Recognition: unknown
Adam-SHANG: A Convergent Adam-Type Method for Stochastic Smooth Convex Optimization
Pith reviewed 2026-05-14 18:40 UTC · model grok-4.3
The pith
Adam-SHANG converges in expectation for stochastic smooth convex optimization under a flexible stepsize condition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adam-SHANG couples momentum, adaptive preconditioning, and a curvature-aware correction through a more stable lagged-preconditioner update. For stochastic smooth convex optimization, the method converges in expectation under an admissible stepsize condition satisfiable by a conservative spectral bound, without requiring global monotonicity on the second-moment sequence. A trace-ratio stepsize rule motivated by local coordinatewise alignment offers a less conservative practical choice.
What carries the argument
The lagged-preconditioner update that stabilizes the curvature estimate while coupling momentum and adaptive steps.
If this is right
- Expected convergence holds whenever the conservative spectral bound is respected.
- The trace-ratio stepsize yields a practical rule under local coordinatewise alignment.
- The same lagged update structure applies beyond convex problems with simplified parameters.
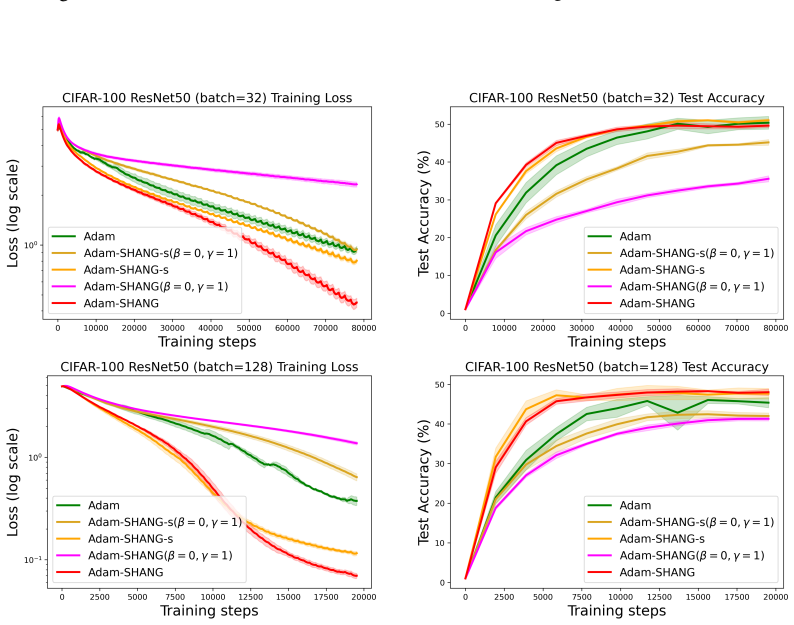
- Experiments confirm the predicted stochastic decay rates and show competitive performance versus Adam and AdamW on deep learning tasks.
Where Pith is reading between the lines
- The relaxed monotonicity requirement may explain why Adam-type methods often succeed empirically even when classical analyses do not apply.
- Lyapunov constructions centered on lagged preconditioners could be reused to analyze other adaptive first-order methods.
- In non-convex deep learning, focusing on local curvature stability rather than global second-moment behavior might guide more reliable stepsize selection.
Load-bearing premise
The lagged preconditioner must keep the effective curvature estimate stable enough that the chosen stepsize satisfies the admissibility condition at every iteration.
What would settle it
A simple strongly convex quadratic where the preconditioner produces steps that violate the spectral bound and the expected objective value stops decreasing toward the minimum.
