Recognition: 3 theorem links
· Lean TheoremA Unified Framework for Critical Scaling of Inverse Temperature in Self-Attention
Pith reviewed 2026-05-14 19:50 UTC · model grok-4.3
The pith
The critical inverse-temperature scale for self-attention concentration is fixed by an upper-tail accumulation scale derived from the gap-counting function of each attention row.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The desirable scale is the upper-tail accumulation scale built from the gap-counting function N_n of each attention row. Below this scale the top competitors remain unseparated; above it the attention entropy collapses. The framework unifies earlier scaling laws as special cases of different N_n and gives a direct diagnostic for attention-score families ranging from theoretical models to trained transformers.
What carries the argument
The upper-tail accumulation scale constructed from the gap-counting function N_n, which counts how many competitors lie within each successive gap from the maximum attention score.
If this is right
- Prior proposals ranging from (log n)^{1/2} to log n and (log n)^2 arise as different choices of the gap-counting function N_n.
- Below the upper-tail accumulation scale multiple leading scores stay competitive and attention fails to concentrate.
- Above the scale the softmax distribution collapses sharply and entropy drops.
- The scale supplies a computable diagnostic that can be applied to observed attention scores in any transformer.
Where Pith is reading between the lines
- Training runs could track N_n on the fly to decide the minimal rescaling needed for stability.
- New attention variants could be engineered so their score gaps produce a target critical scale.
- Extreme-value statistics on attention-score tails would immediately predict the scaling law for any new model family.
Load-bearing premise
That the gap-counting function N_n of each attention row fully determines the critical scale and that attention-score distributions admit well-defined successive gaps from the maximum.
What would settle it
For a concrete family of attention scores whose N_n is known, measure whether the entropy collapse occurs at the predicted inverse-temperature scale or at a different power of log n.
Figures





read the original abstract
Length-dependent logit rescaling is widely used to stabilize long-context self-attention, but existing analyses and methods suggest conflicting inverse-temperature laws for the context length $n$, ranging from $(\log n)^{1/2}$ to $\log n$ and $(\log n)^2$. We provide a general theory showing that the desirable scale is determined by the gap-counting function $N_n$ of each attention row. Counting how many competitors lie within each gap from the maximum, we define an upper-tail accumulation scale and prove that it gives the critical inverse-temperature scale for softmax concentration: below this scale, the top competitors remain unseparated, whereas above it, the attention entropy collapses. This framework unifies prior scaling laws as different $N_n$ and yields a direct diagnostic for attention-score families, from idealized theoretical models to more practical transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified framework for determining the critical inverse-temperature scaling in self-attention based on a gap-counting function N_n derived from attention scores. It defines an upper-tail accumulation scale and claims to prove that this scale governs the transition to softmax concentration, unifying various length-dependent scaling laws as instances of different N_n behaviors.
Significance. Should the derivations be rigorous, this work offers a significant contribution by providing a general, diagnostic-based approach to temperature scaling that reconciles conflicting results in the field. It emphasizes the role of attention score distributions and could lead to more robust methods for long-context modeling in transformers.
major comments (2)
- [§3] §3, Theorem 3.1: The central proof that the upper-tail accumulation scale controls softmax concentration relies on the gap-counting function N_n fully determining the transition; the handling of cases with no well-defined gaps (e.g., ties or continuous distributions without strict ordering) is not explicitly addressed and is load-bearing for the claimed critical scale.
- [§4.2] §4.2: The unification of prior scalings (sqrt(log n), log n, (log n)^2) as special cases of N_n is illustrated with examples, but the explicit reduction from a given N_n form to the scaling exponent is only sketched rather than derived in full, weakening verification of the framework's generality.
minor comments (3)
- [Abstract] Abstract: The phrase 'logit rescaling' appears without immediate clarification that it refers to inverse-temperature scaling; consistent terminology from the outset would improve precision.
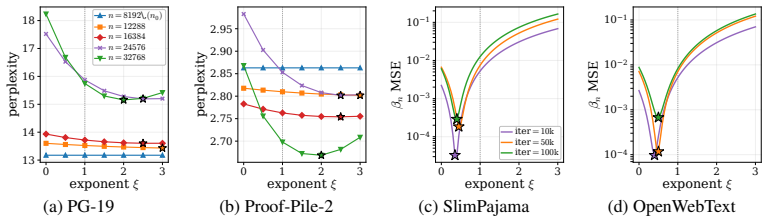
- [Figure 1] Figure 1: The plots of attention entropy versus inverse temperature would be clearer if the predicted critical scale (from the accumulation formula) were marked explicitly on the x-axis for each N_n case.
