Recognition: unknown
GraphIP-Bench: How Hard Is It to Steal a Graph Neural Network, and Can We Stop It?
Pith reviewed 2026-05-14 19:22 UTC · model grok-4.3
The pith
Stealing a graph neural network is straightforward at medium query budgets, and existing defenses rarely prevent extraction or preserve ownership signals on surrogates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that under a unified black-box protocol, model extraction attacks can produce surrogates with high fidelity to the target GNN at medium query budgets, and that defenses spanning watermarking, output perturbation, and query detection largely fail to increase extraction difficulty or maintain reliable ownership verification on the resulting surrogates, with heterophilic graphs being systematically harder to steal and cross-architecture extraction succeeding at reduced performance.
What carries the argument
GraphIP-Bench, the unified benchmark integrating twelve extraction attacks, twelve defenses, ten graphs, three backbones, and three tasks to evaluate fidelity, utility, verification, and cost under shared conditions.
If this is right
- Extraction is easy at medium query budgets across most configurations.
- Watermarks verify on protected models but lose most signal on extracted surrogates.
- Heterophilic graphs are harder to steal than homophilic ones.
- Cross-architecture mismatch reduces extraction success but does not prevent it.
- Joint attack-defense evaluation exposes gaps missed by single-model tests.
Where Pith is reading between the lines
- Service providers may require defenses designed to survive the extraction process itself rather than just marking the original model.
- The results point to heterophily as a potential natural barrier worth exploiting in future designs.
- Extending the benchmark to include adaptive attacks targeting specific defenses could reveal additional vulnerabilities.
- Real-world GNN services might benefit from monitoring query patterns more aggressively if detection proves more robust than watermarking.
Load-bearing premise
The chosen set of twelve attacks, twelve defenses, ten graphs, three backbones, and three tasks is representative of the broader space of GNN services and threats.
What would settle it
A defense that achieves high watermark verification accuracy on surrogates extracted from defended targets across the benchmark's diverse setups would contradict the finding that most defenses lose their verification signal after extraction.
Figures

















read the original abstract
Graph neural networks (GNNs) deployed as cloud services can be \emph{stolen} through \emph{model-extraction attacks}, which train a surrogate from query responses to reproduce the target's behaviour, and a growing line of ownership defenses tries to prevent or trace such theft. The title of this paper asks two questions: \emph{how hard is it to steal a GNN?}, and \emph{can we stop it?} Prior work cannot answer either, because experiments use inconsistent datasets, threat models, and metrics. We introduce \emph{GraphIP-Bench}, a unified benchmark which evaluates both sides under a single black-box protocol. It integrates twelve extraction attacks, twelve defenses spanning watermarking, output-perturbation, and query-pattern-detection families, ten public graphs covering homophilic, heterophilic, and large-scale regimes, three GNN backbones, and three graph-learning tasks, and it reports fidelity, task utility, ownership verification, and computational cost on shared splits, queries, and budgets. We further add a joint attack-and-defense track which runs every attack on every defended target and measures watermark verification on the resulting surrogate, which exposes the protection that a defense retains after extraction. The empirical picture is short: stealing a GNN is easy at medium query budgets and most defenses do not change this; several watermarks verify reliably on the protected model but lose most of their verification signal on the extracted surrogate, which exposes a gap that single-model evaluations miss; and heterophilic graphs are systematically harder to steal, while a cross-architecture mismatch between target and surrogate reduces but does not prevent extraction. Code: \href{https://github.com/LabRAI/GraphIP-Bench}{LabRAI/GraphIP-Bench}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GraphIP-Bench, a unified benchmark for evaluating model extraction attacks on GNNs and corresponding ownership defenses under a consistent black-box protocol. It integrates twelve extraction attacks, twelve defenses spanning watermarking, output-perturbation, and query-pattern-detection families, ten public graphs covering homophilic, heterophilic, and large-scale regimes, three GNN backbones, and three graph-learning tasks. The benchmark reports fidelity, task utility, ownership verification, and computational cost on shared splits and query budgets. A joint attack-and-defense track evaluates every attack against every defended target and measures watermark verification on the resulting surrogates. The main empirical findings are that stealing a GNN is easy at medium query budgets, most defenses do not substantially alter this, watermarks verify reliably on protected models but lose most verification signal on extracted surrogates, heterophilic graphs are systematically harder to steal, and cross-architecture mismatch reduces but does not prevent extraction.