Figures

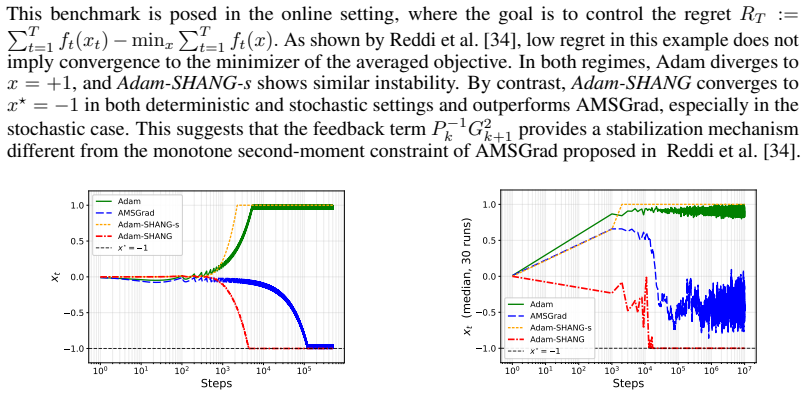
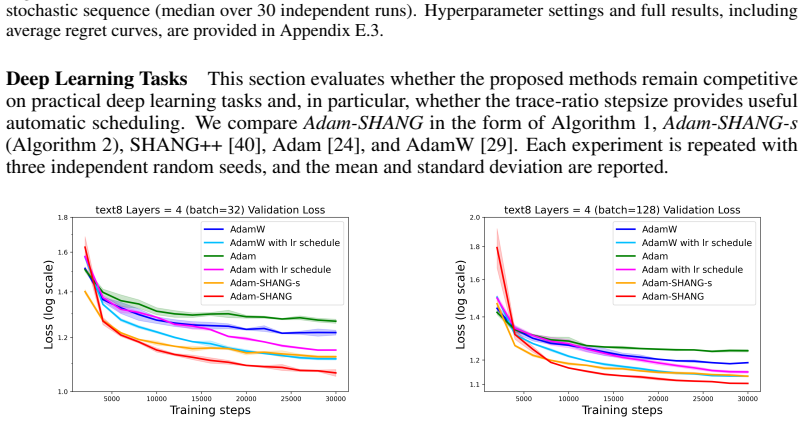
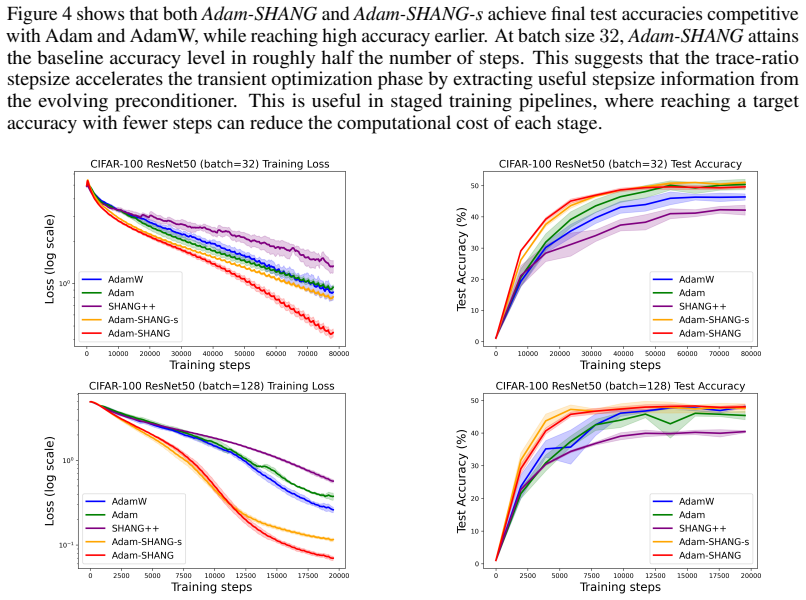


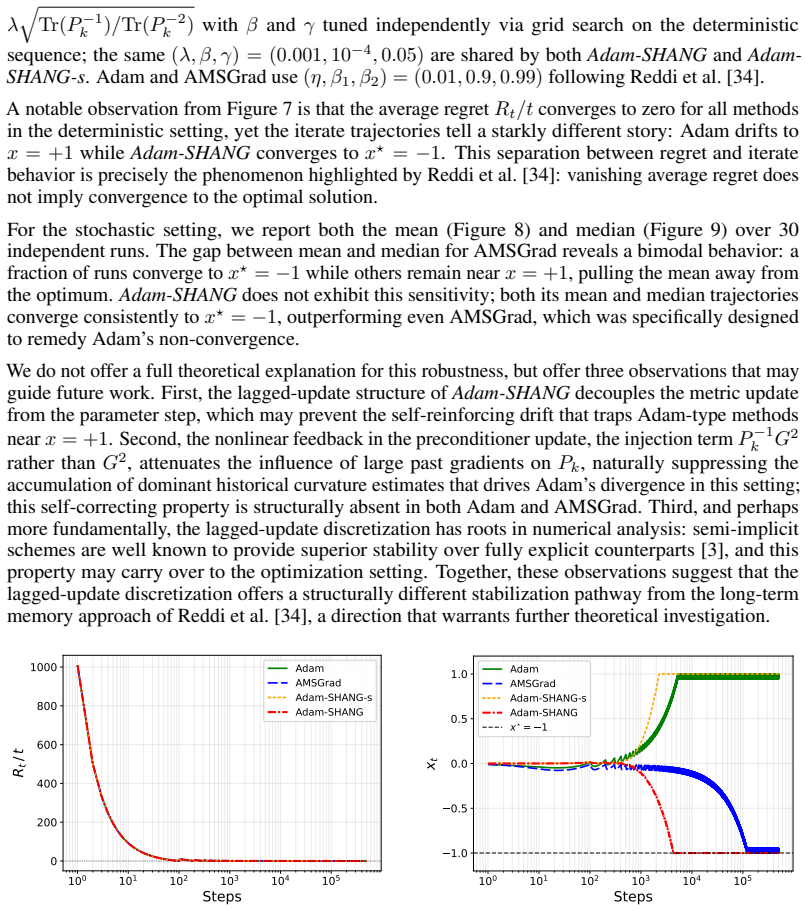





read the original abstract
We propose Adam-SHANG, a Lyapunov-guided Adam-type method that couples momentum, adaptive preconditioning, and a curvature-aware correction through a more stable lagged-preconditioner update. For stochastic smooth convex optimization, we prove convergence in expectation under an admissible stepsize condition that can always be satisfied by a conservative spectral bound, without imposing global monotonicity on the second-moment sequence. To obtain a less conservative practical rule, we introduce a computable trace-ratio stepsize, motivated by a local coordinatewise alignment condition. The same structural update is also tested beyond the convex setting with simplified parameters. Experiments validate the predicted stochastic decay and show competitive training performance against Adam and AdamW on deep learning tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Adam-SHANG, a Lyapunov-guided Adam-type method for stochastic smooth convex optimization that combines momentum, adaptive preconditioning, and a curvature-aware correction via a lagged-preconditioner update. It claims to prove convergence in expectation under an admissible stepsize condition (satisfied by a conservative spectral bound or a practical trace-ratio rule motivated by local coordinatewise alignment), without requiring global monotonicity on the second-moment sequence. The same update is tested in non-convex settings, and experiments are said to validate the predicted O(1/sqrt(T)) decay while showing competitive performance against Adam and AdamW on deep learning tasks.
