Recognition: 2 theorem links
· Lean TheoremBeyond Cooperative Simulators: Generating Realistic User Personas for Robust Evaluation of LLM Agents
Pith reviewed 2026-05-14 20:21 UTC · model grok-4.3
The pith
Evolving Python generators for user personas creates simulators that train LLM agents to succeed 17 percent more often against uncooperative people.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Persona Policies (PPol) is a plug-and-play control layer that uses LLM-driven evolutionary program search to optimize a Python generator; the search discovers behaviors and translates them into roleplay policies that preserve original task goals while the multi-objective fitness score drives both human-likeness and broad coverage, yielding 33-62 percent fitness gains, 80.4 percent human ratings in blinded tests, and 17 percent higher agent success on challenging interactions.
What carries the argument
LLM-driven evolutionary program search that optimizes a Python generator for personas using a multi-objective fitness score of human-likeness plus coverage of human behavioral patterns.
If this is right
- Agents trained with PPol improve task success by 17 percent relative to training only on existing simulated interactions.
- PPol yields 33-62 percent absolute gains in fitness score over baseline simulators in retail and airline domains.
- Annotators rate PPol-conditioned users as human 80.4 percent of the time, nearly twice as often as baseline simulators.
- Once optimized, the generator produces a diverse population of human-like personas for any task in the domain.
Where Pith is reading between the lines
- The same evolutionary search could be applied to create simulators for other interactive systems such as customer-service bots or tutoring agents.
- Measuring whether the evolved personas transfer to entirely new tasks would test how general the coverage of human patterns actually is.
- Combining PPol with other training techniques could further reduce reliance on collecting large sets of real user interaction data.
Load-bearing premise
The multi-objective fitness score actually produces personas that match real human behavioral patterns rather than simply pleasing the LLM judge or the chosen coverage metrics.
What would settle it
Run a blinded test in a held-out domain where agents trained with PPol interact with actual human users and show no gain in task success rates over agents trained only on baseline simulators.
Figures





read the original abstract
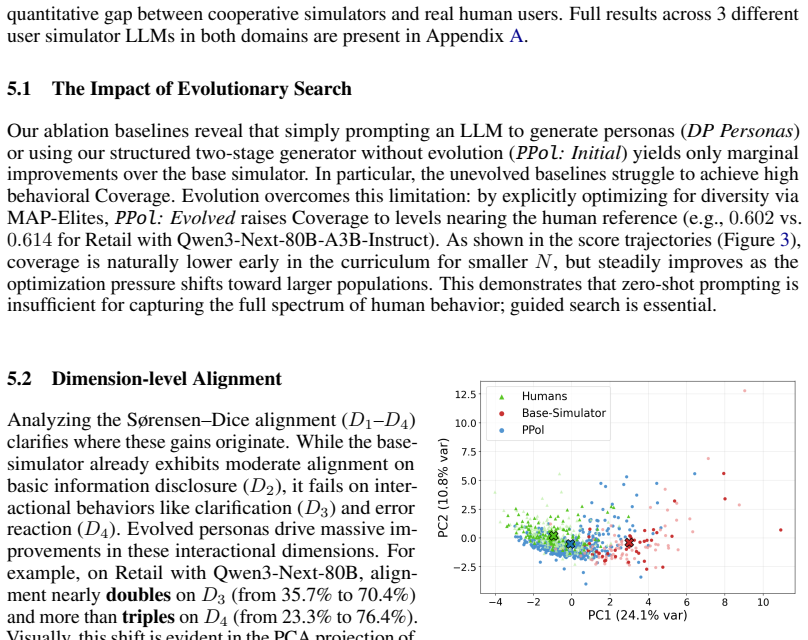
Large Language Model (LLM) agents are increasingly deployed in settings where they interact with a wide variety of people, including users who are unclear, impatient, or reluctant to share information. However, collecting real interaction data at scale remains expensive. The field has turned to LLM-based user simulators as stand-ins, but these simulators inherit the behavior of their underlying models: cooperative and homogeneous. As a result, agents that appear strong in simulation often fail under the unseen, diverse communication patterns of real users. To narrow this gap, we introduce Persona Policies (PPol), a plug-and-play control layer that induces realistic behavioral variation in user simulators while preserving the original task goals. Rather than hand-crafting personas, we cast persona generation as an LLM-driven evolutionary program search that optimizes a Python generator to discover behaviors and translate them into task-preserving roleplay policies. Candidate generators are guided by a multi-objective fitness score combining human-likeness with broad coverage of human behavioral patterns. Once optimized, the generator produces a diverse population of human-like personas for any task in the domain. Across tau^2-bench retail and airline domains, evolved PPol programs yield 33-62% absolute gains in fitness score over the baseline simulator. In a blinded evaluation, annotators rated PPol-conditioned users as human 80.4% of the time, close to real human traces and nearly twice as frequently as baseline simulators. Agents trained with PPol are more robust to challenging, out-of-distribution behaviors, improving task success by +17% relative to training only on existing simulated interactions. This offers a novel approach to strengthen simulator-based evaluation and training without changing tasks or rewards.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Persona Policies (PPol), a plug-and-play control layer that uses LLM-driven evolutionary program search to generate diverse, task-preserving user personas for simulators. It claims 33-62% absolute fitness gains over baseline simulators on tau^2-bench retail and airline domains, 80.4% human-likeness in blinded annotator ratings (nearly twice baseline), and +17% relative task success for agents trained on PPol-generated interactions versus existing simulated data.