Significance. If the selected components prove representative, the benchmark supplies a standardized, reproducible platform that resolves inconsistencies in prior GNN extraction studies and enables direct comparison of attacks and defenses. The joint attack-defense track is a particular strength, as it reveals protection gaps that single-model evaluations miss. Public code release supports reproducibility and future extensions. These elements could usefully guide development of more robust GNN IP mechanisms by quantifying current limitations in watermarking and perturbation approaches.
major comments (3)
- [§3] §3 (Benchmark Design): The selection of the twelve attacks, twelve defenses, ten graphs, three backbones, and three tasks lacks any coverage argument, sensitivity analysis, or comparison to omitted methods. Because the headline claims that stealing is easy at medium budgets and that most defenses fail rest entirely on results from this specific set, the absence of justification for representativeness directly weakens generalization to real-world GNN services.
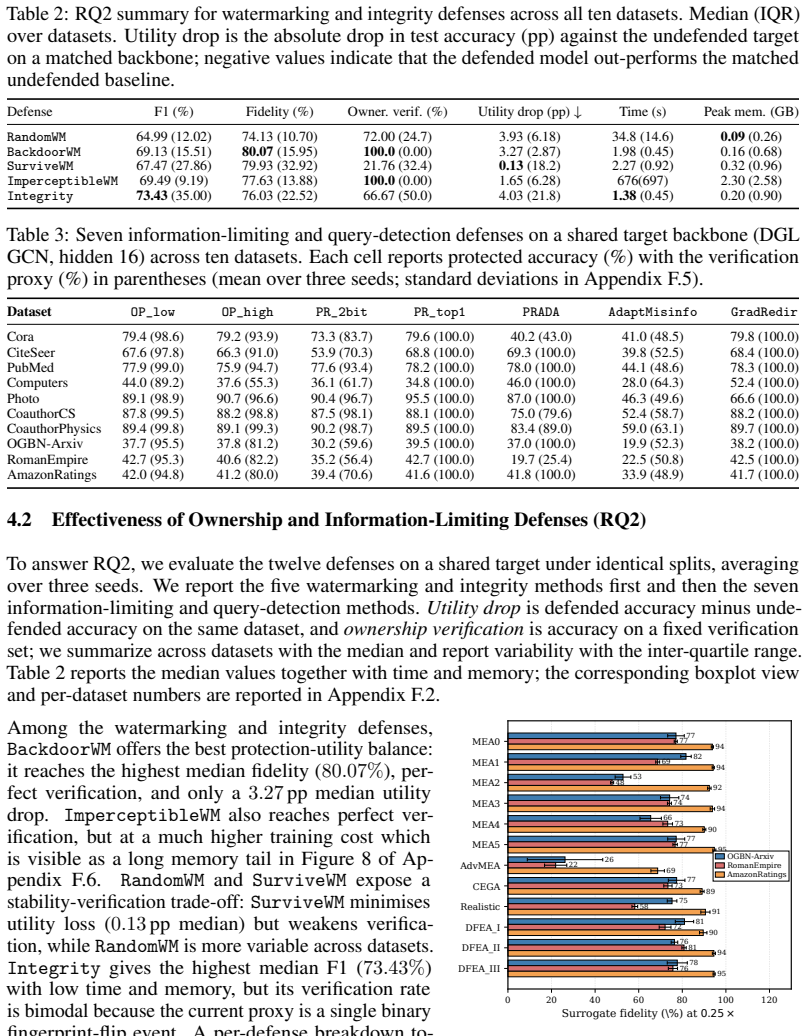
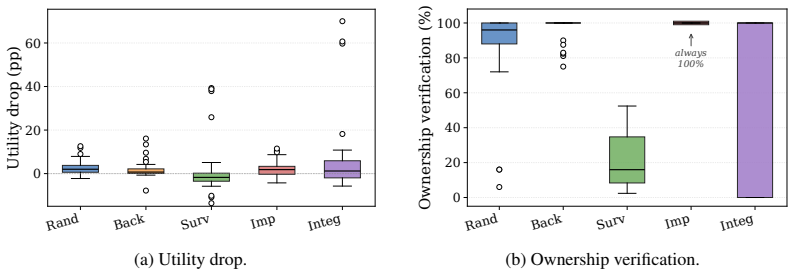
- [§5.3] §5.3 (Joint Attack-and-Defense Track): The observation that watermarks lose most verification signal on surrogates is central to the defense-effectiveness claim, yet the manuscript does not specify the exact verification threshold, how it is applied uniformly across methods, or whether results include multiple random seeds; without these details the reported gap could be sensitive to post-hoc choices.
