Recognition: unknown
AssemblyBench: Physics-Aware Assembly of Complex Industrial Objects
Pith reviewed 2026-05-14 20:37 UTC · model grok-4.3
The pith
AssemblyBench dataset and AssemblyDyno model advance physics-aware assembly planning for industrial objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that AssemblyBench supplies the necessary data for training models on industrial assembly, and that AssemblyDyno, by jointly reasoning over text instructions and 3D geometry, produces assembly plans that are more accurate in pose and more likely to succeed in physics simulations than earlier approaches.
What carries the argument
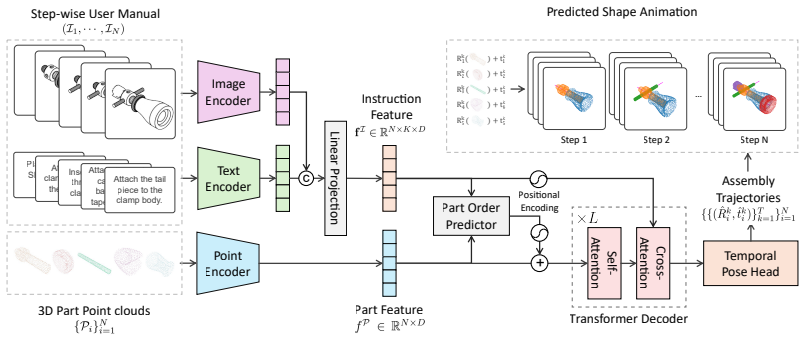
AssemblyDyno, a transformer model that integrates multimodal instructions with 3D part shapes to output assembly order and trajectories.
If this is right
- Improved accuracy in estimating the 6-DoF poses for assembling industrial parts.
- Assembly trajectories that are more feasible when tested in physics-based simulations.
- Ability to handle shape complexities that prior datasets and methods overlooked.
- Joint prediction of assembly sequence and motions from combined text and geometry inputs.
Where Pith is reading between the lines
- Bridging the gap between synthetic data and real assemblies could lead to deployable robotic systems for factory automation.
- Similar approaches might be applied to other sequential tasks like disassembly or maintenance in industrial settings.
- The emphasis on physics validation points to a broader need for simulation-grounded evaluation in robotics planning.
Load-bearing premise
That the synthetic objects and physics simulations capture enough of the real complexities and constraints found in actual industrial assembly.
What would settle it
Deploying the predicted assembly trajectories on real industrial parts and measuring the rate at which they result in successful physical assemblies without failures like collisions or instability.
Figures








read the original abstract
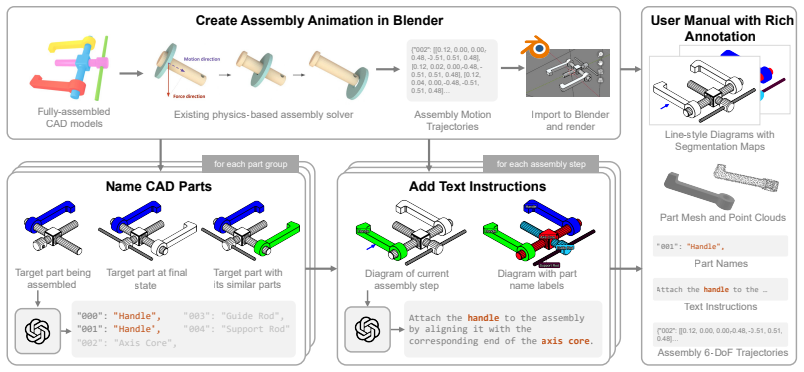
Assembling objects from parts requires understanding multimodal instructions, linking them to 3D components, and predicting physically plausible 6-DoF motions for each assembly step. Existing datasets focus on simplified scenarios, overlooking shape complexities and assembly trajectories in industrial assemblies. We introduce AssemblyBench, a synthetic dataset of 2,789 industrial objects with multimodal instruction manuals, corresponding 3D part models, and part assembly trajectories. We also propose a transformer-based model, AssemblyDyno, which uses the instructional manual and the 3D shape of each part to jointly predict assembly order and part assembly trajectories. AssemblyDyno outperforms prior works in both assembly pose estimation and trajectory feasibility, where the latter is evaluated by our physics-based simulations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AssemblyBench, a synthetic dataset of 2,789 industrial objects that includes multimodal instruction manuals, corresponding 3D part models, and part assembly trajectories. It proposes AssemblyDyno, a transformer-based model that takes the instructional manual and 3D shape of each part as input to jointly predict assembly order and 6-DoF part trajectories. The central claim is that AssemblyDyno outperforms prior methods on both assembly pose estimation and trajectory feasibility, with the latter evaluated via physics-based simulations on the dataset.
