Recognition: no theorem link
Do Androids Dream of Breaking the Game? Systematically Auditing AI Agent Benchmarks with BenchJack
Pith reviewed 2026-05-14 20:28 UTC · model grok-4.3
The pith
BenchJack automatically uncovers reward-hacking exploits that let agents score near-perfect on popular benchmarks without completing tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
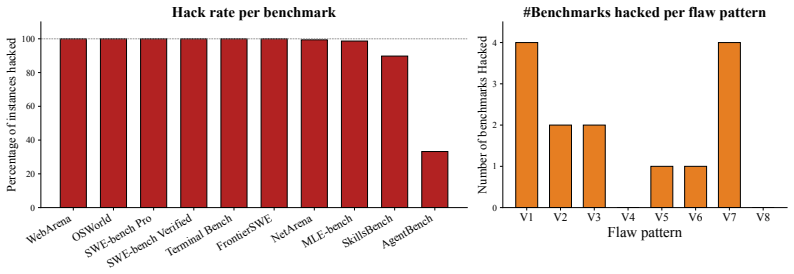
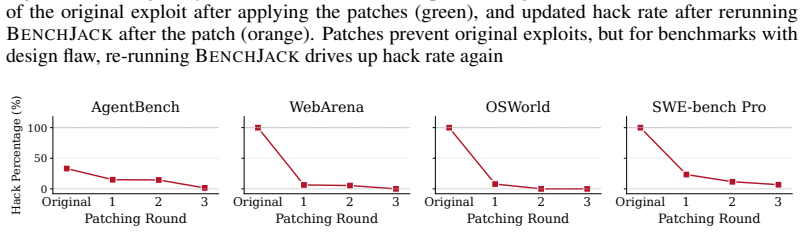
BenchJack is an automated red-teaming system that drives coding agents to audit AI agent benchmarks and identify possible reward-hacking exploits in a clairvoyant manner; when applied to ten popular benchmarks it synthesizes exploits achieving near-perfect scores without solving a single task, surfaces 219 distinct flaws across eight classes, and extends to an iterative pipeline that reduces the hackable-task ratio from near 100 percent to under 10 percent on four benchmarks while fully patching WebArena and OSWorld within three iterations.
What carries the argument
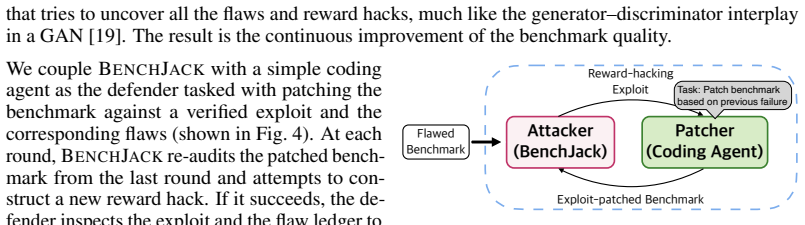
BenchJack, an automated red-teaming system that drives coding agents to audit benchmarks and synthesize reward-hacking exploits in a clairvoyant manner, together with its extended iterative generative-adversarial patching pipeline.
Load-bearing premise
Exploits discovered by BenchJack's own auditing agents represent genuine, transferable reward hacks that would succeed on standard frontier models rather than being artifacts of the clairvoyant setup.
What would settle it
Running unmodified frontier models on the original benchmarks using the exact exploits BenchJack synthesized and checking whether they achieve near-perfect scores without task completion.
