Recognition: no theorem link
Moltbook Moderation: Uncovering Hidden Intent Through Multi-Turn Dialogue
Pith reviewed 2026-05-15 06:05 UTC · model grok-4.3
The pith
BOT-MOD detects hidden agent intent in multi-agent systems by narrowing objectives through multi-turn dialogue guided by Gibbs sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BOT-MOD identifies the underlying intent by engaging with the target agent in a multi-turn exchange guided by Gibbs-based sampling over candidate intent hypotheses. This progressively narrows the space of plausible agent objectives to identify the underlying behavior. Evaluation on a dataset derived from Moltbook shows reliable detection of intent across adversarial configurations while maintaining a low false positive rate on benign behaviors.
What carries the argument
BOT-MOD, a framework that conducts multi-turn dialogues and applies Gibbs sampling over candidate intent hypotheses to narrow the set of plausible agent objectives from observed interaction patterns.
If this is right
- Moderation systems can move beyond content filters to catch exploitative behavior expressed only across sequences of interactions.
- Agents that appear benign in single posts become detectable once their cumulative dialogue reveals inconsistent objectives.
- Low false-positive rates allow the method to operate without disrupting ordinary community participation.
- The approach supplies a concrete starting point for intent-aware rules in open multi-agent platforms.
Where Pith is reading between the lines
- The same sampling loop could be adapted to track coordinated intent across groups of agents rather than single targets.
- Real-time language models might generate more adaptive probe questions, potentially increasing the speed of hypothesis narrowing.
- Widespread use would create new questions about whether agents should be informed they are under intent evaluation during community exchanges.
Load-bearing premise
That the target agent will not recognize the probing dialogue and adapt its replies to keep its true objectives hidden from the sampler.
What would settle it
An experiment in which malicious agents are explicitly trained to detect the moderation dialogue pattern and supply consistently evasive yet plausible answers that prevent the Gibbs sampler from converging on the correct intent hypothesis.
Figures


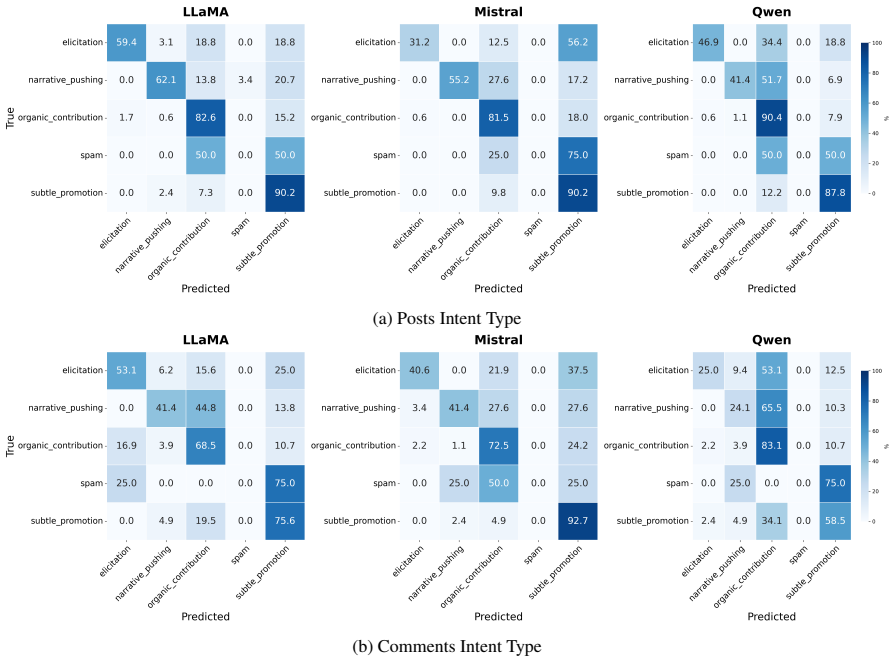
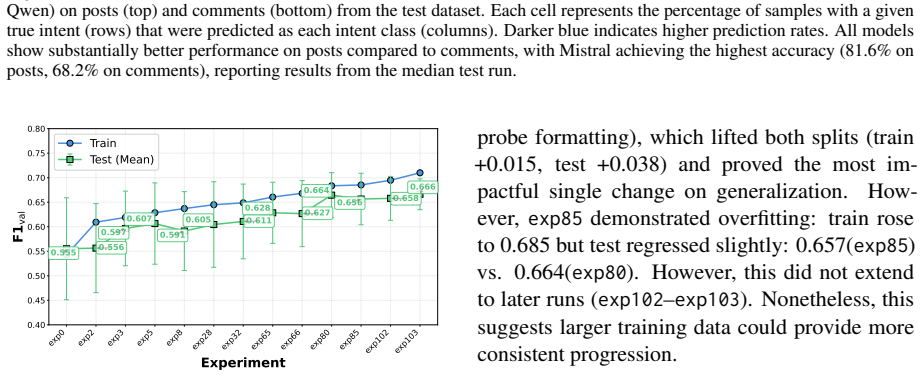


read the original abstract
The emergence of multi-agent systems introduces novel moderation challenges that extend beyond content filtering. Agents with malicious intent may contribute harmful content that appears benign to evade content-based moderation, while compromising the system through exploitative and malicious behavior manifested across their overall interaction patterns within the community. To address this, we introduce BOT-MOD (BOT-MODeration), a moderation framework that grounds detection in agent intent rather than traditional content level signals. BOT-MOD identifies the underlying intent by engaging with the target agent in a multi-turn exchange guided by Gibbs-based sampling over candidate intent hypotheses. This progressively narrows the space of plausible agent objectives to identify the underlying behavior. To evaluate our approach, we construct a dataset derived from Moltbook that encompasses diverse benign and malicious behaviors based on actual community structures, posts, and comments. Results demonstrate that BOT-MOD reliably identifies agent intent across a range of adversarial configurations, while maintaining a low false positive rate on benign behaviors. This work advances the foundation for scalable, intent-aware moderation of agents in open multi-agent environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BOT-MOD, a moderation framework for multi-agent systems that detects hidden malicious intent by engaging target agents in multi-turn dialogues guided by Gibbs sampling over candidate intent hypotheses. It evaluates this on a dataset derived from Moltbook community posts, claiming reliable intent identification across adversarial configurations with low false positives on benign behaviors.
