Recognition: 2 theorem links
· Lean TheoremFrom Instance Selection to Fixed-Pool Data Recipe Search for Supervised Fine-Tuning
Pith reviewed 2026-05-14 20:35 UTC · model grok-4.3
The pith
Recipe search over fixed instruction pools finds better supervised fine-tuning data than instance ranking or full-data training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AutoSelection, a two-layer solver, decouples fixed-pool materialization based on cached signals from expensive full evaluation by using warmup probes, realized subset states, local recipe edits, Gaussian-process-assisted ranking, and stagnation-triggered reseeding, and thereby discovers recipes whose resulting subsets yield stronger in-distribution reasoning performance than full-data training, random recipe search, random top-k, or single-operator selectors.
What carries the argument
Two-layer solver that materializes candidate subsets from cached task-data-model signals for rapid ranking and then refines executable operator sequences with local edits and Gaussian-process assistance under a limited budget of full SFT runs.
If this is right
- Recipe structure itself matters for final performance beyond the choice of any single operator, as shown by structural ablations.
- The discovered recipes transfer across model scales from 1.5B to 7B parameters while preserving the performance ordering.
- The same fixed-pool recipe approach produces measurable gains on out-of-distribution graph-reasoning tasks in addition to the in-distribution average.
- High-quality subsets can be obtained without generating, rewriting, or augmenting any new training examples.
Where Pith is reading between the lines
- The cached-signal layer could be reused across multiple downstream tasks or base models without retraining the ranking model from scratch.
- Extending the operator library with domain-specific filters would allow the same search machinery to target specialized data distributions such as code or math instruction sets.
Load-bearing premise
Cached task, data, and model signals plus warmup probes can reliably predict which recipes will perform well when the full supervised fine-tuning run is actually executed.
What would settle it
Running full SFT evaluations on the top recipes returned by AutoSelection and finding that their actual performance is no better than the performance of recipes found by random search under the same evaluation budget.
Figures




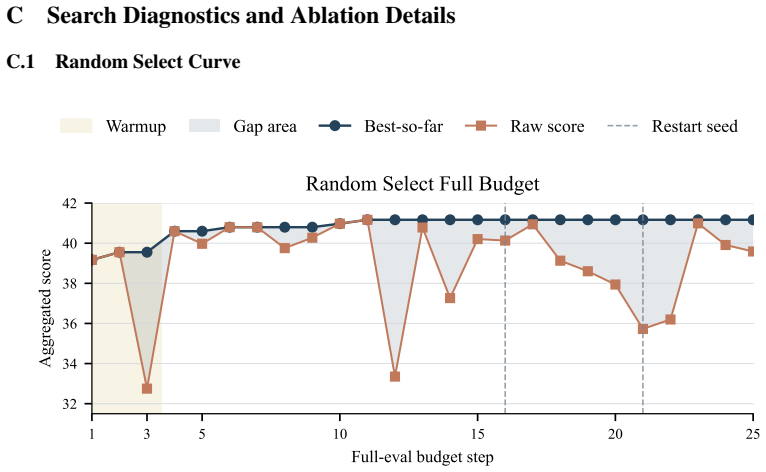
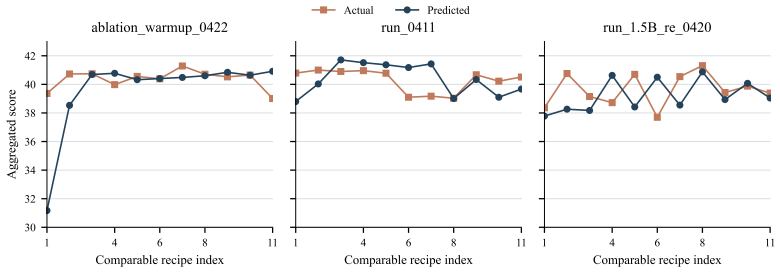

read the original abstract
Supervised fine-tuning (SFT) data selection is commonly formulated as instance ranking: score each example and retain a top-$k$ subset. However, effective SFT training subsets are often produced through ordered curation recipes, where filtering, mixing, and deduplication operators jointly shape the final data distribution. We formulate this problem as fixed-pool data recipe search: given a raw instruction pool and a library of grounded operators, the goal is to discover an executable recipe that constructs a high-quality selected subset under a limited budget of full SFT evaluations, without generating, rewriting, or augmenting training samples. We introduce AutoSelection, a two-layer solver that decouples fixed-pool materialization based on cached task-, data-, and model-side signals from expensive full evaluation, using warmup probes, realized subset states, local recipe edits, Gaussian-process-assisted ranking, and stagnation-triggered reseeding. Experiments on a 90K instruction pool show that AutoSelection achieves the strongest in-distribution reasoning average across three base models, outperforming full-data training, random recipe search, random top-$k$, and single-operator selectors. Additional Out-of-distribution graph-reasoning results, search-stability analyses, structural ablations, and 1.5B-to-7B transfer checks further show that recipe structure matters beyond individual selection