Significance. If the convergence result holds with verifiable assumptions, the work is significant for relaxing a standard monotonicity assumption in analyses of adaptive stochastic methods through the lagged preconditioner and admissible stepsize framework. The dual provision of conservative and computable stepsize rules, together with the extension beyond convexity, offers both theoretical and practical value. Explicit credit is due for attempting a parameter-free derivation route via the spectral bound and for including empirical checks of the predicted decay.
major comments (2)
- [Convergence theorem] Main convergence theorem: the removal of the global monotonicity requirement on the second-moment sequence is load-bearing for the central claim, yet the analysis provides no quantitative bound on the lag parameter or on the probability that the local alignment condition holds under stochastic fluctuations; if the lagged v_t drifts, the Lyapunov decrease may fail even when the spectral bound is respected.
- [Theory section] Admissible stepsize condition (abstract and § on theory): the claim that the condition 'can always be satisfied' by the conservative spectral bound is not accompanied by explicit error bounds or a complete derivation showing how the trace-ratio rule avoids circularity with the fitted alignment; this leaves the O(1/sqrt(T)) rate unverified from the given information.
minor comments (2)
- [Experiments] Experiments: the validation of predicted stochastic decay is described only at high level; adding concrete plots or tables with measured rates versus T and explicit comparison metrics would strengthen the empirical support.
