Recognition: no theorem link
An NPDo Approach for Tensor Block-Diagonalization
Pith reviewed 2026-05-14 18:58 UTC · model grok-4.3
The pith
An NPDo method computes partial tensor block-diagonalization by maximizing the extracted block-diagonal part and converges globally while increasing the objective at each step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the principal tensor block-diagonalization of a given tensor can be obtained by an NPDo optimization procedure; when this procedure is combined with Gauss-Seidel-type updating, the iteration converges globally to a stationary point and the objective function increases monotonically throughout.
What carries the argument
The NPDo approach, which iteratively maximizes the block-diagonal part of the tensor by orthonormal mode multiplications.
If this is right
- PTBD reduces exactly to the Tucker decomposition when only one block is retained.
- PTBD reduces to the approximate dominant tensor SVD when every block is required to be 1-by-1.
- The objective value is guaranteed to increase at each Gauss-Seidel update.
- The sequence of iterates reaches a stationary point from any starting point.
Where Pith is reading between the lines
- The same updating scheme could be tested on tensors whose natural block structure arises from clustering or community detection tasks.
- Runtime comparisons with alternating least-squares or higher-order SVD methods would quantify whether the monotonicity property translates into faster practical convergence.
- The framework admits an immediate extension to weighted or constrained block sizes that reflect prior knowledge about the data.
Load-bearing premise
Maximizing the extracted block-diagonal part via mode multiplications by orthonormal matrices optimally represents the tensor for the chosen block sizes.
What would settle it
