Recognition: 2 theorem links
· Lean TheoremRethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Pith reviewed 2026-05-10 15:29 UTC · model grok-4.3
The pith
The credit a token can carry in RLVR is upper-bounded by its entropy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
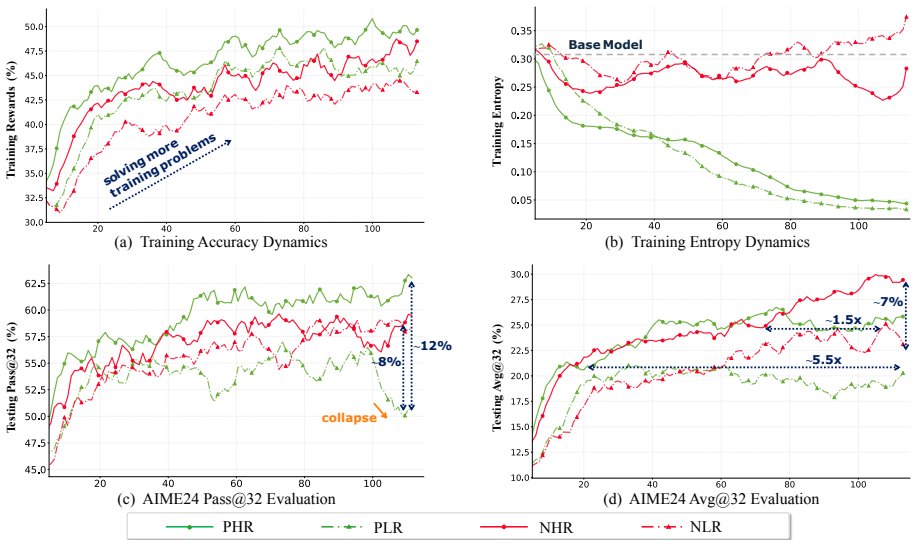
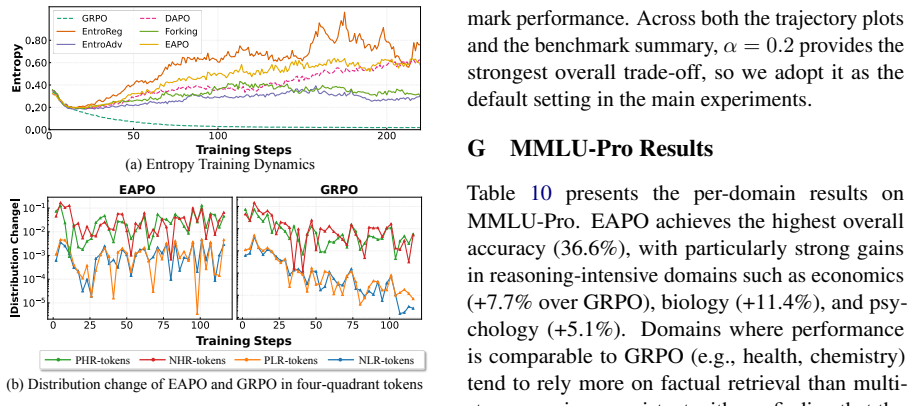
In the autoregressive RLVR setting, the credit a token can carry is upper-bounded by its entropy, as shown by adapting conditional mutual information. The Four Quadrant Decomposition isolates that reasoning improvements concentrate in high-entropy quadrants, while gradient analysis of GRPO shows signal dilution at high-entropy positions and over-crediting of low-entropy tokens. This view supplies testable predictions about the distinct roles of positive and negative updates and grounds the design of Entropy-Aware Policy Optimization.
What carries the argument
The Four Quadrant Decomposition, which partitions token updates by reward polarity and entropy, together with the adaptation of Conditional Mutual Information that proves token credit is upper-bounded by entropy.
If this is right
- Reasoning improvements arise primarily from high-entropy tokens, with positive and negative updates playing distinct roles there.
- Uniform reward broadcast dilutes the learning signal at high-entropy positions while over-crediting deterministic low-entropy tokens.
