Recognition: unknown
OverrideFuzz: Semantic-Aware Grammar Fuzzing for Script-Runtime Vulnerabilities
Pith reviewed 2026-05-14 20:56 UTC · model grok-4.3
The pith
OverrideFuzz uses two-phase semantic-aware grammar fuzzing to reach script runtime boundary behaviors that trigger known vulnerability patterns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OverrideFuzz is a two-phase semantic-aware grammar fuzzer whose declaration phase constructs objects with overriding methods and whose execution phase generates operations routed through those hooks, using active reflection to track runtime types and passive reflection from error messages to remove invalid operation shapes, so that generation reaches the script-native boundary behaviors that can trigger use-after-free or type-confusion bugs; on CPython, Lua, and QuickJS the approach produces consistent coverage growth and a corpus that reconstructs inputs matching known vulnerability patterns.
What carries the argument
Two-phase declaration and execution process with active type tracking and passive error-message reflection to filter operation shapes while preserving boundary-triggering ones.
Where Pith is reading between the lines
- Longer runs could surface previously unknown vulnerabilities once the corpus stabilizes.
- The same declaration-plus-execution pattern could transfer to other dynamic languages that expose metamethods or prototype overrides.
- Coverage plateaus suggest that adding explicit modeling of object lifetime or garbage-collection hooks would be a direct next step.
Load-bearing premise
That error messages supply enough detail to discard only invalid shapes without removing all operation shapes that could actually trigger boundary bugs, and that the short evaluation window is long enough to reveal the fuzzer's reach.
What would settle it
Extend the evaluation window on CPython, Lua, or QuickJS and check whether any newly generated inputs trigger use-after-free or type-confusion bugs that were not found by prior grammar or reflection-based fuzzers.
Figures
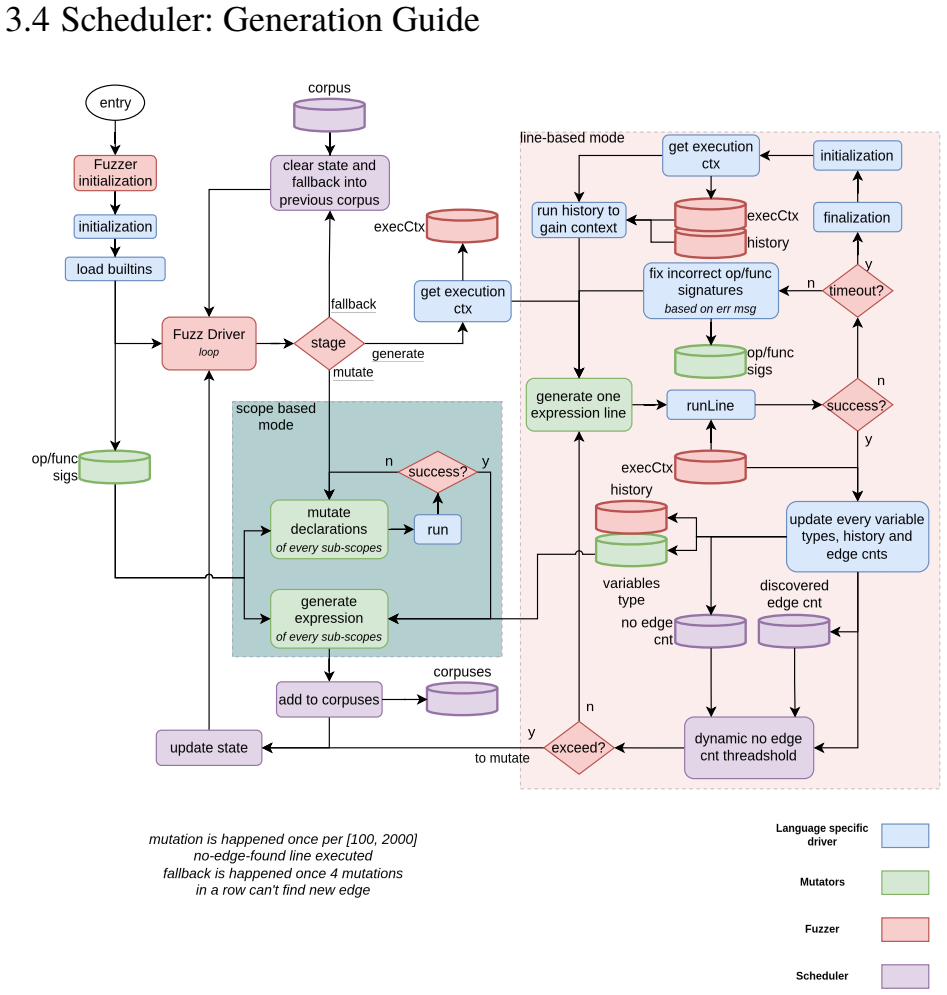



read the original abstract
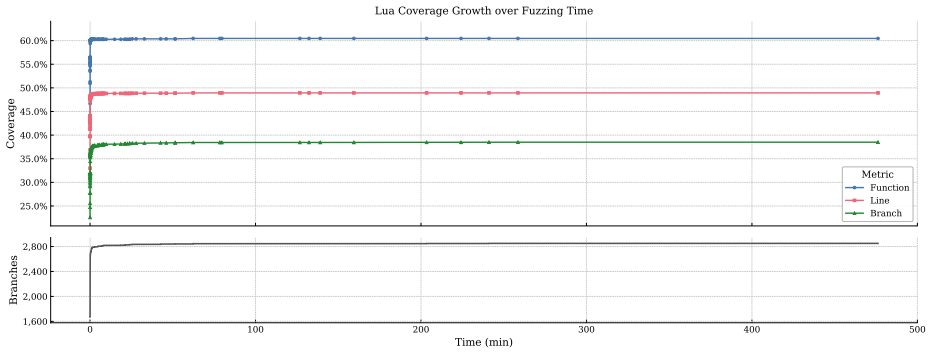
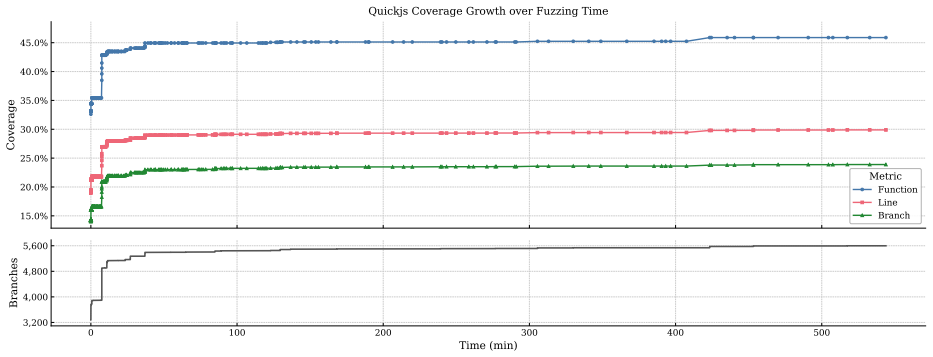