A concrete numerical example in which the NPDo updates produce a decrease in the objective function or fail to approach a stationary point.
Figures
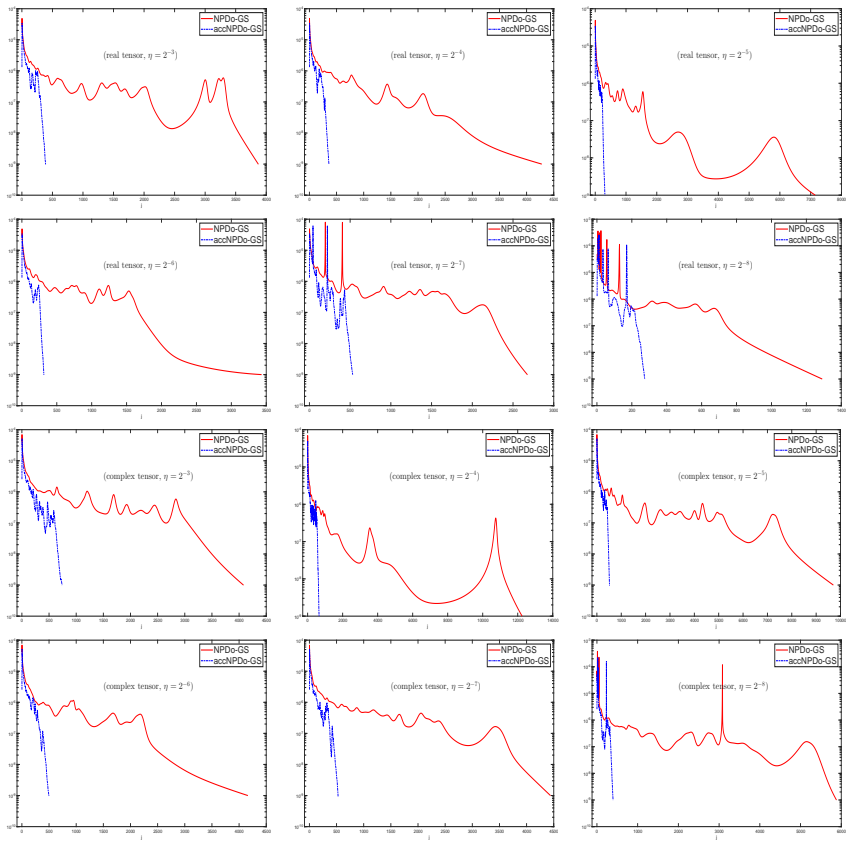


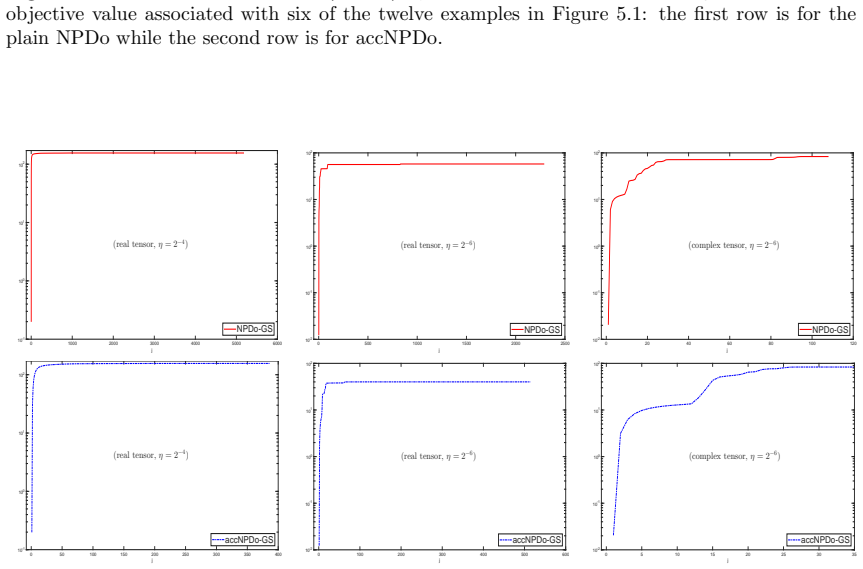



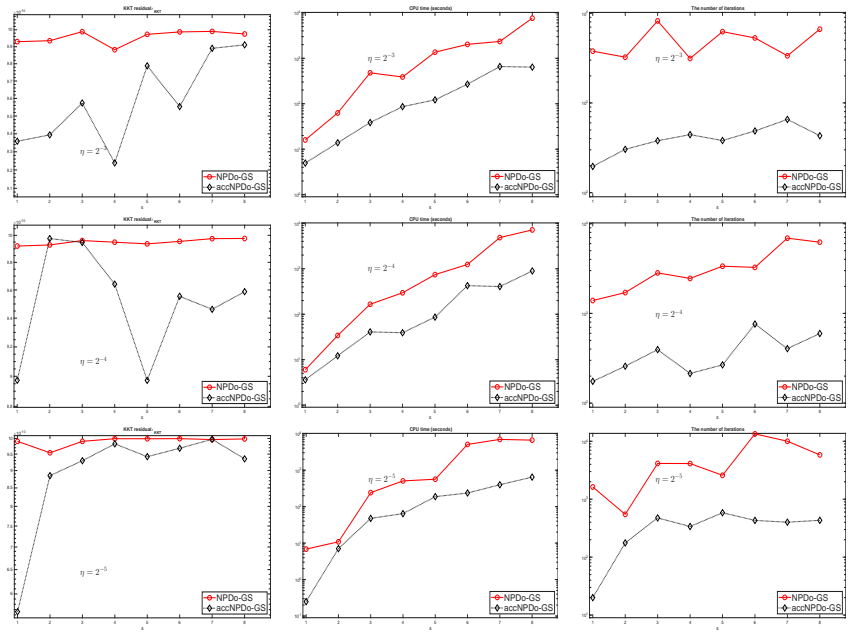

read the original abstract
This paper is concerned with Partial Tensor Block-Diagonalization of a multiway tensor by orthonormal matrices so that the extracted block-diagonal part optimally represents the tensor. The basic idea is to maximize the block-diagonal part via the tensor's mode-multiplications by orthonormal matrices. For that reason, it will be referred to Principal Tensor Block-Diagonalization (PTBD), which contains the Tucker decomposition (TD) of a tensor as a special case with just one block. Also as a special case is the approximate dominant tensor SVD in which each block-size is 1-by-1. An NPDo approach is proposed to optimize the block-diagonal part for computing \ptbd. It is shown the NPDo approach combined with Gauss-Seidel-type updating is globally convergent to a stationary point while the objective increases monotonically. Numerical experiments are presented to illustrate the efficiency of the NPDo approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Principal Tensor Block-Diagonalization (PTBD) of a multiway tensor, achieved by finding orthonormal matrices that maximize the extracted block-diagonal part under mode multiplications. It proposes an NPDo optimization approach combined with Gauss-Seidel-type updates, proves that the resulting sequence is monotonically non-decreasing and globally convergent to a stationary point on the product of Stiefel manifolds, recovers Tucker decomposition as the single-block case and approximate dominant tensor SVD as the all-1x1-blocks case, and illustrates performance via numerical experiments.
