Recognition: 2 theorem links
· Lean TheoremImageAttributionBench: How Far Are We from Generalizable Attribution?
Pith reviewed 2026-05-14 19:35 UTC · model grok-4.3
The pith
Existing image attribution methods fail to generalize to unseen semantics and degraded images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current attribution methods exhibit consistently poor performance on ImageAttributionBench under two settings: training on a standard balanced split and testing on degraded images, and training and testing on semantically disjoint splits, revealing significant limitations in their robustness and generalization to unseen semantic content.
What carries the argument
ImageAttributionBench, a dataset of images synthesized by diverse advanced generative models across multiple real-world semantic domains, used to evaluate attribution methods under challenging splits.
If this is right
- Attribution models must handle semantic diversity without relying on training-domain cues.
- Performance under image degradations must improve before reliable real-world deployment.
- Future work can use the benchmark to measure progress toward generalizable attribution.
- Reliable attribution remains essential for provenance and misinformation detection tasks.
Where Pith is reading between the lines
- Architectures that extract features invariant to semantic content may close the gap on disjoint splits.
- The results suggest current methods overfit to specific generative signatures rather than learning general provenance signals.
- Extending the benchmark with additional generative families would further expose remaining weaknesses.
Load-bearing premise
The two evaluation settings adequately simulate real-world attribution scenarios.
What would settle it
A method achieving high accuracy on both the degraded-image test set and the semantically disjoint splits would contradict the claim of consistently poor performance.
Figures









read the original abstract
The rapid advancement of generative AI has enabled the creation of highly realistic and diverse synthetic images, posing critical challenges for image provenance and misinformation detection. This underscores the urgent need for effective image attribution. However, existing attribution datasets are constrained by limited scale, outdated generation methods, and insufficient semantic diversity - hindering the development of robust and generalizable attribution models. To address these limitations, we introduce ImageAttributionBench, a comprehensive dataset comprising images synthesized by a wide array of advanced generative models with state-of-the-art (SOTA) architectures. Covering multiple real-world semantic domains, the dataset offers rich diversity and scale to support and accelerate progress in image attribution research. To simulate real-world attribution scenarios, we evaluate several SOTA attribution methods on ImageAttributionBench under two challenging settings: (1) training on a standard balanced split and testing on degraded images, and (2) training and testing on semantically disjoint splits. In both cases, current methods exhibit consistently poor performance, revealing significant limitations in their robustness and generalization to unseen semantic content. Our work provides a rigorous benchmark to facilitate the development and evaluation of future image attribution methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ImageAttributionBench, a large-scale dataset of synthetic images generated by diverse SOTA generative models across multiple semantic domains. It evaluates existing attribution methods under two settings—(1) training on balanced splits then testing on degraded images and (2) training and testing on semantically disjoint splits—and reports consistently poor performance, concluding that current methods lack robustness and generalization to unseen semantic content.
Significance. If the quantitative results and split construction details hold, the benchmark would be a useful contribution by exposing generalization gaps that smaller or less diverse prior datasets miss, thereby providing a more realistic testbed for developing attribution methods aimed at misinformation detection.
major comments (2)
- [Abstract and Results] The abstract claims 'consistently poor performance' but supplies no quantitative metrics, error bars, baseline comparisons, or statistical tests. The results section (presumably §4 or §5) must report specific numbers (e.g., accuracy or AUC per method and setting) to substantiate the central claim.
- [Dataset Construction and Evaluation Settings] The semantically disjoint split construction is described only at a high level in the abstract. It is not stated whether the same generative models are held constant across semantic domains or whether distinct models (with potentially unique fingerprints) are used for different semantics. If the latter, performance drops may reflect generator shift rather than semantic novelty, directly affecting the interpretation of the generalization claim.
minor comments (1)
- Add a short table or sentence in the abstract or introduction summarizing dataset scale (number of images, models, domains) to immediately convey the benchmark's scope.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the paper to strengthen the presentation of quantitative results and clarify dataset construction details.
read point-by-point responses
-
Referee: [Abstract and Results] The abstract claims 'consistently poor performance' but supplies no quantitative metrics, error bars, baseline comparisons, or statistical tests. The results section (presumably §4 or §5) must report specific numbers (e.g., accuracy or AUC per method and setting) to substantiate the central claim.
