Recognition: unknown
MLPs are Efficient Distilled Generative Recommenders
Pith reviewed 2026-05-14 20:10 UTC · model grok-4.3
The pith
Distilling generative recommenders into MLPs preserves accuracy while speeding up inference by 8.74x
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standard Transformer decoders are structural overkill for Semantic ID generative recommendation because prediction difficulty drops sharply after the first token due to their hierarchy. SID-MLP captures global user context in a single operation decoupled from sequential prediction and distills the heavy autoregressive teacher into position-specific MLP heads. This eliminates dense attention overhead while preserving prefix and context dependencies, matching teacher accuracy with 8.74x faster inference and serving as a plug-and-play accelerator for various backbones.
What carries the argument
SID-MLP distillation framework that replaces the Transformer decoder with position-specific MLP heads after capturing user context once.
If this is right
- This serves as a plug-and-play accelerator for different backbones and tokenizer settings.
- SID-MLP++ extends the framework to replace the Transformer encoder for further latency reductions.
- Decoder-side MLPs distillation is an effective acceleration path for structured SID recommendation.
- Full encoder replacement offers an additional speed-accuracy trade-off.
Where Pith is reading between the lines
- The approach could extend to other recommendation or prediction tasks with hierarchical token structures where early predictions are hardest.
- Real-world systems might adopt this for lower latency in serving recommendations without retraining from scratch.
- It raises the question of whether attention is overused in other autoregressive setups with structured outputs.
Load-bearing premise
The hierarchical nature of SIDs makes prediction difficulty drop sharply after the first token, rendering repeated attention computations highly redundant.
What would settle it
Observing that the recommendation quality of the MLP-distilled model falls short of the teacher model on held-out data or that the measured inference speedup is substantially below 8.74x.
Figures


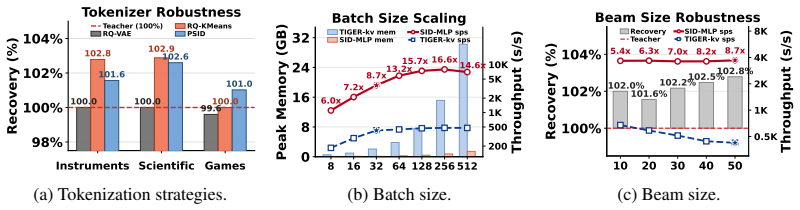


read the original abstract
Generative recommendation models employing Semantic IDs (SIDs) exhibit strong potential, yet their practical deployment is bottlenecked by the high inference latency of beam-expanded autoregressive decoding. In this work, we identify that standard attention-heavy Transformer decoders represent a structural overkill for this task: the hierarchical nature of SIDs makes prediction difficulty drops sharply after the first token, rendering repeated attention computations highly redundant. Driven by this insight, we propose SID-MLP, a lightweight MLP-centric distillation framework that fundamentally simplifies the decoding paradigm for GR. Instead of executing complex, step-by-step attention mechanisms, our approach captures the global user context in a single operation, decoupled from sequential token prediction. We then distill the heavy autoregressive teacher into position-specific MLP heads, eliminating the dense attention overhead while preserving prefix and context dependencies. Extensive experiments demonstrate that SID-MLP matches the accuracy of teacher models while accelerating inference by 8.74x. Crucially, this distillation strategy can serve as a plug-and-play accelerator for different backbones and tokenizer settings. Furthermore, we introduce SID-MLP++, extending our distillation framework to replace the Transformer encoder, unlocking further latency reductions. Ultimately, our work reveals that decoder-side MLPs distillation is an effective acceleration path for structured SID recommendation, while full encoder replacement offers an additional speed--accuracy trade-off.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SID-MLP, a distillation framework that replaces autoregressive attention-based decoding in Semantic ID (SID) generative recommenders with position-specific MLPs. It claims that the hierarchical nature of SIDs causes prediction difficulty to drop sharply after the first token, rendering repeated attention redundant; the approach captures global user context in one step and distills the teacher into lightweight MLP heads. Experiments reportedly show SID-MLP matches teacher accuracy while achieving 8.74x inference speedup, with an extension (SID-MLP++) that also replaces the Transformer encoder for further gains. The method is positioned as a plug-and-play accelerator across backbones and tokenizers.
