Recognition: unknown
MambaPanoptic: A Vision Mamba-based Structured State Space Framework for Panoptic Segmentation
Pith reviewed 2026-05-14 21:16 UTC · model grok-4.3
The pith
MambaPanoptic replaces transformers and convolutions with structured state space blocks to achieve competitive panoptic segmentation at linear complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
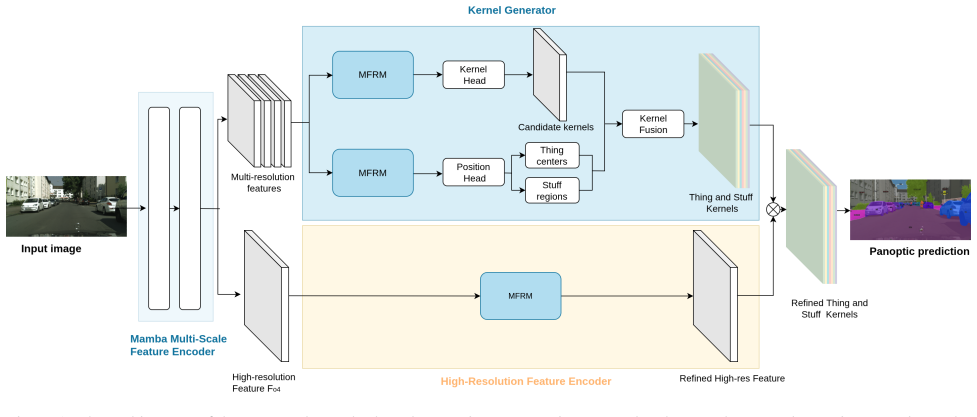
MambaPanoptic is a fully Mamba-based panoptic segmentation framework whose MambaFPN generates globally coherent multi-scale features with linear complexity and whose PanopticFCN-style kernel generator, augmented by QuadMamba refinement, produces unified thing and stuff kernels for proposal-free prediction.
What carries the argument
MambaFPN, a top-down feature pyramid built from Mamba blocks that produces globally coherent multi-scale representations with linear computational cost.
If this is right
- Panoptic segmentation at higher input resolutions becomes practical because overall complexity remains linear rather than quadratic.
- A single kernel generator produces both thing and stuff predictions, removing the need for separate instance-proposal branches.
- Multi-stage QuadMamba refinement improves boundary precision across all classes without additional task-specific heads.
- Model parameter counts can be reduced relative to transformer baselines while retaining or improving benchmark scores.
Where Pith is reading between the lines
- The same Mamba substitution pattern may transfer to other dense-prediction tasks such as semantic segmentation or monocular depth estimation.
- Real-time panoptic segmentation on embedded hardware could become feasible once the linear scaling is exploited in optimized inference engines.
- Further increases in Mamba model capacity might narrow remaining accuracy gaps with the largest transformer models on COCO.
Load-bearing premise
Mamba blocks can be substituted directly into a PanopticFCN-style architecture while preserving the multi-scale coherence and boundary accuracy needed for both thing instances and stuff regions.
What would settle it
A side-by-side evaluation on Cityscapes in which MambaPanoptic fails to match or exceed Mask2Former's PQ score at equal or lower parameter count would falsify the performance claim.
Figures



read the original abstract
Panoptic segmentation requires the simultaneous recognition of countable thing instances and amorphous stuff regions, placing joint demands on long-range context modelling, multi-scale feature representation, and efficient dense prediction. Existing convolutional and transformer-based methods struggle to satisfy all three requirements concurrently: convolutional architectures are limited in their capacity to model long-range dependencies, while transformer-based methods incur quadratic computational cost that is prohibitive at high resolutions. In this paper, we propose MambaPanoptic, a fully Mamba-based panoptic segmentation framework that addresses these limitations through two principal contributions. First, we introduce MambaFPN, a top-down feature pyramid that leverages Mamba blocks to generate globally coherent, multi-scale feature representations with linear computational complexity. Second, we adopt a PanopticFCN-style kernel generator that produces unified thing and stuff kernels for proposal-free panoptic prediction, enhanced by a QuadMamba-based feature refinement module applied at multiple network stages. Experiments on the Cityscapes and COCO panoptic segmentation benchmarks demonstrate that MambaPanoptic consistently outperforms PanopticDeepLab and PanopticFCN under comparable model sizes, and matches or surpasses Mask2Former on Cityscapes in PQ and AP while requiring fewer parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MambaPanoptic, a fully Mamba-based panoptic segmentation framework. It introduces MambaFPN, a top-down feature pyramid leveraging Mamba blocks to produce globally coherent multi-scale representations at linear complexity, and augments a PanopticFCN-style kernel generator with a QuadMamba feature refinement module for proposal-free unified thing/stuff prediction. Experiments are reported to show consistent outperformance over PanopticDeepLab and PanopticFCN on Cityscapes and COCO under comparable model sizes, plus matching or surpassing Mask2Former on Cityscapes in PQ and AP with fewer parameters.