operators. Code is available at https://github.com/w253/AutoSelection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes SFT data selection as fixed-pool recipe search over a library of grounded operators (filtering, mixing, deduplication) applied to a 90K instruction pool. AutoSelection is a two-layer solver that materializes subsets via cached task/data/model signals and limited warmup probes, then uses Gaussian-process ranking, local recipe edits, and stagnation reseeding to locate high-quality recipes under a tight budget of full SFT runs. Experiments report that AutoSelection yields the highest in-distribution reasoning average across three base models, outperforming full-data training, random recipe search, random top-k, and single-operator baselines; additional OOD graph-reasoning results, search-stability analyses, structural ablations, and 1.5B-to-7B transfer checks are presented, with code released.
Significance. If the proxy signals and warmup probes are shown to preserve ranking order with full SFT performance, the work meaningfully shifts the paradigm from instance-level ranking to structured recipe search, offering a practical route to better data curation with far fewer full evaluations. The provision of code and the empirical breadth across models and tasks are clear strengths that would support adoption if the proxy-to-full correlation is established.
major comments (2)
- [§5 and search-stability analyses] §5 (Results) and search-stability analyses: no direct quantification is given of the correlation between warmup-probe rankings and full SFT metrics across the three base models or reasoning tasks. Because the two-layer solver substitutes these proxies for exhaustive evaluation, this correlation is load-bearing for the claim that AutoSelection locates genuinely superior recipes rather than artifacts of the proxy objective.
- [Table 1 / in-distribution results] Table 1 / in-distribution reasoning results: the reported averages lack statistical significance tests, run-to-run variance, or explicit controls for post-hoc selection of the final recipe; without these, the claim of consistent outperformance over random recipe search and single-operator baselines cannot be fully assessed.
minor comments (1)
- [Method] Method section: the distinction between cached signals, realized subset states, and the exact form of the Gaussian-process surrogate could be illustrated with a short pseudocode block or diagram to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§5 and search-stability analyses] §5 (Results) and search-stability analyses: no direct quantification is given of the correlation between warmup-probe rankings and full SFT metrics across the three base models or reasoning tasks. Because the two-layer solver substitutes these proxies for exhaustive evaluation, this correlation is load-bearing for the claim that AutoSelection locates genuinely superior recipes rather than artifacts of the proxy objective.
Authors: We acknowledge that a direct quantification of the correlation between warmup-probe rankings and full SFT performance is not provided in the current manuscript. Our search-stability analyses show that the discovered recipes lead to strong performance, but to directly address this concern, we will add in the revised version explicit correlation metrics (such as Spearman rank correlation) computed across the three base models and tasks, using the available probe and full evaluation data from our experiments. This will help confirm that the proxy objective aligns with the true performance. revision: yes
-
Referee: [Table 1 / in-distribution results] Table 1 / in-distribution reasoning results: the reported averages lack statistical significance tests, run-to-run variance, or explicit controls for post-hoc selection of the final recipe; without these, the claim of consistent outperformance over random recipe search and single-operator baselines cannot be fully assessed.