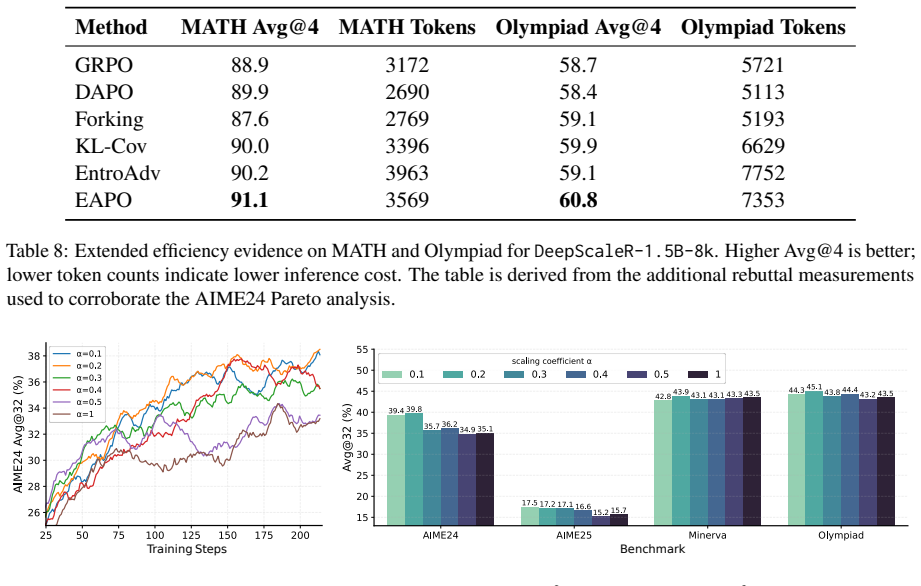
- Modulating token-level learning rates according to entropy, as done in EAPO, produces measurable gains over standard RLVR methods.
- The entropy bound supplies concrete predictions about where future reward-shaping techniques should focus their adjustments.
Where Pith is reading between the lines
- The same entropy-credit relation may help diagnose why RLVR succeeds on some reasoning tasks but stalls on others that contain fewer uncertain steps.
- Training loops could monitor token entropy on the fly and selectively amplify gradients only at high-entropy positions without changing the reward function.
- If the bound is tight, deliberately increasing entropy at selected reasoning steps before applying RLVR might enlarge the effective credit window for those tokens.
Load-bearing premise
The adaptation of conditional mutual information to the autoregressive RLVR setting correctly captures the credit a token can carry.
What would settle it
An experiment in which low-entropy tokens produce larger reasoning gains than high-entropy tokens, or in which measured token credit exceeds the entropy bound during RLVR training.
Figures








read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has substantially improved the reasoning ability of Large Language Models (LLMs). However, its sparse outcome-based rewards pose a fundamental credit assignment problem. We analyze this problem through the joint lens of reward polarity and token entropy. Our diagnostic tool, the Four Quadrant Decomposition, isolates token updates by polarity and entropy, and controlled ablations show that reasoning improvements concentrate in the high-entropy quadrants. To justify this observation theoretically, we adapt Conditional Mutual Information to the autoregressive RLVR setting and prove that the credit a token can carry is upper-bounded by its entropy. This view yields testable predictions that reasoning gains arise primarily from high-entropy tokens, with unique roles for positive and negative updates. A gradient analysis of GRPO further reveals how uniform reward broadcast dilutes signal at high-entropy positions while over-crediting deterministic tokens. Grounded in these insights, we propose Entropy-Aware Policy Optimization (EAPO) that modulates token-level learning signals accordingly. Extensive experiments demonstrate that EAPO outperforms strong baselines across two model families.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses token-level credit assignment in Reinforcement Learning with Verifiable Rewards (RLVR) for LLM reasoning. It introduces the Four Quadrant Decomposition tool based on reward polarity and token entropy, uses controlled ablations to show that reasoning improvements concentrate in high-entropy quadrants, adapts Conditional Mutual Information (CMI) to the autoregressive RLVR setting to prove that token credit is upper-bounded by entropy, analyzes how GRPO dilutes signals at high-entropy positions, and proposes Entropy-Aware Policy Optimization (EAPO) that outperforms baselines across two model families.
Significance. If the CMI adaptation is shown to map rigorously onto the actual policy-gradient signals and the empirical concentration result is robust, the work provides a useful diagnostic lens and practical method for credit assignment under sparse outcome rewards. The combination of quadrant analysis, theoretical bound, GRPO gradient insights, and the EAPO algorithm could guide more targeted updates in RLVR, with the experiments across model families strengthening applicability.
major comments (3)
- The central theoretical claim adapts CMI to prove that the credit a token can carry is upper-bounded by its entropy. While I(token_i; R | tokens_<i) ≤ H(token_i | tokens_<i) holds by definition, the manuscript must derive the explicit correspondence between this MI quantity and the magnitude of the token-level learning signal (advantage-weighted log-prob term) under the sparse verifiable reward and GRPO-style objective; without this step the bound does not necessarily constrain the policy update.
