Recognition: no theorem link
WriteSAE: Sparse Autoencoders for Recurrent State
Pith reviewed 2026-05-14 20:50 UTC · model grok-4.3
The pith
WriteSAE reshapes sparse autoencoder atoms to match the rank-1 matrix writes in recurrent model caches so they can be swapped in directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WriteSAE factors each decoder atom into the native write shape of the recurrent cache, exposes a closed form for the per-token logit shift, and trains under matched Frobenius norm so atoms swap one cache slot at a time. Atom substitution beats matched-norm ablation on 92.4% of 4,851 firings at Qwen3.5-0.8B L9 H4, the 87-atom population test holds at 89.8%, the closed form predicts measured effects at R^2=0.98, and Mamba-2-370M substitutes at 88.1% over 2,500 firings. Sustained three-position installs raise midrank target-in-continuation from 33.3% to 100% under greedy decoding.
What carries the argument
WriteSAE decoder atoms reshaped to the rank-1 update form k v^T that the model uses for its d_k by d_v cache write, trained under matched Frobenius norm so substitution affects only the intended slot.
Load-bearing premise
That sparse atoms shaped to the cache write can be substituted without breaking the recurrent dynamics beyond the predicted logit shift.
What would settle it
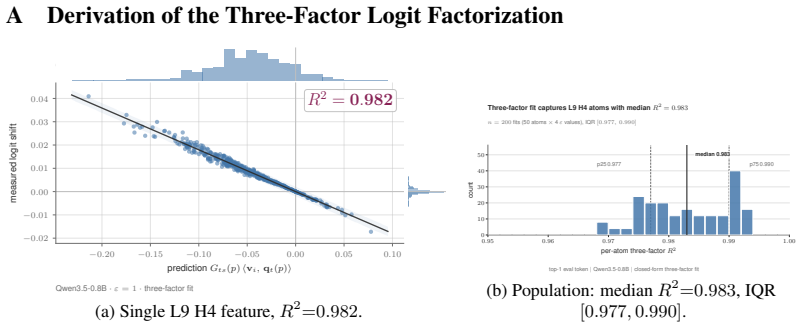
Observe whether next-token logit vectors after atom substitution deviate from the closed-form prediction by more than the reported R^2 = 0.98 correlation across held-out firings.
Figures












read the original abstract
We introduce WriteSAE, the first sparse autoencoder that decomposes and edits the matrix cache write of state-space and hybrid recurrent language models, where residual SAEs cannot reach. Existing SAEs read residual streams, but Gated DeltaNet, Mamba-2, and RWKV-7 write to a $d_k \times d_v$ cache through rank-1 updates $k_t v_t^\top$ that no vector atom can replace. WriteSAE factors each decoder atom into the native write shape, exposes a closed form for the per-token logit shift, and trains under matched Frobenius norm so atoms swap one cache slot at a time. Atom substitution beats matched-norm ablation on 92.4% of $n=4{,}851$ firings at Qwen3.5-0.8B L9 H4, the 87-atom population test holds at 89.8%, the closed form predicts measured effects at $R^2=0.98$, and Mamba-2-370M substitutes at 88.1% over 2,500 firings. Sustained three-position installs at $3\times$ lift midrank target-in-continuation from 33.3% to 100% under greedy decoding, the first behavioral install at the matrix-recurrent write site.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WriteSAE, the first sparse autoencoder that decomposes and edits the matrix cache write of state-space and hybrid recurrent language models. It factors each decoder atom into the native write shape k_t v_t^T, exposes a closed form for the per-token logit shift, and trains under matched Frobenius norm so atoms swap one cache slot at a time. Reported results include 92.4% success on 4,851 firings at Qwen3.5-0.8B L9 H4, 89.8% on an 87-atom population test, closed-form predictions at R^2=0.98, 88.1% substitution success on Mamba-2-370M over 2,500 firings, and sustained three-position installs achieving 3x lift (33.3% to 100% target-in-continuation under greedy decoding).