Significance. If the empirical results hold under rigorous validation, the work provides a practical acceleration technique for SID-based generative recommenders, potentially improving deployability by reducing inference latency with minimal accuracy loss. The distillation strategy's claimed generality across architectures would be a useful contribution to efficient inference methods in recommendation systems.
major comments (3)
- [Abstract] Abstract: The core assumption that 'the hierarchical nature of SIDs makes prediction difficulty drops sharply after the first token' is presented without any per-position quantitative validation (e.g., token-wise accuracy, loss curves, or difficulty metrics for the teacher on positions 2+). This assumption directly justifies replacing autoregressive attention with independent MLPs and is load-bearing for both the accuracy-matching and 8.74x speedup claims.
- [Experiments] Experimental results: The reported matching accuracy and 8.74x speedup lack essential details on datasets, baseline models, number of runs, error bars, and exact inference-time measurement protocol. These omissions prevent assessment of whether the central empirical claims are robust or reproducible.
- [SID-MLP++] SID-MLP++ extension: Replacing the full Transformer encoder with the distillation framework requires additional justification and ablations on how prefix/context dependencies are preserved without attention, as this change is more substantial than decoder-only replacement and directly affects the claimed further latency reductions.
minor comments (2)
- [Abstract] Abstract contains a grammatical error: 'makes prediction difficulty drops' should read 'makes prediction difficulty drop'.
- [Abstract] The 'plug-and-play' claim would be strengthened by explicit discussion of the conditions (e.g., tokenizer settings or backbone types) under which the distillation succeeds without retraining.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below. Where the comments identify gaps in the initial submission, we will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The core assumption that 'the hierarchical nature of SIDs makes prediction difficulty drops sharply after the first token' is presented without any per-position quantitative validation (e.g., token-wise accuracy, loss curves, or difficulty metrics for the teacher on positions 2+). This assumption directly justifies replacing autoregressive attention with independent MLPs and is load-bearing for both the accuracy-matching and 8.74x speedup claims.
Authors: We agree that explicit per-position quantitative validation strengthens the justification. The manuscript provides overall empirical support for the hierarchical property through end-to-end results, but does not include dedicated token-wise accuracy or loss curves for the teacher. In the revised version we will add these analyses (token-wise accuracy and per-position loss for the teacher on positions 2+) to directly validate the assumption. revision: yes
-
Referee: [Experiments] Experimental results: The reported matching accuracy and 8.74x speedup lack essential details on datasets, baseline models, number of runs, error bars, and exact inference-time measurement protocol. These omissions prevent assessment of whether the central empirical claims are robust or reproducible.
Authors: We acknowledge that the initial submission omitted several experimental details for brevity. In the revision we will expand the experimental section to specify the exact datasets, baseline models, number of runs (5), error bars (standard deviation across runs), and the inference-time protocol (single A100 GPU, batch size 1, wall-clock time averaged over 1000 inferences after warmup). revision: yes
-
Referee: [SID-MLP++] SID-MLP++ extension: Replacing the full Transformer encoder with the distillation framework requires additional justification and ablations on how prefix/context dependencies are preserved without attention, as this change is more substantial than decoder-only replacement and directly affects the claimed further latency reductions.
Authors: We agree that the SID-MLP++ extension requires more justification and ablations. The current manuscript describes the extension at a high level but lacks explicit analysis of dependency preservation. In the revision we will add a dedicated subsection with justification and ablations (including comparisons to partial-attention variants) demonstrating that global context capture plus position-specific distillation preserves prefix dependencies while delivering the reported latency gains. revision: yes
Circularity Check
No circularity; claims rest on direct empirical measurements of distillation
full rationale
The paper proposes SID-MLP as a distillation framework motivated by an observed property of hierarchical SIDs, then validates it through experiments comparing accuracy and latency against teacher models. No derivation chain reduces a claimed prediction to fitted inputs by construction, no self-citation is load-bearing for a uniqueness theorem, and no ansatz is smuggled via prior work. The speedup and matching-accuracy results are presented as measured outcomes rather than algebraic identities or renamed fits. The central assumption about per-token difficulty is treated as an empirical premise whose consequences are tested externally, keeping the work self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The hierarchical nature of SIDs makes prediction difficulty drop sharply after the first token.
invented entities (1)
-
SID-MLP
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Transformer memory as a differentiable search index
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. Transformer memory as a differentiable search index. volume 35, pages 21831–21843, 2022
2022
-
[2]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Mahesh Sathiamoorthy. Recommender systems with generative retrieval. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing System...