Script-language runtimes such as Python, Lua, and JavaScript are widely deployed in security sensitive contexts, yet they remain difficult to test because valid inputs must satisfy syntax, dynamic type constraints, and object-level semantics. Existing grammar and reflection-based fuzzers improve syntactic validity and interface reachability, but they rarely model override hooks, dynamic rebinding, and attribute-resolution behavior that can redirect built-in operations across the script-native boundary and trigger use-after-free or type-confusion bugs. We present OverrideFuzz, a two-phase, semantic-aware grammar fuzzer for script-language runtimes. Its declaration phase constructs objects with overriding methods, while its execution phase generates operations that route through those hooks. Active reflection tracks runtime types, and passive reflection learns from error messages to remove invalid operation shapes, allowing generation to approach semantic correctness without manual API specification. We evaluate OverrideFuzz on CPython, Lua, and QuickJS. All three targets show consistent coverage growth, with rapid early expansion followed by slower incremental gains, and Lua benefits most from its pervasive metamethod dispatch mechanism. Although OverrideFuzz did not discover novel vulnerabilities during the bounded evaluation period, corpus analysis shows that it reconstructs inputs matching known vulnerability patterns, which suggests that semantic-aware generation reaches the intended script-native boundary behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. OverrideFuzz is a two-phase semantic-aware grammar fuzzer for script-language runtimes (CPython, Lua, QuickJS) that constructs objects with overriding methods in a declaration phase and generates operations routed through those hooks in an execution phase. Active reflection tracks runtime types while passive reflection learns from error messages to prune invalid operation shapes, enabling semantic correctness without manual API specifications. Evaluation reports consistent coverage growth across targets (with Lua benefiting most from metamethod dispatch) and corpus analysis showing reconstruction of inputs that match known vulnerability patterns, although no novel vulnerabilities were discovered during the bounded evaluation period.