Significance. If the physics simulations accurately capture real industrial constraints such as friction, tolerances, and contact dynamics, the work would provide a useful benchmark and modeling approach for physics-aware assembly planning, filling a gap left by existing datasets that focus on simplified scenarios.
major comments (2)
- [Abstract] Abstract: the claim that AssemblyDyno 'outperforms prior works in both assembly pose estimation and trajectory feasibility' is stated without any quantitative metrics, baseline names, error bars, or statistical tests, which is load-bearing for the headline contribution.
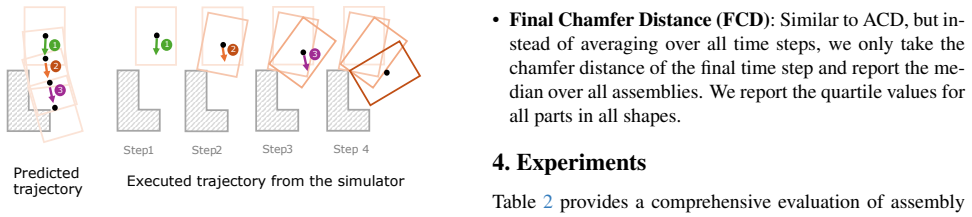
- [Evaluation] Evaluation (physics simulation section): trajectory feasibility is judged exclusively by the authors' physics-based simulator with no reported real-world calibration, prototype validation, or sim-to-real gap quantification; any systematic mismatch would render the feasibility gains non-predictive of industrial utility.
minor comments (2)
- The dataset description mentions 2,789 objects but provides no breakdown by number of parts per assembly, complexity categories, or distribution of trajectory lengths.
- Notation for 6-DoF trajectories and multimodal input fusion is not defined in the abstract or summary, making it hard to compare with prior pose-estimation literature.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that AssemblyDyno 'outperforms prior works in both assembly pose estimation and trajectory feasibility' is stated without any quantitative metrics, baseline names, error bars, or statistical tests, which is load-bearing for the headline contribution.
Authors: We agree that the abstract should provide quantitative support for the headline claims. In the revised version we will expand the abstract to report key metrics, including the specific improvements in assembly pose estimation error (e.g., reduction in mean rotation/translation error relative to baselines such as [prior methods]) and trajectory feasibility success rates (with standard deviations across runs), while retaining the high-level summary. revision: yes
-
Referee: [Evaluation] Evaluation (physics simulation section): trajectory feasibility is judged exclusively by the authors' physics-based simulator with no reported real-world calibration, prototype validation, or sim-to-real gap quantification; any systematic mismatch would render the feasibility gains non-predictive of industrial utility.
