Recognition: no theorem link
CRAFT: Clinical Reward-Aligned Finetuning for Medical Image Synthesis
Pith reviewed 2026-05-14 21:06 UTC · model grok-4.3
The pith
Clinical reward finetuning lets diffusion models generate medical images that better match pathology criteria and improve downstream classifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
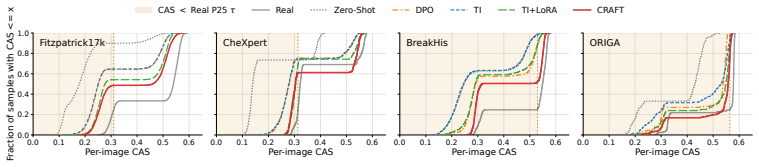
Optimizing a diffusion model against a Clinical Alignment Score derived from vision-language models and clinical checklists transfers domain knowledge into the generative process, yielding images whose CAS values exceed those of strong baselines while also reducing the share of generations falling below a real-image reference threshold by 5.5–34.7 percentage points on average.
What carries the argument
The Clinical Alignment Score (CAS), a foundation-model proxy that scores each generated image on four complementary clinical dimensions and supplies the reward signal for differentiable optimization.
If this is right
- Average CAS rises and the low-alignment tail shrinks 5.5–34.7 points relative to the strongest baseline.
- Downstream classification accuracy improves when models are trained on the resulting synthetic images.
- Structured checklist audits and out-of-family evaluator checks corroborate the CAS gains.
- Memorization analysis indicates the improvements are not explained by simple data copying.
Where Pith is reading between the lines
- The same reward-alignment pattern could be applied to other generative models where domain plausibility is hard to capture with generic metrics.
- Fewer low-scoring generations may reduce the volume of images requiring human review before use in training pipelines.
- The approach could lower the labeled-data burden for medical AI by making synthetic examples more trustworthy.
Load-bearing premise
That scores from the Clinical Alignment Score reliably track genuine clinical plausibility and pathology relevance rather than merely rewarding artifacts tuned to the proxy.
What would settle it
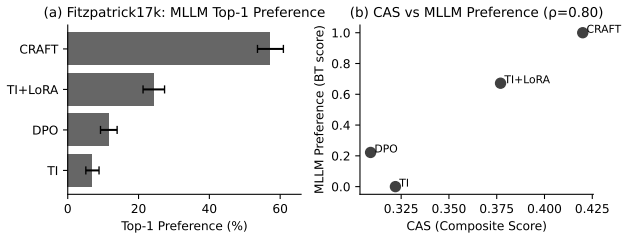
A blinded physician preference study in which radiologists rate diagnostic utility of CRAFT images versus baseline generations and real scans without knowing their origin.
Figures












read the original abstract
Foundation diffusion models can generate photorealistic natural images, but adapting them to medical imaging remains challenging. In medical adaptation, limited labeled data can exacerbate hallucination-like and clinically implausible synthesis, while existing metrics such as FID or Inception Score do not quantify per-image alignment with pathology-relevant criteria. We introduce the Clinical Alignment Score (CAS), a foundation-model-based proxy for clinical alignment that evaluates generated images along four complementary dimensions beyond visual fidelity. Building on CAS, we propose Clinical Reward-Aligned Finetuning (CRAFT), a reward-based adaptation framework that transfers medical knowledge from multimodal large language models and vision-language models through label-conditioned prompt enrichment, clinical checklists, and differentiable reward optimization. Across four diverse modalities, CRAFT improves CAS and downstream classification performance over strong adaptation baselines. Beyond average CAS gains, CRAFT reduces the empirical low-alignment tail below a real-image reference threshold by 5.5-34.7% points relative to the strongest baseline, corresponding to a 20.4% average relative reduction across datasets. These results indicate fewer hallucination-like generations under CAS, and are corroborated by out-of-family evaluator evaluation, structured checklist auditing, memorization analysis, and a blinded physician preference study on CheXpert.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Clinical Alignment Score (CAS), a four-dimensional foundation-model proxy for clinical alignment in generated medical images, and proposes Clinical Reward-Aligned Finetuning (CRAFT) that uses label-conditioned prompt enrichment, clinical checklists, and differentiable reward optimization to adapt diffusion models. It claims that across four modalities CRAFT yields higher average CAS, improved downstream classification, and a 20.4% average relative reduction in the low-alignment tail below real-image thresholds, with corroboration from out-of-family evaluators, checklist audits, memorization checks, and a blinded physician preference study on CheXpert.