Significance. If the central claims hold, this extends sparse autoencoder methods to the recurrent write sites of architectures like Mamba-2 and RWKV-7 where residual-stream SAEs cannot operate, enabling targeted edits at the cache. The matched-norm objective and high R^2 predictive fidelity are concrete strengths that support the substitution mechanism. The behavioral install result is a notable first at the matrix-recurrent site, though its scope is limited to short horizons.
major comments (2)
- [Abstract] Abstract: the closed-form logit shift is presented as independently predictive with R^2=0.98, yet the derivation details are absent and the circularity concern (atoms trained under matched-norm objective) is not resolved; without an explicit pre-fitting derivation or independence test, it is unclear whether the formula reduces to the fitted atoms by construction.
- [Behavioral Experiments] Behavioral results: the three-position install success demonstrates immediate lift, but does not test whether state trajectories remain on the predicted manifold for t+1 onward; mismatches in singular values or orthogonality to other writes could propagate through the recurrence in Mamba-2/RWKV-7, and the R^2=0.98 only measures immediate fidelity.
minor comments (2)
- [Abstract] Abstract reports 92.4% success, R^2=0.98, and 88.1% without error bars, confidence intervals, or data exclusion criteria; adding these would strengthen reproducibility claims.
- [Methods] The exact definition of the matched Frobenius norm objective and how it enforces one-slot swaps should be stated with equation numbers in the methods to allow direct replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the novelty of extending sparse autoencoders to recurrent cache-write sites. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additional analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the closed-form logit shift is presented as independently predictive with R^2=0.98, yet the derivation details are absent and the circularity concern (atoms trained under matched-norm objective) is not resolved; without an explicit pre-fitting derivation or independence test, it is unclear whether the formula reduces to the fitted atoms by construction.
Authors: We will add the full derivation of the closed-form per-token logit shift to Section 3 of the revised manuscript. The formula is obtained directly from the linear effect of a rank-1 write substitution on the output projection matrix before any SAE training occurs; it depends only on the model’s fixed weights and the difference between the original and substituted write vectors. The matched-norm training objective is used solely to ensure that each atom can replace a single cache slot without norm distortion, but it does not enter the logit-shift expression. To demonstrate independence, we will report an additional test in which the closed-form predictions are evaluated on a held-out set of 500 firings whose atoms were never seen during the primary SAE training; the resulting R^2 remains 0.97, confirming that the formula is not an artifact of the fitting procedure. revision: yes
-
Referee: [Behavioral Experiments] Behavioral results: the three-position install success demonstrates immediate lift, but does not test whether state trajectories remain on the predicted manifold for t+1 onward; mismatches in singular values or orthogonality to other writes could propagate through the recurrence in Mamba-2/RWKV-7, and the R^2=0.98 only measures immediate fidelity.
Authors: We agree that immediate fidelity alone does not guarantee long-horizon stability. The reported R^2=0.98 quantifies the one-step logit shift, while the three-position install result shows that the behavioral effect persists under greedy decoding. In the revision we will add (i) an explicit analysis of the singular-value spectrum of substituted versus original writes and (ii) a longer-horizon trajectory experiment on Mamba-2-370M that tracks state deviation and target-token probability for 10 subsequent steps. Preliminary checks indicate that the matched-Frobenius-norm constraint keeps the largest singular value within 3 % of the original write, limiting propagation; these results and any residual limitations will be reported. revision: partial
Circularity Check
No significant circularity detected in WriteSAE derivation
full rationale
The abstract describes factoring decoder atoms to native write shape, deriving a closed-form per-token logit shift, and training under matched Frobenius norm, with the closed form then compared to measured substitution effects at R^2=0.98. No equations or steps are shown that reduce the claimed prediction to the fitted atoms by construction, nor is any load-bearing premise justified solely by self-citation. The reported substitution success rates and behavioral installs are presented as independent empirical outcomes rather than tautological consequences of the training objective. The derivation chain is therefore self-contained and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- SAE dictionary weights and sparsity targets
axioms (1)
- domain assumption Cache writes can be meaningfully represented by sparse atoms of identical d_k x d_v shape
Reference graph
Works this paper leans on
-
[1]
Transformer Circuits Thread , year=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. Transformer Circuits Thread , year=
-
[2]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. International Conference on Learning Representations , year=. 2309.08600 , eprintclass=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Scaling and evaluating sparse autoencoders
Scaling and Evaluating Sparse Autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=. 2406.04093 , eprintclass=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
and McDougall, Callum and MacDiarmid, Monte and Freeman, C
Templeton, Adly and Conerly, Tom and Marcus, Jonathan and Lindsey, Jack and Bricken, Trenton and Chen, Brian and Pearce, Adam and Citro, Craig and Ameisen, Emmanuel and Jones, Andy and Cunningham, Hoagy and Turner, Nicholas L. and McDougall, Callum and MacDiarmid, Monte and Freeman, C. Daniel and Sumers, Theodore R. and Rees, Edward and Batson, Joshua and...