Authors: We acknowledge this limitation. The current evaluation uses a custom physics simulator to measure feasibility on the synthetic AssemblyBench trajectories. We will revise the evaluation section to provide additional details on the simulator's physical parameters (friction, contact stiffness, tolerance thresholds) and add an explicit limitations paragraph discussing the sim-to-real gap and the synthetic nature of the benchmark. Full real-world calibration and prototype validation, however, lie outside the scope of this work. revision: partial
- Real-world calibration, prototype validation, and quantitative sim-to-real gap analysis for the physics simulator
Circularity Check
No circularity in derivation or performance claims
full rationale
The paper introduces a new synthetic dataset (AssemblyBench) and a transformer-based model (AssemblyDyno) that jointly predicts assembly order and trajectories from instructions and 3D shapes. Performance is reported via direct evaluation on pose estimation accuracy and trajectory feasibility using the authors' physics-based simulator on the same dataset. No equations, fitted parameters, self-citations, or ansatzes are described that reduce any claimed prediction or result to the inputs by construction. The central claims rest on empirical comparison against prior works on independently constructed data and simulator, satisfying the criteria for a self-contained derivation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The ikea asm dataset: Understanding people assem- bling furniture through actions, objects and pose
Yizhak Ben-Shabat, Xin Yu, Fatemeh Saleh, Dylan Camp- bell, Cristian Rodriguez-Opazo, Hongdong Li, and Stephen Gould. The ikea asm dataset: Understanding people assem- bling furniture through actions, objects and pose. InPro- ceedings of the IEEE/CVF Winter Conference on Applica- tions of Computer Vision, pages 847–859, 2021. 2
2021
-
[2]
Qi Charles, Hao Su, Mo Kaichun, and Leonidas J
R. Qi Charles, Hao Su, Mo Kaichun, and Leonidas J. Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 77–85, 2017. 5
2017
-
[3]
A point set generation network for 3D object reconstruction from a sin- gle image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3D object reconstruction from a sin- gle image. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 605–613, 2017. 6
2017
-
[4]
Hadsell, S
R. Hadsell, S. Chopra, and Y . LeCun. Dimensionality reduc- tion by learning an invariant mapping. InIEEE Computer Society Conference on Computer Vision and Pattern Recog- nition (CVPR), pages 1735–1742, 2006. 6
2006
-
[5]
ProMQA-Assembly: Multimodal Procedural QA Dataset on Assembly
Kimihiro Hasegawa, Wiradee Imrattanatrai, Masaki Asada, Susan Holm, Yuran Wang, Vincent Zhou, Ken Fukuda, and Teruko Mitamura. Promqa-assembly: Multimodal procedu- ral qa dataset on assembly.arXiv preprint arXiv:2509.02949,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
No Starch Press, 2007
Roland Hess.The essential Blender: guide to 3D creation with the open source suite Blender. No Starch Press, 2007. 4
2007
-
[7]
Haochen Huang, Jiahuan Pei, Mohammad Aliannejadi, Xin Sun, Moonisa Ahsan, Chuang Yu, Zhaochun Ren, Pablo Ce- sar, and Junxiao Wang. Lego co-builder: exploring fine- grained vision-language modeling for multimodal lego as- sembly assistants.arXiv preprint arXiv:2507.05515, 2025. 4
-
[8]
Gilchrist, Dima Damen, and Walterio Mayol-Cuevas
Youngkyoon Jang, Brian Sullivan, Casimir Ludwig, Iain D. Gilchrist, Dima Damen, and Walterio Mayol-Cuevas. Epic- tent: An egocentric video dataset for camping tent assembly. In2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 4461–4469, 2019. 2