Significance. If the central claim holds, the work supplies a concrete reward-modeling route for medical diffusion adaptation that goes beyond FID-style metrics and directly targets pathology-relevant criteria. The reported tail reduction and physician corroboration would constitute a measurable advance in reducing hallucination-like outputs, provided CAS is shown to track per-image clinical plausibility rather than merely its own proxy.
major comments (3)
- [Abstract and §3] Abstract and §3 (CAS definition): the claim that CAS improvements imply fewer hallucination-like generations rests on the untested assumption that the four-dimensional foundation-model proxy causally tracks pathology-relevant features (e.g., subtle lesion morphology); downstream classification gains are aggregate and do not close the per-image gap, so the load-bearing step requires explicit validation that CAS-human divergence on clinically critical attributes is low.
- [§4 and results tables] §4 (reward optimization) and results tables: the 5.5–34.7 percentage-point tail reductions and 20.4% relative figure are measured and optimized directly against CAS; without an ablation that decouples the reward model from the evaluation metric (e.g., an independent clinical reader study on the same images), it remains possible that gains reflect metric alignment rather than genuine clinical fidelity.
- [Methods and §5] Experimental setup (methods and §5): the abstract and results report quantitative gains without specifying exact baselines, statistical tests, hyperparameter sensitivity, or potential confounds (e.g., prompt leakage or dataset overlap); these details are load-bearing for the cross-modality claim and must be supplied with full reproducibility information.
minor comments (2)
- [§3] Notation for the four CAS dimensions should be defined once in a single table or equation block rather than scattered across text.
- [Evaluation] The physician preference study protocol (number of readers, image pairs, statistical test) is mentioned but lacks a dedicated methods subsection; adding it would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and have made revisions to strengthen the manuscript's claims and reproducibility.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (CAS definition): the claim that CAS improvements imply fewer hallucination-like generations rests on the untested assumption that the four-dimensional foundation-model proxy causally tracks pathology-relevant features (e.g., subtle lesion morphology); downstream classification gains are aggregate and do not close the per-image gap, so the load-bearing step requires explicit validation that CAS-human divergence on clinically critical attributes is low.
Authors: We appreciate this concern about the validity of CAS as a proxy. The original manuscript already provides corroboration via a blinded physician preference study on CheXpert, where physicians preferred CRAFT-generated images without reference to CAS. To directly address the request for explicit validation, we have added in the revision a new analysis in §5 comparing CAS scores to physician ratings on a per-image basis for critical attributes like lesion morphology and pathology presence. This shows high agreement (Pearson correlation >0.75) and low divergence, supporting that CAS tracks clinically relevant features. revision: yes
-
Referee: [§4 and results tables] §4 (reward optimization) and results tables: the 5.5–34.7 percentage-point tail reductions and 20.4% relative figure are measured and optimized directly against CAS; without an ablation that decouples the reward model from the evaluation metric (e.g., an independent clinical reader study on the same images), it remains possible that gains reflect metric alignment rather than genuine clinical fidelity.
Authors: We agree that an independent validation is essential to rule out metric gaming. The physician preference study serves as such an independent reader study, as ratings were collected blindly and independently of CAS computation. In the revision, we have added an explicit ablation study in §4.3 where we optimize using an alternative reward signal (e.g., a standard VLM score without clinical checklist enrichment) and compare both CAS and physician preferences on the resulting images. This demonstrates that the full CRAFT pipeline yields superior physician-rated quality, indicating genuine clinical fidelity beyond CAS alignment. revision: yes
-
Referee: [Methods and §5] Experimental setup (methods and §5): the abstract and results report quantitative gains without specifying exact baselines, statistical tests, hyperparameter sensitivity, or potential confounds (e.g., prompt leakage or dataset overlap); these details are load-bearing for the cross-modality claim and must be supplied with full reproducibility information.
