Bi-Level Optimization for Generative Recommendation: Bridging Tokenization and Generation
Pith reviewed 2026-05-18 05:12 UTC · model grok-4.3
The pith
Bi-level optimization couples the tokenizer and recommender so item identifiers directly improve generative recommendation performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BLOGER frames generative recommendation as a bi-level optimization problem. The lower level optimizes the recommender model on sequences produced by the current tokenizer. The upper level then updates the tokenizer parameters to minimize a combination of the tokenization objective and the recommendation loss achieved by the lower-level model. A meta-learning method approximates the solution to this nested optimization, while gradient surgery resolves conflicts between the two loss terms in the upper level. This process ensures the derived item identifiers are both compact and predictive for user-item interactions in an autoregressive manner.
What carries the argument
Bi-level optimization where the upper level optimizes the tokenizer using gradients that account for the lower-level recommender's performance, solved via meta-learning with gradient surgery to handle conflicts.
Load-bearing premise
A meta-learning procedure can solve the bi-level optimization efficiently and gradient surgery can prevent update conflicts without harming the quality of the learned item identifiers.
What would settle it
Running BLOGER on a standard benchmark dataset and finding no improvement over a sequentially trained tokenizer and recommender, or observing instability when gradient surgery is disabled.
Figures



read the original abstract
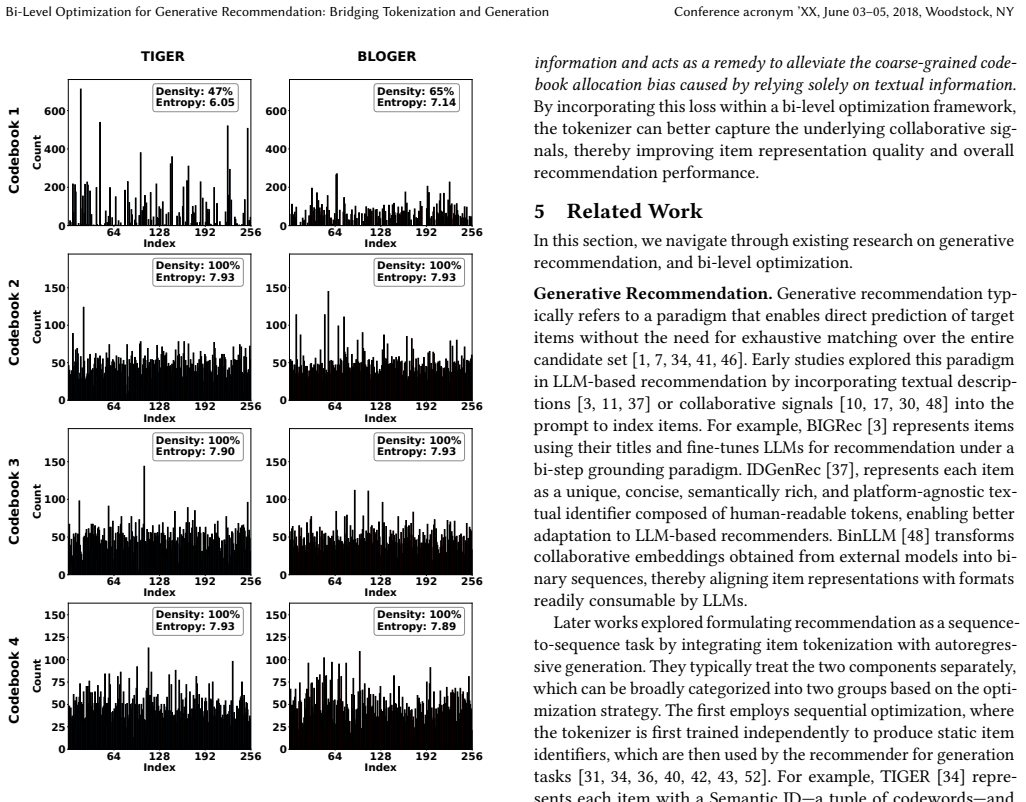
Generative recommendation is emerging as a transformative paradigm by directly generating recommended items, rather than relying on matching. Building such a system typically involves two key components: (1) optimizing the tokenizer to derive suitable item identifiers, and (2) training the recommender based on those identifiers. Existing approaches often treat these components separately--either sequentially or in alternation--overlooking their interdependence. This separation can lead to misalignment: the tokenizer is trained without direct guidance from the recommendation objective, potentially yielding suboptimal identifiers that degrade recommendation performance. To address this, we propose BLOGER, a Bi-Level Optimization for GEnerative Recommendation framework, which explicitly models the interdependence between the tokenizer and the recommender in a unified optimization process. The lower level trains the recommender using tokenized sequences, while the upper level optimizes the tokenizer based on both the tokenization loss and recommendation loss. We adopt a meta-learning approach to solve this bi-level optimization efficiently, and introduce gradient surgery to mitigate gradient conflicts in the upper-level updates, thereby ensuring that item identifiers are both informative and recommendation-aligned. Extensive experiments on multiple real-world datasets demonstrate that BLOGER consistently outperforms state-of-the-art generative recommendation methods while maintaining practical efficiency with no significant additional