Recognition: no theorem link
AgentLens: Revealing The Lucky Pass Problem in SWE-Agent Evaluation
Pith reviewed 2026-05-14 18:46 UTC · model grok-4.3
The pith
Binary pass rates in SWE-agent tests equate chaotic trial-and-error successes with systematic ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
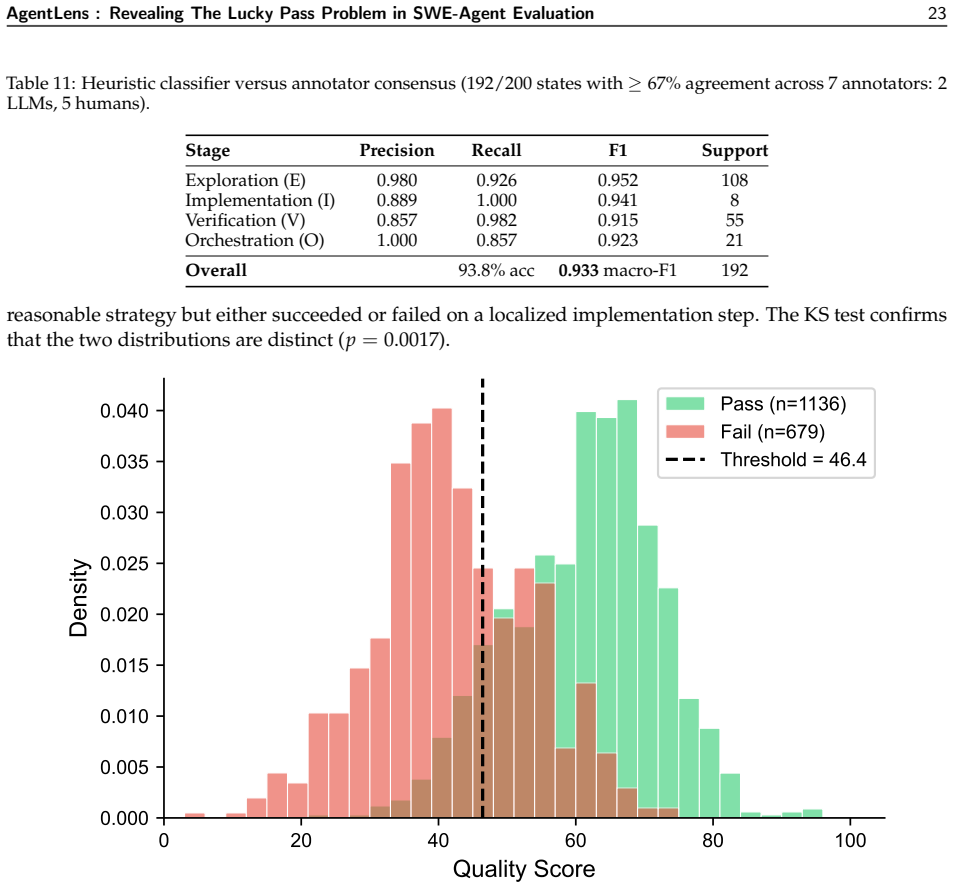
Among passing trajectories in the 1,815-trajectory subset, 10.7% exhibit Lucky Pass behavior consisting of regression cycles, blind retries, missing verification, or temporally disordered exploration, implementation, and verification. AgentLens constructs Prefix Tree Acceptor references by merging multiple passing solutions for each task and applies a context-sensitive labeler that assigns actions to Exploration, Implementation, Verification, or Orchestration based on trajectory history.
What carries the argument
Prefix Tree Acceptor (PTA) references formed by merging multiple passing trajectories, used to score new runs on quality and detect divergence into lucky mechanisms.