Significance. If the generalization claims hold, PPol could meaningfully narrow the sim-to-real gap for LLM agent training and evaluation by inducing realistic behavioral variation without hand-crafted personas or new task definitions. The evolutionary search over Python generators is a technically interesting direction for scalable persona discovery.
major comments (3)
- [Abstract / §4] Abstract and §4 (Experiments): The +17% task success improvement is measured entirely within the tau^2-bench simulator ecosystem (PPol personas vs. baseline simulators); no held-out real-user interaction traces are used to measure agent success rates, leaving the central robustness-to-real-users claim unverified.
- [Abstract / §3] Abstract and §3 (Method): The multi-objective fitness score is described only at a high level (human-likeness + behavioral coverage); without the explicit definition of components, weights, or the precise procedure for computing human-likeness (LLM judge vs. human), it is impossible to assess whether the 33-62% gains reflect genuine behavioral diversity or optimization artifacts.
- [§4] §4: No mention of multiple random seeds or variance reporting for the evolutionary search; a single run leaves open whether the reported fitness and downstream +17% gains are stable or sensitive to initialization.
minor comments (1)
- [§3] Notation for the evolved generators and resulting personas is introduced without a clear running example; a concrete Python snippet in §3 would improve readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment point by point below, providing clarifications and committing to specific revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and §4 (Experiments): The +17% task success improvement is measured entirely within the tau^2-bench simulator ecosystem (PPol personas vs. baseline simulators); no held-out real-user interaction traces are used to measure agent success rates, leaving the central robustness-to-real-users claim unverified.
Authors: We acknowledge that the +17% relative task success gain is measured by training and evaluating agents entirely within the tau^2-bench simulator using PPol-generated versus baseline interactions. This design isolates the effect of behavioral diversity while holding the underlying task and reward fixed. The blinded human evaluation (80.4% rated human, near real traces) and the 33-62% fitness gains provide supporting evidence that PPol personas better approximate real-user variation. We agree that direct evaluation on held-out real-user traces would offer stronger validation of sim-to-real robustness. In the revised manuscript we will add an explicit limitations paragraph in §4 and §5 clarifying that the reported gains constitute a controlled proxy evaluation and identifying real-user trace validation as important future work. revision: partial
-
Referee: [Abstract / §3] Abstract and §3 (Method): The multi-objective fitness score is described only at a high level (human-likeness + behavioral coverage); without the explicit definition of components, weights, or the precise procedure for computing human-likeness (LLM judge vs. human), it is impossible to assess whether the 33-62% gains reflect genuine behavioral diversity or optimization artifacts.
Authors: We agree that the current high-level description of the fitness function limits interpretability. In the revised §3 we will provide the complete mathematical definition of the multi-objective score, including: (i) the human-likeness term (LLM-as-judge prompt that compares generated dialogues against a held-out set of real human traces from the same domains), (ii) the behavioral coverage term (quantified via entropy over communication-style clusters and coverage of impatience/reluctance patterns), (iii) the explicit weighting (equal weights after normalization), and (iv) the aggregation and selection procedure used during evolutionary search. These additions will allow readers to verify that the reported gains arise from genuine diversity rather than optimization artifacts. revision: yes
-
Referee: [§4] §4: No mention of multiple random seeds or variance reporting for the evolutionary search; a single run leaves open whether the reported fitness and downstream +17% gains are stable or sensitive to initialization.