computational overhead, effectively bridging the gap between item tokenization and autoregressive generation. We release our code at https://github.com/Ten-Mao/BLOGER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BLOGER, a bi-level optimization framework for generative recommendation. The lower level optimizes the recommender on tokenized sequences while the upper level optimizes the tokenizer using both tokenization loss and recommendation loss. A meta-learning procedure with gradient surgery solves the bi-level problem, aiming to produce recommendation-aligned item identifiers. Experiments on real-world datasets report consistent outperformance over state-of-the-art generative methods with negligible extra computational cost; code is released.
Significance. If the bi-level formulation and its meta-learning solution are shown to correctly align tokenization with downstream recommendation performance, the work could advance generative recommendation by replacing heuristic alternation or sequential pipelines with a more principled joint optimization. The public code release supports reproducibility and is a clear strength.
major comments (1)
- [§3.2] §3.2 (Meta-Learning Solver): The central claim that BLOGER 'explicitly models the interdependence' rests on the meta-learning approximation correctly propagating the effect of the lower-level recommender optimization to the tokenizer. The manuscript uses a one-step or truncated back-propagation through the inner argmin but provides no diagnostics (e.g., inner-loop loss curves, number of steps to convergence, or sensitivity to truncation length). Without such validation, the upper-level updates may be based on a biased hypergradient rather than the true recommendation performance after full inner optimization, weakening the claim that the framework bridges tokenization and generation beyond heuristic alternation.
minor comments (2)
- [§4.3] §4.3 (Results): While average improvements are reported, the tables would benefit from per-dataset standard deviations across multiple random seeds to allow readers to assess stability of the gains.
- [Figure 3] Figure 3: The legend and axis labels for the gradient-conflict visualization are too small; enlarging them would improve readability of how gradient surgery affects the upper-level update.
Simulated Author's Rebuttal
Thank you for your thorough review and valuable feedback on our paper. We have carefully considered the major comment and provide our response below. We will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Meta-Learning Solver): The central claim that BLOGER 'explicitly models the interdependence' rests on the meta-learning approximation correctly propagating the effect of the lower-level recommender optimization to the tokenizer. The manuscript uses a one-step or truncated back-propagation through the inner argmin but provides no diagnostics (e.g., inner-loop loss curves, number of steps to convergence, or sensitivity to truncation length). Without such validation, the upper-level updates may be based on a biased hypergradient rather than the true recommendation performance after full inner optimization, weakening the claim that the framework bridges tokenization and generation beyond heuristic alternation.