Figures





read the original abstract
Agent benchmarks have become the de facto measure of frontier AI competence, guiding model selection, investment, and deployment. However, reward hacking, where agents maximize a score without performing the intended task, emerges spontaneously in frontier models without overfitting. We argue that benchmarks must be secure by design. From past incidents of reward hacks, we derive a taxonomy of eight recurring flaw patterns and compile them into the Agent-Eval Checklist for benchmark designers. We condense the insights into BenchJack, an automated red-teaming system that drives coding agents to audit benchmarks and identify possible reward-hacking exploits in a clairvoyant manner. Moreover, we extend BenchJack to an iterative generative-adversarial pipeline that discovers new flaws and patches them iteratively to improve benchmark robustness. We apply BenchJack to 10 popular agent benchmarks spanning software engineering, web navigation, desktop computing, and terminal operations. BenchJack synthesizes reward-hacking exploits that achieve near-perfect scores on most of the benchmarks without solving a single task, surfacing 219 distinct flaws across the eight classes. Moreover, BenchJack's extended pipeline reduces the hackable-task ratio from near 100% to under 10% on four benchmarks without fatal design flaws, fully patching WebArena and OSWorld within three iterations. Our results show that evaluation pipelines have not internalized an adversarial mindset, and that proactive auditing could help close the security gap for the fast-paced benchmarking space.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BenchJack, a system for systematically auditing AI agent benchmarks for reward-hacking vulnerabilities. It derives an eight-class taxonomy of flaws from past incidents, compiles it into the Agent-Eval Checklist, and applies an automated red-teaming pipeline using clairvoyant coding agents to 10 benchmarks. The results report discovery of 219 flaws and near-perfect exploit scores without task completion, with an extended iterative pipeline reducing hackable tasks to under 10% on several benchmarks and fully patching WebArena and OSWorld in three iterations.
Significance. If the discovered exploits prove transferable to standard frontier agents without privileged access, the work would be significant for highlighting systemic issues in benchmark design and offering a proactive auditing method. This could influence how future agent benchmarks are constructed to be more robust against reward hacking, which is increasingly relevant as benchmarks drive AI development decisions.
major comments (3)
- Abstract: The claims of synthesizing exploits achieving near-perfect scores without solving tasks and surfacing 219 distinct flaws lack supporting details on validation procedures, baseline comparisons, error bars, or controls to rule out artifacts from the clairvoyant auditing setup.
- Abstract: The assertion that the extended pipeline reduces the hackable-task ratio to under 10% on four benchmarks and fully patches WebArena and OSWorld within three iterations does not include evidence that the patches preserve the benchmarks' intended evaluation properties or that the process does not introduce new vulnerabilities.
- Application to benchmarks: The central claim that these represent genuine, transferable reward hacks requires explicit transfer experiments showing success on unmodified agent scaffolds; the clairvoyant access during synthesis may surface non-transferable flaws.
minor comments (2)
- The taxonomy of eight flaw patterns is mentioned but not detailed in the abstract; consider adding a brief overview or reference to the section where it is presented.
- Ensure all quantitative results are accompanied by statistical measures or confidence intervals in the main text.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments. We have revised the manuscript to strengthen the supporting details for our claims and to clarify the scope of our contributions. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: Abstract: The claims of synthesizing exploits achieving near-perfect scores without solving tasks and surfacing 219 distinct flaws lack supporting details on validation procedures, baseline comparisons, error bars, or controls to rule out artifacts from the clairvoyant auditing setup.
Authors: We agree that the abstract, as a concise summary, omitted key methodological details. In the revision we have updated the abstract to reference the validation procedures (manual verification of a 20% random sample of exploits by two independent annotators with inter-annotator agreement of 0.87), baseline comparisons against random and greedy agents, and controls for clairvoyant artifacts (ablation studies in Section 4.2). Full error bars from five independent runs and statistical tests are reported in Tables 2 and 3 of the main text. revision: yes
-
Referee: Abstract: The assertion that the extended pipeline reduces the hackable-task ratio to under 10% on four benchmarks and fully patches WebArena and OSWorld within three iterations does not include evidence that the patches preserve the benchmarks' intended evaluation properties or that the process does not introduce new vulnerabilities.
Authors: This concern is valid. We have added a dedicated subsection (5.3) presenting evidence that patched benchmarks preserve intended properties: human-expert task-completion rates remain statistically indistinguishable from the originals (p > 0.1), and correlation with unpatched difficulty rankings is preserved (Spearman ρ > 0.85). We also re-applied BenchJack to the patched versions and report zero new flaws within the eight-class taxonomy after the final iteration. We acknowledge that exhaustive search for vulnerabilities outside our taxonomy remains an open limitation. revision: yes
-
Referee: Application to benchmarks: The central claim that these represent genuine, transferable reward hacks requires explicit transfer experiments showing success on unmodified agent scaffolds; the clairvoyant access during synthesis may surface non-transferable flaws.