Significance. If the two-phase approach with passive reflection successfully models override hooks, dynamic rebinding, and attribute resolution to reach script-native boundary behaviors, it would advance automated testing of widely deployed script runtimes for use-after-free and type-confusion issues. The reported reconstruction of known vulnerability patterns provides concrete evidence that generation reaches intended semantic boundaries, and the absence of free parameters or fitted constants in the core mechanism is a strength; however, the lack of new discoveries and limited analysis of pruning effects reduce the demonstrated security impact.
major comments (2)
- [Abstract] Abstract: the central claim that passive reflection removes only invalid shapes while preserving all operation shapes capable of triggering boundary bugs is not supported by any reported analysis of pruned shapes or ablation that re-inserts them to measure lost coverage of boundary behaviors; this assumption is load-bearing for the reachability argument.
- [Evaluation] Evaluation (implied in abstract description of bounded runs): the corpus analysis reconstructs inputs matching known patterns, but the short bounded evaluation found no new vulnerabilities and provides no quantitative detail on how error-based pruning avoids false negatives on shapes that would trigger use-after-free or type-confusion when overriding methods are active.
minor comments (1)
- The description of coverage growth as 'rapid early expansion followed by slower incremental gains' would be strengthened by explicit reference to the time-series data or plots that support this characterization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on OverrideFuzz. We address each major comment below, clarifying the design rationale for passive reflection and the scope of our evaluation claims. We commit to revisions that strengthen the presentation without overstating results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that passive reflection removes only invalid shapes while preserving all operation shapes capable of triggering boundary bugs is not supported by any reported analysis of pruned shapes or ablation that re-inserts them to measure lost coverage of boundary behaviors; this assumption is load-bearing for the reachability argument.
Authors: We agree that an explicit analysis of pruned shapes and an ablation re-inserting them would provide stronger support for the reachability claim. Passive reflection prunes solely on the basis of runtime error messages that signal early invalidity (e.g., type or attribute errors) before native dispatch occurs. By construction, any shape that successfully invokes an overriding method and reaches a use-after-free or type-confusion boundary would not emit such an error and therefore would not be pruned. We did not perform the ablation because of the prohibitive cost of re-running full campaigns with unpruned shape sets. We will revise the abstract and add a limitations paragraph that states this assumption explicitly. revision: partial
-
Referee: [Evaluation] Evaluation (implied in abstract description of bounded runs): the corpus analysis reconstructs inputs matching known patterns, but the short bounded evaluation found no new vulnerabilities and provides no quantitative detail on how error-based pruning avoids false negatives on shapes that would trigger use-after-free or type-confusion when overriding methods are active.
