Recognition: unknown
CoGE: Sim-to-Real Online Geometric Estimation for Monocular Colonoscopy
Pith reviewed 2026-05-14 20:40 UTC · model grok-4.3
The pith
A model trained only on simulated colonoscopy images reaches state-of-the-art depth and 3D reconstruction accuracy on real patient data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
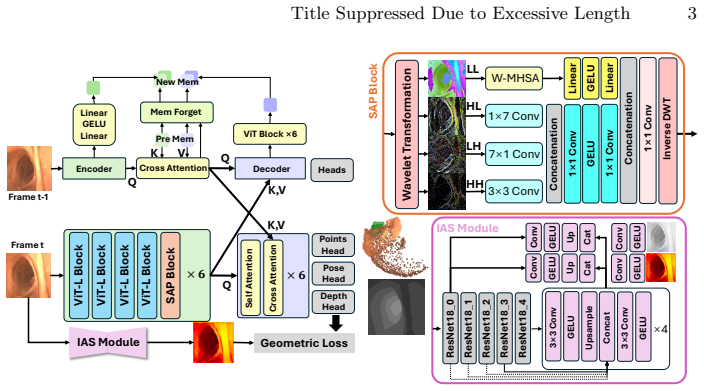
CoGE is a novel framework for online monocular geometric estimation during colonoscopy that first applies an illumination-aware supervision module based on Retinex theory to handle lighting diversity across scenes, then adds a structure-aware perception module based on wavelet decomposition to extract common structural and local features of the colon, enabling a model trained solely on simulated data to achieve state-of-the-art performance in geometric estimation for both simulated and realistic scenes.
What carries the argument
The illumination-aware supervision module based on Retinex theory combined with the structure-aware perception module based on wavelet decomposition, which together close the feature gap between simulated and real colonoscopy images.
If this is right
- Surgeons receive accurate 3D spatial perception and navigation cues from ordinary monocular colonoscopy video.
- No real-world geometric ground truth is required for training or deployment.
- The same model works at top accuracy on both fully simulated test scenes and real patient footage.
- Estimation runs online, supporting live use during procedures.
Where Pith is reading between the lines
- The approach could transfer to other endoscopic domains that share similar narrow-space lighting and texture challenges.
- Training costs drop sharply once simulation pipelines are built, since real labeled data collection is avoided.
- Real-time surgical systems might incorporate the depth output directly for tool guidance or surface measurement.
Load-bearing premise
The two new modules based on Retinex lighting theory and wavelet structure analysis are sufficient by themselves to overcome the large differences in appearance caused by artifacts and illumination between simulated and real data.
What would settle it
A large-scale test on real colonoscopy videos in which the model's depth maps or reconstructed surfaces show larger errors than the current best methods that were trained with any real geometric labels.
Figures






read the original abstract
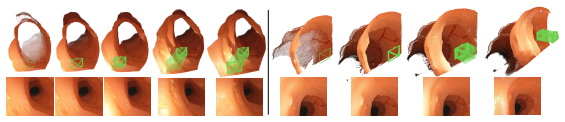
Geometric estimation including depth estimation and scene reconstruction is a crucial technique for colonoscopy which can provide surgeons with 3D spatial perception and navigation. However, geometric ground truth in colonoscopy is difficult to obtain due to narrow and enclosed space of the colon, while there is a large feature gap between simulated data and realistic data caused by artifacts and illumination. In this paper, we present CoGE, a novel framework for online monocular geometric estimation during colonoscopy. Firstly, we propose an illumination-aware supervision module based on the Retinex theory to address illumination diversity in different colonoscopy scenes. Moreover, a structure-aware perception module is proposed based on wavelet decomposition to extract common structural and local features of the colon. Both quantitative and qualitative results demonstrate that the proposed model solely trained on simulated data achieves state-of-the-art performance in geometric estimation for both simulated and realistic scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoGE, a framework for online monocular geometric estimation (depth estimation and scene reconstruction) in colonoscopy. It introduces an illumination-aware supervision module based on Retinex theory to handle illumination diversity and a structure-aware perception module based on wavelet decomposition to extract common structural features. The model is trained exclusively on simulated data and claims state-of-the-art performance on both simulated and realistic scenes, supported by quantitative metrics on simulation and qualitative results on real data.