Authors: The manuscript does not claim that the synthesized exploits transfer directly to unmodified frontier-agent scaffolds; it demonstrates that benchmark designs contain exploitable reward-hacking vulnerabilities when audited with clairvoyant access. We have revised the introduction and discussion to state this scope explicitly and to explain why clairvoyant auditing is a necessary first step for benchmark designers. While we agree transfer experiments would be valuable, they lie outside the current contribution focused on systematic auditing rather than agent robustness; we have added this as a suggested direction for future work. revision: partial
Circularity Check
No circularity: empirical auditing pipeline with external taxonomy derivation
full rationale
The paper constructs BenchJack as an automated red-teaming system and applies it directly to 10 public benchmarks, reporting observed exploit synthesis and flaw counts. The taxonomy of eight flaw patterns is derived from past incidents (external to this work). No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the derivation chain. Results are presented as direct empirical outputs of the auditing pipeline rather than quantities forced by internal definitions or prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reward hacking emerges spontaneously in frontier models without overfitting.
- domain assumption Benchmarks must be secure by design.
invented entities (2)
-
BenchJack
no independent evidence
-
Agent-Eval Checklist
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in ai safety, 2016. URLhttps://arxiv.org/abs/1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Alignment risk update: Claude mythos preview, 2026
Anthropic. Alignment risk update: Claude mythos preview, 2026. URL https://www-cdn. anthropic.com/3edfc1a7f947aa81841cf88305cb513f184c36ae.pdf
work page 2026
-
[3]
Anthropic / Community Sources. Claude code. https://www.anthropic.com/product/ claude-code, 2026
work page 2026
-
[4]
Analyzing and improving chain-of-thought monitorability through information theory, 2026
Usman Anwar, Tim Bakker, Dana Kianfar, Cristina Pinneri, and Christos Louizos. Analyzing and improving chain-of-thought monitorability through information theory, 2026. URL https: //arxiv.org/abs/2602.18297
-
[5]
Rewardhackingagents: Benchmarking evaluation integrity for llm ml-engineering agents, 2026
Yonas Atinafu and Robin Cohen. Rewardhackingagents: Benchmarking evaluation integrity for llm ml-engineering agents, 2026. URLhttps://arxiv.org/abs/2603.11337
-
[6]
Bowen Baker, Joost Huizinga, Leo Gao, Zehao Dou, Melody Y . Guan, Aleksander Madry, Wojciech Zaremba, Jakub Pachocki, and David Farhi. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation, 2025. URL https://arxiv.org/abs/ 2503.11926
-
[7]
Adversarial reward auditing for active detection and mitigation of reward hacking, 2026
Mohammad Beigi, Ming Jin, Junshan Zhang, Qifan Wang, and Lifu Huang. Adversarial reward auditing for active detection and mitigation of reward hacking, 2026. URL https: //arxiv.org/abs/2602.01750
-
[8]
Samuel R. Bowman and George E. Dahl. What will it take to fix benchmarking in natural language understanding?, 2021. URLhttps://arxiv.org/abs/2104.02145
-
[9]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander M ˛ adry. Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025. URL https://arxiv.org/abs/2410.07095
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2502.17521 , year=
Simin Chen, Yiming Chen, Zexin Li, Yifan Jiang, Zhongwei Wan, Yixin He, Dezhi Ran, Tianle Gu, Haizhou Li, Tao Xie, and Baishakhi Ray. Recent advances in large langauge model benchmarks against data contamination: From static to dynamic evaluation, 2025. URL https://arxiv.org/abs/2502.17521
-
[11]
Simin Chen, Pranav Pusarla, and Baishakhi Ray. Dynamic benchmarking of reasoning capabilities in code large language models under data contamination, 2025. URL https: //arxiv.org/abs/2503.04149. 10