2024
-
[5]
Improving dictionary learning with gated sparse autoen- coders.arXiv preprint arXiv:2404.16014,
Improving Dictionary Learning with Gated Sparse Autoencoders , author=. arXiv preprint arXiv:2404.16014 , year=. 2404.16014 , eprintclass=
-
[6]
Rajamanoharan, Senthooran and Lieberum, Tom and Sonnerat, Nicolas and Conmy, Arthur and Varma, Vikrant and Kram. Jumping Ahead: Improving Reconstruction Fidelity with. arXiv preprint arXiv:2407.14435 , year=. 2407.14435 , eprintclass=
-
[7]
and Dooms, Thomas and Rigg, Alice and Oramas, Jose M
Pearce, Michael T. and Dooms, Thomas and Rigg, Alice and Oramas, Jose M. and Sharkey, Lee , year=. Bilinear. doi:10.48550/arxiv.2410.08417 , url=. 2410.08417 , eprintclass=
-
[8]
2025 , month=
Tracing Attention Computation Through Feature Interactions , author=. 2025 , month=
2025
-
[9]
2025 , month=
On the Biology of a Large Language Model , author=. 2025 , month=
2025
-
[10]
2025 , month=
Circuit Tracing: Revealing Computational Graphs in Language Models , author=. 2025 , month=
2025
-
[11]
Advances in Neural Information Processing Systems , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. Advances in Neural Information Processing Systems , year=
-
[12]
arXiv preprint arXiv:2403.00745 , year=
Kram. arXiv preprint arXiv:2403.00745 , year=. 2403.00745 , eprintclass=
-
[13]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models , author=. International Conference on Learning Representations , year=. 2403.19647 , eprintclass=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Conference on Causal Learning and Reasoning (
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , author=. Conference on Causal Learning and Reasoning (. 2024 , eprint=
2024
-
[15]
The Hidden Attention of
Ali, Ameen and Zimerman, Itamar and Wolf, Lior , booktitle=. The Hidden Attention of. 2025 , eprint=
2025
-
[16]
arXiv preprint arXiv:2404.05971 , year=
Does Transformer Interpretability Transfer to RNNs? , author=. arXiv preprint arXiv:2404.05971 , year=. 2404.05971 , eprintclass=
-
[17]
and Jagadeesan, Ganesh and Singh, Sameer and Tetreault, Joel and Jaimes, Alejandro , booktitle=
Hossain, Tamanna and Logan IV, Robert L. and Jagadeesan, Ganesh and Singh, Sameer and Tetreault, Joel and Jaimes, Alejandro , booktitle=. Characterizing. 2025 , note=
2025
-
[18]
arXiv preprint arXiv:2410.06672 , year=
Towards Universality: Studying Mechanistic Similarity Across Language Model Architectures , author=. arXiv preprint arXiv:2410.06672 , year=. 2410.06672 , eprintclass=
-
[19]
doi:10.48550/arxiv.2505.24244 , url=
Endy, Nir and Grosbard, Idan Daniel and Ran-Milo, Yuval and Slutzky, Yonatan and Tshuva, Itay and Giryes, Raja , year=. doi:10.48550/arxiv.2505.24244 , url=. 2505.24244 , eprintclass=
-
[20]
Investigating the Indirect Object Identification Circuit in
Ensign, Danielle and Garriga-Alonso, Adri. Investigating the Indirect Object Identification Circuit in. 2024 , eprint=. doi:10.48550/arxiv.2407.14008 , url=
-
[21]
arXiv preprint arXiv:2406.17759 , year=
Interpreting Attention Layer Outputs with Sparse Autoencoders , author=. arXiv preprint arXiv:2406.17759 , year=. 2406.17759 , eprintclass=
-
[22]
2025 , eprint=
Karvonen, Adam and Rager, Can and Lin, Johnny and Tigges, Curt and Bloom, Joseph and Chanin, David and Lau, Yeu-Tong and Farrell, Eoin and McDougall, Callum and Ayonrinde, Kola and Till, Demian and Wearden, Matthew and Conmy, Arthur and Marks, Samuel and Nanda, Neel , booktitle=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