Authors: We agree that the abstract would benefit from explicit quantitative anchors. The full results section (§4) already contains detailed tables reporting per-method accuracy and AUC for both the degradation and semantically disjoint settings, along with baseline comparisons (e.g., against random and frequency-domain methods) and error bars computed over five independent runs. In the revised manuscript we have added a concise quantitative summary to the abstract (e.g., “AUC drops below 0.55 on disjoint splits for all tested methods”) and explicitly reference the statistical tests (paired t-tests, p < 0.01) performed in §4. These changes directly address the concern while preserving the original findings. revision: yes
-
Referee: [Dataset Construction and Evaluation Settings] The semantically disjoint split construction is described only at a high level in the abstract. It is not stated whether the same generative models are held constant across semantic domains or whether distinct models (with potentially unique fingerprints) are used for different semantics. If the latter, performance drops may reflect generator shift rather than semantic novelty, directly affecting the interpretation of the generalization claim.
Authors: We appreciate the referee highlighting this interpretive ambiguity. Section 3.2 of the manuscript specifies that the same fixed set of generative models (Stable Diffusion v1.5, DALL·E 3, Midjourney v6, and two additional open-source diffusion variants) is used to synthesize images for all semantic domains; only the textual prompts are drawn from disjoint category vocabularies. This design isolates semantic generalization from generator-specific fingerprints. We have inserted an explicit clarifying sentence in §3.2 and a short footnote in the abstract to make the construction unambiguous. A supplementary table listing the exact model–domain pairings is also added. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper introduces ImageAttributionBench as a new dataset and reports direct empirical performance of existing attribution methods under two fixed evaluation protocols (balanced split with degradation; semantically disjoint splits). No derivations, equations, fitted parameters, or predictions appear in the provided text. Central claims rest on measured accuracy drops rather than any self-referential construction or self-citation chain. The two evaluation settings are defined explicitly by the authors and do not reduce to prior results by the same team. This is a standard dataset-plus-benchmark paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing attribution datasets are constrained by limited scale, outdated generation methods, and insufficient semantic diversity.
- domain assumption The two described evaluation settings simulate real-world attribution scenarios.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
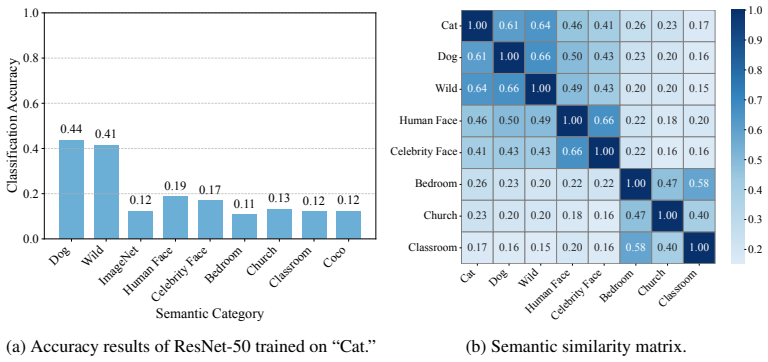
We evaluate several SOTA attribution methods on ImageAttributionBench under two challenging settings: (1) training on a standard balanced split and testing on degraded images, and (2) training and testing on semantically disjoint splits. In both cases, current methods exhibit consistently poor performance...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ImageAttributionBench comprises roughly 640,000 images... 31 state-of-the-art generators... 10 semantic classes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Ai dungeon: Ai-powered text adventure game.https://aidungeon.com/
AI Dungeon. Ai dungeon: Ai-powered text adventure game.https://aidungeon.com/
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Improving image generation with better captions.Computer Science
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions.Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
work page 2023
-
[5]
FLUX.2 [klein]: Towards interactive visual intelligence, January 2026
Black Forest Labs. FLUX.2 [klein]: Towards interactive visual intelligence, January 2026. URL https: //bfl.ai/blog/flux2-klein-towards-interactive-visual-intelligence
work page 2026
-
[6]
Wild: a new in-the- wild image linkage dataset for synthetic image attribution