If this is right
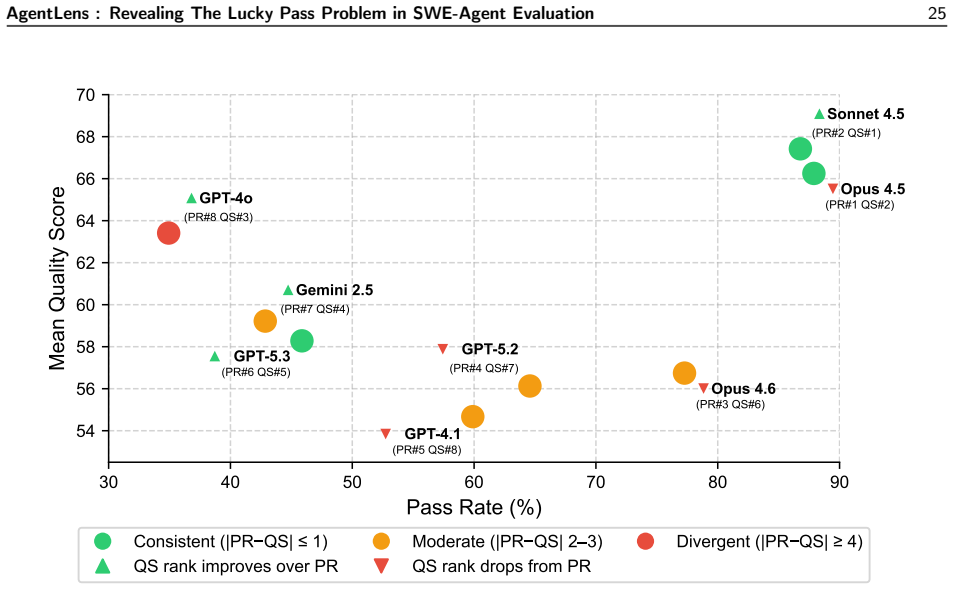
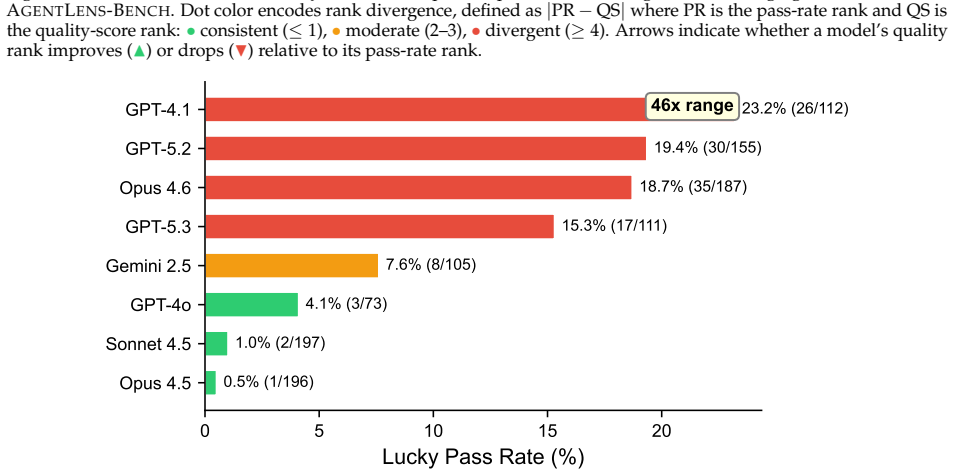
- Lucky Pass rates range from 0.5% to 23.2% across the eight model backends.
- Ranking models by quality score instead of pass rate moves some models by up to five positions.
- Lucky Passes decompose into five recurring mechanisms that can be measured separately.
- Process-level scores distinguish chaotic successes from solid ones within the same passing set.
- The framework supplies annotated trajectories and task references for further study of agent processes.
Where Pith is reading between the lines
- If many passes are lucky, real-world deployment of these agents may encounter more failures once test oracles are imperfect.
- Filtering training data to exclude Lucky trajectories could improve downstream agent reliability.
- The PTA reference approach might extend to other agent domains where outcome-only evaluation hides process flaws.
- Re-running the evaluation on the full SWE-bench Verified set could reveal whether the 10.7% rate holds beyond the 47 tasks with sufficient data.