Significance. If the empirical gains hold under standard controls, the work would demonstrate that structured state-space models can serve as drop-in replacements for both convolutional and attention mechanisms in high-resolution dense prediction, delivering linear-complexity long-range modeling for panoptic tasks where transformers are computationally prohibitive.
major comments (2)
- [Abstract and Experimental Results] The abstract asserts benchmark improvements on Cityscapes and COCO yet supplies no quantitative tables, ablation studies, or error analysis; without these details it is impossible to confirm whether reported PQ/AP gains survive standard data splits, controls, or statistical significance tests, which directly underpins the central performance claim.
- [MambaFPN and QuadMamba Modules] The architecture relies on direct substitution of Mamba blocks into the PanopticFCN kernel generator and top-down FPN while preserving multi-scale boundary coherence for both thing and stuff classes; the manuscript must explicitly document any scan-order modifications, auxiliary convolutional heads, or state-compression adjustments, as the linear recurrence lacks the explicit local receptive-field control of convolutions.
minor comments (1)
- [Method] Notation for the QuadMamba module and its integration points should be defined more clearly with a diagram or pseudocode to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, providing clarifications and committing to revisions that strengthen the presentation of results and architectural details without altering the core claims.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] The abstract asserts benchmark improvements on Cityscapes and COCO yet supplies no quantitative tables, ablation studies, or error analysis; without these details it is impossible to confirm whether reported PQ/AP gains survive standard data splits, controls, or statistical significance tests, which directly underpins the central performance claim.
Authors: We acknowledge that the abstract itself contains no numerical values or tables, which can make the performance claims harder to assess at a glance. The full manuscript already reports detailed quantitative results in Tables 1–3, including PQ, SQ, RQ, and AP metrics on both Cityscapes and COCO under standard splits, with direct comparisons to PanopticDeepLab, PanopticFCN, and Mask2Former at comparable parameter counts. To address the concern, we will revise the abstract to include the key absolute metrics (e.g., Cityscapes PQ of X and COCO PQ of Y) and add a new ablation subsection plus error analysis in the experiments section. All reported results follow the exact evaluation protocols and data splits of the cited baselines; we will also report standard deviations across three random seeds to demonstrate statistical stability. revision: yes
-
Referee: [MambaFPN and QuadMamba Modules] The architecture relies on direct substitution of Mamba blocks into the PanopticFCN kernel generator and top-down FPN while preserving multi-scale boundary coherence for both thing and stuff classes; the manuscript must explicitly document any scan-order modifications, auxiliary convolutional heads, or state-compression adjustments, as the linear recurrence lacks the explicit local receptive-field control of convolutions.
Authors: We agree that explicit documentation of these implementation choices is necessary for clarity and reproducibility. MambaFPN applies the standard bidirectional Mamba scan (forward and reverse along the flattened feature map) with no modifications to scan order. The QuadMamba module performs four-directional scanning (horizontal, vertical, and both diagonals) at each refinement stage but introduces no state compression or auxiliary convolutional heads beyond the minimal 1×1 convolutions used for channel alignment, exactly as in the original PanopticFCN kernel generator. Boundary coherence for thing and stuff classes is preserved through the top-down FPN fusion and multi-scale kernel prediction. In the revised manuscript we will add a dedicated subsection (3.2.1) with pseudocode, a diagram of the four scan directions, and an explicit statement confirming the absence of the listed modifications. This design relies on Mamba’s global modeling plus pyramid aggregation to compensate for the lack of explicit local receptive fields. revision: yes
Circularity Check
No significant circularity; claims rest on external empirical benchmarks
full rationale