Significance. If the convergence analysis holds, the work supplies a convergent, flexible extension of classical tensor decompositions that interpolates between Tucker forms and diagonal approximations. The explicit recovery of known special cases and the use of standard compactness arguments on Stiefel manifolds provide a reliable algorithmic foundation for applications requiring structured tensor approximations.
minor comments (3)
- [§2] §2, definition of the block-diagonal objective: the precise expression for the extracted block-diagonal part (in terms of the mode products and the chosen block sizes) should be written explicitly before the optimization problem is stated.
- [§4] §4, Gauss-Seidel update rules: the subproblem solved at each step (maximization over a single orthogonal factor while others are fixed) should be accompanied by a short derivation showing it reduces to a Procrustes-type problem or equivalent.
- [Numerical experiments] Numerical section: the tables reporting iteration counts and objective values should include a column for the final stationarity measure (e.g., norm of the projected gradient) to make the convergence claim directly verifiable from the experiments.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the accurate summary of the PTBD formulation and NPDo approach, and the recommendation for minor revision. We are pleased that the global convergence result on the product of Stiefel manifolds, the recovery of Tucker decomposition and approximate tensor SVD as special cases, and the numerical illustrations are viewed as strengths.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper defines the PTBD problem as maximizing the block-diagonal part of a tensor under orthonormal mode multiplications, then proposes the NPDo algorithm with Gauss-Seidel updates. The global convergence to a stationary point is established via a standard monotonicity argument (objective non-decreasing) combined with compactness of the product of Stiefel manifolds and continuity of the objective; this is independent of the input data and does not reduce to a fitted parameter or self-referential definition. Special cases (Tucker decomposition for single block, dominant tensor SVD for 1x1 blocks) are recovered as direct substitutions into the same objective, which is verification rather than circular forcing. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear in the central claims. The derivation is self-contained against external benchmarks of block-diagonal approximation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Orthonormal mode multiplications preserve the Frobenius norm of the tensor
Reference graph
Works this paper leans on
- [1]
-
[2]
G. Ballard and . G. Kolda. Tensor Decompositions for Data Science . Cambridge University Press, 2025
work page 2025
- [3]
-
[4]
J. Chen and Y. Saad. On the tensor SVD and the optimal low rank o rthogonal approximation of tensors. SIAM J. Matrix Anal. Appl. , 30(4):1709–1734, 2009
work page 2009
-
[5]
L. De Lathauwer. Decompositions of a higher-order tensor in blo ck terms – Part I: Lemmas for partitioned matrices. SIAM J. Matrix Anal. Appl. , 30(3):1022–1032, 2008
work page 2008
-
[6]
L. De Lathauwer. Decompositions of a higher-order tensor in blo ck terms – Part II: Definitions and uniqueness. SIAM J. Matrix Anal. Appl. , 30(3):1033–1066, 2008
work page 2008
-
[7]
