Causality , year=
2022
-
[52]
Research on Language and Computation , year =
Copestake, Ann and Flickinger, Dan and Pollard, Carl and Sag, Ivan , title =. Research on Language and Computation , year =
-
[53]
2005 , isbn =
Akhmatova, Elena and Moll\'. 2005 , isbn =
2005
-
[54]
Bos, Johan and Markert, Katja , TITLE =
-
[55]
Manning , TITLE =
Christopher D. Manning , TITLE =
-
[56]
Sinz, Carsten , title =. 2005 , publisher =. doi:10.1007/11564751_73 , booktitle =
-
[57]
Alon Albalak and Duy Phung and Nathan Lile and Rafael Rafailov and Kanishk Gandhi and Louis Castricato and Anikait Singh and Chase Blagden and Violet Xiang and Dakota Mahan and Nick Haber , year=. 2502.17387 , archivePrefix=
-
[58]
Lauria, M. and Elffers, Jan and Nordstr. CNFgen : A generator of crafted benchmarks , series =. 20th International Conference on Theory and Applications of Satisfiability Testing, SAT 2017 , institution =. doi:10.1007/978-3-319-66263-3_30 , year =
-
[59]
2025 , month=
Anthropic , TITLE =. 2025 , month=
2025
-
[60]
Journal of Automated Reasoning , month =
Arkoudas, Konstantine , title =. Journal of Automated Reasoning , month =. 2005 , publisher =
2005
-
[61]
2025 , month=
Google , TITLE =. 2025 , month=
2025
-
[62]
Dan Gusfield , title =. 1997
1997
-
[63]
Buss and J
S. Buss and J. Nordström , title =. Handbook of Satisfiability , publisher =
-
[64]
Annual Conference on Neural Information Processing Systems , year=
Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus , author=. Annual Conference on Neural Information Processing Systems , year=
-
[65]
and Angeli, Gabor and Potts, Christopher and Manning, Christopher D
Bowman, Samuel R. and Angeli, Gabor and Potts, Christopher and Manning, Christopher D. A large annotated corpus for learning natural language inference. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1075
-
[66]
2023 , editor =
Morishita, Terufumi and Morio, Gaku and Yamaguchi, Atsuki and Sogawa, Yasuhiro , booktitle =. 2023 , editor =
2023
-
[67]
P roof W riter: Generating Implications, Proofs, and Abductive Statements over Natural Language
Tafjord, Oyvind and Dalvi, Bhavana and Clark, Peter. P roof W riter: Generating Implications, Proofs, and Abductive Statements over Natural Language. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021
2021
-
[68]
Pushing the Limits of Rule Reasoning in Transformers through Natural Language Satisfiability
Richardson, Kyle and Sabharwal, Ashish. Pushing the Limits of Rule Reasoning in Transformers through Natural Language Satisfiability. Proceedings of the AAAI Conference on Artificial Intelligence. 2022
2022
-
[69]
Recognizing textual entailment: Rational, evaluation and approaches , url =
Dagan, Ido and Dolan, Bill and Magnini, Bernardo and Roth, Dan , journal =. Recognizing textual entailment: Rational, evaluation and approaches , url =
-
[70]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,
Logically Consistent Adversarial Attacks for Soft Theorem Provers , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , month =
2022
-
[71]
2021 , booktitle =
Clark, Peter and Tafjord, Oyvind and Richardson, Kyle , title =. 2021 , booktitle =
2021
-
[72]
2023 , url=
Abulhair Saparov and He He , booktitle=. 2023 , url=
2023
-
[73]
T heorem QA : A Theorem-driven Question Answering Dataset
Chen, Wenhu and Yin, Ming and Ku, Max and Lu, Pan and Wan, Yixin and Ma, Xueguang and Xu, Jianyu and Wang, Xinyi and Xia, Tony. T heorem QA : A Theorem-driven Question Answering Dataset. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
-
[74]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark and Isaac Cowhey and Oren Etzioni and Tushar Khot and Ashish Sabharwal and Carissa Schoenick and Oyvind Tafjord , title =. arXiv:1803.05457v1 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
Diagnosing the First-Order Logical Reasoning Ability Through L ogic NLI
Tian, Jidong and Li, Yitian and Chen, Wenqing and Xiao, Liqiang and He, Hao and Jin, Yaohui. Diagnosing the First-Order Logical Reasoning Ability Through L ogic NLI. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021
2021
-
[76]
A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference
Williams, Adina and Nangia, Nikita and Bowman, Samuel. A Broad-Coverage Challenge Corpus for Sentence Understanding through Inference. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018
2018
-
[77]
IEEE/ACM Trans
Liu, Hanmeng and Liu, Jian and Cui, Leyang and Teng, Zhiyang and Duan, Nan and Zhou, Ming and Zhang, Yue , title =. IEEE/ACM Trans. Audio, Speech and Lang. Proc. , month = jul, pages =. 2023 , issue_date =
2023
-
[78]
FOLIO : Natural Language Reasoning with First-Order Logic
Han, Simeng and Schoelkopf, Hailey and Zhao, Yilun and Qi, Zhenting and Riddell, Martin and Zhou, Wenfei and Coady, James and Peng, David and Qiao, Yujie and Benson, Luke and Sun, Lucy and Wardle-Solano, Alexander and Szab. FOLIO : Natural Language Reasoning with First-Order Logic. Proceedings of the 2024 Conference on Empirical Methods in Natural Languag...
2024
-
[79]
Athena: A Language for Proof Engineering , howpublished =
-
[80]
and Bommasani, R
Liang, P. and Bommasani, R. and Lee, T. and Tsipras, D. and Soylu, D. and Yasunaga, M. and Zhang, Y. and Narayanan, D. and Wu, Y. and Kumar, A. and Newman, B. and Yuan, B. and Yan, B. and Zhang, C. and Cosgrove, C. and Manning, C. D and Re, C. and Acosta-Navas, D. and Hudson, D. A. and Zelikman, E. and Durmus, E. and Ladhak, F. and Rong, F. and Ren, H. an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.