2023
-
[3]
Adapting large language models by integrating collaborative semantics for recommenda- tion
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommenda- tion. In40th IEEE International Conference on Data Engineering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024. IEEE, 2024
2024
-
[4]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Session-based recommendations with recurrent neural networks
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks. 2016
2016
-
[6]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. 2018
2018
-
[7]
Plum: Adapting pre-trained language models for industrial-scale generative recommendations
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al. Plum: Adapting pre-trained language models for industrial-scale generative recommendations. InProceedings of the ACM Web Conference 2026, pages 8093–8104, 2026
2026
-
[8]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. 2023
2023
-
[9]
Lee, Deming Chen, and Tri Dao
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple llm inference acceleration framework with multiple decoding heads. 2024
2024
-
[10]
Eagle: Speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty. 2025
2025
-
[11]
Efficient inference for large language model-based generative recommendation
Xinyu Lin, Chaoqun Yang, Wenjie Wang, Yongqi Li, Cunxiao Du, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Efficient inference for large language model-based generative recommendation. 2024
2024
-
[12]
Generating long semantic ids in parallel for recom- mendation
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. Generating long semantic ids in parallel for recom- mendation. 2025
2025
-
[13]
Nezha: A zero-sacrifice and hyperspeed decoding architecture for generative recommendations
Yejing Wang, Shengyu Zhou, Jinyu Lu, Ziwei Liu, Langming Liu, Maolin Wang, Wenlin Zhang, Feng Li, Wenbo Su, Pengjie Wang, Jian Xu, and Xiangyu Zhao. Nezha: A zero-sacrifice and hyperspeed decoding architecture for generative recommendations. 2026
2026
-
[14]
Non- autoregressive generative models for reranking recommendation
Yuxin Ren, Qiya Yang, Yichun Wu, Wei Xu, Yalong Wang, and Zhiqiang Zhang. Non- autoregressive generative models for reranking recommendation. 2025
2025
-
[15]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. 2015
2015
-
[16]
Graph-less neural networks: Teaching old mlps new tricks via distillation
Shichang Zhang, Yozen Liu, Yizhou Sun, and Neil Shah. Graph-less neural networks: Teaching old mlps new tricks via distillation. 2022
2022
-
[17]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A survey of large language models.arXiv preprint arXiv:2303.18223, 2023. 10
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Filter-enhanced MLP is all you need for sequential recommendation
Kun Zhou, Hui Yu, Wayne Xin Zhao, and Ji-Rong Wen. Filter-enhanced MLP is all you need for sequential recommendation. InWWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, 2022
2022
-
[19]
Bridging language and items for retrieval and recommendation: Benchmarking llms as semantic encoders
Yupeng Hou, Jiacheng Li, Xiangjun Fu, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation: Benchmarking llms as semantic encoders. 2026
2026
-
[20]
EARN: efficient inference acceleration for llm-based generative recommendation by register tokens.CoRR, 2025
Chaoqun Yang, Xinyu Lin, Wenjie Wang, Yongqi Li, Teng Sun, Xianjing Han, and Tat-Seng Chua. EARN: efficient inference acceleration for llm-based generative recommendation by register tokens.CoRR, 2025
2025
-
[21]
Gated delta networks: Improving mamba2 with delta rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. 2025
2025
-
[22]
Transformers are ssms: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. 2024
2024
-
[23]
Generative recommendation with semantic ids: A practitioner’s handbook
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. Generative recommendation with semantic ids: A practitioner’s handbook. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6420–6425, 2025
2025
-
[24]
Autoregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11523–11532, 2022
2022
-
[25]
Ruohan Zhang, Jiacheng Li, Julian McAuley, and Yupeng Hou. Purely semantic indexing for llm-based generative recommendation and retrieval.arXiv preprint arXiv:2509.16446, 2025
-
[26]
Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5)
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). InProceedings of the 16th ACM Conference on Recommender Systems, 2022