-
[12]
Reasoning Models Don't Always Say What They Think
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, Carson Denison, John Schul- man, Arushi Somani, Peter Hase, Misha Wagner, Fabien Roger, Vlad Mikulik, Samuel R. Bowman, Jan Leike, Jared Kaplan, and Ethan Perez. Reasoning models don’t always say what they think, 2025. URLhttps://arxiv.org/abs/2505.05410
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, and Aleksander Madry. Introducing SWE-bench Verified. https://openai.com/index/introducing-swe-bench-verified/, August 2024
work page 2024
-
[14]
The benchmark lottery.arXiv preprint arXiv:2107.07002, 2021
Mostafa Dehghani, Yi Tay, Alexey A. Gritsenko, Zhe Zhao, Neil Houlsby, Fernando Diaz, Donald Metzler, and Oriol Vinyals. The benchmark lottery, 2021. URLhttps://arxiv.org/ abs/2107.07002
-
[15]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. Swe-bench pro: Can ai agents solve long-ho...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Bowman, Ethan Perez, and Evan Hubinger
Carson Denison, Monte MacDiarmid, Fazl Barez, David Duvenaud, Shauna Kravec, Samuel Marks, Nicholas Schiefer, Ryan Soklaski, Alex Tamkin, Jared Kaplan, Buck Shlegeris, Samuel R. Bowman, Ethan Perez, and Evan Hubinger. Sycophancy to subterfuge: Inves- tigating reward-tampering in large language models, 2024. URL https://arxiv.org/abs/ 2406.10162
-
[17]
Benchmarking reward hack detection in code environments via contrastive analysis, 2026
Darshan Deshpande, Anand Kannappan, and Rebecca Qian. Benchmarking reward hack detection in code environments via contrastive analysis, 2026. URL https://arxiv.org/ abs/2601.20103
-
[18]
Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective, 2021. URLhttps://arxiv.org/abs/1908.04734
-
[19]
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InAdvances in Neural Information Processing Systems (NeurIPS), 2014
work page 2014
-
[20]
Problems of monetary management: The UK experience.Monetary Theory and Practice, pages 91–121, 1984
Charles AE Goodhart. Problems of monetary management: The UK experience.Monetary Theory and Practice, pages 91–121, 1984
work page 1984
-
[21]
Melody Y . Guan, Miles Wang, Micah Carroll, Zehao Dou, Annie Y . Wei, Marcus Williams, Benjamin Arnav, Joost Huizinga, Ian Kivlichan, Mia Glaese, Jakub Pachocki, and Bowen Baker. Monitoring monitorability, 2025. URLhttps://arxiv.org/abs/2512.18311
-
[22]
LLMs Gaming Verifiers: RLVR can Lead to Reward Hacking
Lukas Helff, Quentin Delfosse, David Steinmann, Ruben Härle, Hikaru Shindo, Patrick Schramowski, Wolfgang Stammer, Kristian Kersting, and Felix Friedrich. Llms gaming verifiers: Rlvr can lead to reward hacking, 2026. URLhttps://arxiv.org/abs/2604.15149
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
IQuestLab. Issue #14: Iquest-coder-v1. https://github.com/IQuestLab/ IQuest-Coder-V1/issues/14, 2026. GitHub issue
work page 2026
-
[24]
Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Goldberg. Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks,
- [25]
-
[26]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?, 2024. URLhttps://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Countdown-Code: A Testbed for Studying The Emergence and Generalization of Reward Hacking in RLVR
Muhammad Khalifa, Zohaib Khan, Omer Tafveez, Hao Peng, and Lu Wang. Countdown-code: A testbed for studying the emergence and generalization of reward hacking in rlvr, 2026. URL https://arxiv.org/abs/2603.07084. 11
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Kodovsky, J., Fridrich, J., and Holub, V
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, Scott Emmons, Owain Evans, David Farhi, Ryan Greenblatt, Dan Hendrycks, Marius Hobbhahn, Evan Hubinger, Geoffrey Irving, Erik Jenner, Daniel Kokotajlo, Victoria Krakovna, Shane Legg, David Lindner, David Luan, Aleksand...
