Recognition: unknown
Training Large Language Models to Predict Clinical Events
Pith reviewed 2026-05-14 19:57 UTC · model grok-4.3
The pith
A small LoRA adapter trained on time-ordered clinical notes improves calibration for predicting future patient events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
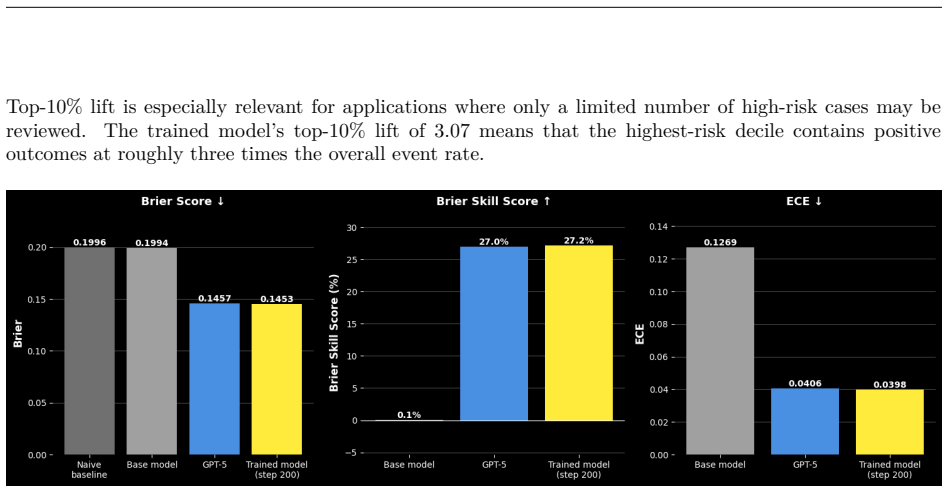
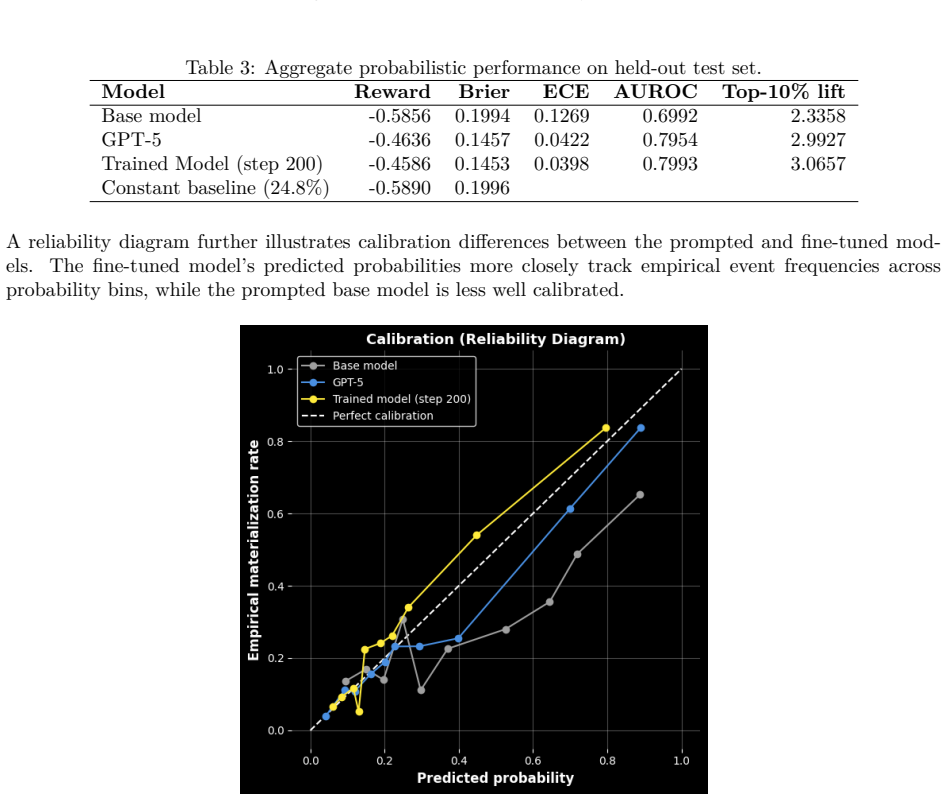
Converting time-ordered clinical notes into examples of past context, a natural-language question about a possible future event, and a label resolved from later documentation allows a small LoRA adapter to be trained that improves over the prompted base model, cutting expected calibration error from 0.1269 to 0.0398 and Brier score from 0.199 to 0.145 while slightly outperforming GPT-5 on held-out questions.