Authors: We thank the referee for this insightful observation. The bi-level optimization in BLOGER is solved using a meta-learning procedure with a one-step approximation for the inner optimization, which allows us to propagate gradients from the recommendation loss back to the tokenizer parameters. This is intended to explicitly capture the interdependence. We acknowledge that the manuscript currently lacks detailed diagnostics on the inner optimization process, such as loss curves or sensitivity to truncation. To strengthen the validation of our approach, we will include in the revised manuscript additional experimental results, including inner-loop loss curves over training steps and an analysis of how varying the number of inner optimization steps affects the final recommendation performance. These additions will help confirm that the approximation used does not introduce significant bias and supports the bridging of tokenization and generation. revision: yes
Circularity Check
No circularity: bi-level optimization framework is self-contained
full rationale
The paper presents BLOGER as a bi-level optimization where the lower level trains the recommender on tokenized sequences and the upper level optimizes the tokenizer using both tokenization and recommendation losses, solved via meta-learning with gradient surgery. No equations, predictions, or first-principles results in the abstract or described framework reduce by construction to fitted inputs or self-citations; the interdependence is modeled through an explicit optimization procedure rather than a definitional loop or renamed empirical pattern. The approach is independent of any load-bearing self-citation chains and maintains external falsifiability through experimental comparisons on real-world datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The tokenizer and recommender can be optimized jointly in a bi-level process where the upper level uses both tokenization loss and recommendation loss.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We adopt a meta-learning approach to solve this bi-level optimization efficiently, and introduce gradient surgery to mitigate gradient conflicts in the upper-level updates
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the bi-level optimization problem is formulated as min_ϕ L_rec(T_ϕ,R_θ*) + λ L_token(T_ϕ) s.t. θ* = arg min_θ L_rec(T_ϕ,R_θ)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
MLPs are Efficient Distilled Generative Recommenders
SID-MLP distills autoregressive generative recommenders into efficient position-specific MLP heads for Semantic ID tasks, achieving 8.74x faster inference with matching accuracy.
-
Conditional Memory Enhanced Item Representation for Generative Recommendation
ComeIR introduces dual-level Engram memory and memory-restoring prediction to reconstruct SID-token embeddings and restore token granularity in generative recommendation.
Reference graph
Works this paper leans on
- [1]
-
[2]
Yimeng Bai, Yang Zhang, Jing Lu, Jianxin Chang, Xiaoxue Zang, Yanan Niu, Yang Song, and Fuli Feng. 2024. LabelCraft: Empowering Short Video Recommenda- tions with Automated Label Crafting. InProceedings of the 17th ACM International Conference on Web Search and Data Mining(Merida, Mexico)(WSDM ’24). Asso- ciation for Computing Machinery, New York, NY, USA, 28–37
work page 2024
-
[3]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems.ACM Trans. Recomm. Syst. 3, 4, Article 53 (April 2025), 27 pages
work page 2025
-
[4]
Keqin Bao, Jizhi Zhang, Yang Zhang, Xinyue Huo, Chong Chen, and Fuli Feng
-
[5]
InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Decoding Matters: Addressing Amplification Bias and Homogeneity Issue in Recommendations for Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Miami, Florida, USA, 10540–10552
work page 2024
-
[6]
Luca Bertinetto, João F. Henriques, Philip H. S. Torr, and Andrea Vedaldi. 2019. Meta-learning with differentiable closed-form solvers. In7th International Con- ference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9,
work page 2019
-
[7]
Dong-Kyu Chae, Jin-Soo Kang, Sang-Wook Kim, and Jung-Tae Lee. 2018. CFGAN: A Generic Collaborative Filtering Framework based on Generative Adversarial Networks. InProceedings of the 27th ACM International Conference on Information and Knowledge Management(Torino, Italy)(CIKM ’18). Association for Computing Machinery, New York, NY, USA, 137–146
work page 2018
-
[8]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment.arXiv preprint arXiv:2502.18965(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta- learning for fast adaptation of deep networks. InProceedings of the 34th Inter- national Conference on Machine Learning - Volume 70(Sydney, NSW, Australia) (ICML’17). JMLR.org, 1126–1135
work page 2017
-
[10]
Christian Ganhör, David Penz, Navid Rekabsaz, Oleg Lesota, and Markus Schedl
-
[11]
Unlearning Protected User Attributes in Recommendations with Adversar- ial Training. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 2142–2147
-
[12]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). InProceedings of the 16th ACM Conference on Recommender Systems(Seattle, WA, USA)(RecSys ’22). Association for Computing Machinery, New York, NY, USA, 299–315
work page 2022
-
[13]
Jesse Harte, Wouter Zorgdrager, Panos Louridas, Asterios Katsifodimos, Dietmar Jannach, and Marios Fragkoulis. 2023. Leveraging Large Language Models for Sequential Recommendation. InProceedings of the 17th ACM Conference on Recom- mender Systems(Singapore, Singapore)(RecSys ’23). Association for Computing Machinery, New York, NY, USA, 1096–1102
work page 2023
-
[14]
Ruining He and Julian McAuley. 2016. Ups and Downs: Modeling the Visual Evo- lution of Fashion Trends with One-Class Collaborative Filtering. InProceedings of the 25th International Conference on World Wide Web(Montréal, Québec, Canada) (WWW ’16). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 507–517
work page 2016
-
[15]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, YongDong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. InProceedings of the 43rd International ACM SIGIR Confer- ence on Research and Development in Information Retrieval(Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New Yor...