Authors: We concur that statistical robustness is essential for evolutionary methods. In the revised §4 we will rerun the evolutionary program search with five independent random seeds, reporting mean and standard deviation for both the final fitness scores (across retail and airline domains) and the downstream agent task-success rates. We will also include a brief sensitivity analysis showing that the top-performing programs from different seeds yield consistent +17% gains within one standard deviation, thereby demonstrating stability with respect to initialization. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes casting persona generation as an LLM-driven evolutionary program search optimizing a multi-objective fitness score (human-likeness plus behavioral coverage), then reports resulting fitness gains of 33-62% and separate blinded annotator ratings of 80.4% human-likeness close to real traces. The +17% task success improvement is measured on a distinct agent training/evaluation metric within tau^2-bench. No equations, self-citations, or uniqueness theorems are present that would reduce any load-bearing claim to its own inputs by construction. The optimization objective and downstream empirical results (annotator judgments, task success) remain independent, making the overall derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- fitness score weights
axioms (1)
- domain assumption LLM-based evolutionary search can discover task-preserving yet behaviorally diverse personas
invented entities (1)
-
Persona Policies (PPol)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean (and all Foundation/* modules)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We cast persona generation as an LLM-driven evolutionary program search that optimizes a Python generator to discover behaviors and translate them into task-preserving roleplay policies... multi-objective fitness score combining human-likeness with broad coverage of human behavioral patterns.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Agents trained with PPol are more robust to challenging, out-of-distribution behaviors, improving task success by +17% relative to training only on existing simulated interactions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
2025
-
[2]
Deepseek-v3 technical report, 2024
DeepSeek-AI. Deepseek-v3 technical report, 2024
2024
-
[3]
Yao Dou, Michel Galley, Baolin Peng, Chris Kedzie, Weixin Cai, Alan Ritter, Chris Quirk, Wei Xu, and Jianfeng Gao. Simulatorarena: Are user simulators reliable proxies for multi-turn evaluation of AI assistants? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35200–35278, 2025
2025
-
[4]
Scaling synthetic data creation with 1,000,000,000 personas, 2025
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
-
[5]
Muyu He, Anand Kumar, Tsach Mackey, Meghana Rajeev, James Zou, and Nazneen Rajani. Impatient users confuse AI agents: High-fidelity simulations of human traits for testing agents.arXiv preprint arXiv:2510.04491, 2025
-
[6]
On overcoming miscal- ibrated conversational priors in LLM-based chatbots
Christine Herlihy, Jennifer Neville, Tobias Schnabel, and Adith Swaminathan. On overcoming miscal- ibrated conversational priors in LLM-based chatbots. InUncertainty in Artificial Intelligence, pages 1599–1620. PMLR, 2024
2024
-
[7]
How to approach ambiguous queries in conversational search: A survey of techniques, approaches, tools, and challenges.ACM Computing Surveys, 55(6):1–40, 2022
Kimiya Keyvan and Jimmy Xiangji Huang. How to approach ambiguous queries in conversational search: A survey of techniques, approaches, tools, and challenges.ACM Computing Surveys, 55(6):1–40, 2022. 10
2022
-
[8]
Platolm: Teaching LLMs in multi- round dialogue via a user simulator
Chuyi Kong, Yaxin Fan, Xiang Wan, Feng Jiang, and Benyou Wang. Platolm: Teaching LLMs in multi- round dialogue via a user simulator. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7841–7863, 2024
2024
-
[9]
LLMs get lost in multi-turn conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs get lost in multi-turn conversation. InProceedings of the Fourteenth International Conference on Learning Representations (ICLR), 2026
2026
-
[10]
Toolsandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, et al. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1160–1183, 2025
2025
-
[11]
Duetsim: Building user simulator with dual large language models for task-oriented dialogues