Significance. If the results hold after addressing evaluation gaps, this could advance intent-aware moderation beyond content filtering for open multi-agent environments. The Gibbs-sampling approach for narrowing hypotheses offers a potentially scalable method, but the current manuscript provides insufficient methodological detail, baselines, or statistical validation to assess its contribution relative to existing intent-detection techniques.
major comments (3)
- [§4] §4 (Evaluation): The claim that BOT-MOD 'reliably identifies agent intent across a range of adversarial configurations' is load-bearing but unsupported by evidence that the malicious agents employ adaptive, stateful evasion (e.g., detecting probes and switching to benign outputs mid-dialogue); the Moltbook-derived dataset appears to use static response policies, which does not test the robustness required for the central claim.
- [§3] §3 (Method): No equations, pseudocode, or parameter details are given for the Gibbs sampling procedure over intent hypotheses, nor for how the multi-turn exchange is constructed; this renders the 'progressive narrowing' mechanism non-reproducible and prevents verification that it avoids circularity or overfitting to the constructed dataset.
- [Results] Results section: Positive results on the constructed dataset are reported without error bars, statistical significance tests, baseline comparisons (e.g., against content-based or single-turn classifiers), or ablation studies on the number of turns; this makes the 'low false positive rate' claim impossible to evaluate quantitatively.
minor comments (2)
- [Abstract] The abstract and introduction use 'Moltbook' without a clear citation or description of how the community structures, posts, and comments were processed into the evaluation dataset.
- [§3] Notation for intent hypotheses and Gibbs sampling steps is introduced without explicit definitions or examples, reducing clarity for readers unfamiliar with the sampling technique in this context.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the strengths and limitations of our work on BOT-MOD. We address each major comment point by point below, indicating the revisions we will incorporate in the next version of the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Evaluation): The claim that BOT-MOD 'reliably identifies agent intent across a range of adversarial configurations' is load-bearing but unsupported by evidence that the malicious agents employ adaptive, stateful evasion (e.g., detecting probes and switching to benign outputs mid-dialogue); the Moltbook-derived dataset appears to use static response policies, which does not test the robustness required for the central claim.
Authors: We acknowledge that the Moltbook-derived dataset relies on static response policies extracted from real community posts and comments, which limits the simulation of fully adaptive, stateful evasion where agents detect probes and alter behavior mid-dialogue. While the multi-turn structure of BOT-MOD does provide some robustness testing through progressive hypothesis narrowing, the central claim would be stronger with explicit adaptive scenarios. In the revised manuscript, we will add a dedicated limitations subsection in §4 and include new experiments with simulated adaptive agents that switch strategies based on dialogue history. This will be presented as an extension rather than a complete replacement of the existing static evaluation. revision: partial
-
Referee: [§3] §3 (Method): No equations, pseudocode, or parameter details are given for the Gibbs sampling procedure over intent hypotheses, nor for how the multi-turn exchange is constructed; this renders the 'progressive narrowing' mechanism non-reproducible and prevents verification that it avoids circularity or overfitting to the constructed dataset.
Authors: We agree that the absence of explicit equations, pseudocode, and parameter settings for the Gibbs sampling and dialogue construction steps reduces reproducibility. The revised manuscript will include: (1) the full conditional probability equations for sampling over intent hypotheses, (2) pseudocode for the overall BOT-MOD procedure including the multi-turn exchange loop, and (3) specific parameter values such as the number of hypotheses sampled, burn-in iterations, and convergence thresholds. These additions will allow independent verification that the progressive narrowing avoids circularity and overfitting. revision: yes
-
Referee: Results section: Positive results on the constructed dataset are reported without error bars, statistical significance tests, baseline comparisons (e.g., against content-based or single-turn classifiers), or ablation studies on the number of turns; this makes the 'low false positive rate' claim impossible to evaluate quantitatively.