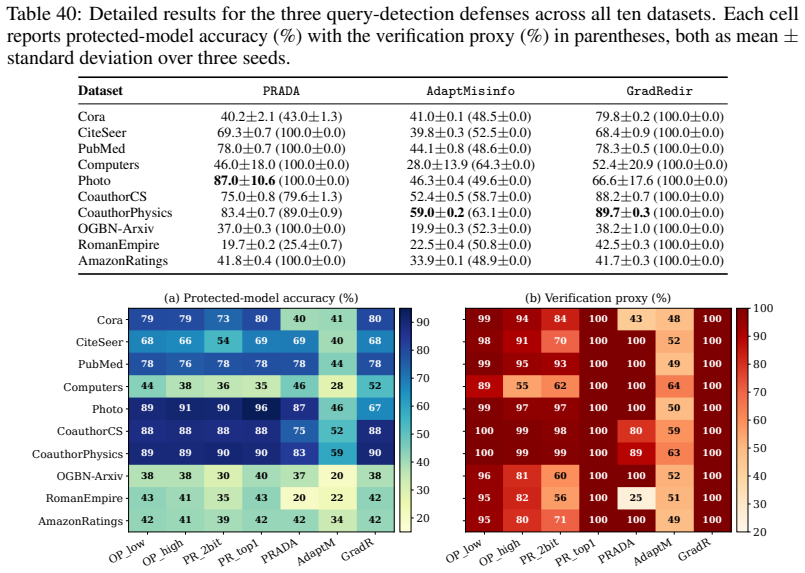
- [Table 2] Table 2 (Fidelity vs. Budget): The statement that heterophilic graphs are systematically harder to steal would be stronger if accompanied by statistical tests or variance across query selections, as single-run fidelity numbers may not establish the difference reliably.
minor comments (3)
- [Abstract] Abstract: The phrase 'several watermarks verify reliably' would be clearer if the specific watermarking methods were enumerated.
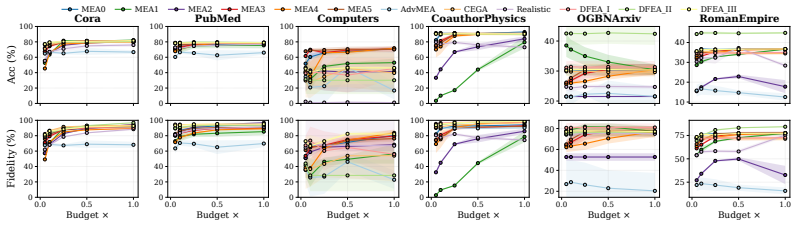
- [Figure 4] Figure 4: The x-axis scaling on query-budget plots makes it difficult to visually separate the medium-budget regime where the main claims are made; a log scale or inset would improve readability.