- [Method] Notation: the lagged-preconditioner update (v_t = beta v_{t-1} + (1-beta) g_t^2 with lag) should be defined with a single consistent equation number and clearly distinguished from the standard Adam second-moment update.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for recognizing the potential significance of relaxing the global monotonicity assumption via the lagged preconditioner. We address each major comment below and will revise the manuscript to improve clarity on the admissible stepsize framework.
read point-by-point responses
-
Referee: [Convergence theorem] Main convergence theorem: the removal of the global monotonicity requirement on the second-moment sequence is load-bearing for the central claim, yet the analysis provides no quantitative bound on the lag parameter or on the probability that the local alignment condition holds under stochastic fluctuations; if the lagged v_t drifts, the Lyapunov decrease may fail even when the spectral bound is respected.
Authors: The main theorem establishes convergence in expectation under the admissible stepsize condition, which is formulated to guarantee a sufficient Lyapunov decrease for any fixed lag parameter (chosen as a small constant in the algorithm). The conservative spectral bound is derived from an upper estimate on the operator norm of the preconditioner and holds deterministically, independent of stochastic fluctuations in v_t or any alignment probability. Thus, the Lyapunov decrease is ensured whenever the stepsize satisfies this bound, without requiring quantitative control on the lag or probabilistic statements on local alignment. The local alignment condition is used only to motivate the practical trace-ratio rule and is not invoked in the convergence proof. We will add a clarifying remark in the theory section explaining this deterministic guarantee. revision: partial
-
Referee: [Theory section] Admissible stepsize condition (abstract and § on theory): the claim that the condition 'can always be satisfied' by the conservative spectral bound is not accompanied by explicit error bounds or a complete derivation showing how the trace-ratio rule avoids circularity with the fitted alignment; this leaves the O(1/sqrt(T)) rate unverified from the given information.
Authors: The conservative spectral bound is constructed by replacing the preconditioner with its maximum possible eigenvalue (a uniform upper bound independent of the specific second-moment estimates), which directly yields an admissible stepsize that satisfies the required inequality by design; we will include the full derivation of this bound in the revised theory section, together with the resulting explicit constants in the O(1/sqrt(T)) rate. The trace-ratio rule is presented as a practical, computable alternative motivated by an empirical local alignment observation and is not used in the proof of the rate; the rate is established solely under the admissible condition satisfied by the spectral bound, avoiding any circularity. We will expand the manuscript to make this separation explicit and add the missing derivation steps. revision: yes
Circularity Check
No significant circularity in the convergence derivation
full rationale
The paper's central claim rests on a standard Lyapunov analysis for stochastic smooth convex optimization. The admissible stepsize condition is satisfied independently via a conservative spectral bound (or local trace-ratio alignment), without the convergence rate being defined in terms of itself or a fitted parameter from the same data. The lagged preconditioner update is presented as a structural choice motivated by stability considerations, not a self-definitional renaming or post-hoc fit. No load-bearing self-citation chains or ansatz smuggling reduce the result to its inputs by construction. The derivation remains self-contained against external benchmarks for convex stochastic problems.
Axiom & Free-Parameter Ledger
free parameters (1)
- admissible stepsize bound
axioms (1)
- domain assumption Stochastic gradients are unbiased with bounded variance; objective is smooth and convex.