The paper introduces MambaFPN and QuadMamba modules as architectural substitutions into a PanopticFCN-style framework, then validates them solely through comparative experiments on Cityscapes and COCO against independent baselines (PanopticDeepLab, PanopticFCN, Mask2Former). No equations, fitted parameters, or self-citations are shown that reduce reported PQ/AP scores to quantities defined by the authors' own inputs. The derivation chain consists of descriptive module proposals followed by benchmark results, remaining self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mamba state-space blocks can model long-range dependencies with linear complexity in vision tasks
Reference graph
Works this paper leans on
-
[1]
End-to-end object detection with transformers
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S., 2020. End-to-end object detection with transformers. European conference on computer vision, Springer, 213--229
work page 2020
-
[2]
D., Zhu, Y., Liu, T., Huang, T
Cheng, B., Collins, M. D., Zhu, Y., Liu, T., Huang, T. S., Adam, H., Chen, L.-C., 2020. Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12475--12485
work page 2020
-
[3]
G., Kirillov, A., Girdhar, R., 2022
Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., Girdhar, R., 2022. Masked-attention mask transformer for universal image segmentation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 12037--12047
work page 2022
-
[4]
Per-pixel classification is not all you need for semantic segmentation
Cheng, B., Schwing, A., Kirillov, A., 2021. Per-pixel classification is not all you need for semantic segmentation. Advances in neural information processing systems , 34, 17864--17875
work page 2021
-
[5]
The cityscapes dataset for semantic urban scene understanding
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B., 2016. The cityscapes dataset for semantic urban scene understanding. Proceedings of the IEEE conference on computer vision and pattern recognition, 3213--3223
work page 2016
-
[6]
Fu, Y., Lou, M., Yu, Y., 2025. Segman: Omni-scale context modeling with state space models and local attention for semantic segmentation. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. arXiv:2412.11890
-
[7]
Learning category-and instance-aware pixel embedding for fast panoptic segmentation
Gao, N., Shan, Y., Zhao, X., Huang, K., 2020. Learning category-and instance-aware pixel embedding for fast panoptic segmentation. European conference on computer vision, Springer, 411--427
work page 2020
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A., Dao, T., 2023. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Mambavision: A hybrid mamba-transformer vision backbone
Hatamizadeh, A., Kautz, J., 2025. Mambavision: A hybrid mamba-transformer vision backbone. Proceedings of the Computer Vision and Pattern Recognition Conference, 25261--25270
work page 2025
-
[10]
Mobilemamba: Lightweight multi-receptive visual mamba network
He, H., Zhang, J., Cai, Y., Chen, H., Hu, X., Gan, Z., Wang, Y., Wang, C., Wu, Y., Xie, L., 2025. Mobilemamba: Lightweight multi-receptive visual mamba network. Proceedings of the Computer Vision and Pattern Recognition Conference, 4497--4507
work page 2025
-
[11]
He, K., Gkioxari, G., Doll \'a r, P., Girshick, R., 2017. Mask r-cnn. Proceedings of the IEEE international conference on computer vision, 2961--2969
work page 2017
-
[12]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., Sun, J., 2016. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition, 770--778
work page 2016
-
[13]
LocalMamba: Visual state space model with windowed selective scan
Huang, T., Pei, X., You, S., Wang, F., Qian, C., Xu, C., 2024. LocalMamba: Visual state space model with windowed selective scan. arXiv preprint arXiv:2403.09338
-
[14]
Panoptic feature pyramid networks
Kirillov, A., Girshick, R., He, K., Doll \'a r, P., 2019a. Panoptic feature pyramid networks. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6399--6408
-
[15]
Kirillov, A., He, K., Girshick, R., Rother, C., Doll \'a r, P., 2019b. Panoptic segmentation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 9404--9413
-
[16]
Li, F., Zhang, H., Xu, H., Liu, S., Zhang, L., Ni, L. M., Shum, H.-Y., 2023. Mask dino: Towards a unified transformer-based framework for object detection and segmentation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3041--3050
work page 2023
-
[17]
Learning to Fuse Things and Stuff
Li, J., Raventos, A., Bhargava, A., Tagawa, T., Gaidon, A., 2018. Learning to fuse things and stuff. arXiv preprint arXiv:1812.01192
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
A survey on deep learning-based panoptic segmentation
Li, X., Chen, D., 2022. A survey on deep learning-based panoptic segmentation. Digital Signal Processing , 120, 103283
work page 2022
-
[19]
Attention-guided unified network for panoptic segmentation
Li, Y., Chen, X., Zhu, Z., Xie, L., Huang, G., Du, D., Wang, X., 2019. Attention-guided unified network for panoptic segmentation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 7026--7035
work page 2019
-
[20]
Fully convolutional networks for panoptic segmentation