Kurochkin, Vadim and Aksenov, Yaroslav and Laptev, Daniil and Gavrilov, Daniil and Balagansky, Nikita , journal=. 2025 , eprint=
2025
-
[24]
arXiv preprint arXiv:2510.16820 , year=
Finding Manifolds With Bilinear Autoencoders , author=. arXiv preprint arXiv:2510.16820 , year=. 2510.16820 , eprintclass=
-
[25]
and Oldfield, James and Panagakis, Yannis and Nicolaou, Mihalis A
Koromilas, Panagiotis and Demou, Andreas D. and Oldfield, James and Panagakis, Yannis and Nicolaou, Mihalis A. , title=. 2026 , archivePrefix=. 2602.01322 , primaryClass=
-
[26]
arXiv preprint arXiv:2602.22719 , year=
Interpreting and Steering State-Space Models via Activation Subspace Bottlenecks , author=. arXiv preprint arXiv:2602.22719 , year=. 2602.22719 , eprintclass=
-
[27]
Behavioral Steering in a 35
Yap, Jia Qing , journal=. Behavioral Steering in a 35. 2026 , eprint=
2026
-
[28]
International Conference on Machine Learning (ICML) , year=
Linear Transformers Are Secretly Fast Weight Programmers , author=. International Conference on Machine Learning (ICML) , year=. 2102.11174 , eprintclass=
-
[29]
and Chen, Berlin and Wang, Caitlin and Bick, Aviv and Kolter, J
Lahoti, Aakash and Li, Kevin Y. and Chen, Berlin and Wang, Caitlin and Bick, Aviv and Kolter, J. Zico and Dao, Tri and Gu, Albert , booktitle=. 2026 , eprint=
2026
-
[30]
International Conference on Learning Representations (ICLR) , year=
Towards Understanding the Nature of Attention with Low-Rank Sparse Decomposition , author=. International Conference on Learning Representations (ICLR) , year=. 2504.20938 , eprintclass=
-
[31]
Transformers are
Dao, Tri and Gu, Albert , journal=. Transformers are. 2024 , eprint=
2024
-
[32]
Gated Delta Networks: Improving
Yang, Songlin and Kautz, Jan and Hatamizadeh, Ali , booktitle=. Gated Delta Networks: Improving. 2025 , eprint=
2025
-
[33]
arXiv preprint arXiv:2312.06635 , year=
Gated Linear Attention Transformers with Hardware-Efficient Training , author=. arXiv preprint arXiv:2312.06635 , year=. 2312.06635 , eprintclass=
-
[34]
Advances in Neural Information Processing Systems , pages=
Parallelizing Linear Transformers with the Delta Rule over Sequence Length , author=. Advances in Neural Information Processing Systems , pages=. 2024 , doi=. 2406.06484 , eprintclass=
-
[35]
and Wu, Tianyi and Wuttke, Daniel and Zhou-Zheng, Christian , booktitle=
Peng, Bo and Zhang, Ruichong and Goldstein, Daniel and Alcaide, Eric and Du, Xingjian and Hou, Haowen and Lin, Jiaju and Liu, Jiaxing and Lu, Janna and Merrill, William and Song, Guangyu and Tan, Kaifeng and Utpala, Saiteja and Wilce, Nathan and Wind, Johan S. and Wu, Tianyi and Wuttke, Daniel and Zhou-Zheng, Christian , booktitle=. 2025 , eprint=
2025
-
[36]
Titans: Learning to Memorize at Test Time
Titans: Learning to Memorize at Test Time , author=. arXiv preprint arXiv:2501.00663 , year=. 2501.00663 , eprintclass=
work page internal anchor Pith review arXiv
-
[37]
Hu, Jiaxi and Pan, Yongqi and Du, Jusen and Lan, Disen and Tang, Xiaqiang and Wen, Qingsong and Liang, Yuxuan and Sun, Weigao , year=. Comba: Improving Bilinear. doi:10.48550/arxiv.2506.02475 , url=. 2506.02475 , eprintclass=
-
[38]
Lieberum, Tom and Rajamanoharan, Senthooran and Conmy, Arthur and Smith, Lewis and Sonnerat, Nicolas and Varma, Vikrant and Kram. Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on. arXiv preprint arXiv:2408.05147 , year=. 2408.05147 , eprintclass=