Pietro Bongini, Sara Mandelli, Andrea Montibeller, Mirko Casu, Orazio Pontorno, Claudio Vittorio Ragaglia, Luca Zanchetta, Mattia Aquilina, Taiba Majid Wani, Luca Guarnera, et al. Wild: a new in-the- wild image linkage dataset for synthetic image attribution. In2025 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2025
work page 2025
-
[7]
Repmix: Representation mixing for robust attribution of synthesized images
Tu Bui, Ning Yu, and John Collomosse. Repmix: Representation mixing for robust attribution of synthesized images. InEuropean Conference on Computer Vision, pages 146–163. Springer, 2022
work page 2022
-
[8]
Deeper thinking, more accurate generation: Introducing Seedream 5.0 lite, February 2026
ByteDance Seed Team. Deeper thinking, more accurate generation: Introducing Seedream 5.0 lite, February 2026. URL https://seed.bytedance.com/en/blog/ deeper-thinking-more-accurate-generation-introducing-seedream-5-0-lite
work page 2026
-
[9]
What makes fake images detectable? understanding properties that generalize
Lucy Chai, David Bau, Ser-Nam Lim, and Phillip Isola. What makes fake images detectable? understanding properties that generalize. InComputer vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, proceedings, part XXVI 16, pages 103–120. Springer, 2020
work page 2020
-
[10]
Jiaxuan Chen, Jieteng Yao, and Li Niu. A single simple patch is all you need for ai-generated image detection.arXiv preprint arXiv:2402.01123, 2024
-
[11]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Stargan v2: Diverse image synthesis for multiple domains
Yunjey Choi, Youngjung Uh, Jaejun Yoo, and Jung-Woo Ha. Stargan v2: Diverse image synthesis for multiple domains. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8188–8197, 2020
work page 2020
-
[14]
Dario Cioni, Christos Tzelepis, Lorenzo Seidenari, and Ioannis Patras. Are clip features all you need for universal synthetic image origin attribution?arXiv preprint arXiv:2408.09153, 2024
-
[15]
On the detection of synthetic images generated by diffusion models
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, Giovanni Poggi, Koki Nagano, and Luisa Verdo- liva. On the detection of synthetic images generated by diffusion models. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
work page 2023
-
[16]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021. 10
work page 2021
-
[17]
Effect of ai generated content advertising on consumer engagement
Duo Du, Yanling Zhang, and Jiao Ge. Effect of ai generated content advertising on consumer engagement. InInternational conference on human-computer interaction, pages 121–129. Springer, 2023
work page 2023
-
[18]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
work page 2021
-
[19]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
work page 2024
- [20]
-
[21]
Leveraging frequency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. Leveraging frequency analysis for deep fake image recognition. InInternational conference on machine learning, pages 3247–3258. PMLR, 2020
work page 2020
-
[22]
Yu Gao, Lixue Gong, Qiushan Guo, Xiaoxia Hou, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, et al. Seedream 3.0 technical report.arXiv preprint arXiv:2504.11346, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
gemini.https://aistudio.google.com/, 2025
work page 2025
-
[24]
Gemini 2.5 flash image, October 2025
Google Cloud. Gemini 2.5 flash image, October 2025. URL https://docs.cloud.google.com/ vertex-ai/generative-ai/docs/models/gemini/2-5-flash-image
work page 2025
-
[25]
Gemini 3 pro image, November 2025
Google Cloud. Gemini 3 pro image, November 2025. URL https://docs.cloud.google.com/ vertex-ai/generative-ai/docs/models/gemini/3-pro-image
work page 2025
-
[26]
grok3.https://grok.com/, 2025
work page 2025
-
[27]
Danhuai Guo, Huixuan Chen, Ruoling Wu, and Yangang Wang. Aigc challenges and opportunities related to public safety: a case study of chatgpt.Journal of Safety Science and Resilience, 4(4):329–339, 2023
work page 2023
-
[28]
Hierarchical fine-grained image forgery detection and localization
Xiao Guo, Xiaohong Liu, Zhiyuan Ren, Steven Grosz, Iacopo Masi, and Xiaoming Liu. Hierarchical fine-grained image forgery detection and localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3155–3165, 2023