Load-bearing premise
Merging multiple passing solutions into Prefix Tree Acceptor references produces a pure model of principled behavior without incorporating lucky elements from the source trajectories.
What would settle it
Manual review of the released AgentLens-Bench annotations to check whether trajectories scored as Lucky actually display the listed disordered behaviors such as regression cycles or absent verification steps.
Figures







read the original abstract
Evaluation of software engineering (SWE) agents is dominated by a binary signal: whether the final patch passes the tests. This outcome-only view treats a principled solution and a chaotic trial-and-error process as equivalent. We show that this equivalence is empirically false. We evaluate 2,614 OpenHands trajectories from eight model backends on 60 SWE-bench Verified tasks. Of these, 47 have enough passing trajectories to construct task-level process references, yielding a 1,815-trajectory evaluation subset. Among passing trajectories in this subset, 10.7% exhibit behavior we call a Lucky Pass: regression cycles, blind retries, missing verification, or temporally disordered exploration, implementation, and verification. We introduce AgentLens, a framework for process-level assessment of SWE-agent trajectories, and release AgentLens-Bench, a dataset of 1,815 trajectories annotated with quality scores, waste signals, divergence points, and 47 task-level Prefix Tree Acceptor (PTA) references. AgentLens builds PTA references by merging multiple passing solutions for the same task, and uses a context-sensitive intent labeler to assign actions to Exploration, Implementation, Verification, or Orchestration based on trajectory history rather than tool identity alone. On AgentLens-Bench, the quality score separates passing trajectories into Lucky, Solid, and Ideal tiers and further decomposes Lucky Passes into five recurring mechanisms. Across the eight model backends, Lucky rates range from 0.5% to 23.2%, and some models move by as many as five rank positions when ranked by quality score instead of pass rate. We release the anonymized project repository, including the AgentLens-Bench dataset and AgentLens SDK, at https://github.com/microsoft/code-agent-state-trajectories/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that binary pass/fail evaluation of SWE agents is insufficient, as many passing trajectories involve inefficient 'Lucky Pass' processes (regression cycles, blind retries, missing verification, or temporally disordered exploration/implementation/verification). Using AgentLens on 1,815 trajectories from 2,614 total across eight models and 60 SWE-bench Verified tasks (47 tasks with sufficient passes), they construct task-level Prefix Tree Acceptor (PTA) references by merging passing solutions, apply a context-sensitive intent labeler to categorize actions, and derive quality scores that partition trajectories into Lucky/Solid/Ideal tiers. This yields a 10.7% lucky pass rate, model-specific lucky rates from 0.5% to 23.2%, and rank shifts of up to five positions when using quality scores versus pass rates. The work releases AgentLens-Bench (annotated trajectories and 47 PTA references) and an SDK.
Significance. If the central measurements are robust, the result is significant because it demonstrates that outcome-only metrics can mask substantial process differences in agent behavior, with direct implications for benchmark design and model ranking in software engineering agents. The open release of the annotated dataset, PTA references, and SDK is a clear strength for reproducibility and enables follow-on work on process-aware evaluation. The empirical rank-shift evidence provides a falsifiable hook for the community to test whether quality tiers predict downstream properties such as maintainability or generalization.
major comments (2)
- [§3] §3 (PTA reference construction): The PTA references are formed by merging all passing trajectories per task without an explicit quality filter or iterative removal of trajectories later classified as lucky passes. Because the source set contains the same regression cycles and disordered sequences that the framework later flags, the acceptor may encode non-principled paths as canonical; this directly affects the validity of the 10.7% lucky-pass statistic and the quality-tier separation. A sensitivity analysis that rebuilds PTAs after removing candidate lucky trajectories, or a description of any ad-hoc filtering, is required to establish that the reference truly captures principled behavior.