Authors: The manuscript already states that no new vulnerabilities were found in the bounded window. The corpus reconstruction of known vulnerability patterns supplies concrete evidence that the two-phase generation reaches the intended semantic boundaries. Error-based pruning cannot produce false negatives on bug-triggering shapes because those shapes execute the override hooks without generating the pruning errors. We lack quantitative false-negative measurements because constructing an oracle for all possible boundary-triggering shapes is infeasible. We will expand the evaluation section with further description of the pruning process, its effect on corpus validity rates, and coverage curves with and without passive reflection where feasible. revision: partial
Circularity Check
No circularity: empirical observations only
full rationale
The paper presents OverrideFuzz as a two-phase grammar fuzzer whose claims rest on experimental coverage measurements and corpus reconstruction of known vulnerability patterns. No equations, fitted parameters, or derivations are introduced that reduce to the inputs by construction. Passive reflection is described as a heuristic for pruning invalid shapes, but this is presented as an engineering choice whose effectiveness is evaluated empirically rather than proven via self-referential logic or self-citation chains. The central suggestion that semantic-aware generation reaches boundary behaviors is tied directly to observable corpus matches, not to any renamed known result or ansatz smuggled through prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Active and passive reflection on runtime types and error messages can approach semantic correctness without manual API specifications.
Reference graph
Works this paper leans on
-
[1]
Integrating formal methods and automated tools for DO-178C compliance in UA V software,
R. Zrelli et al., “Integrating formal methods and automated tools for DO-178C compliance in UA V software,” Information and Software Technology, vol. 194, p. 108068, 2026, doi: https://doi.org/10.1016/j.infsof.2026.108068
-
[2]
LLVM Project, “Clang Static Analyzer.” Accessed: Apr. 20, 2026. [Online]. Available: https://clang-analyzer.llvm.org/
work page 2026
-
[3]
SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis,
Y. Shoshitaishvili et al., “SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis,” in 2016 IEEE Symposium on Security and Privacy (SP), 2016, pp. 138–157. doi: 10.1109/SP.2016.17
-
[4]
FUZZILLI: Fuzzing for JavaScript JIT Compiler Vulnerabilities,
S. Groß, S. Koch, L. Bernhard, T. Holz, and M. Johns, “FUZZILLI: Fuzzing for JavaScript JIT Compiler Vulnerabilities,” in Proceedings 2023 Network and Distributed System Security Symposium, San Diego, CA, USA: Internet Society, 2023. doi: 10.14722/ndss.2023.24290
-
[5]
NAUTILUS: Fishing for Deep Bugs with Grammars,
C. Aschermann, T. Holz, P. Jauernig, A.-R. Sadeghi, and D. Teuchert, “NAUTILUS: Fishing for Deep Bugs with Grammars,” in Proceedings 2019 Network and Distributed System Secu- rity Symposium, San Diego, CA: Internet Society, 2019. doi: 10.14722/ndss.2019.23412
-
[6]
One Engine to Fuzz 'em All: Generic Language Processor Testing with Semantic Validation,
Y. Chen et al., “One Engine to Fuzz 'em All: Generic Language Processor Testing with Semantic Validation,” in 2021 IEEE Symposium on Security and Privacy (SP) , 2021, pp. 642–658. doi: 10.1109/SP40001.2021.00071
-
[7]
PatchFuzz: Patch Fuzzing for JavaScript Engines,
J. Wang, Z. Xie, X. Xie, X. Du, and X. Zhang, “PatchFuzz: Patch Fuzzing for JavaScript Engines,” Information and Software Technology , vol. 194, p. 108087, June 2026, doi: 10.1016/j.infsof.2026.108087
-
[8]
REFLECTA: Reflection-based Scalable and Semantic Scripting Language Fuzzing,