- [§2] §2 (Related Work): A few 2023-2024 GNN extraction papers are missing; adding them would better situate the benchmark.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the value of the unified benchmark and joint attack-defense track. We address each major point below and will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: The selection of the twelve attacks, twelve defenses, ten graphs, three backbones, and three tasks lacks any coverage argument, sensitivity analysis, or comparison to omitted methods. The headline claims rest on this specific set, weakening generalization.
Authors: We selected components to represent the primary families in the GNN extraction literature (query-efficient, gradient-based attacks; watermarking, perturbation, and detection defenses) while covering homophilic, heterophilic, and large-scale graphs. We will add a dedicated paragraph in §3 with references to prior surveys justifying representativeness and a limited sensitivity check on two omitted methods. Full enumeration of every variant is infeasible, but the chosen set enables direct comparison under a consistent protocol. revision: yes
-
Referee: The observation that watermarks lose verification signal on surrogates lacks the exact verification threshold, uniform application details, and multiple random seeds; results may be sensitive to post-hoc choices.
Authors: We agree these details are essential. In the revision we will state the precise threshold for each watermark (taken from the original papers), confirm uniform application, and report means and standard deviations over five random seeds in §5.3 and the experimental setup. This will demonstrate that the observed verification drop is robust rather than threshold-dependent. revision: yes
-
Referee: The claim that heterophilic graphs are systematically harder to steal would be stronger with statistical tests or variance across query selections, as single-run fidelity numbers may not establish the difference reliably.
Authors: We will augment Table 2 and §5 with fidelity variance across three independent query-selection seeds and add paired t-tests comparing homophilic versus heterophilic graphs at each budget. These additions will quantify the systematic gap with statistical support. revision: yes
Circularity Check
No circularity: empirical benchmark relies on external measurements
full rationale
The paper introduces GraphIP-Bench as a unified empirical evaluation of 12 attacks, 12 defenses, 10 public graphs, 3 backbones and 3 tasks under a fixed black-box protocol. All reported results (fidelity, utility, verification success, cost) are obtained by direct execution on standard public datasets and open-source GNN implementations; no equations, fitted parameters, or predictions are derived from the benchmark itself. Central claims rest on observed experimental outcomes rather than any self-referential reduction, self-citation chain, or ansatz smuggled from prior author work. The benchmark is therefore self-contained against external, reproducible inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Enyan Dai, Minhua Lin, and Suhang Wang. Pregip: Watermarking the pretraining of graph neural networks for deep intellectual property protection.arXiv preprint arXiv:2402.04435, 2024
-
[2]
Enyan Dai, Tianxiang Zhao, Huaisheng Zhu, Junjie Xu, Zhimeng Guo, Hui Liu, Jiliang Tang, and Suhang Wang. A comprehensive survey on trustworthy graph neural networks: Privacy, robustness, fairness, and explainability.Machine Intelligence Research, pages 1–51, 2024
work page 2024
-
[3]
Adversarial model extraction on graph neural networks.arXiv preprint arXiv:1912.07721, 2019
David DeFazio and Arti Ramesh. Adversarial model extraction on graph neural networks.arXiv preprint arXiv:1912.07721, 2019
-
