Recognition: unknown
Large Language Models Lack Temporal Awareness of Medical Knowledge
Pith reviewed 2026-05-14 20:13 UTC · model grok-4.3
The pith
Large language models lack awareness of when medical knowledge applies in time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
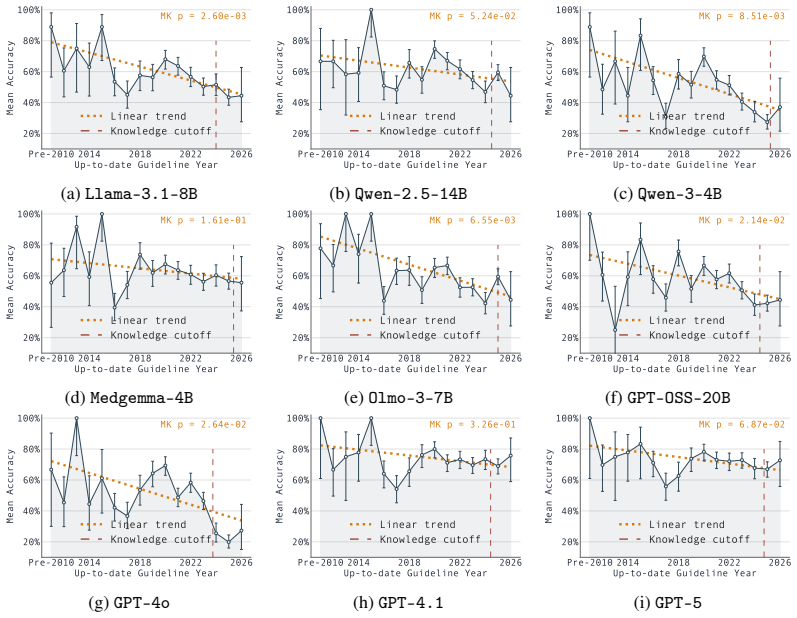
LLMs lack temporal awareness of medical knowledge. On TempoMed-Bench, performance on up-to-date recommendations falls in a gradual linear pattern over successive years instead of exhibiting a sharp knowledge cutoff, recall accuracy for historical guideline versions reaches only 25.37 to 53.89 percent of current-version accuracy, and model outputs fluctuate irregularly when the same question is posed for neighboring years.
What carries the argument
TempoMed-Bench, a benchmark built from evolving medical guidelines that supplies time-labeled questions to test recall, consistency, and knowledge cutoff behavior.
If this is right
- Models may output recommendations that are valid only for the wrong time window without any internal signal of mismatch.
- Standard training leads to partial forgetting of earlier guideline versions rather than clean retention of all historical states.
- Atemporal medical benchmarks miss the consistency failures that appear when questions are posed across successive years.
- Adding agentic search improves results only modestly and leaves residual temporal inconsistency intact.
Where Pith is reading between the lines
- The same gradual-fade and inconsistency pattern may appear in any domain where facts carry validity dates, such as legal statutes or scientific consensus.
- Training pipelines could add explicit time-stamping or versioning layers to reduce the observed forgetting of historical states.
- Medical deployment pipelines should treat parametric outputs as provisional and require external verification against current sources.
Load-bearing premise
The chosen evolving guidelines represent typical temporal shifts in medical knowledge and model answers reflect internal parametric storage rather than prompt or retrieval effects.
What would settle it
Retrain one of the tested models on the same guideline corpus but with explicit year tags attached to each fact, then re-run TempoMed-Bench to check whether the gradual decline and year-to-year inconsistency both disappear.