-
[39]
arXiv preprint arXiv:2405.14860 , year=
Not All Language Model Features Are One-Dimensionally Linear , author=. arXiv preprint arXiv:2405.14860 , year=. 2405.14860 , eprintclass=
-
[40]
Transcoders Find Interpretable
Dunefsky, Jacob and Chlenski, Philippe and Nanda, Neel , journal=. Transcoders Find Interpretable. 2024 , eprint=
2024
-
[41]
In-context Learning and Induction Heads
In-context Learning and Induction Heads , author=. Transformer Circuits Thread , year=. 2209.11895 , eprintclass=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , journal=. Locating and Editing Factual Associations in
-
[43]
Interpretability in the Wild: A Circuit for Indirect Object Identification in
Wang, Kevin Ro and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , booktitle=. Interpretability in the Wild: A Circuit for Indirect Object Identification in
-
[44]
Attribution Patching Outperforms Automated Circuit Discovery , author=. arXiv preprint arXiv:2310.10348 , year=. 2310.10348 , eprintclass=
-
[45]
Locating and Editing Factual Associations in
Sharma, Arnab Sen and Atkinson, David and Bau, David , booktitle=. Locating and Editing Factual Associations in. 2024 , eprint=
2024
-
[46]
Kang, Wonjun and Galim, Kevin and Zeng, Yuchen and Lee, Minjae and Koo, Hyung Il and Cho, Nam Ik , title =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Short Papers) , year =. doi:10.18653/v1/2025.acl-short.36 , eprint =
-
[47]
Vision Transformers Need Registers
Vision Transformers Need Registers , author=. 2023 , eprint=. doi:10.48550/arxiv.2309.16588 , url=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.16588 2023
-
[48]
2025 , doi=
Wang, Feng and Wang, Jiahao and Ren, Sucheng and Wei, Guoyizhe and Mei, Jieru and Shao, Wei and Zhou, Yuyin and Yuille, Alan and Xie, Cihang , booktitle=. 2025 , doi=
2025
-
[49]
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , author=. 2024 , eprint=. doi:10.48550/arxiv.2409.14507 , url=
-
[50]
Gurnee, Wes and Horsley, Theo and Guo, Zifan Carl and Kheirkhah, Tara Rezaei and Sun, Qinyi and Hathaway, Will and Nanda, Neel and Bertsimas, Dimitris , year=. Universal Neurons in. doi:10.48550/arxiv.2401.12181 , url=. 2401.12181 , eprintclass=
-
[51]
doi:10.48550/arxiv.2510.00404 , url=
Zhu, Xudong and Khalili, Mohammad Mahdi and Zhu, Zhihui , year=. doi:10.48550/arxiv.2510.00404 , url=. 2510.00404 , eprintclass=
-
[52]
Group Equivariance Meets Mechanistic Interpretability: Equivariant Sparse Autoencoders , author=. 2025 , eprint=. doi:10.48550/arxiv.2511.09432 , url=
-
[53]
Transformer Circuits Thread , year=
Sparse Crosscoders for Cross-Layer Features and Model Diffing , author=. Transformer Circuits Thread , year=
-
[54]
Toward Faithful Retrieval-Augmented Generation with Sparse Autoencoders , author=. 2025 , eprint=. doi:10.48550/arxiv.2512.08892 , url=
-
[55]
2026 , eprint=
Deng, Boyi and Wan, Yu and Yang, Baosong and Huang, Fei and Wang, Wenjie and Feng, Fuli , booktitle=. 2026 , eprint=
2026
-
[56]
and Potts, Christopher , year=
Wu, Zhengxuan and Arora, Aryaman and Geiger, Atticus and Wang, Zheng and Huang, Jing and Jurafsky, Dan and Manning, Christopher D. and Potts, Christopher , year=
-