Authors: We agree that including statistical significance and variance would strengthen the results. Due to the high computational cost of full SFT runs, our experiments used single evaluations per recipe within the budget. In the revision, we will report run-to-run variance from additional repeated runs on the top recipes where possible, include p-values from statistical tests comparing AutoSelection to baselines, and add a description of the recipe selection procedure to clarify that it follows the fixed budget and automated process without post-hoc cherry-picking. revision: yes
Circularity Check
No circularity: empirical search method with independent experimental validation
full rationale
The paper presents AutoSelection as a practical two-layer search algorithm that uses cached signals and limited warmup probes to rank recipes, followed by full SFT evaluations on discovered subsets. All central claims rest on direct empirical comparisons (in-distribution reasoning averages, OOD graph-reasoning, stability analyses, and transfer checks) against explicit baselines such as full-data training, random recipe search, and single-operator selectors. No equations, predictions, or uniqueness claims reduce by construction to fitted parameters or self-citations; the method is algorithmic rather than derivational, and code is released for external reproduction. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A library of grounded operators (filtering, mixing, deduplication) is sufficient to shape high-quality SFT data distributions
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formulate this problem as fixed-pool data recipe search: given a raw instruction pool and a library of grounded operators, the goal is to discover an executable recipe that constructs a high-quality selected subset under a limited budget of full SFT evaluations
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AutoSelection ... using warmup probes, realized subset states, local recipe edits, Gaussian-process-assisted ranking, and stagnation-triggered reseeding
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
2023
-
[2]
What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning
Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning. InThe Twelfth International Conference on Learning Representations
-
[3]
Data-juicer: A one-stop data processing system for large language models
Daoyuan Chen, Yilun Huang, Zhijian Ma, Hesen Chen, Xuchen Pan, Ce Ge, Dawei Gao, Yuexiang Xie, Zhaoyang Liu, Jinyang Gao, et al. Data-juicer: A one-stop data processing system for large language models. InCompanion of the 2024 International Conference on Management of Data, pages 120–134, 2024
2024
-
[4]
LESS: Selecting influential data for targeted instruction tuning
Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen. LESS: Selecting influential data for targeted instruction tuning. InForty-first International Conference on Machine Learning, 2024. URLhttps://openreview.net/forum?id=PG5fV50maR
2024
-
[5]
Task-specific data selection for instruction tuning via monosemantic neuronal activations
Da Ma, Gonghu Shang, Zhi Chen, Libo Qin, Yijie LUO, Hongshen Xu, Lei Pan, Shuai Fan, Kai Yu, and Lu Chen. Task-specific data selection for instruction tuning via monosemantic neuronal activations. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[6]
Lead: iterative data selection for efficient llm instruction tuning.Proceedings of the VLDB Endowment, 19(3):426–439, 2025
Xiaotian Lin, Yanlin Qi, Yizhang Zhu, Themis Palpanas, Chengliang Chai, Nan Tang, and Yuyu Luo. Lead: iterative data selection for efficient llm instruction tuning.Proceedings of the VLDB Endowment, 19(3):426–439, 2025
2025
-
[7]
Yicheng Chen, Zerun Ma, Xinchen Xie, Yining Li, and Kai Chen. Datachef: Cooking up optimal data recipes for llm adaptation via reinforcement learning.arXiv preprint arXiv:2602.11089, 2026
-
[8]
LLM-AutoDP: Automatic Data Processing via LLM Agents for Model Fine-tuning
Wei Huang, Anda Cheng, Yinggui Wang, Lei Wang, and Tao Wei. Llm-autodp: Automatic data processing via LLM agents for model fine-tuning.arXiv preprint arXiv:2601.20375, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Evaluating data influence in meta learning.arXiv preprint arXiv:2501.15963, 2025
Chenyang Ren, Huanyi Xie, Shu Yang, Meng Ding, Lijie Hu, and Di Wang. Evaluating data influence in meta learning.arXiv preprint arXiv:2501.15963, 2025
-
[10]
From quantity to quality: Boosting LLM performance with self-guided data selection for instruction tuning
Ming Li, Yong Zhang, Zhitao Li, Jiuhai Chen, Lichang Chen, Ning Cheng, Jianzong Wang, Tianyi Zhou, and Jing Xiao. From quantity to quality: Boosting LLM performance with self-guided data selection for instruction tuning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech...