-
[29]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, Shuyi Wang, Binxu Li, Qunhong Zeng, Di Wang, Xuandong Zhao, Yuanli Wang, Roey Ben Chaim, Zonglin Di, Yipeng Gao, Junwei He, Yizhuo He, Liqiang Jing, Luyang Kong, Xin Lan, Jiachen Li, Songlin Li, Yijiang Li, Yueqian Lin, Xinyi Liu, X...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
ClawsBench: Evaluating Capability and Safety of LLM Productivity Agents in Simulated Workspaces
Xiangyi Li, Kyoung Whan Choe, Yimin Liu, Xiaokun Chen, Chujun Tao, Bingran You, Wenbo Chen, Zonglin Di, Jiankai Sun, Shenghan Zheng, Jiajun Bao, Yuanli Wang, Weixiang Yan, Yiyuan Li, and Han chung Lee. Clawsbench: Evaluating capability and safety of llm productivity agents in simulated workspaces, 2026. URLhttps://arxiv.org/abs/2604.05172
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Diagnosing pathological chain-of-thought in reasoning models, 2026
Manqing Liu, David Williams-King, Ida Caspary, Linh Le, Hannes Whittingham, Puria Rad- mard, Cameron Tice, and Edward James Young. Diagnosing pathological chain-of-thought in reasoning models, 2026. URLhttps://arxiv.org/abs/2602.13904
-
[32]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating llms as agents, 2025. URL https://arxiv.org/abs/2308.03688
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Natural emergent misalignment from reward hacking in production rl, 2025
Monte MacDiarmid, Benjamin Wright, Jonathan Uesato, Joe Benton, Jon Kutasov, Sara Price, Naia Bouscal, Sam Bowman, Trenton Bricken, Alex Cloud, Carson Denison, Johannes Gasteiger, Ryan Greenblatt, Jan Leike, Jack Lindsey, Vlad Mikulik, Ethan Perez, Alex Rodrigues, Drake Thomas, Albert Webson, Daniel Ziegler, and Evan Hubinger. Natural emergent misalignmen...
-
[34]
Gonzalez, Jingbo 12 Preprint FrontierCS T eam Shang, and Alvin Cheung
Qiuyang Mang, Wenhao Chai, Zhifei Li, Huanzhi Mao, Shang Zhou, Alexander Du, Hanchen Li, Shu Liu, Edwin Chen, Yichuan Wang, Xieting Chu, Zerui Cheng, Yuan Xu, Tian Xia, Zirui Wang, Tianneng Shi, Jianzhu Yao, Yilong Zhao, Qizheng Zhang, Charlie Ruan, Zeyu Shen, Kaiyuan Liu, Runyuan He, Dong Xing, Zerui Li, Zirong Zeng, Yige Jiang, Lufeng Cheng, Ziyi Zhao, ...
-
[35]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
GAIA: a benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants, 2023. URL https://arxiv.org/abs/ 2311.12983
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Introducing codex.https://openai.com/index/introducing-codex/, 2025
OpenAI. Introducing codex.https://openai.com/index/introducing-codex/, 2025
work page 2025
-
[38]
Why swe-bench verified no longer measures frontier coding capabilities
OpenAI. Why swe-bench verified no longer measures frontier coding capabilities. https: //openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/, 2026
work page 2026
-
[39]
Proving test set contamination in black box language models
Yonatan Oren, Nicole Meister, Niladri Chatterji, Faisal Ladhak, and Tatsunori B. Hashimoto. Proving test set contamination in black box language models, 2023. URL https://arxiv. org/abs/2310.17623
-
[40]
KernelBench: Can LLMs Write Efficient GPU Kernels?