What carries the argument
The conversion of longitudinal notes into prediction examples consisting of past context, a natural-language future-event question, and a later-documentation label, used to supervise LoRA fine-tuning.
If this is right
- Enables reusable clinical prediction supervision from longitudinal notes without hand-engineered structured features.
- Supports a single adapter across multiple event types instead of separate endpoint-specific classifiers.
- Produces better-calibrated probability estimates than prompting the base model alone.
- Yields slight gains over GPT-5 point estimates on held-out clinical questions.
Where Pith is reading between the lines
- The same note-to-example conversion could be applied to other large clinical corpora to test generalization beyond MIMIC-III.
- Real-time deployment in electronic health records might allow ongoing updates to predictions as new notes arrive.
- Combining the adapter with structured data streams could further reduce reliance on note-only supervision.
Load-bearing premise
Labels resolved from later documentation in the same admission accurately represent true future events without systematic bias, missing data, or documentation lag.
What would settle it
A prospective test on new admissions where model predictions are compared directly against actual clinical outcomes recorded after the prediction time.
Figures

read the original abstract
Longitudinal clinical notes contain rich evidence of how patients evolve over time, but converting this signal into training supervision for clinical prediction remains challenging. We extend Foresight Learning to clinical prediction by converting time-ordered MIMIC-III notes into examples consisting of past patient context, a natural-language question about a possible future event, and a label resolved from later documentation. This process yields 6,900 prediction examples from 702 admissions across medications, procedures, organ support, microbiology, and mortality. A small LoRA adapter trained on these examples improves over the prompted base model, reducing expected calibration error from 0.1269 to 0.0398 and Brier score from 0.199 to 0.145, while slightly outperforming GPT-5 point estimates on held-out questions. The approach enables reusable clinical prediction supervision from longitudinal notes without hand-engineered structured features or endpoint-specific classifiers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends Foresight Learning to clinical prediction by converting time-ordered MIMIC-III notes into 6,900 supervised examples consisting of past context, a natural-language question about a possible future event, and a label resolved from later documentation within the same admission. A small LoRA adapter is trained on these examples and reported to reduce expected calibration error from 0.1269 to 0.0398 and Brier score from 0.199 to 0.145 on held-out questions, while slightly outperforming GPT-5 point estimates.
Significance. If the label resolution process provides faithful proxies for actual future events, the work demonstrates a scalable route to reusable clinical prediction supervision directly from longitudinal notes without hand-engineered structured features or endpoint-specific classifiers, potentially enabling broader LLM-based forecasting in healthcare.
major comments (2)
- [Abstract] Abstract: The central performance claims (ECE drop 0.1269→0.0398, Brier 0.199→0.145) rest on labels resolved from later documentation in the same admission, yet the manuscript supplies no quantitative validation of label fidelity against structured MIMIC fields such as ICD codes, lab results, or discharge summaries; without this, it is unclear whether metric gains reflect improved forecasting or exploitation of documentation patterns and lag.