2024
-
[11]
Deduplicating training data makes language mod- els better
Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language mod- els better. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8424–8445, 2022. 10
2022
- [12]
-
[13]
Data diversity matters for robust instruction tuning
Alexander Bukharin, Shiyang Li, Zhengyang Wang, Jingfeng Yang, Bing Yin, Xian Li, Chao Zhang, Tuo Zhao, and Haoming Jiang. Data diversity matters for robust instruction tuning. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3411–3425, 2024
2024
-
[14]
Automatic configuration of llm post-training pipelines
Channe Chwa, Xinle Wu, and Yao Lu. Automatic configuration of llm post-training pipelines. arXiv preprint arXiv:2603.18773, 2026
-
[15]
Random search for hyper-parameter optimization.Journal of machine learning research, 13(2), 2012
James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization.Journal of machine learning research, 13(2), 2012
2012
-
[16]
Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems, 25, 2012
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. Practical bayesian optimization of machine learning algorithms.Advances in neural information processing systems, 25, 2012
2012
-
[17]
Hy- perband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(185):1–52, 2018
Lisha Li, Kevin Jamieson, Giulia DeSalvo, Afshin Rostamizadeh, and Ameet Talwalkar. Hy- perband: A novel bandit-based approach to hyperparameter optimization.Journal of Machine Learning Research, 18(185):1–52, 2018. URL http://jmlr.org/papers/v18/16-558. html
2018
-
[18]
BOHB: Robust and efficient hyperparameter optimization at scale
Stefan Falkner, Aaron Klein, and Frank Hutter. BOHB: Robust and efficient hyperparameter optimization at scale. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1437–1446. PMLR, 10–15 Jul 2018. URL https://proceedings.mlr. press/v80/...
2018
-
[19]
Efficient and robust automated machine learning
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springenberg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors,Advances in Neural Information Processing Sys- tems, volume 28. Curran Associates, Inc., 2015. URL https://proceedings.neurips.cc/ p...
2015
-
[20]
Limit: Less is more for instruction tuning across evaluation paradigms
Aditi Jha, Sam Havens, Jeremy Dohmann, Alexander Trott, and Jacob Portes. Limit: Less is more for instruction tuning across evaluation paradigms. InNeurIPS 2023 Workshop on Instruction Tuning and Instruction Following
2023
-
[22]
Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants, 2023
Teknium. Openhermes 2.5: An open dataset of synthetic data for generalist llm assistants, 2023. URLhttps://huggingface.co/datasets/teknium/OpenHermes-2.5
2023
-
[23]
Self-instruct: Aligning language models with self-generated instruc- tions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
2023
-
[24]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
2024
-
[25]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
Brown, et al
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=uyTL5Bvosj. Featured Certifica- tion. 11
2023
-
[27]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=d7KBjmI3GmQ
2021
-
[28]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, et al. Qwen2.5 technical report, 2025. URLhttps://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Aaron Grattafiori, Abhimanyu Dubey, et al. The llama 3 herd of models, 2024. URL https: //arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Graphwiz: An instruction-following language model for graph computational problems
Nuo Chen, Yuhan Li, Jianheng Tang, and Jia Li. Graphwiz: An instruction-following language model for graph computational problems. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 353–364, 2024
2024
-
[31]
Can language models solve graph problems in natural language?Advances in Neural Informa- tion Processing Systems, 36:30840–30861, 2023
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural language?Advances in Neural Informa- tion Processing Systems, 36:30840–30861, 2023
2023
-
[32]
Ioannis Kontoyiannis and Sergio Verdú. Optimal lossless data compression: Non-asymptotics and asymptotics.IEEE Transactions on Information Theory, 60(2):777–795, 2014. doi: 10.1109/TIT.2013.2291007
-
[33]
A new generalized varentropy and its properties
Saeid Maadani, Gholam Reza Mohtashami Borzadaran, and Abdolhamid Rezaei Roknabadi. A new generalized varentropy and its properties. 2020. URL https://api.semanticscholar. org/CorpusID:225604868
2020
-
[34]
Exploring iterative controllable summarization with large language models
Xianzhi Li, Ethan Callanan, Abdellah Ghassel, and Xiaodan Zhu. Entropy-gated branching for efficient test-time reasoning. In Vera Demberg, Kentaro Inui, and Lluís Marquez, editors, Proceedings of the 19th Conference of the European Chapter of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 5054–5069, Rabat, Morocco, March 20...