Reference graph
Works this paper leans on
-
[1]
Convergence of adaptive algorithms for weakly convex constrained optimization, 2020
Ahmet Alacaoglu, Yura Malitsky, and V olkan Cevher. Convergence of adaptive algorithms for weakly convex constrained optimization, 2020. URL https://arxiv.org/abs/2006. 06650
2020
-
[2]
Asgo: Adaptive structured gradient optimization, 2025
Kang An, Yuxing Liu, Rui Pan, Yi Ren, Shiqian Ma, Donald Goldfarb, and Tong Zhang. Asgo: Adaptive structured gradient optimization, 2025
2025
-
[3]
Ascher, Steven J
Uri M. Ascher, Steven J. Ruuth, and Brian T. R. Wetton. Implicit-explicit methods for time- dependent partial differential equations.SIAM Journal on Numerical Analysis, 32(3):797–823, 1995
1995
-
[4]
Convergence and dynamical behavior of the adam algorithm for non-convex stochastic optimization, 2020
Anas Barakat and Pascal Bianchi. Convergence and dynamical behavior of the adam algorithm for non-convex stochastic optimization, 2020
2020
-
[5]
Popov, Arash Sarshar, and Adrian Sandu
Abhinab Bhattacharjee, Andrey A. Popov, Arash Sarshar, and Adrian Sandu. Improv- ing adam through an implicit-explicit (imex) time-stepping approach.Journal of Ma- chine Learning for Modeling and Computing, 5(3):47–68, 2024. ISSN 2689-3967. doi: 10.1615/jmachlearnmodelcomput.2024053508
-
[6]
First order optimization methods based on hessian-driven nesterov accelerated gradient flow, 2019
Long Chen and Hao Luo. First order optimization methods based on hessian-driven nesterov accelerated gradient flow, 2019
2019
-
[7]
Accelerated gradient methods through variable and operator splitting, 2025
Long Chen, Luo Hao, and Jingrong Wei. Accelerated gradient methods through variable and operator splitting, 2025
2025
-
[8]
On the convergence of a class of adam-type algorithms for non-convex optimization, 2019
Xiangyi Chen, Sijia Liu, Ruoyu Sun, and Mingyi Hong. On the convergence of a class of adam-type algorithms for non-convex optimization, 2019
2019
-
[9]
A general system of differential equations to model first order adaptive algorithms, 2019
André Belotto da Silva and Maxime Gazeau. A general system of differential equations to model first order adaptive algorithms, 2019
2019
-
[10]
Convergence guarantees for rmsprop and adam in non-convex optimization and an empirical comparison to nesterov acceleration, 2018
Soham De, Anirbit Mukherjee, and Enayat Ullah. Convergence guarantees for rmsprop and adam in non-convex optimization and an empirical comparison to nesterov acceleration, 2018
2018
-
[11]
Convergence rates for the adam optimizer, 2024
Steffen Dereich and Arnulf Jentzen. Convergence rates for the adam optimizer, 2024. URL https://arxiv.org/abs/2407.21078
-
[12]
Ode approximation for the adam algorithm: General and overparametrized setting, 2025
Steffen Dereich, Arnulf Jentzen, and Sebastian Kassing. Ode approximation for the adam algorithm: General and overparametrized setting, 2025
2025
-
[13]
Sharp higher order convergence rates for the adam optimizer, 2025
Steffen Dereich, Arnulf Jentzen, and Adrian Riekert. Sharp higher order convergence rates for the adam optimizer, 2025. URLhttps://arxiv.org/abs/2504.19426
-
[14]
Adaptive subgradient methods for online learning and stochastic optimization.Journal of Machine Learning Research, 12(61):2121–2159, 2011
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.Journal of Machine Learning Research, 12(61):2121–2159, 2011
2011
-
[15]
A simple convergence proof of adam and adagrad, 2022
Alexandre Défossez, Léon Bottou, Francis Bach, and Nicolas Usunier. A simple convergence proof of adam and adagrad, 2022
2022
-
[16]
Continuous-time analysis of adaptive optimization and normalization, 2024
Rhys Gould and Hidenori Tanaka. Continuous-time analysis of adaptive optimization and normalization, 2024
2024
-
[17]
Siegel, and Stephan Wojtowytsch
Kanan Gupta, Jonathan W. Siegel, and Stephan Wojtowytsch. Nesterov acceleration despite very noisy gradients, 2024. URLhttps://arxiv.org/abs/2302.05515
-
[18]
Shampoo: Preconditioned stochastic tensor optimization, 2018
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization, 2018
2018
-
[19]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. doi: 10.1109/CVPR.2016.90
-
[20]
Modeling adagrad, rmsprop, and adam with integro-differential equations, 2025
Carlos Heredia. Modeling adagrad, rmsprop, and adam with integro-differential equations, 2025. 10
2025
-
[21]
From adam to adam-like lagrangians: Second-order nonlocal dynamics, 2026
Carlos Heredia. From adam to adam-like lagrangians: Second-order nonlocal dynamics, 2026
2026
-
[22]
Nostalgic adam: Weighting more of the past gradients when designing the adaptive learning rate
Haiwen Huang, Chang Wang, and Bin Dong. Nostalgic adam: Weighting more of the past gradients when designing the adaptive learning rate. InProceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-2019, page 2556–2562. In- ternational Joint Conferences on Artificial Intelligence Organization, August 2019. doi: 10.249...