Xiang Luo, Zhiwen Tang, Jin Wang, and Xuejie Zhang. Duetsim: Building user simulator with dual large language models for task-oriented dialogues. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 5414–5424, 2024
2024
-
[12]
Crowdsourcing a word–emotion association lexicon.Computa- tional intelligence, 29(3):436–465, 2013
Saif M Mohammad and Peter D Turney. Crowdsourcing a word–emotion association lexicon.Computa- tional intelligence, 29(3):436–465, 2013
2013
-
[13]
Illuminating search spaces by mapping elites
Jean-Baptiste Mouret and Jeff Clune. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[14]
Tarek Naous, Philippe Laban, Wei Xu, and Jennifer Neville. Flipping the dialogue: Training and evaluating user language models.arXiv preprint arXiv:2510.06552, 2025
-
[15]
GPT-5.4 mini language model
OpenAI. GPT-5.4 mini language model. Chat output, 2026. Generated on 2026-05-07
2026
-
[16]
Davide Paglieri, Logan Cross, William A Cunningham, Joel Z Leibo, and Alexander Sasha Vezhnevets. Persona generators: Generating diverse synthetic personas at scale.arXiv preprint arXiv:2602.03545, 2026
-
[17]
Pennebaker, Ryan L
James W. Pennebaker, Ryan L. Boyd, Kayla Jordan, and Kate G. Blackburn. The development and psychometric properties of LIWC2015. 2015
2015
-
[18]
Prolific.https://www.prolific.com, 2026
Prolific. Prolific.https://www.prolific.com, 2026. Online participant recruitment platform
2026
-
[19]
Reliable LLM-based user simulator for task-oriented dialogue systems
Ivan Sekulic, Silvia Terragni, Victor Guimarães, Nghia Khau, Bruna Guedes, Modestas Filipavicius, Andre Ferreira Manso, and Roland Mathis. Reliable LLM-based user simulator for task-oriented dialogue systems. In Yvette Graham, Qun Liu, Gerasimos Lampouras, Ignacio Iacobacci, Sinead Madden, Haider Khalid, and Rameez Qureshi, editors,Proceedings of the 1st ...
2024
-
[20]
Lost in simulation: LLM-simulated users are unreliable proxies for human users in agentic evaluations
Preethi Seshadri, Samuel Cahyawijaya, Ayomide Odumakinde, Sameer Singh, and Seraphina Goldfarb- Tarrant. Lost in simulation: LLM-simulated users are unreliable proxies for human users in agentic evaluations. InAlgorithmic Fairness Across Alignment Procedures and Agentic Systems, 2026
2026
-
[21]
Openevolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. Openevolve: an open-source evolutionary coding agent, 2025
2025
-
[22]
Non-collaborative user simulators for tool agents
Jeonghoon Shim, Woojung Song, Cheyon Jin, Seungwon Kook, and Yohan Jo. Non-collaborative user simulators for tool agents. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[23]
Qwen3 technical report, 2025
Qwen Team. Qwen3 technical report, 2025
2025
-
[24]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
2017
-
[25]
Know you first and be you better: Modeling human-like user simulators via implicit profiles
Kuang Wang, Xianfei Li, Shenghao Yang, Li Zhou, Feng Jiang, and Haizhou Li. Know you first and be you better: Modeling human-like user simulators via implicit profiles. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: L...
2025
-
[26]
MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback. InThe Twelfth International Conference on Learning Representations, 2024. 11
2024
-
[27]
Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. Personalizing dialogue agents: I have a dog, do you have pets too? In Iryna Gurevych and Yusuke Miyao, editors, Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2204–2213, Melbourne, Australia, July ...
2018
-
[28]
behavior
Xuhui Zhou, Weiwei Sun, Qianou Ma, Yiqing Xie, Jiarui Liu, Weihua Du, Sean Welleck, Yiming Yang, Graham Neubig, Sherry Tongshuang Wu, and Maarten Sap. Mind the Sim2Real gap in user simulation for agentic tasks, 2026. Broader Impacts We introduce a method to generate realistic, diverse user behaviors for simulating task-oriented interactions. The primary p...
2026
-
[29]
GROUND the persona in this specific Task Context and behavior profile
-
[30]
Specify concrete communication patterns that should be followed: linguistics, vocabulary, emotional markers, how they respond to agent requests
-
[31]
Preserve all goals and facts from the Task Context; only vary *how* the person pursues them
-
[32]
Do NOT break the character — no mention of "simulation", "benchmark", or "AI". Respond with ONLY the roleplay instruction text:""" defgenerate_personas_detailed(c:str, axes: List[Dict[str, Any]], n:int) -> List[Dict[str, Any]]: """G(c, D, N) — the single public entrypoint. expanded_instruction of each persona is fed to the user simulator. """ population =...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.