- [§4.2] §4.2 and Table 2 (quality-score derivation and five-mechanism decomposition): The quality tiers and the breakdown of the 10.7% into five recurring mechanisms rest on the context-sensitive intent labeler and subsequent annotation. The manuscript must report inter-annotator agreement (e.g., Cohen’s κ or percentage agreement) for the Exploration/Implementation/Verification/Orchestration labels and for the lucky-pass mechanism tags; without these metrics it is impossible to assess whether the reported percentages and rank shifts are stable under annotation noise.
minor comments (2)
- [§2] Abstract and §2: The total of 2,614 trajectories is reduced to the 1,815-trajectory subset for the 47 tasks that have enough passes; the exact selection rule (minimum number of passes per task, any other filters) should be stated explicitly in the main text rather than only in the abstract.
- [Figure 3] Figure 3 (rank-shift visualization): Ensure that the legend clearly distinguishes pass-rate ranking from quality-score ranking and that error bars or confidence intervals are shown for the per-model lucky rates.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We believe the concerns raised can be addressed through additional analysis and reporting in the revised manuscript, strengthening the robustness of our claims.
read point-by-point responses
-
Referee: [§3] §3 (PTA reference construction): The PTA references are formed by merging all passing trajectories per task without an explicit quality filter or iterative removal of trajectories later classified as lucky passes. Because the source set contains the same regression cycles and disordered sequences that the framework later flags, the acceptor may encode non-principled paths as canonical; this directly affects the validity of the 10.7% lucky-pass statistic and the quality-tier separation. A sensitivity analysis that rebuilds PTAs after removing candidate lucky trajectories, or a description of any ad-hoc filtering, is required to establish that the reference truly captures principled behavior.
Authors: We appreciate this observation regarding the potential circularity in PTA construction. While the merging process in Prefix Tree Acceptors inherently captures the most common paths across trajectories, and lucky passes are defined as significant deviations from this merged structure, we acknowledge that including all passes could introduce some noise. In the revised version, we will conduct a sensitivity analysis by iteratively removing trajectories classified as lucky passes and rebuilding the PTAs to verify stability of the quality scores and lucky-pass rates. This will be added to §3. revision: yes
-
Referee: [§4.2] §4.2 and Table 2 (quality-score derivation and five-mechanism decomposition): The quality tiers and the breakdown of the 10.7% into five recurring mechanisms rest on the context-sensitive intent labeler and subsequent annotation. The manuscript must report inter-annotator agreement (e.g., Cohen’s κ or percentage agreement) for the Exploration/Implementation/Verification/Orchestration labels and for the lucky-pass mechanism tags; without these metrics it is impossible to assess whether the reported percentages and rank shifts are stable under annotation noise.
Authors: We agree that reporting inter-annotator agreement is essential for validating the annotation process. The context-sensitive intent labeler combines automated rules with human verification for ambiguous cases. In the revision, we will include Cohen’s κ scores for both the intent labels (Exploration/Implementation/Verification/Orchestration) and the lucky-pass mechanism tags, based on a double-annotation of a subset of trajectories. This addition will appear in §4.2. revision: yes
Circularity Check
No significant circularity; derivation relies on independent annotations and merged references
full rationale
The paper constructs task-level PTA references by merging multiple passing trajectories and applies a context-sensitive intent labeler plus quality annotations to identify Lucky Passes (regression cycles, blind retries, missing verification, disordered sequences) at 10.7%. Quality scores and tiering into Lucky/Solid/Ideal are built from these annotations and references rather than from the binary pass-rate signal or any fitted parameter. No self-citation load-bearing steps, uniqueness theorems imported from authors, or ansatzes smuggled via prior work appear in the derivation chain. The central empirical claims rest on the released AgentLens-Bench dataset and explicit behavioral signals, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- quality tier thresholds
axioms (1)
- domain assumption Multiple passing trajectories for the same task can be merged into a Prefix Tree Acceptor that represents ideal solution structure.