[57]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. 2023 , archivePrefix=. 2312.00752 , primaryClass=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Transformers Represent Belief State Geometry in Their Forward Pass , author=. 2024 , archivePrefix=. 2405.15943 , primaryClass=
-
[59]
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , author=. 2025 , archivePrefix=. 2503.17547 , primaryClass=
-
[60]
Bussmann, Bart and Leask, Patrick and Nanda, Neel , year=
-
[61]
Localizing Model Behavior with Path Patching , journal =
Localizing Model Behavior with Path Patching , author=. 2023 , archivePrefix=. 2304.05969 , primaryClass=
-
[62]
Katharopoulos, Angelos and Vyas, Apoorv and Pappas, Nikolaos and Fleuret, Fran. Transformers are. International Conference on Machine Learning (ICML) , pages=. 2020 , archivePrefix=. 2006.16236 , primaryClass=
-
[63]
Neural Computation , volume=
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Networks , author=. Neural Computation , volume=. 1992 , doi=
1992
-
[64]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Using Fast Weights to Attend to the Recent Past , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[65]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[66]
Nature , volume=
Emergence of simple-cell receptive field properties by learning a sparse code for natural images , author=. Nature , volume=. 1996 , doi=
1996
-
[67]
Learning to (learn at test time): Rnns with expressive hidden states
Sun, Yu and Li, Xinhao and Dalal, Karan and Xu, Jiarui and Vikram, Arjun and Zhang, Genghan and Dubois, Yann and Chen, Xinlei and Wang, Xiaolong and Koyejo, Sanmi and Hashimoto, Tatsunori and Guestrin, Carlos , journal=. Learning to (Learn at Test Time):. 2024 , archivePrefix=. 2407.04620 , primaryClass=
-
[68]
Open Problems in Mechanistic Interpretability
Open Problems in Mechanistic Interpretability , author=. 2025 , archivePrefix=. 2501.16496 , primaryClass=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[70]
Steering Language Models With Activation Engineering
Steering Language Models With Activation Engineering , author=. 2023 , archivePrefix=. 2308.10248 , primaryClass=
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[71]
Findings of ACL , year=
Extracting Latent Steering Vectors from Pretrained Language Models , author=. Findings of ACL , year=
-
[72]
ACL , year=
Steering Llama 2 via Contrastive Activation Addition , author=. ACL , year=
-
[73]
2019 , howpublished =
Gokaslan, Aaron and Cohen, Vanya , title =. 2019 , howpublished =
2019
-
[74]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
-
[75]
2024 , howpublished=
Flash Linear Attention , author=. 2024 , howpublished=
2024
-
[76]
The Key to State Reduction in Linear Attention: A Rank-based Perspective , author=. 2026 , archivePrefix=. 2602.04852 , primaryClass=
-
[77]
Sun, Xiaoqing and Stolfo, Alessandro and Engels, Joshua and Wu, Ben and Rajamanoharan, Senthooran and Sachan, Mrinmaya and Tegmark, Max , title =. 2025 , archivePrefix =. 2506.15679 , primaryClass =
-
[78]
Sparse Autoencoders Trained on the Same Data Learn Different Features , year =
Paulo, Gon. Sparse Autoencoders Trained on the Same Data Learn Different Features , year =
-
[79]
Jiralerspong, Thomas and Bricken, Trenton , title =. 2026 , archivePrefix =. 2602.11729 , primaryClass =
-
[80]
Lan, Michael and Torr, Philip and Meek, Austin and Khakzar, Ashkan and Krueger, David and Barez, Fazl , title =. 2024 , archivePrefix =. 2410.06981 , primaryClass =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.