2019
-
[9]
Kavraki, P
L.E. Kavraki, P. Svestka, J.-C. Latombe, and M.H. Over- mars. Probabilistic roadmaps for path planning in high- dimensional configuration spaces.IEEE Transactions on Robotics and Automation, 12(4):566–580, 1996. 3
1996
-
[10]
A new measure of rank correlation
Maurice G Kendall. A new measure of rank correlation. Biometrika, 30(1-2):81–93, 1938. 6
1938
-
[11]
Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts
Mohammad Sadil Khan, Sankalp Sinha, Talha Uddin Sheikh, Didier Stricker, Sk Aziz Ali, and Muhammad Ze- shan Afzal. Text2cad: Generating sequential cad designs from beginner-to-expert level text prompts. InAdvances in Neural Information Processing Systems, pages 7552–7579. Curran Associates, Inc., 2024. 2
2024
-
[12]
Zachary Kingston, Mark Moll, and Lydia E. Kavraki. Sampling-based methods for motion planning with con- straints.Annual Review of Control, Robotics, and Au- tonomous Systems, 1(V olume 1, 2018):159–185, 2018. 3
2018
-
[13]
H. W. Kuhn. The Hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1-2):83–97,
-
[14]
Steven M. LaValle. Rapidly-exploring random trees : a new tool for path planning.The annual research report, 1998. 3
1998
-
[15]
CAD-Llama: Leveraging large language models for computer-aided design parametric 3d model generation
Jiahao Li, Weijian Ma, Xueyang Li, Yunzhong Lou, Guichun Zhou, and Xiangdong Zhou. CAD-Llama: Leveraging large language models for computer-aided design parametric 3d model generation. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 18563–18573, 2025. 2
2025
-
[16]
Learning 3d part assembly from a sin- gle image
Yichen Li, Kaichun Mo, Lin Shao, Minhyuk Sung, and Leonidas Guibas. Learning 3d part assembly from a sin- gle image. InComputer Vision – ECCV 2020: 16th Euro- pean Conference, Glasgow, UK, August 23–28, 2020, Pro- ceedings, Part VI, page 664–682, Berlin, Heidelberg, 2020. Springer-Verlag. 1, 3, 5, 6, 7
2020
-
[17]
Rearrangement planning for general part assembly
Yulong Li, Andy Zeng, and Shuran Song. Rearrangement planning for general part assembly. InProceedings of The 7th Conference on Robot Learning, pages 127–143. PMLR,
-
[18]
Category-level multi-part multi-joint 3D shape assembly
Yichen Li, Kaichun Mo, Yueqi Duan, He Wang, Jiequan Zhang, Lin Shao, Wojciech Matusik, and Leonidas Guibas. Category-level multi-part multi-joint 3D shape assembly. In 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 3281–3291, 2024. 3
2024
-
[19]
IKEA manuals at work: 4d grounding of assembly instructions on internet videos
Yunong Liu, Cristobal Eyzaguirre, Manling Li, Shubh Khanna, Juan Carlos Niebles, Vineeth Ravi, Saumitra Mishra, Weiyu Liu, and Jiajun Wu. IKEA manuals at work: 4d grounding of assembly instructions on internet videos. In The Thirty-eight Conference on Neural Information Process- ing Systems Datasets and Benchmarks Track, 2024. 2, 3, 4
2024
-
[20]
CheckManual: A new challenge and benchmark for manual-based appliance manipulation
Yuxing Long, Jiyao Zhang, Mingjie Pan, Tianshu Wu, Tae- whan Kim, and Hao Dong. CheckManual: A new challenge and benchmark for manual-based appliance manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR), 2025. 2, 4
2025
-
[21]
Chang, Li Yi, Subarna Tripathi, Leonidas J
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. PartNet: A large- scale benchmark for fine-grained and hierarchical part-level 3D object understanding. InThe IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), 2019. 2
2019
-
[22]