- [Abstract] Abstract and methods description: No information is given on train-test split construction, temporal ordering safeguards, or statistical significance testing of the reported improvements, leaving open the possibility of leakage or overfitting to admission-specific note styles rather than generalizable event prediction.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each major comment below and have prepared revisions to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (ECE drop 0.1269→0.0398, Brier 0.199→0.145) rest on labels resolved from later documentation in the same admission, yet the manuscript supplies no quantitative validation of label fidelity against structured MIMIC fields such as ICD codes, lab results, or discharge summaries; without this, it is unclear whether metric gains reflect improved forecasting or exploitation of documentation patterns and lag.
Authors: We agree that additional validation of the label resolution process would be valuable. In the revised manuscript, we include a new subsection detailing a quantitative comparison of resolved labels against available structured MIMIC-III fields (such as ICD codes for procedures and mortality) on a random subset of examples. This analysis shows strong agreement, indicating that the labels capture genuine clinical events rather than solely documentation patterns. revision: yes
-
Referee: [Abstract] Abstract and methods description: No information is given on train-test split construction, temporal ordering safeguards, or statistical significance testing of the reported improvements, leaving open the possibility of leakage or overfitting to admission-specific note styles rather than generalizable event prediction.
Authors: We regret the omission of these details. The train-test split was performed at the admission level (80/20) to prevent any cross-admission leakage, and context for each prediction example was restricted to notes prior to the target event time. We have expanded the methods section to fully describe the split construction and temporal safeguards. Additionally, we now report bootstrap confidence intervals and p-values for the observed improvements in ECE and Brier score to demonstrate statistical significance. revision: yes
Circularity Check
No circularity: standard supervised fine-tuning on externally resolved labels
full rationale
The paper constructs training examples by pairing past clinical notes with natural-language questions and labels resolved from later documentation in the same admission, then applies standard LoRA fine-tuning. Performance metrics (ECE, Brier score) are evaluated on held-out examples using the identical label-resolution process. No equations, ansatzes, uniqueness theorems, or self-citations are invoked to derive the central claim; the improvement is an empirical outcome of supervised learning rather than a definitional or fitted-input tautology. The label-resolution step is an external data-preparation choice, not a self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Later documentation in the same admission provides accurate and complete labels for future clinical events
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2601.06336 , year =
Turtel, Benjamin and Wilczewski, Paul and Franklin, Danny and Skotheim, Kris , title =. arXiv preprint arXiv:2601.06336 , year =
-
[2]
BEHRT: Transformer for Electronic Health Records , journal =
Li, Yikuan and Rao, Shishir and Solares, Jos. BEHRT: Transformer for Electronic Health Records , journal =. 2020 , url =
work page 2020
-
[3]
npj Digital Medicine , volume =
Rasmy, Laila and Xiang, Yang and Xie, Ziqian and Tao, Cui and Zhi, Degui , title =. npj Digital Medicine , volume =. 2021 , url =
work page 2021
- [4]
-
[5]
Qu, Zhan and F. GRAIL: Geometry-Aware Retrieval-Augmented Inference with LLMs over Hyperbolic Representations of Patient Trajectories , journal =. 2026 , url =
work page 2026
-
[6]
arXiv preprint arXiv:1904.05342 , year =
Huang, Kexin and Altosaar, Jaan and Ranganath, Rajesh , title =. arXiv preprint arXiv:1904.05342 , year =
-
[7]
arXiv preprint arXiv:2601.19189 , year =
Turtel, Benjamin and Wilczewski, Paul and Franklin, Danny and Skotheim, Kris , title =. arXiv preprint arXiv:2601.19189 , year =
-
[8]
arXiv preprint arXiv:2604.01298 , year =
Turtel, Benjamin and Wilczewski, Paul and Skotheim, Kris , title =. arXiv preprint arXiv:2604.01298 , year =
-
[9]
Johnson, Alistair E. W. and Pollard, Tom J. and Shen, Lu and Lehman, Li-wei and Feng, Mengling and Ghassemi, Mohammad and Moody, Benjamin and Szolovits, Peter and Celi, Leo Anthony and Mark, Roger G. , title =. Scientific Data , volume =. 2016 , url =
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.