work page 2020
-
[16]
Xiangnan He, Zhankui He, Xiaoyu Du, and Tat-Seng Chua. 2018. Adversarial Personalized Ranking for Recommendation. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval(Ann Arbor, MI, USA)(SIGIR ’18). Association for Computing Machinery, New York, NY, USA, 355–364
work page 2018
-
[17]
Balázs Hidasi and Alexandros Karatzoglou. 2018. Recurrent Neural Networks with Top-k Gains for Session-based Recommendations. InProceedings of the 27th ACM International Conference on Information and Knowledge Management (Torino, Italy)(CIKM ’18). Association for Computing Machinery, New York, NY, USA, 843–852. https://doi.org/10.1145/3269206.3271761
-
[18]
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. 2025. Generating Long Se- mantic IDs in Parallel for Recommendation(KDD ’25). Association for Computing Machinery, New York, NY, USA, 956–966
work page 2025
-
[19]
Wenyue Hua, Shuyuan Xu, Yingqiang Ge, and Yongfeng Zhang. 2023. How to Index Item IDs for Recommendation Foundation Models. InProceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region(Beijing, China)(SIGIR-AP ’23). Association for Computing Machinery, New York, NY, USA, 195–204
work page 2023
-
[20]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, IEEE Computer Society, 197–206
work page 2018
-
[21]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
work page 2009
-
[22]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11523–11532
work page 2022
-
[23]
Guanyu Lin, Zhigang Hua, Tao Feng, Shuang Yang, Bo Long, and Jiaxuan You
-
[24]
arXiv preprint arXiv:2502.16474(2025)
Unified semantic and ID representation learning for deep recommenders. arXiv preprint arXiv:2502.16474(2025)
-
[25]
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao
-
[26]
Generative Recommender with End-to-End Learnable Item Tokenization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 11 pages. Bi-Level Optimization for Generative Recommendation: Bridging Tokenization and Gene...
work page 2018
-
[27]
Risheng Liu, Jiaxin Gao, Jin Zhang, Deyu Meng, and Zhouchen Lin. 2022. Investi- gating Bi-Level Optimization for Learning and Vision From a Unified Perspective: A Survey and Beyond.IEEE Transactions on Pattern Analysis and Machine Intelli- gence44, 12 (2022), 10045–10067
work page 2022
-
[28]
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al
- [29]
-
[30]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regulariza- tion. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net
work page 2019
- [31]
-
[32]
Chen Ma, Peng Kang, and Xue Liu. 2019. Hierarchical Gating Networks for Se- quential Recommendation. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining(Anchorage, AK, USA)(KDD ’19). Association for Computing Machinery, New York, NY, USA, 825–833
work page 2019
-
[33]
Masoud Mansoury, Himan Abdollahpouri, Mykola Pechenizkiy, Bamshad Mobasher, and Robin Burke. 2020. Feedback Loop and Bias Amplification in Recommender Systems. InProceedings of the 29th ACM International Conference on Information & Knowledge Management(Virtual Event, Ireland)(CIKM ’20). Association for Computing Machinery, New York, NY, USA, 2145–2148
work page 2020
-
[34]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Kentaro Inui, Jing Jiang, Vincent Ng, and X...