-
[35]
Rethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Yuhang He, Haodong Wu, Siyi Liu, Hongyu Ge, Hange Zhou, Keyi Wu, Zhuo Zheng, Qihong Lin, Zixin Zhong, and Yongqi Zhang. Rethinking token-level credit assignment in rlvr: A polarity-entropy analysis.arXiv preprint arXiv:2604.11056, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Claude E. Shannon. A mathematical theory of communication.Bell Syst. Tech. J., 27:623–656,
-
[37]
URLhttps://api.semanticscholar.org/CorpusID:55379485
-
[38]
The best of both worlds: Bridging quality and diversity in data selection with bipartite graph
Minghao Wu, Thuy-Trang Vu, Lizhen Qu, and Gholamreza Haffari. The best of both worlds: Bridging quality and diversity in data selection with bipartite graph. InForty-second Inter- national Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=nCoaJYNCcg
2025
-
[39]
A preliminary study of the intrinsic relationship between complexity and alignment
Yingxiu Zhao, Bowen Yu, Binyuan Hui, Haiyang Yu, Fei Huang, Yongbin Li, and Nevin L Zhang. A preliminary study of the intrinsic relationship between complexity and alignment. arXiv preprint arXiv:2308.05696, 2023
-
[40]
Chasing random: Instruction selection strategies fail to generalize
Harshita Diddee and Daphne Ippolito. Chasing random: Instruction selection strategies fail to generalize. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1943–1957, 2025
2025
-
[41]
Large-scale data selection for instruction tuning.arXiv preprint arXiv:2503.01807, 2025
Hamish Ivison, Muru Zhang, Faeze Brahman, Pang Wei Koh, and Pradeep Dasigi. Large-scale data selection for instruction tuning.arXiv preprint arXiv:2503.01807, 2025
-
[42]
A critical look at targeted instruction selection: Disentangling what matters (and what doesn’t)
Nihal V Nayak, Paula Rodriguez-Diaz, Neha Hulkund, Sara Beery, and David Alvarez-Melis. A critical look at targeted instruction selection: Disentangling what matters (and what doesn’t). arXiv preprint arXiv:2602.14696, 2026. 12
-
[43]
Dheeraj Mekala, Alex Nguyen, and Jingbo Shang. Smaller language models are capable of selecting instruction-tuning training data for larger language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 10456–10470, Bangkok, Thailand, August 2024. Association for Comput...
-
[44]
Yu Yang, Siddhartha Mishra, Jeffrey Chiang, and Baharan Mirzasoleiman. Smalltolarge (s2l): Scalable data selection for fine-tuning large language models by summarizing train- ing trajectories of small models. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, v...
-
[45]
Doremi: Optimiz- ing data mixtures speeds up language model pretraining
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. Doremi: Optimiz- ing data mixtures speeds up language model pretraining. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 69798–6...
2023
-
[46]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Sparse autoencoders find highly interpretable features in language models
Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum? id=F76bwRSLeK. 13 A Experimental Protocol and Operator Details A.1 Operator Library Table 4 s...
2024
-
[48]
We group the fields into task, data, and model components, z(S) = ztask(S);z data(S);z model(S) . Table 8 lists the fields used in our search. SNAR denotes sparse-neuron activation rate. Table 8: State-vector fields used to summarize an executed candidate subset. Group Field Computation Meaning Task score_meanmean x,b sb(x)overEAverage MONA task relevance...
-
[49]
A specific observation (not vague)
-
[50]
Backed by data from the table
-
[51]
Be direct and quantitative
Actionable (suggests what to try or avoid) Format each finding as a numbered line. Be direct and quantitative. These are HYPOTHESES based on limited data, not proven facts. Example format:
-
[52]
Avoid aggressive filtering
More data consistently helps: recipe_A (12K samples, 22.2%) > recipe_C (3K samples, 18.5%). Avoid aggressive filtering
-
[53]
Try higher rates or skip it
operator_X at rate 0.3 hurts benchmark_Y: recipe_B dropped from 15% to 0.9%. Try higher rates or skip it. Listing 2: Proposer prompt template. You are an expert Data-Centric AI Search Controller optimizing a data recipe. YOUR GOAL: Propose {n_candidates} DISTINCT mutated recipe configurations that resolve current risks and explore different valid subspace...
-
[54]
Analyze the current recipe, state vector, and search history
-
[55]
Select operators and hyperparameters ONLY from the OPERATOR CATALOG
-
[56]
Do NOT include markdown blocks (‘ ‘‘‘json ‘), just raw JSON
Your output MUST be a valid JSON array of objects representing the {n_candidates} recipes. Do NOT include markdown blocks (‘ ‘‘‘json ‘), just raw JSON
-
[57]
steps": [ {
Format: [ { "steps": [ { "operator": "operator_name", "params": {"param1": "value", "param2": 123} 29 } ] }, ... (up to {n_candidates} distinct configurations) ] Listing 3: Ranker prompt template. You are a strategic advisor for an automated data selection search system. Your task is to select the SINGLE most promising candidate recipe for real evaluation...