Significance. If the sim-to-real transfer holds under rigorous evaluation, the work could advance practical 3D perception in colonoscopy without requiring real-world geometric ground truth, which is difficult to obtain in the narrow enclosed anatomy. The Retinex-based illumination handling and wavelet-based structure extraction represent targeted adaptations for endoscopy domain gaps, potentially enabling better surgical navigation if the performance generalizes beyond visual inspection.
major comments (2)
- [Abstract] Abstract: The central claim that the model achieves SOTA geometric estimation on realistic scenes is supported only by qualitative results. The abstract explicitly notes that geometric ground truth is difficult to obtain in real colonoscopies, so quantitative metrics (RMSE, AbsRel, etc.) are presumably computed only on simulated data. This renders the sim-to-real SOTA assertion dependent on subjective visual comparison rather than direct numerical benchmarking against baselines on real data.
- [Experiments] Experiments section (assumed §4 or §5): If real-scene evaluation relies solely on qualitative inspection or indirect proxies without falsifiable quantitative comparison to prior methods, the headline performance claim on realistic scenes cannot be verified objectively. A load-bearing fix would require either proxy metrics on real data or explicit acknowledgment that real-scene superiority is qualitative only.
minor comments (1)
- [Method] Ensure consistent notation for the two proposed modules (illumination-aware supervision and structure-aware perception) across the method and results sections to avoid reader confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to clarify the distinction between quantitative and qualitative evaluations. We agree that the manuscript should more explicitly acknowledge the limitations of real-scene assessment and will revise the abstract and experiments section to ensure claims are precisely supported by the available evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the model achieves SOTA geometric estimation on realistic scenes is supported only by qualitative results. The abstract explicitly notes that geometric ground truth is difficult to obtain in real colonoscopies, so quantitative metrics (RMSE, AbsRel, etc.) are presumably computed only on simulated data. This renders the sim-to-real SOTA assertion dependent on subjective visual comparison rather than direct numerical benchmarking against baselines on real data.
Authors: We agree that quantitative metrics cannot be computed on real data due to the unavailability of geometric ground truth, as already stated in the manuscript. In the endoscopy literature, qualitative visual comparisons are the established standard for evaluating sim-to-real transfer when ground truth is unobtainable. Our results show clear improvements in illumination handling and structural fidelity over baselines in real colonoscopy footage. We will revise the abstract to explicitly qualify that state-of-the-art performance on realistic scenes is demonstrated qualitatively. revision: yes
-
Referee: [Experiments] Experiments section (assumed §4 or §5): If real-scene evaluation relies solely on qualitative inspection or indirect proxies without falsifiable quantitative comparison to prior methods, the headline performance claim on realistic scenes cannot be verified objectively. A load-bearing fix would require either proxy metrics on real data or explicit acknowledgment that real-scene superiority is qualitative only.
Authors: We accept that real-scene evaluation is qualitative only. We will add an explicit statement in the Experiments section clarifying that quantitative results are restricted to simulated data while real-scene superiority is shown through visual comparisons. This revision will prevent any overstatement and align the claims with the evidence presented. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces an illumination-aware supervision module based on Retinex theory and a structure-aware perception module based on wavelet decomposition as additive components to handle sim-to-real domain gaps. These are presented as independent architectural choices rather than redefinitions of the target depth or reconstruction metrics. No equations in the provided abstract or description reduce the claimed performance metrics (e.g., RMSE on geometric estimation) to quantities fitted directly on the evaluation data by construction. Training occurs exclusively on simulated data with known ground truth, while real-scene results are described qualitatively; this separation avoids any fitted-input-called-prediction pattern. Self-citations, if present in the full text, are not load-bearing for the core claim. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Retinex theory can be used to separate illumination from reflectance in colonoscopy images