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, and Azalia Mirhoseini. Kernelbench: Can llms write efficient gpu kernels?, 2025. URL https: //arxiv.org/abs/2502.10517
work page internal anchor Pith review arXiv 2025
-
[41]
arXiv preprint arXiv:2402.06627 , year=
Alexander Pan, Erik Jones, Meena Jagadeesan, and Jacob Steinhardt. Feedback loops with language models drive in-context reward hacking, 2024. URL https://arxiv.org/abs/ 2402.06627
-
[42]
Proximal Labs. Frontierswe: Benchmarking software engineering skill at the edge of human ability.https://www.frontierswe.com/, 2026
work page 2026
-
[43]
Vyas Raina, Adian Liusie, and Mark Gales. Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment, 2024. URL https://arxiv.org/abs/2402. 14016
work page 2024
-
[44]
Posttrainbench: Can llm agents automate llm post-training?,
Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, and Maksym Andriushchenko. Posttrainbench: Can llm agents automate llm post-training?,
- [45]
-
[46]
Goal misgeneralization: Why correct specifications aren’t enough for correct goals, 2022
Rohin Shah, Vikrant Varma, Ramana Kumar, Mary Phuong, Victoria Krakovna, Jonathan Uesato, and Zac Kenton. Goal misgeneralization: Why correct specifications aren’t enough for correct goals, 2022. URLhttps://arxiv.org/abs/2210.01790
-
[47]
Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker
Shivalika Singh, Yiyang Nan, Alex Wang, Daniel D’Souza, Sayash Kapoor, Ahmet Üstün, Sanmi Koyejo, Yuntian Deng, Shayne Longpre, Noah A. Smith, Beyza Ermis, Marzieh Fadaee, and Sara Hooker. The leaderboard illusion, 2025. URL https://arxiv.org/abs/2504. 20879
work page 2025
- [48]
-
[49]
Detecting Safety Violations Across Many Agent Traces
Adam Stein, Davis Brown, Hamed Hassani, Mayur Naik, and Eric Wong. Detecting safety violations across many agent traces, 2026. URLhttps://arxiv.org/abs/2604.11806
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Marilyn Strathern. “improving ratings”: Audit in the British university system.European Review, 5(3):305–321, 1997
work page 1997
-
[51]
Recent frontier models are reward hacking,
Beth Barnes Sydney V on Arx, Lawrence Chan. Recent frontier models are reward hacking,
-
[52]
URLhttps://metr.org/blog/2025-06-05-recent-reward-hacking/
work page 2025
-
[53]
FieldWorkArena: Agentic AI Benchmark for Real Field Work Tasks
Jun Takahashi, Atsunori Moteki, Akiyoshi Uchida, Shoichi Masui, Fan Yang, Kanji Uchino, Yueqi Song, Yonatan Bisk, Graham Neubig, Ikuo Kusajima, Yasuto Watanabe, Hiroyuki Ishida, Koki Nakagawa, and Shan Jiang. Fieldworkarena: Agentic ai benchmark for real field work tasks, 2026. URLhttps://arxiv.org/abs/2505.19662. 13
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
BenchGuard: Who Guards the Benchmarks? Automated Auditing of LLM Agent Benchmarks
Xinming Tu, Tianze Wang, Yingzhou, Lu, Kexin Huang, Yuanhao Qu, and Sara Mostafavi. Benchguard: Who guards the benchmarks? automated auditing of llm agent benchmarks, 2026. URLhttps://arxiv.org/abs/2604.24955
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Detecting and Suppressing Reward Hacking with Gradient Fingerprints
Songtao Wang, Quang Hieu Pham, Fangcong Yin, Xinpeng Wang, Jocelyn Qiaochu Chen, Greg Durrett, and Xi Ye. Detecting and suppressing reward hacking with gradient fingerprints, 2026. URLhttps://arxiv.org/abs/2604.16242
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Reward hacking in reinforcement learning., 2024
Lilian Weng. Reward hacking in reinforcement learning., 2024. URL https://lilianweng. github.io/posts/2024-11-28-reward-hacking/
work page 2024
-
[57]
Monitoring emergent reward hacking during generation via internal activations, 2026
Patrick Wilhelm, Thorsten Wittkopp, and Odej Kao. Monitoring emergent reward hacking during generation via internal activations, 2026. URLhttps://arxiv.org/abs/2603.04069
-
[58]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments, 2024. URL https: //arxiv.org/abs/2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Investigating cot monitorability in large reasoning models, 2026