2022
-
[27]
Aleksandr V . Petrov and Craig Macdonald. Generative sequential recommendation with gptrec. arXiv preprint arXiv:2306.11114, 2023
-
[28]
Actions speak louder than words: Trillion- parameter sequential transducers for generative recommendations
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. Actions speak louder than words: Trillion- parameter sequential transducers for generative recommendations. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, 2024
2024
-
[29]
Liu Yang, Fabian Paischer, Kaveh Hassani, Jiacheng Li, Shuai Shao, Zhang Gabriel Li, Yun He, Xue Feng, Nima Noorshams, Sem Park, et al. Unifying generative and dense retrieval for sequential recommendation.arXiv preprint arXiv:2411.18814, 2024
-
[30]
How to index item ids for recommendation foundation models
Wenyue Hua, Shuyuan Xu, Yingqiang Ge, and Yongfeng Zhang. How to index item ids for recommendation foundation models. InProceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pages 195–204, 2023
2023
-
[31]
Eager: Two-stream generative recommender with behavior-semantic collaboration
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, et al. Eager: Two-stream generative recommender with behavior-semantic collaboration. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3245–3254, 2024
2024
-
[32]
Cost: Contrastive quantization based semantic tokenization for generative recommendation
Jieming Zhu, Mengqun Jin, Qijiong Liu, Zexuan Qiu, Zhenhua Dong, and Xiu Li. Cost: Contrastive quantization based semantic tokenization for generative recommendation. In Proceedings of the 18th ACM Conference on Recommender Systems, pages 969–974, 2024
2024
-
[33]
Penglong Zhai, Yifang Yuan, Fanyi Di, Jie Li, Yue Liu, Chen Li, Jie Huang, Sicong Wang, Yao Xu, and Xin Li. A simple contrastive framework of item tokenization for generative recommendation.arXiv preprint arXiv:2506.16683, 2025. 11
-
[34]
Tianxin Wei, Xuying Ning, Xuxing Chen, Ruizhong Qiu, Yupeng Hou, Yan Xie, Shuang Yang, Zhigang Hua, and Jingrui He. Cofirec: Coarse-to-fine tokenization for generative recommendation.arXiv preprint arXiv:2511.22707, 2025
-
[35]
Bridging textual-collaborative gap through semantic codes for sequential recommendation
Enze Liu, Bowen Zheng, Wayne Xin Zhao, and Ji-Rong Wen. Bridging textual-collaborative gap through semantic codes for sequential recommendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 1788–1798, 2025
2025
-
[36]
Actionpiece: Contextually tokenizing action sequences for generative recommendation
Yupeng Hou, Jianmo Ni, Zhankui He, Noveen Sachdeva, Wang-Cheng Kang, Ed H Chi, Julian McAuley, and Derek Zhiyuan Cheng. Actionpiece: Contextually tokenizing action sequences for generative recommendation. 2025
2025
-
[37]
Qiyong Zhong, Jiajie Su, Yunshan Ma, Julian McAuley, and Yupeng Hou. Pctx: Tokenizing personalized context for generative recommendation.arXiv preprint arXiv:2510.21276, 2025
-
[38]
Multi-behavior generative recommendation
Zihan Liu, Yupeng Hou, and Julian McAuley. Multi-behavior generative recommendation. InProceedings of the 33rd ACM international conference on information and knowledge management, pages 1575–1585, 2024
2024
-
[39]
Han Liu, Yinwei Wei, Xuemeng Song, Weili Guan, Yuan-Fang Li, and Liqiang Nie. Mm- grec: Multimodal generative recommendation with transformer model.arXiv preprint arXiv:2404.16555, 2024
-
[40]
Multimodal quantitative language for generative recommendation
Jianyang Zhai, Zi-Feng Mai, Chang-Dong Wang, Feidiao Yang, Xiawu Zheng, Hui Li, and Yonghong Tian. Multimodal quantitative language for generative recommendation. 2025
2025
-
[41]
Multi-aspect cross-modal quantization for generative recommendation
Fuwei Zhang, Xiaoyu Liu, Dongbo Xi, Jishen Yin, Huan Chen, Peng Yan, Fuzhen Zhuang, and Zhao Zhang. Multi-aspect cross-modal quantization for generative recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 16271–16279, 2026
2026
-
[42]
Jing Zhu, Mingxuan Ju, Yozen Liu, Danai Koutra, Neil Shah, and Tong Zhao. Beyond unimodal boundaries: Generative recommendation with multimodal semantics.arXiv preprint arXiv:2503.23333, 2025
-
[43]
Learnable item tokenization for generative recommendation
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Learnable item tokenization for generative recommendation. 2025
2025
-
[44]
Generative recommender with end-to-end learnable item tokenization