invented entities (1)
-
Lucky Pass
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.20285 , year=
Swe-search: Enhancing software agents with monte carlo tree search and iterative refinement , author=. arXiv preprint arXiv:2410.20285 , year=
-
[2]
Swe-rebench: An automated pipeline for task collection and decontaminated evaluation of software engineering agents , author=. arXiv preprint arXiv:2505.20411 , year=
-
[3]
arXiv preprint arXiv:2506.18824 , year=
Understanding software engineering agents: A study of thought-action-result trajectories , author=. arXiv preprint arXiv:2506.18824 , year=
- [4]
-
[5]
doi:10.5281/zenodo.19357078 , url =
Max Brunsfeld and Amaan Qureshi and Andrew Hlynskyi and Will Lillis and ObserverOfTime and Christian Clason and dundargoc and Phil Turnbull and Timothy Clem and Douglas Creager and Andrew Helwer and Riley Bruins and Antonin Delpeuch and Daumantas Kavolis and Michael Davis and Ika and bfredl and Tuấn-Anh Nguyễn and Amin Ya and Stafford Brunk and skewb1k an...
-
[6]
Why Do Multi-Agent LLM Systems Fail?
Why do multi-agent llm systems fail? , author=. arXiv preprint arXiv:2503.13657 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
International Journal of Innovative Research in Technology , year =
Sana Ansari, Sakshi Kini , title =. International Journal of Innovative Research in Technology , year =
-
[8]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
TRAIL: Trace reasoning and agentic issue localization.arXiv preprint arXiv:2505.08638, 2025
Trail: Trace reasoning and agentic issue localization , author=. arXiv preprint arXiv:2505.08638 , year=
-
[10]
Pattern recognition letters , volume=
An introduction to ROC analysis , author=. Pattern recognition letters , volume=. 2006 , publisher=
work page 2006
-
[11]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents,
R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents , author=. arXiv preprint arXiv:2504.07164 , year=
-
[13]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Swe-bench: Can language models resolve real-world github issues? , author=. arXiv preprint arXiv:2310.06770 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
IEEE Transactions on software engineering , volume=
An exploratory study of how developers seek, relate, and collect relevant information during software maintenance tasks , author=. IEEE Transactions on software engineering , volume=. 2006 , publisher=
work page 2006
-
[15]
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
work page 2022
-
[16]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[17]
IEEE Transactions on Information theory , volume=
Divergence measures based on the Shannon entropy , author=. IEEE Transactions on Information theory , volume=. 2002 , publisher=
work page 2002
-
[18]
AgentBench: Evaluating LLMs as Agents
Agentbench: Evaluating llms as agents , author=. arXiv preprint arXiv:2308.03688 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proceedings of the ACM on Programming Languages , volume=
Process-Centric Analysis of Agentic Software Systems , author=. Proceedings of the ACM on Programming Languages , volume=. 2026 , publisher=
work page 2026
-
[20]
Advances in neural information processing systems , volume=
Agentboard: An analytical evaluation board of multi-turn llm agents , author=. Advances in neural information processing systems , volume=
-
[21]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[22]
arXiv preprint arXiv:2511.00197 , year=
Understanding Code Agent Behaviour: An Empirical Study of Success and Failure Trajectories , author=. arXiv preprint arXiv:2511.00197 , year=
-
[23]
Swe-lancer: Can frontier llms earn \ 1 million from real-world freelance software engineering? , author=. arXiv preprint arXiv:2502.12115 , year=
-
[24]
Pattern recognition and image analysis , volume=
Inferring regular languages in polynomial update time , author=. Pattern recognition and image analysis , volume=. 1992 , publisher=
work page 1992
-
[26]
Training software engineering agents and verifiers with swe-gym, 2024.URL https://arxiv
Training software engineering agents and verifiers with swe-gym , author=. arXiv preprint arXiv:2412.21139 , year=
-
[27]
arXiv preprint arXiv:2505.15277 , year=
Web-shepherd: Advancing prms for reinforcing web agents , author=. arXiv preprint arXiv:2505.15277 , year=
-