C. Zhang, G. Lee, Q. Liu, and M. Payer, “REFLECTA: Reflection-based Scalable and Semantic Scripting Language Fuzzing,” in Proceedings ASIA CCS '25 , Hanoi, Vietnam,
-
[9]
doi: 10.1145/3708821.3710818
-
[10]
AFL++ : Combining Incremental Steps of Fuzzing Research,
A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “AFL++ : Combining Incremental Steps of Fuzzing Research,” in 14th USENIX Workshop on Offensive Technologies (WOOT 29 20), USENIX Association, Aug. 2020. [Online]. Available: https://www.usenix.org/ conference/woot20/presentation/fioraldi
work page 2020
-
[11]
Superion: Grammar-Aware Greybox Fuzzing,
J. Wang, B. Chen, L. Wei, and Y. Liu, “Superion: Grammar-Aware Greybox Fuzzing,” in 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE) , 2019, pp. 724–735. doi: 10.1109/ICSE.2019.00081
-
[12]
Python interpreter fuzzing using AST-base mutators, based on LibFuzzer
Y. Qiu, “Python interpreter fuzzing using AST-base mutators, based on LibFuzzer.” Accessed: Apr. 20, 2026. [Online]. Available: https://github.com/Nambers/CPython-AST- Fuzzer
work page 2026
-
[13]
UAF when writing to a bytearray with an element implementing __index__ with side-ef- fects
“UAF when writing to a bytearray with an element implementing __index__ with side-ef- fects.” Accessed: Apr. 20, 2026. [Online]. Available: https://github.com/python/cpython/ issues/91153
work page 2026
-
[14]
There is a way to access an underlying mapping in MappingProxyType
“There is a way to access an underlying mapping in MappingProxyType.” Accessed: Apr. 20, 2026. [Online]. Available: https://github.com/python/cpython/issues/88004
work page 2026
-
[15]
The Zephyr abstract syntax description language,
D. C. Wang, A. W. Appel, J. L. Korn, and C. S. Serra, “The Zephyr abstract syntax description language,” in Proceedings of the Conference on Domain-Specific Languages on Conference on Domain-Specific Languages (DSL), 1997 , in DSL'97. Santa Barbara, California: USENIX Association, 1997, p. 17
work page 1997
-
[16]
LLVM Project, “SanitizerCoverage.” Accessed: Apr. 20, 2026. [Online]. Available: https:// clang.llvm.org/docs/SanitizerCoverage.html
work page 2026
-
[17]
Nix & NixOS | Declarative builds and deployments
NixOS contributors, “Nix & NixOS | Declarative builds and deployments..” Accessed: Apr. 20, 2026. [Online]. Available: https://nixos.org/
work page 2026
-
[18]
Python Software Foundation, “release 3.14.3 python/cpython.” Accessed: Apr. 20, 2026. [Online]. Available: https://github.com/python/cpython/releases/tag/v3.14.3
work page 2026
-
[19]
Lua Team, “Lua: version history.” Accessed: Apr. 20, 2026. [Online]. Available: https:// www.lua.org/versions.html#5.5
work page 2026
-
[20]
F. Bellard, “QuickJS binary releases.” Accessed: Apr. 20, 2026. [Online]. Available: https:// bellard.org/quickjs/binary_releases/ 30
work page 2026
-
[21]
ECMAScript 2023 Language Specification
Ecma International, “ECMAScript 2023 Language Specification.” Accessed: Apr. 20, 2026. [Online]. Available: https://tc39.es/ecma262/2023/
work page 2023
-
[22]
Evaluating and mitigating the growing risk of LLM-discovered 0-days
N. Carlini et al., “Evaluating and mitigating the growing risk of LLM-discovered 0-days.” Accessed: Apr. 20, 2026. [Online]. Available: https://red.anthropic.com/2026/zero-days/
work page 2026
-
[23]
SoK: DARPA's AI Cyber Challenge (AIxCC): Competition Design, Archi- tectures, and Lessons Learned,
C. Zhang et al., “SoK: DARPA's AI Cyber Challenge (AIxCC): Competition Design, Archi- tectures, and Lessons Learned,” no. arXiv:2602.07666. arXiv, Feb. 2026. doi: 10.48550/ arXiv.2602.07666. 31 APPENDIX A Override Functions Reference The table below shows representative examples of override functions discovered by OverrideFuzz’s active reflection phase fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.