[4]
Faqian Guan, Tianqing Zhu, Hanjin Tong, and Wanlei Zhou. A realistic model extraction attack against graph neural networks.Knowledge-Based Systems, page 112144, 2024
work page 2024
-
[5]
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
work page 2017
-
[6]
Hongsheng Hu, Shuo Wang, Tian Dong, and Minhui Xue. Learn what you want to unlearn: Unlearning inversion attacks against machine unlearning.arXiv preprint arXiv:2404.03233, 2024
-
[7]
Prada: protecting against dnn model stealing attacks
Mika Juuti, Sebastian Szyller, Samuel Marchal, and N Asokan. Prada: protecting against dnn model stealing attacks. In2019 IEEE European Symposium on Security and Privacy (EuroS&P), pages 512–527, 2019
work page 2019
-
[8]
Defending against model stealing attacks with adaptive misinformation
Sanjay Kariyappa and Moinuddin K Qureshi. Defending against model stealing attacks with adaptive misinformation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 770–778, 2020
work page 2020
-
[9]
Model extraction warning in mlaas paradigm
Manish Kesarwani, Bhaskar Mukhoty, Vijay Arya, and Sameep Mehta. Model extraction warning in mlaas paradigm. InProceedings of the 34th Annual Computer Security Applications Conference, pages 371–380, 2018
work page 2018
-
[10]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks.arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Intellectual property in graph-based machine learning as a service: Attacks and defenses
Lincan Li, Bolin Shen, Chenxi Zhao, Yuxiang Sun, Kaixiang Zhao, Shirui Pan, and Yushun Dong. Intellectual property in graph-based machine learning as a service: Attacks and defenses. arXiv preprint arXiv:2508.19641, 2025
-
[12]
Wenjun Li, Wanjun Ma, Mengyun Yang, and Xiwei Tang. Drug repurposing based on the dtd-gnn graph neural network: revealing the relationships among drugs, targets and diseases. BMC genomics, 25, 2024
work page 2024
-
[13]
Model extraction attacks revisited
Jiacheng Liang, Ren Pang, Changjiang Li, and Ting Wang. Model extraction attacks revisited. InProceedings of the 19th ACM Asia Conference on Computer and Communications Security, pages 1231–1245, 2024
work page 2024
-
[14]
Mantas Mazeika, Bo Li, and David Forsyth. How to steer your adversary: Targeted and efficient model stealing defenses with gradient redirection. InInternational conference on machine learning, pages 15241–15254. PMLR, 2022. 10
work page 2022
-
[15]
Dag-net: Double attentive graph neural network for trajectory forecasting
Alessio Monti, Alessia Bertugli, Simone Calderara, and Rita Cucchiara. Dag-net: Double attentive graph neural network for trajectory forecasting. In2020 25th international conference on pattern recognition (ICPR), pages 2551–2558. IEEE, 2021
work page 2021
-
[16]
Christopher Morris, Nils M Kriege, Franka Bause, Kristian Kersting, Petra Mutzel, and Marion Neumann. Tudataset: A collection of benchmark datasets for learning with graphs.arXiv preprint arXiv:2007.08663, 2020
-
[17]
Knockoff nets: Stealing functionality of black-box models
Tribhuvanesh Orekondy, Bernt Schiele, and Mario Fritz. Knockoff nets: Stealing functionality of black-box models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4954–4963, 2019
work page 2019
-
[18]
Intellectual property protection of dnn models.World Wide Web, 26(4):1877–1911, 2023
Sen Peng, Yufei Chen, Jie Xu, Zizhuo Chen, Cong Wang, and Xiaohua Jia. Intellectual property protection of dnn models.World Wide Web, 26(4):1877–1911, 2023
work page 1911
-
[19]
Oleg Platonov, Denis Kuznedelev, Michael Diskin, Artem Babenko, and Liudmila Prokhorenkova. A critical look at the evaluation of gnns under heterophily: Are we really making progress?arXiv preprint arXiv:2302.11640, 2023
-
[20]
A review of adversarial attacks and defenses on graphs