- Notation: The accumulation scale is introduced in §3 but referenced in the introduction without a forward pointer; adding an early definition or equation number would aid readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments, which help clarify the presentation of our unified framework. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [§3] §3, Theorem 3.1: The central proof that the upper-tail accumulation scale controls softmax concentration relies on the gap-counting function N_n fully determining the transition; the handling of cases with no well-defined gaps (e.g., ties or continuous distributions without strict ordering) is not explicitly addressed and is load-bearing for the claimed critical scale.
Authors: We agree that explicit handling of ties and continuous distributions strengthens the result. Theorem 3.1 is stated for strictly ordered scores, which holds with probability 1 under continuous distributions. For discrete cases with positive tie probability, the critical scale remains unchanged when ties are broken uniformly at random, as this only affects a vanishing fraction of the upper tail. In the revision we will add a short remark after Theorem 3.1 and a brief appendix paragraph deriving the same accumulation scale under random tie-breaking, confirming the claimed critical inverse-temperature scaling is unaffected. revision: yes
-
Referee: [§4.2] §4.2: The unification of prior scalings (sqrt(log n), log n, (log n)^2) as special cases of N_n is illustrated with examples, but the explicit reduction from a given N_n form to the scaling exponent is only sketched rather than derived in full, weakening verification of the framework's generality.
Authors: We accept that the reductions should be written out explicitly. Section 4.2 currently illustrates the three canonical N_n regimes with the resulting scalings; we will expand each paragraph to include the intermediate steps that convert the asymptotic form of N_n into the precise exponent of the upper-tail accumulation scale (e.g., solving the implicit equation for the scale when N_n ~ log n yields the sqrt(log n) law). These derivations follow directly from the general definition already given in §3 and will be added in the revised version. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines the gap-counting function N_n directly from observed attention scores in each row and constructs the upper-tail accumulation scale as the critical inverse-temperature threshold via order-statistic arguments on the softmax partition function. This is a direct mathematical mapping from the input score distribution to the claimed transition point (unseparated competitors below the scale, entropy collapse above), without fitting parameters to target laws or reducing the result to a self-citation chain. Prior scalings (sqrt(log n), log n, (log n)^2) are recovered as special cases of different N_n shapes, which follows from the general definition rather than by construction. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears; the framework remains externally falsifiable against attention-score histograms.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard tail bounds and concentration properties of the softmax function
invented entities (2)
-
gap-counting function N_n
no independent evidence
-
upper-tail accumulation scale
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
Definition 4.4 (Upper-tail accumulation scale). The upper-tail accumulation scale Λ_n is the smallest exponent for which the envelope N_n(t) ≤ e^{Λ_n t} (t>0) holds, equivalently Λ_n := sup_{t>0} log N_n(t)/t.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
Theorem 4.6. (Λ_n) is the TE scale. ... Subcritical: β_n/Λ_n → 0 ⇒ top-two collapse; Supercritical: β_n/Λ_n → ∞ ⇒ entropy collapse.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Corollary 4.9 (Coordinate decomposition of ξ_Λ). ... ξ_Λ = ξ_α - ξ_Δ + 1.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems , 30, 2017
2017
-
[2]
Infinite attention: NNGP and NTK for deep attention networks
Jiri Hron, Yasaman Bahri, Jascha Sohl-Dickstein, and Roman Novak. Infinite attention: NNGP and NTK for deep attention networks. In International Conference on Machine Learning (ICML) , pages 4376--4386. PMLR, 2020
2020
-
[3]