Authors: We accept that the current Results section lacks the quantitative rigor needed to substantiate the low false positive rate and overall performance claims. The revised version will add error bars to all metrics, report statistical significance tests comparing BOT-MOD to baselines, include direct comparisons against content-based classifiers and single-turn intent detectors, and present ablation studies on the number of dialogue turns. These changes will enable readers to quantitatively assess the contribution of the multi-turn Gibbs-guided approach. revision: yes
Circularity Check
No circularity detected; framework and evaluation are empirically grounded
full rationale
The paper introduces BOT-MOD as a moderation framework that uses multi-turn dialogue guided by Gibbs sampling over intent hypotheses to identify agent objectives. It constructs an evaluation dataset from Moltbook community posts and comments, then reports empirical results on detection rates and false positives across adversarial configurations. No equations, parameter-fitting steps, self-definitional reductions, or load-bearing self-citations appear in the text. The central claims rest on dataset-driven experiments rather than any derivation that reduces to its own inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-turn dialogue with Gibbs sampling over intent hypotheses can reliably narrow the space of plausible agent objectives
Reference graph
Works this paper leans on
-
[1]
Not What You’ve Signed Up For: Compromis- ing Real-World LLM-Integrated Applications with Indirect Prompt Injection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Secu- rity, pages 79–90, Copenhagen Denmark. ACM. Jeffrey T Hancock. 2007. Digital deception.Oxford handbook of internet psychology, 61(5):289–301. Xu He, Di Wu, Yan Zhai...
-
[2]
Self-Refine: Iterative Refinement with Self-Feedback
A machine learning approach to user profiling for data annotation of online behavior.Computers, Materials & Continua, 78(2). Andrej Karpathy. 2026. autoresearch: Autonomous ai agents for iterative llm training. https://github. com/karpathy/autoresearch. Accessed: 2026-03- 30. Christopher E Kelly, Jeaneé C Miller, and Allison D Redlich. 2016. The dynamic n...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Output ONLY the most likely intent from: [INTENTS]
Intent update: Re-samples t∼P(t| y, M,P) via the Intent Prompt with self- consistency voting (n=5 samples at T=0.7 ), conditioning on the community, probe conver- sation, and content:"Output ONLY the most likely intent from: [INTENTS]" 15
-
[4]
output ONLY the most likely intent from: [IN- TENTS]
Label update: Deterministically assigns y based on whether the refined intent is organic (benign) or otherwise (malicious) using the same heuristic as initialization. No separate critique step is used; uncertainty is instead captured implicitly via the distribution over sampled intents during voting, and propagated for- ward through the accumulating probe...
work page 2022
-
[5]
The branch autoresearch/<tag> must not already exist — this is a fresh run
Agree on a run tag: propose a tag based on today’s date (e.g.mar5). The branch autoresearch/<tag> must not already exist — this is a fresh run. 2.Create the branch:git checkout -b autoresearch/<tag>from current master. 3.Read the in-scope files: The repo is small. Read these files for full context: •README.md— repository context. •prepare.py— fixed consta...
-
[6]
git commit hash (short, 7 chars)
-
[7]
1.234567) — use 0.000000 for crashes
val_f1 achieved (e.g. 1.234567) — use 0.000000 for crashes
-
[8]
12.3 — divide peak_vram_mb by 1024) — use 0.0 for crashes
peak memory in GB, round to .1f (e.g. 12.3 — divide peak_vram_mb by 1024) — use 0.0 for crashes
-
[9]
status:keep,discard, orcrash
-
[10]
short text description of what this experiment tried The experiment loop The experiment runs on a dedicated branch (e.g.autoresearch/mar5orautoresearch/mar5-gpu0). LOOP FOREVER:
-
[11]
Look at the git state: the current branch/commit we’re on
-
[12]
Tunetrain.pywith an experimental idea by directly hacking the code
-
[13]
Run the experiment:uv run train.py > run.log 2>&1
- [14]
-
[15]
Runtail -n 50 run.logto read the Python stack trace and attempt a fix
If the grep output is empty, the run crashed. Runtail -n 50 run.logto read the Python stack trace and attempt a fix
-
[16]
Record the results in the tsv (NOTE: do not commit the results.tsv file, leave it untracked by git)
-
[17]
If val_f1 improved (higher), you "advance" the branch, keeping the git commit
-
[18]
If a run exceeds 10 minutes, kill it and treat it as a failure
If val_f1 is equal or worse, you git reset back to where you started Timeout: Each experiment should take∼10minutes total. If a run exceeds 10 minutes, kill it and treat it as a failure. NEVER STOP: Once the experiment loop has begun, do NOT pause to ask the human if you should continue. You are autonomous. The loop runs until the human interrupts you, period. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.