L. De Lathauwer, B. De Moor, and J. Vandewalle. On the best ran k-1 and rank-( r1, r 2, . . . , r n) approximation of higher-order tensors. SIAM J. Matrix Anal. Appl. , 21(4):1324–1342, 2000
work page 2000
-
[8]
De Lathauwer, Bart De Moor, and Joos Vandewalle
L. De Lathauwer, Bart De Moor, and Joos Vandewalle. A multilinear singular value decom- position. SIAM J. Matrix Anal. Appl. , 21(4):1253–1278, 2000
work page 2000
-
[9]
L. De Lathauwer and D. Nion. Decompositions of a higher-order t ensor in block terms – Part III: Alternating least squares algorithms. SIAM J. Matrix Anal. Appl. , 30(3):1067–1083, 2008
work page 2008
-
[10]
J. Demmel. Applied Numerical Linear Algebra . SIAM, Philadelphia, PA, 1997
work page 1997
-
[11]
L. Eld´ en. Matrix Methods in Data Mining and Pattern Recognition . SIAM, Philadelphia, 2007
work page 2007
-
[12]
G. H. Golub and C. F. Van Loan. Matrix Computations . Johns Hopkins University Press, Baltimore, Maryland, 4th edition, 2013
work page 2013
-
[13]
N. J. Higham. Functions of Matrices: Theory and Computation . SIAM, Philadelphia, PA, USA, 2008
work page 2008
-
[14]
C. Kanzow and H.-D. Qi. A QP-free constrained Newton-type me thod for variational inequal- ity problems. Math. Program., 85:81–106, 1999
work page 1999
-
[15]
E. Kofidis and P. A. Regalia. On the best rank-1 approximation of higher-order supersym- metric tensors. SIAM J. Matrix Anal. Appl. , 23(3):863–884, 2002
work page 2002
-
[16]
T. G. Kolda and B. W. Bader. Tensor decompositions and applicat ions. SIAM Rev., 51(3):455– 500, 2009
work page 2009
-
[17]
R.-C. Li. A perturbation bound for the generalized polar decomp osition. BIT, 33:304–308, 1993
work page 1993
-
[18]
R.-C. Li. New perturbation bounds for the unitary polar factor . SIAM J. Matrix Anal. Appl. , 16:327–332, 1995
work page 1995
-
[19]
R.-C. Li. Matrix perturbation theory. In L. Hogben, R. Brualdi, and G. W. Stewart, editors, Handbook of Linear Algebra, page Chapter 21. CRC Press, Boca Raton, FL, 2nd edition, 2014. 32
work page 2014
- [20]
-
[21]
R.-C. Li. A theory of the NEPv approach for optimization on the S tiefel manifold. Found. Comput. Math. , 26:179–244, 2026
work page 2026
-
[22]
R.-C. Li, D. Lu, L. Wang, and L.-H. Zhang. An NPDo approach for principal joint block diagonalization. BIT Numer. Math. , 66(26), 2026
work page 2026
-
[23]
An NPDo Approach for Principal Joint SVD-type Block Diagonalization
R.-C. Li, Li Wang, and Mei Yang. An NPDo approach for principal joint SVD-type block diagonalization, May 2026. arXiv:2605.09202
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
D. Lu and R.-C. Li. Locally unitarily invariantizable NEPv and conver gence analysis of SCF. Math. Comp. , 93(349):2291–2329, 2024
work page 2024
-
[25]
J. Mor´ e and D. Sorensen. Computing a trust region step. SIAM J. Sci. Statist. Comput. , 4(3):553–572, 1983
work page 1983
-
[26]
G. W. Stewart and J.-G. Sun. Matrix Perturbation Theory . Academic Press, Boston, 1990
work page 1990
-
[27]
L. R. Tucker. Some mathematical notes on three-mode facto r analysis. Psychometrika, 31(3):279–311, 1966
work page 1966
-
[28]
L. Wang, L.-H. Zhang, and R.-C. Li. Maximizing sum of coupled trac es with applications. Numer. Math. , 152:587–629, 2022
work page 2022
-
[29]
T. Zhang and G. H. Golub. Rank-one approximation to high order tensors. SIAM J. Matrix Anal. Appl. , 23(2):534–550, 2001
work page 2001
-
[30]
Y. Zhou and R.-C. Li. Bounding the spectrum of large Hermitian ma trices. Linear Algebra Appl., 435:480–493, 2011. 33
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.