work page 2019
- [35]
- [36]
-
[37]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
work page 2020
-
[38]
Aravind Rajeswaran, Chelsea Finn, Sham M. Kakade, and Sergey Levine. 2019. Meta-learning with implicit gradients. Curran Associates Inc., Red Hook, NY, USA
work page 2019
-
[39]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Keshavan, Trung Vu, Lukasz Heidt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. 2023. Recommender systems with generative retrieval. InProceedings of the 37th International Conference on Neural Information Processing Systems(New Orleans, LA, US...
work page 2023
-
[40]
Wentao Shi, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, and Fuli Feng. 2024. Large Language Models are Learnable Planners for Long-Term Recommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(Wash- ington DC, USA)(SIGIR ’24). Association for Computing...
work page 2024
-
[41]
Zihua Si, Zhongxiang Sun, Jiale Chen, Guozhang Chen, Xiaoxue Zang, Kai Zheng, Yang Song, Xiao Zhang, Jun Xu, and Kun Gai. 2024. Generative Retrieval with Semantic Tree-Structured Identifiers and Contrastive Learning. InProceedings of the 2024 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific...
work page 2024
-
[42]
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, and Yongfeng Zhang. 2024. IDGenRec: LLM-RecSys Alignment with Textual ID Learning. In Proceedings of the 47th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 355–364
work page 2024
-
[43]
Jiaxi Tang and Ke Wang. 2018. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. InProceedings of the Eleventh ACM International Conference on Web Search and Data Mining(Marina Del Rey, CA, USA)(WSDM ’18). Association for Computing Machinery, New York, NY, USA, 565–573
work page 2018
-
[44]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yas- mine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhos- ale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See- Kiong Ng, and Tat-Seng Chua. 2024. Learnable Item Tokenization for Generative Recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New York, NY, USA, 2400–2409
work page 2024
- [46]
-
[47]
Yidan Wang, Zhaochun Ren, Weiwei Sun, Jiyuan Yang, Zhixiang Liang, Xin Chen, Ruobing Xie, Su Yan, Xu Zhang, Pengjie Ren, Zhumin Chen, and Xin Xin. 2024. Content-Based Collaborative Generation for Recommender Systems. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Co...
work page 2024
-
[48]
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, and Zhenhua Dong. 2024. EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Barcelona, Spain)(KDD ’24). Association for Computing Mac...
work page 2024
-
[49]
Zongwei Wang, Min Gao, Wentao Li, Junliang Yu, Linxin Guo, and Hongzhi Yin. 2023. Efficient Bi-Level Optimization for Recommendation Denoising. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Long Beach, CA, USA)(KDD ’23). Association for Computing Machinery, New York, NY, USA, 2502–2511
work page 2023
-
[50]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. 2020. Gradient surgery for multi-task learning. InProceedings of the 34th International Conference on Neural Information Processing Systems (Vancouver, BC, Canada)(NIPS ’20). Curran Associates Inc., Red Hook, NY, USA, Article 489, 13 pages
work page 2020
-
[51]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations. InProceedings of the 41st International Conference on Machine Learning(Vienna, Austria)(ICML’24). JMLR.org, ...
work page 2024
- [52]
-
[53]
Yang Zhang, Keqin Bao, Ming Yan, Wenjie Wang, Fuli Feng, and Xiangnan He
-
[54]
Text-like Encoding of Collaborative Information in Large Language Models for Recommendation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 9181–9191
-
[55]
Yihua Zhang, Prashant Khanduri, Ioannis Tsaknakis, Yuguang Yao, Mingyi Hong, and Sijia Liu. 2024. An introduction to bilevel optimization: Foundations and applications in signal processing and machine learning.IEEE Signal Processing Magazine41, 1 (2024), 38–59
work page 2024
- [56]
- [57]
-
[58]
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. 2024. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 1435–1448
work page 2024
-
[59]
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. 2020. S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization. InPro- ceedings of the 29th ACM International Conference on Information & Knowledge Management(Virtual Event, Ireland)(CIKM ’20). Association f...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.