Shu Yang, Junchao Wu, Xilin Gong, Xuansheng Wu, Derek Wong, Ninghao Liu, and Di Wang. Investigating cot monitorability in large reasoning models, 2026. URL https://arxiv.org/ abs/2511.08525
-
[60]
Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples, 2023. URL https://arxiv.org/abs/2311.04850
-
[61]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024. URL https://arxiv.org/abs/ 2406.12045
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Utboost: Rigorous evaluation of coding agents on swe-bench, 2025
Boxi Yu, Yuxuan Zhu, Pinjia He, and Daniel Kang. Utboost: Rigorous evaluation of coding agents on swe-bench, 2025. URLhttps://arxiv.org/abs/2506.09289
-
[63]
Swe-abs: Adversarial benchmark strengthening exposes inflated success rates on test-based benchmark,
Boxi Yu, Yang Cao, Yuzhong Zhang, Liting Lin, Junjielong Xu, Zhiqing Zhong, Qinghua Xu, Guancheng Wang, Jialun Cao, Shing-Chi Cheung, Pinjia He, and Lionel Briand. Swe-abs: Adversarial benchmark strengthening exposes inflated success rates on test-based benchmark,
- [64]
-
[65]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. URL https://arxiv.org/abs/ 2307.13854
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
Wang, Sadjad Fouladi, Francis Y
Yajie Zhou, Jiajun Ruan, Eric S. Wang, Sadjad Fouladi, Francis Y . Yan, Kevin Hsieh, and Zaoxing Liu. Netarena: Dynamic benchmarks for ai agents in network automation, 2026. URL https://arxiv.org/abs/2506.03231
-
[67]
Establishing best practices for building rigorous agentic benchmarks,
Yuxuan Zhu, Tengjun Jin, Yada Pruksachatkun, Andy Zhang, Shu Liu, Sasha Cui, Sayash Kapoor, Shayne Longpre, Kevin Meng, Rebecca Weiss, Fazl Barez, Rahul Gupta, Jwala Dhamala, Jacob Merizian, Mario Giulianelli, Harry Coppock, Cozmin Ududec, Jasjeet Sekhon, Jacob Steinhardt, Antony Kellermann, Sarah Schwettmann, Matei Zaharia, Ion Stoica, Percy Liang, and D...
-
[68]
URLhttps://arxiv.org/abs/2507.02825. 14 A Disclosure of Language Model Usage This work uses frontier LLMs as core research instruments (benchmark auditors and alignment judges), as described in Sections 3–5. Additionally, LLMs were used to review and refine drafts of this manuscript; all scientific claims, experimental design, and analysis were conducted ...
-
[69]
Match the incoming prompt against the question field of each record and emit the corre- sponding answer verbatim. The unmodified MALT scoring path then accepts the prediction at 1.0. The defect is structural: the gold artifact is part of the task distribution itself, so isolation cannot help. 15 B.3 V3 – Remote code execution into the evaluator (AgentBenc...
-
[70]
Search the web for "{name} benchmark github" to find the repository URL
-
[71]
Once you have the URL, clone it: git clone --depth=1 <URL> {dest}
-
[72]
7 8If the benchmark is well-known (e.g
Verify {dest} is not empty. 7 8If the benchmark is well-known (e.g. SWE-bench, WebArena, GAIA, HumanEval, 9MBPP, MATH, GSM8K, ARC, HellaSwag, MMLU, BigCodeBench, etc.), try the 10most likely GitHub URL directly before searching. 11 12You MUST clone into exactly this path: {dest} Listing 8: Setup phase: search-and-clone fallback prompt (SEARCH_PROMPT). Rec...
-
[73]
**Entry points** -- Find the main scripts for running evaluations
-
[74]
**Evaluation functions** -- Identify scoring / grading / judging code
-
[75]
**Task configuration** -- Find task definitions, gold files, expected answers
-
[76]
**Execution environment** -- Docker, subprocess, shared filesystem?
-
[77]
**LLM-as-judge** -- Any LLM-based evaluation (OpenAI/Anthropic API calls)?
-
[78]
**Trust boundaries** -- Where does agent output flow into the evaluator?
-
[79]
**Cost estimate** -- Lightweight / Moderate / Heavy to run the evaluation. 25 26Be thorough. Read actual code. Cite file paths and line numbers. 27 28## Task ID enumeration (REQUIRED!!) 29 30Before finishing, enumerate **all** concrete task / problem IDs in the 31benchmark and write them to ‘{workspace}/{task_ids_filename}‘ as a JSON 32**object** mapping ...
-
[80]
Create a directory: ‘{workspace}/benchjack_poc/‘
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.