Hanjin Sun, Wen Yang, and Yatie Xiao. A review of adversarial attacks and defenses on graphs. InProceedings of the 4th International Conference on Artificial Intelligence and Computer Engineering, page 416–421, 2024
work page 2024
-
[21]
Lichao Sun, Yingtong Dou, Carl Yang, Kai Zhang, Ji Wang, Philip S. Yu, Lifang He, and Bo Li. Adversarial attack and defense on graph data: A survey.IEEE Transactions on Knowledge and Data Engineering, 35(8):7693–7711, 2023
work page 2023
-
[22]
Deep intellectual property protection: A survey.arXiv preprint arXiv:2304.14613, 2023
Yuchen Sun, Tianpeng Liu, Panhe Hu, Qing Liao, Shaojing Fu, Nenghai Yu, Deke Guo, Yongxiang Liu, and Li Liu. Deep intellectual property protection: A survey.arXiv preprint arXiv:2304.14613, 2023
-
[23]
Stealing machine learning models via prediction {APIs}
Florian Tramèr, Fan Zhang, Ari Juels, Michael K Reiter, and Thomas Ristenpart. Stealing machine learning models via prediction {APIs}. In25th USENIX security symposium (USENIX Security 16), pages 601–618, 2016
work page 2016
-
[24]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks.arXiv preprint arXiv:1710.10903, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Asim Waheed, Vasisht Duddu, and N. Asokan. Grove: Ownership verification of graph neural networks using embeddings. In2024 IEEE Symposium on Security and Privacy (SP), pages 2460–2477, 2024
work page 2024
-
[26]
Making watermark survive model extraction attacks in graph neural networks
Haiming Wang, Zhikun Zhang, Min Chen, and Shibo He. Making watermark survive model extraction attacks in graph neural networks. InICC 2023-IEEE International Conference on Communications, pages 57–62, 2023
work page 2023
-
[27]
Zebin Wang, Menghan Lin, Bolin Shen, Ken Anderson, Molei Liu, Tianxi Cai, and Yushun Dong. Cega: A cost-effective approach for graph-based model extraction and acquisition.arXiv preprint arXiv:2506.17709, 2025
-
[28]
Adapting membership inference attacks to gnn for graph classification: Approaches and implications
Bang Wu, Xiangwen Yang, Shirui Pan, and Xingliang Yuan. Adapting membership inference attacks to gnn for graph classification: Approaches and implications. In2021 IEEE International Conference on Data Mining (ICDM), pages 1421–1426, 2021
work page 2021
-
[29]
Model extraction attacks on graph neural networks: Taxonomy and realisation
Bang Wu, Xiangwen Yang, Shirui Pan, and Xingliang Yuan. Model extraction attacks on graph neural networks: Taxonomy and realisation. InProceedings of the 2022 ACM on Asia conference on computer and communications security, pages 337–350, 2022
work page 2022
-
[30]
Bang Wu, Xingliang Yuan, Shuo Wang, Qi Li, Minhui Xue, and Shirui Pan. Securing graph neural networks in mlaas: A comprehensive realization of query-based integrity verification. In 2024 IEEE Symposium on Security and Privacy (SP), pages 2534–2552. IEEE, 2024. 11
work page 2024
-
[31]
Trustworthy graph learning: Reliability, explainability, and privacy protection
Bingzhe Wu, Yatao Bian, Hengtong Zhang, Jintang Li, Junchi Yu, Liang Chen, Chaochao Chen, and Junzhou Huang. Trustworthy graph learning: Reliability, explainability, and privacy protection. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4838–4839, 2022
work page 2022
-
[32]
Watermarking graph neural networks based on backdoor attacks
Jing Xu, Stefanos Koffas, O ˘guzhan Ersoy, and Stjepan Picek. Watermarking graph neural networks based on backdoor attacks. In2023 IEEE 8th European Symposium on Security and Privacy (EuroS&P), pages 1179–1197, 2023
work page 2023
-
[33]
Mingfu Xue, Yushu Zhang, Jian Wang, and Weiqiang Liu. Intellectual property protection for deep learning models: Taxonomy, methods, attacks, and evaluations.IEEE Transactions on Artificial Intelligence, 3(6):908–923, 2021
work page 2021
-