Infinite limits of multi-head transformer dynamics
Blake Bordelon, Hamza Chaudhry, and Cengiz Pehlevan. Infinite limits of multi-head transformer dynamics. Advances in Neural Information Processing Systems , 37: 0 35824--35878, 2024
2024
-
[4]
Infinite-width limit of a single attention layer: Analysis via tensor programs
Mana Sakai, Ryo Karakida, and Masaaki Imaizumi. Infinite-width limit of a single attention layer: Analysis via tensor programs. In Advances in Neural Information Processing Systems (NeurIPS) , 2025, https://arxiv.org/abs/2506.00846 arXiv:2506.00846 . URL https://arxiv.org/abs/2506.00846
-
[5]
A mathematical perspective on transformers.CoRR, abs/2312.10794, 2023
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. A mathematical perspective on T ransformers. Bulletin of the American Mathematical Society , 62 0 (3): 0 427--479, 2025. Also arXiv:2312.10794
-
[6]
A multiscale analysis of mean-field transformers in the moderate interaction regime
Giuseppe Bruno, Federico Pasqualotto, and Andrea Agazzi. A multiscale analysis of mean-field transformers in the moderate interaction regime. In Advances in Neural Information Processing Systems (NeurIPS) , 2025, https://arxiv.org/abs/2509.25040 arXiv:2509.25040 . URL https://arxiv.org/abs/2509.25040. Oral
-
[7]
Mind the gap: a spectral analysis of rank collapse and signal propagation in attention layers
Thiziri Nait Saada, Alireza Naderi, and Jared Tanner. Mind the gap: a spectral analysis of rank collapse and signal propagation in attention layers. In Forty-second International Conference on Machine Learning , 2025
2025
-
[8]
Alessio Giorlandino and Sebastian Goldt. Two failure modes of deep transformers and how to avoid them: a unified theory of signal propagation at initialisation. In International Conference on Learning Representations , 2026, https://arxiv.org/abs/2505.24333 arXiv:2505.24333 . URL https://arxiv.org/abs/2505.24333
-
[9]
Critical attention scaling in long-context transformers
Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet. Critical attention scaling in long-context transformers. arXiv preprint , 2025, https://arxiv.org/abs/2510.05554 arXiv:2510.05554 . URL https://arxiv.org/abs/2510.05554
-
[10]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng X...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
-
[12]
YaRN: Efficient Context Window Extension of Large Language Models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN : Efficient context window extension of large language models. arXiv preprint , 2023, https://arxiv.org/abs/2309.00071 arXiv:2309.00071 . URL https://arxiv.org/abs/2309.00071. Published at ICLR 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Ben Anson, Xi Wang, and Laurence Aitchison. Scale-invariant attention. In Advances in Neural Information Processing Systems (NeurIPS) , 2025, https://arxiv.org/abs/2505.17083 arXiv:2505.17083 . URL https://arxiv.org/abs/2505.17083
-
[14]
B. Derrida. Random-energy model: An exactly solvable model of disordered systems. Physical Review B , 24 0 (5): 0 2613--2626, 1981
1981
-
[15]
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. In International Conference on Learning Representations , 2020, https://arxiv.org/abs/1911.05507 arXiv:1911.05507 . URL https://openreview.net/forum?id=SylKikSYDH
-
[16]
Llemma: An open language model for mathematics.arXiv preprint arXiv:2310.10631, 2023
Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma : An open language model for mathematics. In International Conference on Learning Representations , 2024, https://arxiv.org/abs/2310.10631 arXiv:2310.10631 . URL https://openreview.net/forum?id=4WnqRR915j
-
[17]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical report, OpenAI, 2019. URL https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
2019
-
[18]
nanoGPT : The simplest, fastest repository for training/finetuning medium-sized GPTs
Andrej Karpathy. nanoGPT : The simplest, fastest repository for training/finetuning medium-sized GPTs . https://github.com/karpathy/nanoGPT, 2022
2022
-
[19]
Steeves, Joel Hestness, and Nolan Dey
Daria Soboleva, Faisal Al-Khateeb, Robert Myers, Jacob R. Steeves, Joel Hestness, and Nolan Dey. SlimPajama : A 627 B token cleaned and deduplicated version of RedPajama . https://cerebras.ai/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama, 2023