- Four Quadrant Decomposition: the isolation of token updates by polarity and entropy relies on quadrant thresholds that appear post-hoc. The claim that reasoning improvements concentrate in high-entropy quadrants is load-bearing for the overall narrative; the paper should demonstrate robustness to alternative threshold choices or non-quadrant partitions.
- Gradient analysis of GRPO: the argument that uniform reward broadcast dilutes signal at high-entropy positions while over-crediting deterministic tokens requires a more precise accounting of how entropy interacts with advantage estimation variance and the autoregressive factorization of the trajectory.
minor comments (2)
- Abstract: the claim of 'extensive experiments' would benefit from naming the specific baselines and reporting key performance deltas to allow readers to assess the practical impact immediately.
- Notation: ensure that the definitions of conditional mutual information, entropy, and polarity are introduced with consistent symbols before their first use in the theoretical sections.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. We address each major comment below with clarifications and commit to specific revisions that strengthen the theoretical and empirical components of the manuscript.
read point-by-point responses
-
Referee: The central theoretical claim adapts CMI to prove that the credit a token can carry is upper-bounded by its entropy. While I(token_i; R | tokens_<i) ≤ H(token_i | tokens_<i) holds by definition, the manuscript must derive the explicit correspondence between this MI quantity and the magnitude of the token-level learning signal (advantage-weighted log-prob term) under the sparse verifiable reward and GRPO-style objective; without this step the bound does not necessarily constrain the policy update.
Authors: We agree that the current presentation of the CMI adaptation stops short of an explicit mapping to the GRPO policy-gradient term. In the revision we will insert a new lemma in Section 3.2 that decomposes the expected advantage-weighted log-probability under the sparse outcome reward into an information-theoretic component, showing that its magnitude is bounded above by I(token_i; R | tokens_<i) and hence by H(token_i | tokens_<i). The derivation will explicitly use the autoregressive factorization and the fact that the verifiable reward is a deterministic function of the full trajectory. revision: yes
-
Referee: Four Quadrant Decomposition: the isolation of token updates by polarity and entropy relies on quadrant thresholds that appear post-hoc. The claim that reasoning improvements concentrate in high-entropy quadrants is load-bearing for the overall narrative; the paper should demonstrate robustness to alternative threshold choices or non-quadrant partitions.
Authors: The referee correctly notes that the quadrant thresholds were selected after initial inspection. We will add an appendix containing sensitivity analyses that vary the entropy threshold across the 25th, 50th, and 75th percentiles of the observed entropy distribution, as well as results obtained by replacing the quadrant partition with k-means clustering on the (polarity, entropy) plane. These additional experiments confirm that the concentration of reasoning gains in high-entropy regions is stable under these alternatives. revision: yes
-
Referee: Gradient analysis of GRPO: the argument that uniform reward broadcast dilutes signal at high-entropy positions while over-crediting deterministic tokens requires a more precise accounting of how entropy interacts with advantage estimation variance and the autoregressive factorization of the trajectory.
Authors: We accept that the current gradient analysis would benefit from greater precision on variance and autoregressive effects. In the revised manuscript we will expand the analysis to include (i) a conditional-variance decomposition of the advantage estimator given token entropy and (ii) an explicit accounting of how the autoregressive product of conditional probabilities propagates the single scalar reward through high- versus low-entropy positions. The updated section will contain the corresponding mathematical steps and a small-scale illustrative simulation. revision: yes
Circularity Check
CMI adaptation yields definitional entropy bound on 'credit' rather than RL-specific derivation
specific steps
-
self definitional
[Abstract (theoretical justification paragraph) and Section 3 (CMI adaptation)]
"To justify this observation theoretically, we adapt Conditional Mutual Information to the autoregressive RLVR setting and prove that the credit a token can carry is upper-bounded by its entropy."