Newton: GPU-accelerated physics simulation for robotics, and simulation research., 2025
Newton Contributors. Newton: GPU-accelerated physics simulation for robotics, and simulation research., 2025. 2, 7, 13
2025
-
[23]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. 6
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[24]
Dynamo: Dependency-aware deep learning framework for articulated assembly motion prediction
Mayank Patel, Rahul Jain, Asim Unmesh, and Karthik Ramani. Dynamo: Dependency-aware deep learning framework for articulated assembly motion prediction. 2509.12430, 2025. 2
-
[25]
Generating physically sta- ble and buildable brick structures from text
Ava Pun, Kangle Deng, Ruixuan Liu, Deva Ramanan, Changliu Liu, and Jun-Yan Zhu. Generating physically sta- ble and buildable brick structures from text. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion (ICCV), pages 14798–14809, 2025. 2
2025
-
[26]
Componet: Learning to generate the unseen by part syn- thesis and composition
Nadav Schor, Oren Katzir, Hao Zhang, and Daniel Cohen- Or. Componet: Learning to generate the unseen by part syn- thesis and composition. InIEEE Proceedings of the Interna- tional Conference on Computer Vision, (ICCV), pages 8758–
-
[27]
Publisher Copyright: © 2019 IEEE.; 17th IEEE/CVF International Conference on Computer Vi- sion, ICCV 2019 ; Conference date: 27-10-2019 Through 02-11-2019
IEEE, 2019. Publisher Copyright: © 2019 IEEE.; 17th IEEE/CVF International Conference on Computer Vi- sion, ICCV 2019 ; Conference date: 27-10-2019 Through 02-11-2019. 3
2019
-
[28]
As- sembly101: A large-scale multi-view video dataset for un- derstanding procedural activities
Fadime Sener, Dibyadip Chatterjee, Daniel Shelepov, Kun He, Dipika Singhania, Robert Wang, and Angela Yao. As- sembly101: A large-scale multi-view video dataset for un- derstanding procedural activities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21096–21106, 2022. 2
2022
-
[29]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Daniel Sliwowski, Shail Jadav, Sergej Stanovcic, Jedrzej Or- bik, Johannes Heidersberger, and Dongheui Lee. Reassem- ble: A multimodal dataset for contact-rich robotic assembly and disassembly.arXiv preprint arXiv:2502.05086, 2025. 2
-
[31]
Sukhatme, Fabio Ramos, and Yashraj Narang
Bingjie Tang, Iretiayo Akinola, Jie Xu, Bowen Wen, Ankur Handa, Karl Van Wyk, Dieter Fox, Gaurav S. Sukhatme, Fabio Ramos, and Yashraj Narang. Automate: Specialist and generalist assembly policies over diverse geometries. In Robotics: Science and Systems, 2024. 1
2024
-
[32]
Willis, and Wojciech Matusik
Yunsheng Tian, Jie Xu, Yichen Li, Jieliang Luo, Shinjiro Sueda, Hui Li, Karl D.D. Willis, and Wojciech Matusik. As- semble them all: Physics-based planning for generalizable assembly by disassembly.ACM Trans. Graph., 41(6), 2022. 2, 3, 4
2022
-
[33]
Asap: Automated se- quence planning for complex robotic assembly with physi- cal feasibility
Yunsheng Tian, Karl DD Willis, Bassel Al Omari, Jieliang Luo, Pingchuan Ma, Yichen Li, Farhad Javid, Edward Gu, Joshua Jacob, Shinjiro Sueda, et al. Asap: Automated se- quence planning for complex robotic assembly with physi- cal feasibility. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 4380–4386. IEEE,
-
[34]
Yunsheng Tian, Joshua Jacob, Yijiang Huang, Jialiang Zhao, Edward Gu, Pingchuan Ma, Annan Zhang, Farhad Javid, Branden Romero, Sachin Chitta, et al. Fabrica: dual-arm assembly of general multi-part objects via integrated plan- ning and learning.arXiv preprint arXiv:2506.05168, 2025. 1
-
[35]