2023
-
[20]
OpenWebText corpus
Aaron Gokaslan, Vanya Cohen, Ellie Pavlick, and Stefanie Tellex. OpenWebText corpus. http://Skylion007.github.io/OpenWebTextCorpus, 2019
2019
-
[21]
Attention is not all you need: pure attention loses rank doubly exponentially with depth
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: pure attention loses rank doubly exponentially with depth. In International Conference on Machine Learning (ICML) , volume 139 of Proceedings of Machine Learning Research , pages 2793--2803, 2021
2021
-
[22]
Signal propagation in T ransformers: Theoretical perspectives and the role of rank collapse
Lorenzo Noci, Sotiris Anagnostidis, Luca Biggio, Antonio Orvieto, Sidak Pal Singh, and Aurelien Lucchi. Signal propagation in T ransformers: Theoretical perspectives and the role of rank collapse. In Advances in Neural Information Processing Systems (NeurIPS) , 2022, https://arxiv.org/abs/2206.03126 arXiv:2206.03126
-
[23]
Geometric dynamics of signal propagation predict trainability of transformers
Aditya Cowsik, Tamra Nebabu, Xiao-Liang Qi, and Surya Ganguli. Geometric dynamics of signal propagation predict trainability of transformers. Physical Review E , 112: 0 055301, 2025. Also arXiv:2403.02579
-
[24]
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics. In Advances in Neural Information Processing Systems (NeurIPS) , 2023, https://arxiv.org/abs/2305.05465 arXiv:2305.05465
-
[25]
Asymptotics of SGD in sequence-single index models and single-layer attention networks
Luca Arnaboldi, Bruno Loureiro, Ludovic Stephan, Florent Krzakala, and Lenka Zdeborov \'a . Asymptotics of SGD in sequence-single index models and single-layer attention networks. In Advances in Neural Information Processing Systems (NeurIPS) , 2025, https://arxiv.org/abs/2506.02651 arXiv:2506.02651 . URL https://arxiv.org/abs/2506.02651
-
[26]
How do transformers learn topic structure: Towards a mechanistic understanding
Yuchen Li, Yuanzhi Li, and Andrej Risteski. How do transformers learn topic structure: Towards a mechanistic understanding. In Proceedings of the 40th International Conference on Machine Learning (ICML) , volume 202 of Proceedings of Machine Learning Research , pages 19689--19729, 2023. URL https://proceedings.mlr.press/v202/li23p.html
2023
-
[27]
How transformers learn structured data: Insights from hierarchical filtering
J \'e r \^o me Garnier-Brun, Marc M \'e zard, Emanuele Moscato, and Luca Saglietti. How transformers learn structured data: Insights from hierarchical filtering. In Proceedings of the 42nd International Conference on Machine Learning (ICML) , 2025. URL https://openreview.net/forum?id=AVXApuBCvN
2025
-
[28]
Dynamic metastability in the self-attention model
Borjan Geshkovski, Hugo Koubbi, Yury Polyanskiy, and Philippe Rigollet. Dynamic metastability in the self-attention model. arXiv preprint arXiv:2410.06833 , 2024, https://arxiv.org/abs/2410.06833 arXiv:2410.06833 . URL https://arxiv.org/abs/2410.06833
-
[29]
Clustering in causal attention masking
Nikita Karagodin, Yury Polyanskiy, and Philippe Rigollet. Clustering in causal attention masking. In Advances in Neural Information Processing Systems (NeurIPS) , volume 37, pages 115652--115681, 2024, https://arxiv.org/abs/2411.04990 arXiv:2411.04990 . URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/d18d208fa9c333483e5724ade7beff0f-Abstrac...
-
[30]
Recurrent self-attention dynamics: An energy-agnostic perspective from jacobians
Akiyoshi Tomihari and Ryo Karakida. Recurrent self-attention dynamics: An energy-agnostic perspective from jacobians. In Advances in Neural Information Processing Systems (NeurIPS) , 2025, https://arxiv.org/abs/2505.19458 arXiv:2505.19458 . URL https://openreview.net/forum?id=GKLePUzyO8
-
[31]
The mean-field dynamics of transformers
Philippe Rigollet. The mean-field dynamics of transformers. arXiv preprint arXiv:2512.01868 , 2026, https://arxiv.org/abs/2512.01868 arXiv:2512.01868 . URL https://arxiv.org/abs/2512.01868. To appear in Proceedings of the ICM 2026
-
[32]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer : Enhanced transformer with rotary position embedding. Neurocomputing , 568: 0 127063, 2024, https://arxiv.org/abs/2104.09864 arXiv:2104.09864
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.