[34]
Dgrec: Graph neural network for recommendation with diversified embedding generation
Liangwei Yang, Shengjie Wang, Yunzhe Tao, Jiankai Sun, Xiaolong Liu, Philip S Yu, and Taiqing Wang. Dgrec: Graph neural network for recommendation with diversified embedding generation. InProceedings of the sixteenth ACM international conference on web search and data mining, pages 661–669, 2023
work page 2023
-
[35]
Gnnfingers: A fingerprinting framework for verifying ownerships of graph neural networks
Xiaoyu You, Youhe Jiang, Jianwei Xu, Mi Zhang, and Min Yang. Gnnfingers: A fingerprinting framework for verifying ownerships of graph neural networks. InProceedings of the ACM on Web Conference 2024, pages 652–663, 2024
work page 2024
-
[36]
Trustworthy graph neural networks: Aspects, methods and trends.arXiv preprint arXiv:2205.07424, 2022
He Zhang, Bang Wu, Xingliang Yuan, Shirui Pan, Hanghang Tong, and Jian Pei. Trustworthy graph neural networks: Aspects, methods and trends.arXiv preprint arXiv:2205.07424, 2022
-
[37]
An imperceptible and owner-unique watermarking method for graph neural networks
Linji Zhang, Mingfu Xue, Leo Yu Zhang, Yushu Zhang, and Weiqiang Liu. An imperceptible and owner-unique watermarking method for graph neural networks. InProceedings of the ACM Turing Award Celebration Conference-China 2024, pages 108–113, 2024
work page 2024
-
[38]
Zaixi Zhang, Qi Liu, Zhenya Huang, Hao Wang, Chee-Kong Lee, and Enhong Chen. Model inversion attacks against graph neural networks.IEEE Transactions on Knowledge and Data Engineering, 2022
work page 2022
-
[39]
Kaixiang Zhao, Lincan Li, Kaize Ding, Neil Zhenqiang Gong, Yue Zhao, and Yushun Dong. A survey of model extraction attacks and defenses in distributed computing environments.arXiv preprint arXiv:2502.16065, 2025
-
[40]
Kaixiang Zhao, Lincan Li, Kaize Ding, Neil Zhenqiang Gong, Yue Zhao, and Yushun Dong. A survey on model extraction attacks and defenses for large language models.arXiv preprint arXiv:2506.22521, 2025
-
[41]
A systematic survey of model extraction attacks and defenses: State-of-the-art and perspectives
Kaixiang Zhao, Lincan Li, Kaize Ding, Neil Zhenqiang Gong, Yue Zhao, and Yushun Dong. A systematic survey of model extraction attacks and defenses: State-of-the-art and perspectives. arXiv preprint arXiv:2508.15031, 2025
-
[42]
Watermarking graph neural networks by random graphs
Xiangyu Zhao, Hanzhou Wu, and Xinpeng Zhang. Watermarking graph neural networks by random graphs. In2021 9th International Symposium on Digital Forensics and Security (ISDFS), pages 1–6, 2021
work page 2021
-
[43]
Graph robustness benchmark: Benchmarking the adversarial robustness of graph machine learning
Qinkai Zheng, Xu Zou, Yuxiao Dong, Yukuo Cen, Da Yin, Jiarong Xu, Yang Yang, and Jie Tang. Graph robustness benchmark: Benchmarking the adversarial robustness of graph machine learning. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2021
work page 2021
-
[44]
Yuanxin Zhuang, Chuan Shi, Mengmei Zhang, Jinghui Chen, Lingjuan Lyu, Pan Zhou, and Lichao Sun. Unveiling the secrets without data: Can graph neural networks be exploited through {Data-Free} model extraction attacks? In33rd USENIX Security Symposium (USENIX Security 24), pages 5251–5268, 2024. 12 Appendix Contents A Related Work 14 B Limitations and Futur...
work page 2024
-
[45]
the extraction can achieve up to ∼80% fidelity
with NVIDIA driver 570.195.03 and a CUDA 12.8 driver capability. Login nodes have no GPU access, so all timing and memory numbers are recorded from Slurm-allocated GPU jobs only. Software stack.The full pipeline runs in a dedicated Conda environment namedgraphip: Python 3.11.15, PyTorch 2.2.1 + cu121, DGL 2.1.0 + cu121, PyTorch Geometric 2.7.0, OGB 1.3.6,...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.