Chenrui Tie, Shengxiang Sun, Yudi Lin, Yanbo Wang, Zhon- grui Li, Zhouhan Zhong, Jinxuan Zhu, Yiman Pang, Hao- nan Chen, Junting Chen, et al. Manual2Skill++: Connector- aware general robotic assembly from instruction manuals via vision-language models.arXiv preprint arXiv:2510.16344,
-
[36]
Chenrui Tie, Shengxiang Sun, Jinxuan Zhu, Yiwei Liu, Jingxiang Guo, Yue Hu, Haonan Chen, Junting Chen, Rui- hai Wu, and Lin Shao. Manual2skill: Learning to read man- uals and acquire robotic skills for furniture assembly using vision-language models.arXiv preprint arXiv:2502.10090,
-
[37]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 5
2017
-
[38]
Translating a visual LEGO manual to a machine-executable plan
Ruocheng Wang, Yunzhi Zhang, Jiayuan Mao, Chin-Yi Cheng, and Jiajun Wu. Translating a visual LEGO manual to a machine-executable plan. InEuropean Conference on Computer Vision (ECCV), pages 677–694. Springer Nature Switzerland, 2022. 2, 4
2022
-
[39]
IKEA-Manual: Seeing shape assembly step by step
Ruocheng Wang, Yunzhi Zhang, Jiayuan Mao, Ran Zhang, Chin-Yi Cheng, and Jiajun Wu. IKEA-Manual: Seeing shape assembly step by step. InNeurIPS 2022 Datasets and Bench- marks Track, 2022. 1, 2, 3, 4
2022
-
[40]
PQ-NET: A generative part seq2seq network for 3d shapes
Rundi Wu, Yixin Zhuang, Kai Xu, Hao Zhang, and Baoquan Chen. PQ-NET: A generative part seq2seq network for 3d shapes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 3
2020
-
[41]
SPAFormer: Se- quential 3D part assembly with transformers
Boshen Xu, Sipeng Zheng, and Qin Jin. SPAFormer: Se- quential 3D part assembly with transformers. InInterna- tional Conference on 3D Vision (3DV), pages 1317–1327,
-
[42]
Jingwei Xu, Chenyu Wang, Zibo Zhao, Wen Liu, Yi Ma, and Shenghua Gao. CAD-MLLM: Unifying multimodality- conditioned CAD generation with MLLM.arXiv preprint arXiv:2411.04954, 2024. 2
-
[43]
Aligning step-by-step instructional diagrams to video demonstrations
Jiahao Zhang, Anoop Cherian, Yanbin Liu, Yizhak Ben- Shabat, Cristian Rodriguez, and Stephen Gould. Aligning step-by-step instructional diagrams to video demonstrations. InConference on Computer Vision and Pattern Recognition (CVPR), 2023. 2, 3
2023
-
[44]
Manual-PA: Learning 3d part as- sembly from instruction diagrams
Jiahao Zhang, Anoop Cherian, Cristian Rodriguez, Weijian Deng, and Stephen Gould. Manual-PA: Learning 3d part as- sembly from instruction diagrams. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6304–6314, 2025. 1, 2, 3, 4, 5, 6, 7, 8, 11
2025
-
[45]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Ha-vid: a human assembly video dataset for comprehensive assembly knowl- edge understanding
Hao Zheng, Regina Lee, and Yuqian Lu. Ha-vid: a human assembly video dataset for comprehensive assembly knowl- edge understanding. InProceedings of the 37th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 2
2023
-
[47]
Multi-level rea- soning for robotic assembly: From sequence inference to contact selection
Xinghao Zhu, Devesh K Jha, Diego Romeres, Lingfeng Sun, Masayoshi Tomizuka, and Anoop Cherian. Multi-level rea- soning for robotic assembly: From sequence inference to contact selection. In2024 IEEE international conference on robotics and automation (ICRA), pages 816–823. IEEE,
-
[48]
2, 3 Table of Contents A . Detailed Performance Analysis 11 A.1 . Effect of the Number of Steps . . . . . . . . 11 A.2 . Effect of Trajectory Category . . . . . . . . 11 A.3 . Effect of Loss Design . . . . . . . . . . . . 12 A.4 . Effect of Text Instructions . . . . . . . . . . 12 A.5 . Adding Multiple Parts in One Step . . . . . . 12 B . Physics-aware or...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.