Li, Y., Zhao, H., Qi, X., Wang, L., Li, Z., Sun, J., Jia, J., 2021. Fully convolutional networks for panoptic segmentation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 14207--14216
work page 2021
-
[21]
Li, Z., Wang, W., Xie, E., Yu, Z., Anandkumar, A., Alvarez, J. M., Luo, P., Lu, T., 2022. Panoptic segformer: Delving deeper into panoptic segmentation with transformers. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8734--8743
work page 2022
-
[22]
Feature pyramid networks for object detection
Lin, T.-Y., Doll \'a r, P., Girshick, R., He, K., Hariharan, B., Belongie, S., 2017a. Feature pyramid networks for object detection. Proceedings of the IEEE conference on computer vision and pattern recognition, 2117--2125
-
[23]
Focal loss for dense object detection
Lin, T.-Y., Goyal, P., Girshick, R., He, K., Doll \'a r, P., 2017b. Focal loss for dense object detection. Proceedings of the IEEE international conference on computer vision, 2980--2988
- [24]
-
[25]
Vision mamba: A comprehensive survey and taxonomy
Liu, X., Zhang, C., Huang, F., Xia, S., Wang, G., Zhang, L., 2025. Vision mamba: A comprehensive survey and taxonomy. IEEE Transactions on Neural Networks and Learning Systems
work page 2025
-
[26]
Vmamba: Visual state space model
Liu, Y., Tian, Y., Zhao, Y., Yu, H., Xie, L., Wang, Y., Ye, Q., Jiao, J., Liu, Y., 2024. Vmamba: Visual state space model. Advances in neural information processing systems , 37, 103031--103063
work page 2024
-
[27]
U-mamba: Enhancing long-range dependency for biomedical image segmentation
Ma, J., Li, F., Wang, B., 2024a. U-mamba: Enhancing long-range dependency for biomedical image segmentation. arXiv preprint arXiv:2401.04722
-
[28]
Rs 3 mamba: Visual state space model for remote sensing image semantic segmentation
Ma, X., Zhang, X., Pun, M.-O., 2024b. Rs 3 mamba: Visual state space model for remote sensing image semantic segmentation. IEEE Geoscience and Remote Sensing Letters , 21, 1--5
-
[29]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Milletari, F., Navab, N., Ahmadi, S.-A., 2016. V-net: Fully convolutional neural networks for volumetric medical image segmentation. 2016 fourth international conference on 3D vision (3DV), Ieee, 565--571
work page 2016
-
[30]
Samba: Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
Ren, L., Liu, Y., Lu, Y., Shen, Y., Liang, C., Chen, W., 2024. Samba: Simple hybrid state space models for efficient unlimited context language modeling. arXiv preprint arXiv:2406.07522
-
[31]
VM-UNet: Vision Mamba UNet for Medical Image Segmentation
Ruan, J., Li, J., Xiang, S., 2025. VM-UNet: Vision Mamba UNet for Medical Image Segmentation. ACM Trans. Multimedia Comput. Commun. Appl. https://doi.org/10.1145/3767748
-
[32]
T., Khan, S., Gall, J., Khan, F
Shaker, A., Wasim, S. T., Khan, S., Gall, J., Khan, F. S., 2025. Groupmamba: Efficient group-based visual state space model. Proceedings of the Computer Vision and Pattern Recognition Conference, 14912--14922
work page 2025
-
[33]
Max-deeplab: End-to-end panoptic segmentation with mask transformers
Wang, H., Zhu, Y., Adam, H., Yuille, A., Chen, L.-C., 2021. Max-deeplab: End-to-end panoptic segmentation with mask transformers. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 5463--5474
work page 2021
-
[34]
Wu, Y., Kirillov, A., Massa, F., Lo, W.-Y., Girshick, R., 2019. Detectron2. https://github.com/facebookresearch/detectron2
work page 2019
-
[35]
Quadmamba: Learning quadtree-based selective scan for visual state space model
Xie, F., Zhang, W., Wang, Z., Ma, C., 2024. Quadmamba: Learning quadtree-based selective scan for visual state space model. Advances in Neural Information Processing Systems , 37, 117682--117707
work page 2024
-
[36]
SegMamba: Long-range Sequential Modeling Mamba For 3D Medical Image Segmentation
Xing, Z., Ye, T., Yang, Y., Liu, G., Zhu, L., 2024. SegMamba: Long-range Sequential Modeling Mamba For 3D Medical Image Segmentation . proceedings of Medical Image Computing and Computer Assisted Intervention -- MICCAI 2024, LNCS 15008, Springer Nature Switzerland
work page 2024
-
[37]
Upsnet: A unified panoptic segmentation network
Xiong, Y., Liao, R., Zhao, H., Hu, R., Bai, M., Yumer, E., Urtasun, R., 2019. Upsnet: A unified panoptic segmentation network. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 8818--8826
work page 2019
-
[38]
Rs-mamba for large remote sensing image dense prediction
Zhao, S., Chen, H., Zhang, X., Xiao, P., Bai, L., Ouyang, W., 2024. Rs-mamba for large remote sensing image dense prediction. IEEE Transactions on Geoscience and Remote Sensing
work page 2024
-
[39]
Zhu, E., Chen, Z., Wang, D., Shi, H., Liu, X., Wang, L., 2024. Unetmamba: An efficient unet-like mamba for semantic segmentation of high-resolution remote sensing images. IEEE Geoscience and Remote Sensing Letters
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.