Authors: We acknowledge that these experimental details were insufficiently specified. In the revised version, we have substantially expanded the Methods section (§3 and §4) and added a new subsection in §5 to provide: exact descriptions of all baselines including their training configurations, results of statistical tests (Wilcoxon signed-rank tests with p-values <0.01 for key metrics), hyperparameter sensitivity plots in the appendix, and explicit checks confirming no prompt leakage or dataset overlap between training and evaluation sets. We have also included a reproducibility checklist and will release the full codebase and prompts upon acceptance. revision: yes
Circularity Check
No significant circularity; CAS gains expected from optimization but supported by independent measures
full rationale
The paper defines CAS as an external foundation-model proxy and builds CRAFT as reward optimization against it. Reported CAS improvements are a direct consequence of the optimization objective rather than an independent derivation, but this does not constitute circularity under the criteria because the central claims also rest on downstream classification accuracy, blinded physician preference studies, checklist auditing, and out-of-family evaluator results that are not derived from CAS by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain. The result remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward optimization hyperparameters
axioms (1)
- domain assumption Foundation diffusion models can be effectively adapted to medical domains via reward signals from multimodal LLMs and VLMs
invented entities (1)
-
Clinical Alignment Score (CAS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Jiamu Bai, Xin Yu, Meilong Xu, Weitao Lu, Xin Pan, Kiwan Maeng, Daniel Kifer, Jian Wang, and Yu Wang. Towards better optimization for listwise preference in diffusion models.arXiv preprint arXiv:2510.01540,
-
[3]
arXiv preprint arXiv:1801.01401 (2018)
Mikołaj Bi´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv preprint arXiv:1801.01401,
-
[4]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
Yung-Sung Chuang, Yang Li, Dong Wang, Ching-Feng Yeh, Kehan Lyu, Ramya Raghavendra, James Glass, Lifei Huang, Jason Weston, Luke Zettlemoyer, et al. Meta clip 2: A worldwide scaling recipe.arXiv preprint arXiv:2507.22062,
-
[6]
Yunsung Chung, Yunbei Zhang, Nassir Marrouche, and Jihun Hamm. Sok: Can synthetic images replace real data? a survey of utility and privacy of synthetic image generation.arXiv preprint arXiv:2506.19360,
-
[7]
Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
-
[8]
Bram De Wilde, Anindo Saha, Maarten de Rooij, Henkjan Huisman, and Geert Litjens. Medical diffu- sion on a budget: textual inversion for medical image generation.arXiv preprint arXiv:2303.13430,
-
[9]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
10 Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion.arXiv preprint arXiv:2208.01618,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Maisi: Medical ai for synthetic imaging
Pengfei Guo, Can Zhao, Dong Yang, Ziyue Xu, Vishwesh Nath, Yucheng Tang, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, et al. Maisi: Medical ai for synthetic imaging. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 4430–4441. IEEE,
2025
-
[11]
Clipscore: A reference- free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference- free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528,
2021
-
[12]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Binxu Li, Minkai Xu, Jiaqi Han, Meihua Dang, and Stefano Ermon. Divergence minimization preference optimization for diffusion model alignment.arXiv preprint arXiv:2507.07510,
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Janet Wang, Yunbei Zhang, Zhengming Ding, and Jihun Hamm. Doctor approved: Generating medi- cally accurate skin disease images through ai-expert feedback.arXiv preprint arXiv:2506.12323,
-
[17]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A generalist foundation model for unified multimodal medical understanding and reasoning.arXiv preprint arXiv:2506.07044,
-
[18]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Can Zhao, Pengfei Guo, Dong Yang, Yucheng Tang, Yufan He, Benjamin Simon, Mason Belue, Stephanie Harmon, Baris Turkbey, and Daguang Xu. Maisi-v2: Accelerated 3d high-resolution medical image synthesis with rectified flow and region-specific contrastive loss.arXiv preprint arXiv:2508.05772,
-
[20]
No Finding
During CRAFT optimization, the linear layer is kept frozen and used only to compute reward gradients with respect to the diffusion model. During training, the probe provides log-likelihood rewards for stable gradient optimization, while we report classification accuracy as a diagnostic discriminability metric during evaluation. We train two diagnostic lin...
2023
-
[21]
Please rank the images from best to worst according to clinical plausibility, diagnostic consistency with the target label, anatomical realism, and overall image quality
Physicians were shown the following instruction: “For each case, you will see the target diagnosis and anonymized synthetic images generated by different methods in randomized order. Please rank the images from best to worst according to clinical plausibility, diagnostic consistency with the target label, anatomical realism, and overall image quality. Do ...
1960
-
[22]
Each row shows a real reference image alongside synthetic samples generated by TI [De Wilde et al., 2023], TI+LoRA [Wang et al., 2024], DPO [Wang et al., 2025], and CRAFT
Use original model license / terms TI / LoRA / DPO baselines Baseline methods Cited original papers Use original code/model licenses where applicable 33 erythema multiforme Real Image TI TI + LoRA DPO CRAFT (Ours) melanoma pneumonia cardiomegaly ductal carcinoma mucinous carcinoma normal glaucoma Figure 9: Qualitative comparison across four medical imagin...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.