[28]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[29]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[30]
arXiv preprint arXiv:2512.21919 , year=
SWE-RM: Execution-free Feedback For Software Engineering Agents , author=. arXiv preprint arXiv:2512.21919 , year=
-
[31]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces , author=. arXiv preprint arXiv:2601.11868 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process-and outcome-based feedback , author=. arXiv preprint arXiv:2211.14275 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Wang, Xingyao and Chen, Yangyi and Yuan, Lifan and Zhang, Yizhe and Li, Yunzhu and Peng, Hao and Ji, Heng , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[34]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Math-shepherd: Verify and reinforce llms step-by-step without human annotations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Openhands: An open platform for ai software developers as generalist agents , author=. arXiv preprint arXiv:2407.16741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
Multi-swe-bench: A multilingual benchmark for issue resolving , author=. arXiv preprint arXiv:2504.02605 , year=
-
[38]
SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution
Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution , author=. arXiv preprint arXiv:2502.18449 , year=
work page internal anchor Pith review arXiv
-
[39]
Agentless: Demystifying LLM-based Software Engineering Agents
Agentless: Demystifying llm-based software engineering agents , author=. arXiv preprint arXiv:2407.01489 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and Liu, Yitao and Xu, Yiheng and Zhou, Shuyan and Savarese, Silvio and Xiong, Caiming and Zhong, Victor and Yu, Tao , booktitle =. OSWorld: Benchmarking Multimodal Agents for Open-En...
-
[41]
Andrew P. Bradley , keywords =. The use of the area under the ROC curve in the evaluation of machine learning algorithms , journal =. 1997 , issn =. doi:https://doi.org/10.1016/S0031-3203(96)00142-2 , url =
-
[42]
Frank J. Massey , journal =. The Kolmogorov-Smirnov Test for Goodness of Fit , urldate =
-
[43]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
Yang, John and Jimenez, Carlos and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , booktitle =. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , url =. doi:10.52202/079017-1601 , editor =
-
[44]
SWE-smith: Scaling Data for Software Engineering Agents , author=. 2025 , eprint=
work page 2025
-
[45]
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
work page 2023
-
[46]
and Cao, Yuan and Narasimhan, Karthik , title =
Yao, Shunyu and Yu, Dian and Zhao, Jeffrey and Shafran, Izhak and Griffiths, Thomas L. and Cao, Yuan and Narasimhan, Karthik , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
work page 2023
-
[47]
Youden, W. J. , title =. Cancer , volume =. doi:https://doi.org/10.1002/1097-0142(1950)3:1<32::AID-CNCR2820030106>3.0.CO;2-3 , url =. https://acsjournals.onlinelibrary.wiley.com/doi/pdf/10.1002/1097-0142 year =
-
[48]
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
work page 2020
-
[49]
Zhang, Yuntong and Ruan, Haifeng and Fan, Zhiyu and Roychoudhury, Abhik , title =. 2024 , isbn =. doi:10.1145/3650212.3680384 , booktitle =
-
[50]
P rocess B ench: Identifying Process Errors in Mathematical Reasoning
Zheng, Chujie and Zhang, Zhenru and Zhang, Beichen and Lin, Runji and Lu, Keming and Yu, Bowen and Liu, Dayiheng and Zhou, Jingren and Lin, Junyang. P rocess B ench: Identifying Process Errors in Mathematical Reasoning. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/20...
-
[51]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , url=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Establishing Best Practices for Building Rigorous Agentic Benchmarks , author=. 2025 , eprint=
work page 2025
-
[53]
Agent-as-a-Judge: Evaluate Agents with Agents , author=. 2024 , eprint=
work page 2024
-
[54]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. arXiv preprint arXiv:2406.15877 , year=
work page internal anchor Pith review arXiv
- [55]
-
[56]
Moatless tools: An open-source SWE-agent toolkit , year =
- [57]
-
[58]
Jimenez, C. E. and others , title =
- [59]
- [60]
-
[61]
Zhang, Linghao and others , year =. 2505.23419 , archivePrefix =
- [62]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.