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao. Generative recommender with end-to-end learnable item tokenization. InProceedings of the 48th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, pages 729–739, 2025
2025
-
[45]
Bi-Level Optimization for Generative Recommendation: Bridging Tokenization and Generation
Yimeng Bai, Chang Liu, Yang Zhang, Dingxian Wang, Frank Yang, Andrew Rabinovich, Wenge Rong, and Fuli Feng. Bi-level optimization for generative recommendation: Bridging tokenization and generation.arXiv preprint arXiv:2510.21242, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Huanjie Wang, Xinchen Luo, Honghui Bao, Zhang Zixing, Lejian Ren, Yunfan Wu, Hongwei Zhang, Liwei Guan, and Guang Chen. Pit: A dynamic personalized item tokenizer for end-to- end generative recommendation.arXiv preprint arXiv:2602.08530, 2026
-
[47]
Differentiable Semantic ID for Generative Recommendation
Junchen Fu, Xuri Ge, Alexandros Karatzoglou, Ioannis Arapakis, Suzan Verberne, Joemon M Jose, and Zhaochun Ren. Differentiable semantic id for generative recommendation.arXiv preprint arXiv:2601.19711, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Jialei Li, Yang Zhang, Yimeng Bai, Shuai Zhu, Ziqi Xue, Xiaoyan Zhao, Dingxian Wang, Frank Yang, Andrew Rabinovich, and Xiangnan He. Unigrec: Unified generative recommendation with soft identifiers for end-to-end optimization.arXiv preprint arXiv:2601.17438, 2026
-
[49]
Jie Jiang, Xinxun Zhang, Enming Zhang, Yuling Xiong, Jun Zhang, Jingwen Wang, Huan Yu, Yuxiang Wang, Hao Wang, Xiao Yan, et al. End-to-end semantic id generation for generative advertisement recommendation.arXiv preprint arXiv:2602.10445, 2026. 12
-
[50]
Runjin Chen, Mingxuan Ju, Ngoc Bui, Dimosthenis Antypas, Stanley Cai, Xiaopeng Wu, Leonardo Neves, Zhangyang Wang, Neil Shah, and Tong Zhao. Enhancing item tokenization for generative recommendation through self-improvement.arXiv preprint arXiv:2412.17171, 2024
-
[51]
Better generalization with semantic ids: A case study in ranking for recommendations
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, et al. Better generalization with semantic ids: A case study in ranking for recommendations. InProceedings of the 18th ACM Conference on Recommender Systems, pages 1039–1044, 2024
2024
-
[52]
Jingzhe Liu, Liam Collins, Jiliang Tang, Tong Zhao, Neil Shah, and Clark Mingxuan Ju. Understanding generative recommendation with semantic ids from a model-scaling view.arXiv preprint arXiv:2509.25522, 2025
-
[53]
How well does generative recommendation generalize? 2026
Yijie Ding, Zitian Guo, Jiacheng Li, Letian Peng, Shuai Shao, Wei Shao, Xiaoqiang Luo, Luke Simon, Jingbo Shang, Julian McAuley, and Yupeng Hou. How well does generative recommendation generalize? 2026
2026
-
[54]
Expressiveness limits of autoregressive semantic id generation in generative recommendation
Yupeng Hou, Haven Kim, Clark Mingxuan Ju, Eduardo Escoto, Neil Shah, and Julian McAuley. Expressiveness limits of autoregressive semantic id generation in generative recommendation. 2026
2026
-
[55]
Semantic ids for recommender systems at snapchat: Use cases, technical challenges, and design choices
Clark Mingxuan Ju, Tong Zhao, Leonardo Neves, Liam Collins, Bhuvesh Kumar, Jiwen Ren, Lili Zhang, Wenfeng Zhuo, Vincent Zhang, Xiao Bai, Jinchao Li, Karthik Iyer, Zihao Fan, Yilun Xu, Yiwen Chen, Peicheng Yu, Manish Malik, and Neil Shah. Semantic ids for recommender systems at snapchat: Use cases, technical challenges, and design choices. 2026
2026
-
[56]
Mitigating Collaborative Semantic ID Staleness in Generative Retrieval
Vladimir Baikalov, Iskander Bagautdinov, and Sergey Muravyov. Mitigating collaborative semantic id staleness in generative retrieval.arXiv preprint arXiv:2604.13273, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Sequential data augmentation for generative recommendation
Geon Lee, Bhuvesh Kumar, Mingxuan Ju, Tong Zhao, Kijung Shin, Neil Shah, and Liam Collins. Sequential data augmentation for generative recommendation. InProceedings of the Nineteenth ACM International Conference on Web Search and Data Mining, pages 303–312, 2026
2026
-
[58]
Inductive generative recommen- dation via retrieval-based speculation
Yijie Ding, Jiacheng Li, Julian McAuley, and Yupeng Hou. Inductive generative recommen- dation via retrieval-based speculation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 14675–14683, 2026
2026
-
[59]
Order-agnostic identifier for large language model-based generative recommendation