work page 2023
-
[29]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis, 2024
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis, 2024. URL https: //arxiv.org/abs/2412.04431
-
[30]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[31]
hidream-l1-fast Model on Huggingface
HiDream-ai. hidream-l1-fast Model on Huggingface. https://huggingface.co/HiDream-ai/ HiDream-I1-Fast, 2025. Accessed: 2025-04-25
work page 2025
-
[32]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[33]
Wildfake: A large-scale challenging dataset for ai-generated images detection
Yan Hong and Jianfu Zhang. Wildfake: A large-scale challenging dataset for ai-generated images detection. arXiv preprint arXiv:2402.11843, 2024
-
[34]
ideogram.https://ideogram.ai, 2023
work page 2023
-
[35]
Ginger Zhe Jin et al.Artificial intelligence and consumer privacy. Number w24253. National Bureau of Economic Research, 2018
work page 2018
-
[36]
Kimmo Karkkainen and Jungseock Joo. Fairface: Face attribute dataset for balanced race, gender, and age for bias measurement and mitigation. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1548–1558, 2021
work page 2021
-
[37]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 11
work page 2019
-
[39]
Jan Kietzmann, Jeannette Paschen, and Emily Treen. Artificial intelligence in advertising: How marketers can leverage artificial intelligence along the consumer journey.Journal of Advertising Research, 58(3): 263–267, 2018
work page 2018
-
[40]
kling.https://klingai.com/cn/dev/model/image, 2024
work page 2024
-
[41]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
work page 2024
-
[42]
Daiqing Li, Aleks Kamko, Ehsan Akhgari, Ali Sabet, Linmiao Xu, and Suhail Doshi. Playground v2.5: Three insights towards enhancing aesthetic quality in text-to-image generation, 2024
work page 2024
-
[43]
Jialiang Li, Haoyue Wang, Sheng Li, Zhenxing Qian, Xinpeng Zhang, and Athanasios V Vasilakos. Are handcrafted filters helpful for attributing ai-generated images? InProceedings of the 32nd ACM International Conference on Multimedia, pages 10698–10706, 2024
work page 2024
-
[44]
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024
work page 2024
-
[45]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, Jinbao Xue,...
work page 2024
-
[46]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, pages 740–755. Springer, 2014
work page 2014
-
[47]
On the limited memory bfgs method for large scale optimization
Dong C Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical programming, 45(1):503–528, 1989
work page 1989
-
[48]
Artificial intelligence: Risks to privacy and democracy.Yale JL & Tech., 21:106, 2019
Karl Manheim and Lyric Kaplan. Artificial intelligence: Risks to privacy and democracy.Yale JL & Tech., 21:106, 2019
work page 2019
-
[49]
Midjourney.https://www.midjourney.com/home/, 2022
work page 2022
-
[50]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Sora: Openai’s ai-powered text ui.https://openai.com/sora/
OpenAI. Sora: Openai’s ai-powered text ui.https://openai.com/sora/
-
[52]
Introducing our latest image generation model in the API, April 2025
OpenAI. Introducing our latest image generation model in the API, April 2025. URLhttps://openai. com/index/image-generation-api/
work page 2025
-
[53]
The new ChatGPT images is here, December 2025
OpenAI. The new ChatGPT images is here, December 2025. URL https://openai.com/index/ new-chatgpt-images-is-here/
work page 2025
-
[54]
David Patterson, Joseph Gonzalez, Urs Hölzle, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David R So, Maud Texier, and Jeff Dean. The carbon footprint of machine learning training will plateau, then shrink.Computer, 55(7):18–28, 2022
work page 2022
-
[55]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[57]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, June 2022
work page 2022
-
[58]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 12
work page 2022
-
[59]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge.International Journal of Computer Vision (IJCV), 115(3):211–252,
-
[60]
doi: 10.1007/s11263-015-0816-y