- domain assumption Wavelet decomposition extracts structural features common to both simulated and real colon images
Reference graph
Works this paper leans on
-
[1]
Medical image analysis90, 102956 (2023)
Bobrow, T.L., Golhar, M., Vijayan, R., Akshintala, V.S., Garcia, J.R., Durr, N.J.: Colonoscopy 3d video dataset with paired depth from 2d-3d registration. Medical image analysis90, 102956 (2023)
2023
-
[2]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Cui, B., Islam, M., Bai, L., Wang, A., Ren, H.: Endodac: Efficient adapting foun- dation model for self-supervised depth estimation from any endoscopic camera. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 208–218. Springer (2024)
2024
-
[3]
arXiv preprint arXiv:2506.24074 (2025)
Golhar, M.V., Fretes, L.S.G., Ayers, L., Akshintala, V.S., Bobrow, T.L., Durr, N.J.: C3vdv2–colonoscopy 3d video dataset with enhanced realism. arXiv preprint arXiv:2506.24074 (2025)
-
[4]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Guo, J., Dong, W., Huang, T., Ding, H., Wang, Z., Kuang, H., Dou, Q., Liu, Y.H.: Endo3r: Unified online reconstruction from dynamic monocular endoscopic video. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 170–180. Springer (2025)
2025
-
[5]
Medical image analysis70, 101990 (2021)
İncetan, K., Celik, I.O., Obeid, A., Gokceler, G.I., Ozyoruk, K.B., Almalioglu, Y., Chen, R.J., Mahmood, F., Gilbert, H., Durr, N.J., et al.: Vr-caps: a virtual environment for capsule endoscopy. Medical image analysis70, 101990 (2021)
2021
-
[6]
IEEE Robotics and Au- tomation Letters (2025)
Jiang, Z., Wang, Y., Cheng, X., Ge, Z.: Colonadapter: Geometry estimation through foundation model adaptation for colonoscopy. IEEE Robotics and Au- tomation Letters (2025)
2025
-
[7]
In: European conference on computer vision
Kim, S., Park, K., Sohn, K., Lin, S.: Unified depth prediction and intrinsic im- age decomposition from a single image via joint convolutional neural fields. In: European conference on computer vision. pp. 143–159. Springer (2016)
2016
-
[8]
arXiv preprint arXiv:2508.10893 (2025)
Lan,Y.,Luo,Y.,Hong,F.,Zhou,S.,Chen,H.,Lyu,Z.,Yang,S.,Dai,B.,Loy,C.C., Pan, X.: Stream3r: Scalable sequential 3d reconstruction with causal transformer. arXiv preprint arXiv:2508.10893 (2025)
-
[9]
IEEE transactions on medical imaging37(12), 2572–2581 (2018)
Mahmood, F., Chen, R., Durr, N.J.: Unsupervised reverse domain adaptation for synthetic medical images via adversarial training. IEEE transactions on medical imaging37(12), 2572–2581 (2018)
2018
-
[10]
Medical image analysis48, 230–243 (2018)
Mahmood,F.,Durr,N.J.:Deeplearningandconditionalrandomfields-baseddepth estimation and topographical reconstruction from conventional endoscopy. Medical image analysis48, 230–243 (2018)
2018
-
[11]
Medical Image Analysis96, 103195 (2024)
Rau, A., Bano, S., Jin, Y., Azagra, P., Morlana, J., Kader, R., Sanderson, E., Matuszewski, B.J., Lee, J.Y., Lee, D.J., et al.: Simcol3d—3d reconstruction during colonoscopy challenge. Medical Image Analysis96, 103195 (2024)
2024
-
[12]
Medical image analysis77, 102338 (2022)
Shao, S., Pei, Z., Chen, W., Zhu, W., Wu, X., Sun, D., Zhang, B.: Self-supervised monocular depth and ego-motion estimation in endoscopy: Appearance flow to the rescue. Medical image analysis77, 102338 (2022)
2022
-
[13]
In: 2025 Interna- tional Conference on 3D Vision (3DV)
Wang, H., Agapito, L.: 3d reconstruction with spatial memory. In: 2025 Interna- tional Conference on 3D Vision (3DV). pp. 78–89. IEEE (2025)
2025
-
[14]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Q., Zhang, Y., Holynski, A., Efros, A.A., Kanazawa, A.: Continuous 3d perception model with persistent state. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10510–10522 (2025) 10 L. Shao et al
2025
-
[15]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20697–20709 (2024)
2024
-
[16]
Medical Image Analysis102, 103534 (2025)
Wang, Z., Zhou, Y., He, S., Li, T., Huang, F., Ding, Q., Feng, X., Liu, M., Li, Q.: Monopcc: Photometric-invariant cycle constraint for monocular depth estimation of endoscopic images. Medical Image Analysis102, 103534 (2025)
2025
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10371–10381 (2024)
2024
-
[18]
arXiv preprint arXiv:2410.03825 (2024)
Zhang, J., Herrmann, C., Hur, J., Jampani, V., Darrell, T., Cole, F., Sun, D., Yang, M.H.: Monst3r: A simple approach for estimating geometry in the presence of motion. arXiv preprint arXiv:2410.03825 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.