Xinyu Lin, Haihan Shi, Wenjie Wang, Fuli Feng, Qifan Wang, See-Kiong Ng, and Tat-Seng Chua. Order-agnostic identifier for large language model-based generative recommendation. In Proceedings of the 48th international ACM SIGIR conference on research and development in information retrieval, pages 1923–1933, 2025
1923
-
[60]
Closing the performance gap in generative recommenders with collaborative tokenization and efficient modeling
Simon Lepage, Jeremie Mary, and David Picard. Closing the performance gap in generative recommenders with collaborative tokenization and efficient modeling. 2025
2025
-
[61]
Diffgrm: Diffusion-based generative recommendation model
Zhao Liu, Yichen Zhu, Yiqing Yang, Xiao Lv, Guoping Tang, Rui Huang, Qiang Luo, Ruiming Tang, and Guorui Zhou. Diffgrm: Diffusion-based generative recommendation model. In Proceedings of the ACM Web Conference 2026, pages 5853–5864, 2026
2026
-
[62]
Diffusion generative recommendation with continuous tokens
Haohao Qu, Shanru Lin, Yujuan Ding, Yiqi Wang, and Wenqi Fan. Diffusion generative recommendation with continuous tokens. InProceedings of the ACM Web Conference 2026, pages 7259–7270, 2026
2026
-
[63]
Masked diffusion for generative recommendation
Kulin Shah, Bhuvesh Kumar, Neil Shah, and Liam Collins. Masked diffusion for generative recommendation. 2025
2025
-
[64]
Llada-rec: Discrete diffusion for parallel semantic id generation in generative recommendation
Teng Shi, Chenglei Shen, Weijie Yu, Shen Nie, Chongxuan Li, Xiao Zhang, Ming He, Yan Han, and Jun Xu. Llada-rec: Discrete diffusion for parallel semantic id generation in generative recommendation. 2025
2025
-
[65]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. 2015. 13
2015
-
[66]
Distillation matters: Empowering sequential recommenders to match the performance of large language models
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, and Jiawei Chen. Distillation matters: Empowering sequential recommenders to match the performance of large language models. In18th ACM Conference on Recommender Systems, page 507–517. ACM, October 2024
2024
-
[67]
Distillation enhanced generative retrieval
Yongqi Li, Zhen Zhang, Wenjie Wang, Liqiang Nie, Wenjie Li, and Tat-Seng Chua. Distillation enhanced generative retrieval. 2024
2024
-
[68]
Chawla, Neil Shah, and Tong Zhao
Zhichun Guo, William Shiao, Shichang Zhang, Yozen Liu, Nitesh V . Chawla, Neil Shah, and Tong Zhao. Linkless link prediction via relational distillation. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, Proceedings of Machine Learning Research, 2023
2023
-
[69]
Fast transformer decoding: One write-head is all you need
Noam Shazeer. Fast transformer decoding: One write-head is all you need. 2019
2019
-
[70]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. 2023
2023
-
[71]
Hydra: Sequentially-dependent draft heads for medusa decoding
Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan-Kelley, and William Brandon. Hydra: Sequentially-dependent draft heads for medusa decoding. 2024
2024
-
[72]
Eagle-3: Scaling up inference acceleration of large language models via training-time test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-3: Scaling up inference acceleration of large language models via training-time test. 2025
2025
-
[73]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. 2022
2022
-
[74]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. 2024
2024
-
[75]
Justifying recommendations using distantly- labeled reviews and fine-grained aspects
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly- labeled reviews and fine-grained aspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, 2019
2019
-
[76]
Discovering the gems in early layers: Accelerating long-context llms with 1000x input token reduction
Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, and Shafiq Joty. Discovering the gems in early layers: Accelerating long-context llms with 1000x input token reduction. 2024
2024
-
[77]
Cold-starts in generative recommendation: A reproducibility study
Zhen Zhang, Jujia Zhao, Xinyu Ma, Xin Xin, Maarten de Rijke, and Zhaochun Ren. Cold-starts in generative recommendation: A reproducibility study. 2026. 14 A Notations Table 6 summarizes the notations used throughout the paper. Table 6: Notations and explanations. Notation Explanation U,VUser and item sets;uandvindex users and items Xu = [v1, . . . , vn]Hi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.