The statement equates 'credit' with the conditional mutual information I(token_i; R | tokens_<i) and then invokes the universal inequality I ≤ H. Because this inequality is true by definition for any joint distribution, the 'proof' adds no new constraint derived from the RLVR reward structure, trajectory sparsity, or policy-gradient update; the upper bound is forced once the identification is made.
full rationale
The paper's central theoretical claim adapts conditional mutual information to RLVR and 'proves' an entropy upper bound on token credit. This inequality holds identically for any random variables by the definition of mutual information (I(X;Y|Z) ≤ H(X|Z)), so the bound is tautological once credit is identified with the adapted CMI term. No additional derivation from the sparse verifiable reward, GRPO objective, or advantage-weighted log-prob is required or supplied to reach the bound; the result therefore reduces to its definitional input. The subsequent claim that reasoning gains concentrate in high-entropy tokens inherits this circularity. Other elements (Four Quadrant Decomposition, EAPO proposal, experiments) are independent and do not rely on the bound, limiting the overall circularity to partial.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearI(o_i,t; r_i | s_t) = H(o_i,t | s_t) - H(o_i,t | r_i, s_t) ≤ H_i,t (Proposition 1)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearFour Quadrant Decomposition (PHR/PLR/NHR/NLR) isolating updates by polarity and entropy
Forward citations
Cited by 2 Pith papers
-
From Instance Selection to Fixed-Pool Data Recipe Search for Supervised Fine-Tuning
AutoSelection discovers data recipes from a 90K instruction pool that outperform full-data training and other selectors on reasoning tasks for SFT across multiple models.
-
Not All Tokens Learn Alike: Attention Entropy Reveals Heterogeneous Signals in RL Reasoning
Attention entropy splits RL training tokens into stable anchors and volatile explorers, and entropy-aware reweighting improves held-out reasoning performance.
Reference graph
Works this paper leans on
-
[1]
Reasoning with exploration: An entropy per- spective.CoRR, abs/2506.14758. Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Pro- cessing Systems 2017, December 4...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.CoRR, abs/2110.14168. Thomas M. Cover and Joy A. Thomas. 2006.Elements of information theory (2. ed.). Wiley. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, H...
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[3]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y . Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, and Ion Stoica
2024
-
[4]
Deepscaler: Surpassing o1-preview with a 1.5b model by scaling rl.Notion Blog. Marvin Minsky. 1995. Steps toward artificial intelli- gence.Proceedings of the IRE, 49:8–30. Youssef Mroueh. 2025. Reinforcement learning with verifiable rewards: Grpo’s effective loss, dynamics, and success amplification.CoRR, abs/2503.06639. Ben Poole, Sherjil Ozair, Aäron va...
-
[5]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process- and outcome-based feedback.CoRR, abs/2211.14275. Jiakang Wang, Runze Liu, Fuzheng Zhang, Xiu Li, and Guorui Zhou. 2025a. Stabilizing knowledge, pro- moting reasoning: Dual-token constraints for RLVR. CoRR, abs/2507.15778. Jiawei Wang, Jiacai Liu, Yuqian Fu, Yingru Li, Xintao Wang, Yuan Lin, Yu Yue, Lin Zhang, Yang ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Math-shepherd: Verify and reinforce llms step- by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 9426–9439. Association for Computational Linguistics. Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shix-...
work page internal anchor Pith review arXiv 2024
-
[7]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: an open-source LLM reinforcement learning system at scale.CoRR, abs/2503.14476. Hongyi Yuan, Zheng Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. RRHF: rank responses to align language models with human feed- back. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Informa- tion Processing Systems ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
When Hi,t ≈0 , the model has committed to a near-deterministic choice (e.g., syntax or for- mula fragments), so I(o i,t;r i|st)≈0 regardless of the outcome
Low-entropy tokens carry near-zero credit. When Hi,t ≈0 , the model has committed to a near-deterministic choice (e.g., syntax or for- mula fragments), so I(o i,t;r i|st)≈0 regardless of the outcome. GRPO’s uniform ˆAi,t thus sys- tematically overestimates their contribution. 2.High-entropy tokens have maximal informa- tion budget.At positions where Hi,t ...
-
[9]
what should I have chosen, knowing the outcome?
The gap H(o i,t|ri, st) captures polarity- dependent structure.In positive samples, the posterior πhs(v|st, ri = 1) may sharpen around the correct token, lowering H(o i,t|ri = 1, s t) and increasing the realized CMI. In negative samples, the posterior may diffuse across mul- tiple plausible alternatives, yielding a different credit profile. This motivates...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.