-
[61]
Liangjing Shao, Benshuang Chen, Ziqun Zhang, Zhen Zhang, and Xinrong Chen. Artificial intelligence generated content (aigc) in medicine: A narrative review.Mathematical Biosciences and Engineering, 21 (1):1672–1711, 2024
work page 2024
-
[62]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[63]
The social harms of ai-generated fake news: Addressing deepfake and ai political manipulation
LI Sophia. The social harms of ai-generated fake news: Addressing deepfake and ai political manipulation. Digital Society & Virtual Governance, 1(1):72–88, 2025
work page 2025
-
[64]
Sudowrite: Ai writing partner.https://sudowrite.com/
Sudowrite. Sudowrite: Ai writing partner.https://sudowrite.com/
-
[65]
Qwen Team. Qwen2.5-vl, January 2025. URLhttps://qwenlm.github.io/blog/qwen2.5-vl/
work page 2025
-
[66]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z-Image Team. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
work page 2024
-
[68]
Kandinsky 3: Text-to-image synthesis for multifunctional generative frame- work
Arkhipkin Vladimir, Viacheslav Vasilev, Andrei Filatov, Igor Pavlov, Julia Agafonova, Nikolai Gerasi- menko, Anna Averchenkova, Evelina Mironova, Bukashkin Anton, Konstantin Kulikov, Andrey Kuznetsov, and Denis Dimitrov. Kandinsky 3: Text-to-image synthesis for multifunctional generative frame- work. In Delia Irazu Hernandez Farias, Tom Hope, and Manling ...
work page 2024
-
[69]
Diffusers: State-of-the-art diffusion models.https://github.com/huggingface/diffusers, 2022
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models.https://github.com/huggingface/diffusers, 2022
work page 2022
-
[70]
Cnn-generated images are surprisingly easy to spot
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn-generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8695–8704, 2020
work page 2020
-
[71]
TY Wang, Li Li, Xiang Chen, and KZ Li. A study on the risks and countermeasures of false information caused by aigc.Journal of Electrical Systems, 20(3):420–426, 2024
work page 2024
-
[72]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[73]
Omnidfa: A unified framework for open set synthesis image detection and few-shot attribution, 2025
Shiyu Wu, Shuyan Li, Jing Li, Jing Liu, and Yequan Wang. Omnidfa: A unified framework for open set synthesis image detection and few-shot attribution, 2025. URL https://arxiv.org/abs/2509.25682
-
[74]
Few-shot learner generalizes across ai-generated image detection, 2025
Shiyu Wu, Jing Liu, Jing Li, and Yequan Wang. Few-shot learner generalizes across ai-generated image detection, 2025. URLhttps://arxiv.org/abs/2501.08763
-
[75]
Combating misinformation in the era of generative ai models
Danni Xu, Shaojing Fan, and Mohan Kankanhalli. Combating misinformation in the era of generative ai models. InProceedings of the 31st ACM International Conference on Multimedia, pages 9291–9298, 2023
work page 2023
-
[76]
Ucf: Uncovering common features for generalizable deepfake detection
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. Ucf: Uncovering common features for generalizable deepfake detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22412–22423, 2023
work page 2023
-
[77]
Tianyun Yang, Juan Cao, Qiang Sheng, Lei Li, Jiaqi Ji, Xirong Li, and Sheng Tang. Learning to disentangle gan fingerprint for fake image attribution.arXiv preprint arXiv:2106.08749, 2021
-
[78]
Deepfake network architecture attribution
Tianyun Yang, Ziyao Huang, Juan Cao, Lei Li, and Xirong Li. Deepfake network architecture attribution. InProceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 4662–4670, 2022. 13
work page 2022
-
[79]
Progressive open space expansion for open-set model attribution
Tianyun Yang, Danding Wang, Fan Tang, Xinying Zhao, Juan Cao, and Sheng Tang. Progressive open space expansion for open-set model attribution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15856–15865, 2023
work page 2023
-
[80]
LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop
Fisher Yu, Yinda Zhang, Shuran Song, Ari Seff, and Jianxiong Xiao. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop.arXiv preprint arXiv:1506.03365, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.