-
[23]
Yiming Jiang, Jinlan Liu, Dongpo Xu, and Danilo P. Mandic. Uadam: Unified adam-type algorithmic framework for nonconvex optimization.Neural Computation, 36(9):1912–1938, August 2024. ISSN 1530-888X. doi: 10.1162/neco_a_01692. URL http://dx.doi.org/10. 1162/neco_a_01692
-
[24]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017
2017
-
[25]
Sgd with adaptive preconditioning: Unified analysis and momentum accelera- tion, 2025
Dmitry Kovalev. Sgd with adaptive preconditioning: Unified analysis and momentum accelera- tion, 2025
2025
-
[26]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009
2009
-
[27]
Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations, 2018
Qianxiao Li, Cheng Tai, and Weinan E. Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations, 2018
2018
-
[28]
Adagrad under anisotropic smoothness, 2024
Yuxing Liu, Rui Pan, and Tong Zhang. Adagrad under anisotropic smoothness, 2024
2024
-
[29]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019
2019
-
[30]
A qualitative study of the dynamic behavior for adaptive gradient algorithms, 2021
Chao Ma, Lei Wu, and Weinan E. A qualitative study of the dynamic behavior for adaptive gradient algorithms, 2021
2021
-
[31]
Large text compression benchmark
Matt Mahoney. Large text compression benchmark. http://www.mattmahoney.net/dc/ text.html, 2009. Accessed: 2025
2009
-
[32]
On the sdes and scaling rules for adaptive gradient algorithms, 2024
Sadhika Malladi, Kaifeng Lyu, Abhishek Panigrahi, and Sanjeev Arora. On the sdes and scaling rules for adaptive gradient algorithms, 2024
2024
-
[33]
D. S. Mitrinovi´c, J. E. Pe ˇcari´c, and A. M. Fink.Classical and New Inequalities in Analysis. Kluwer Academic Publishers, Dordrecht, 1993
1993
-
[34]
Reddi, Satyen Kale, and Sanjiv Kumar
Sashank J. Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond, 2019
2019
-
[35]
Adopt: Modified adam can converge with any β2 with the optimal rate, 2024
Shohei Taniguchi, Keno Harada, Gouki Minegishi, Yuta Oshima, Seong Cheol Jeong, Go Na- gahara, Tomoshi Iiyama, Masahiro Suzuki, Yusuke Iwasawa, and Yutaka Matsuo. Adopt: Modified adam can converge with any β2 with the optimal rate, 2024. URL https: //arxiv.org/abs/2411.02853
-
[36]
Qianqian Tong, Guannan Liang, and Jinbo Bi. Calibrating the adaptive learning rate to improve convergence of adam.Neurocomputing, 481:333–356, 2022. ISSN 0925-2312. doi: https://doi. org/10.1016/j.neucom.2022.01.014. URL https://www.sciencedirect.com/science/ article/pii/S0925231222000340
-
[37]
Incorporating preconditioning into accelerated approaches: Theoretical guarantees and practical improvement,
Stepan Trifonov, Leonid Levin, Savelii Chezhegov, and Aleksandr Beznosikov. Incorporating preconditioning into accelerated approaches: Theoretical guarantees and practical improvement,
- [38]
-
[39]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2023
2023
-
[40]
Structured precondi- tioners in adaptive optimization: A unified analysis, 2025