-
[58]
- A candidate whose per-task MONA scores improve across multiple benchmarks is a strong positive signal, even if retain_ratio drops
Per-Task MONA Scores (PRIMARY SIGNAL): - score_per_task shows how relevant the selected subset is to each benchmark. - A candidate whose per-task MONA scores improve across multiple benchmarks is a strong positive signal, even if retain_ratio drops. - Compare each candidate’s score_per_task against the parent’s and look for improvements on weak benchmarks...
-
[59]
- Late search: prefer high mu candidates to refine the best
Exploration vs Exploitation Trade-off: - Early search: prefer high sigma candidates to gather information. - Late search: prefer high mu candidates to refine the best. - Current phase: {phase}
-
[60]
- Historical evidence shows extreme filtering often fails catastrophically
Data Quantity Risk: - Recipes that aggressively filter data risk producing too few samples. - Historical evidence shows extreme filtering often fails catastrophically. - Union operators can recover data volume and are safer exploration choices. - Refer to the per-benchmark history to see how sample count correlates with each benchmark
-
[61]
- Operators from the same family are often redundant
Operator Synergies and Redundancy: - Multiple filtering operators in sequence compound data loss multiplicatively. - Operators from the same family are often redundant. - Complementary operators tend to work well together
-
[62]
Feedback Alignment: - Does this candidate address the patterns identified in evaluation insights? - Does it avoid strategies that have been shown to fail?
-
[63]
- High distribution_drift indicates risky distributional shift
State Vector Patterns: - High retain_ratio with good score_mean tends to perform well. - High distribution_drift indicates risky distributional shift. - The parent’s state vector shows the data profile that candidates will modify
-
[64]
ranking": [<best_idx>, <2nd_idx>, ..., <worst_idx>],
GP Model Limitations: - The GP has only {n_iterations} training points, so predictions carry uncertainty. - Do not blindly trust GP rankings, especially when scores are close. - Qualitative reasoning about operator interactions can add value beyond the GP. ## OUTPUT FORMAT After thorough reasoning, output a full ranking of all presented candidates as a JS...
-
[65]
Select only operators from the allowed catalog above
-
[66]
Prefer operators and combinations supported by the evidence
-
[67]
Keep parameters within catalog bounds
-
[68]
operator
Return raw JSON only in this exact format: [ {"operator": "mona_filter", "params": {"fraction": 0.5}}, {"operator": "ngram_entropy", "params": {"fraction": 0.4}} ] Pool size reference: [POOL_SIZE] E.2 Benchmark evaluation prompts The validation suite uses GPQA, GSM8K, BBH, and MMLU. Listing 5: GPQA evaluation prompt scaffold. System: You are an expert ass...
-
[71]
Respond with ONLY the letter of the correct answer (A, B, C, or D) on the last line
-
[72]
Example format: [Your reasoning] Answer: B Few-shot turns: User: Question: Which of the following is NOT a function of the cell membrane? A
Format: put your final answer after "Answer:" on the last line. Example format: [Your reasoning] Answer: B Few-shot turns: User: Question: Which of the following is NOT a function of the cell membrane? A. Selective permeability B. Protein synthesis C. Cell signaling D. Cell adhesion Assistant: The cell membrane has multiple functions including selective p...
-
[73]
Think through the problem carefully
-
[74]
Example format: [Your reasoning] Answer: (B) Few-shot turns: User: not ( True ) and ( True ) is Assistant: not ( True ) evaluates to False
On the last line, write your final answer after "Answer:" exactly matching the expected format. Example format: [Your reasoning] Answer: (B) Few-shot turns: User: not ( True ) and ( True ) is Assistant: not ( True ) evaluates to False. False and ( True ) evaluates to False. Answer: False User: In the following sentences, explain the antecedent of the pron...
-
[75]
Read the question carefully
-
[76]
Consider each option
-
[77]
Example format: [Your reasoning] Answer: B Few-shot turns: User: Question: What is the capital of France? A
Respond with your reasoning, then provide the letter of the correct answer after "Answer:" on the last line. Example format: [Your reasoning] Answer: B Few-shot turns: User: Question: What is the capital of France? A. London B. Berlin C. Paris D. Madrid Assistant: Paris is the capital and largest city of France. Answer: C User: Question: Which planet is k...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.