Shuo Xie, Tianhao Wang, Sashank Reddi, Sanjiv Kumar, and Zhiyuan Li. Structured precondi- tioners in adaptive optimization: A unified analysis, 2025
2025
-
[41]
Shang++: Robust stochastic acceleration under multiplicative noise, 2026
Yaxin Yu, Long Chen, and Minfu Feng. Shang++: Robust stochastic acceleration under multiplicative noise, 2026. 11
2026
-
[42]
Adam-HNAG: A Convergent Reformulation of Adam with Accelerated Rate
Yaxin Yu, Long Chen, and Zeyi Xu. Adam-hnag: A convergent reformulation of adam with accelerated rate, 2026. URLhttps://arxiv.org/abs/2604.08742
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
On the convergence of adaptive gradient methods for nonconvex optimization, 2024
Dongruo Zhou, Jinghui Chen, Yuan Cao, Ziyan Yang, and Quanquan Gu. On the convergence of adaptive gradient methods for nonconvex optimization, 2024
2024
-
[44]
A sufficient condition for convergences of adam and rmsprop, 2019
Fangyu Zou, Li Shen, Zequn Jie, Weizhong Zhang, and Wei Liu. A sufficient condition for convergences of adam and rmsprop, 2019. A Convergence analysis ofAdam-SHANG A.1 Proof of Lemma 2.1 Proof of Lemma 2.1.ByL-smoothness andx + k+1 −x k+1 =−η k+1P −1 k gk+1,we have f(x + k+1)≤f(x k+1)−η k+1⟨∇f(x k+1), gk+1⟩P −1 k + Lη2 k+1 2 ∥gk+1∥2 P −2 k . Taking expect...
2019
-
[45]
Applying Lemma 2.1 atx k+1 and multiplying by−α k, we obtain E[−αkE(z k+1, Pk+1)]≤E −αkE(z + k+1, Pk+1)− αkηk+1 2(1 +σ 2
∥gk+1∥2 P −1 k + ηk+1σ2 0 1 +σ 2 1 + αkγk 2 ∥yk+1 −x ⋆∥2 P −1 k G2 k+1 + α2 k 2 ∥gk+1∥2 P −1 k . Applying Lemma 2.1 atx k+1 and multiplying by−α k, we obtain E[−αkE(z k+1, Pk+1)]≤E −αkE(z + k+1, Pk+1)− αkηk+1 2(1 +σ 2
-
[46]
Usingsup k ∥yk −x ⋆∥∞ ≤Randγ k =α k/R2, we further have αkγk 2 ∥yk+1 −x ⋆∥2 P −1 k G2 k+1 = α2 k 2R2 dX i=1 yk+1,i −x ⋆ i 2 P −1 k iig2 k+1,i ≤ α2 k 2 ∥gk+1∥2 P −1 k
∥gk+1∥2 P −1 k + αkηk+1σ2 0 1 +σ 2 1 . Usingsup k ∥yk −x ⋆∥∞ ≤Randγ k =α k/R2, we further have αkγk 2 ∥yk+1 −x ⋆∥2 P −1 k G2 k+1 = α2 k 2R2 dX i=1 yk+1,i −x ⋆ i 2 P −1 k iig2 k+1,i ≤ α2 k 2 ∥gk+1∥2 P −1 k . With the chosen parameters2α 2 k(1 +σ 2
-
[47]
Therefore, E E(z + k+1, Pk+1) ≤E 1 1 +α k E(z + k , Pk) + 2α2 kσ2 0
=η k+1, 2α2 k −(1 +α k) ηk+1 1 +σ 2 1 ≤0, so theg k+1-weighted terms are nonpositive and can be dropped. Therefore, E E(z + k+1, Pk+1) ≤E 1 1 +α k E(z + k , Pk) + 2α2 kσ2 0 . This yields the claimed one-step bound, and iterating the recursion proves the theorem. RemarkA.1.For analytical tractability, we assume that there existsR >0such that sup k≥0 ∥yk −x...
-
[48]
Figure 5: Empirical verification of the admissibility condition forAdam-SHANG
≥1.(30) The admissibility condition is satisfied wheneverRatio≥1. Figure 5: Empirical verification of the admissibility condition forAdam-SHANG. The ratio should be not less than1. Observation.In all tested cases, the monitored ratio remains above 1 throughout the whole trajectory. Thus, with the safety factor λ= 0.5 in the practical rule (13), we do not ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.