Figures















read the original abstract
The existing methods for evaluating the medical knowledge of Large Language Models (LLMs) are largely based on atemporal examination-style benchmarks, while in reality, medical knowledge is inherently dynamic and continuously evolves as new evidence emerges and treatments are approved. Consequently, evaluating medical knowledge without a temporal context may provide an incomplete assessment of whether LLMs can accurately reason about time-specific medical knowledge. Moreover, most medical data are historical, requiring the models not only to recall the correct knowledge, but also to know when that knowledge is correct. To bridge the gap, we built TempoMed-Bench, the first-of-its-kind benchmark for evaluating the temporal awareness of the LLMs in the medical domain through evolving guideline knowledge. Based on the TempoMed-Bench, our evaluation analysis first reveals that LLMs lack temporal awareness in medical knowledge through the key findings: (1) model performance on up-to-date medical knowledge exhibits a gradual linear decline over time rather than a sharp knowledge-cutoff behavior, suggesting that parametric medical knowledge is not strictly bounded by knowledge cutoffs; (2) LLMs consistently struggle more with recalling outdated historical medical knowledge than with up-to-date recommendations: accuracy of historical knowledge is only 25.37%-53.89% of up-to-date knowledge, indicating potential knowledge forgetting effects during training; and (3) LLMs often exhibit temporally inconsistent behaviors, where predictions fluctuate irregularly across neighboring years. We also show that the temporal awareness problem is a challenge that cannot be easily solved when integrated with agentic search tools (-3.15%-14.14%). This work highlights an important yet underexplored challenge and motivates future research on developing LLMs that can better encode time-specific medical knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TempoMed-Bench, the first benchmark for temporal awareness in medical LLMs constructed from evolving clinical guidelines. It reports three main empirical findings: (1) up-to-date knowledge performance declines gradually and linearly rather than exhibiting a sharp cutoff; (2) historical guideline accuracy is only 25.37–53.89 % of current accuracy, interpreted as evidence of forgetting; and (3) models display temporally inconsistent predictions across neighboring years. Experiments with agentic search tools show only modest gains (-3.15 % to 14.14 %), leading to the conclusion that temporal awareness cannot be easily mitigated by retrieval.
Significance. If the benchmark isolates parametric temporal encoding from data-distribution and difficulty confounds, the results would be significant for medical AI, where outdated recommendations carry direct clinical risk. The work supplies concrete cross-model quantitative measurements against an external, time-stamped reference and introduces a reusable evolving-domain benchmark, both of which are valuable contributions even if further validation is required.
major comments (3)
- [§3] §3 (TempoMed-Bench construction): The manuscript does not report controls for question difficulty, lexical complexity, or training-data frequency between historical and current guideline versions. Without such controls (e.g., expert difficulty ratings or n-gram overlap statistics), the reported accuracy gap of 25.37–53.89 % could arise from general medical-reasoning difficulty rather than absence of temporal parameters.
- [§5.3] §5.3 (search-tool ablation): The ablation reports performance deltas of -3.15 % to 14.14 % but provides no details on whether the retrieval pipeline blocks direct leakage of the guideline texts used to build TempoMed-Bench or standardizes query phrasing. This information is load-bearing for the claim that external tools cannot solve the temporal-awareness problem.
- [§4] §4 (results): The assertion of a 'gradual linear decline' is presented without statistical support (e.g., linear-regression R², comparison against a step-function cutoff model, or confidence intervals on the slope). Adding these tests would strengthen the distinction from knowledge-cutoff behavior.
minor comments (2)
- [Abstract] Abstract: The accuracy range 25.37–53.89 % should be accompanied by the specific models that achieve the lower and upper bounds.
- [Figures] Figure captions: Ensure that time axes and accuracy metrics are labeled consistently with the text (e.g., year ranges and exact evaluation protocol).
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the presentation of our results on temporal awareness in medical LLMs. We address each major comment below and commit to revisions that improve clarity and rigor without altering the core findings.
read point-by-point responses
-
Referee: [§3] §3 (TempoMed-Bench construction): The manuscript does not report controls for question difficulty, lexical complexity, or training-data frequency between historical and current guideline versions. Without such controls (e.g., expert difficulty ratings or n-gram overlap statistics), the reported accuracy gap of 25.37–53.89 % could arise from general medical-reasoning difficulty rather than absence of temporal parameters.
Authors: We agree that explicit controls would better isolate temporal effects. Although questions are derived from paired versions of the same guideline documents (ensuring matched clinical topics), we did not previously quantify overlap or difficulty. In the revised manuscript we will report n-gram overlap statistics between historical and current question sets and include expert-rated difficulty scores for a representative sample to confirm that the accuracy gap is not driven by general reasoning difficulty. revision: yes
-
Referee: [§5.3] §5.3 (search-tool ablation): The ablation reports performance deltas of -3.15 % to 14.14 % but provides no details on whether the retrieval pipeline blocks direct leakage of the guideline texts used to build TempoMed-Bench or standardizes query phrasing. This information is load-bearing for the claim that external tools cannot solve the temporal-awareness problem.
Authors: We appreciate this observation. The retrieval experiments used paraphrased queries and an index that excluded the TempoMed-Bench source documents to prevent direct leakage. In the revision we will add a full description of the pipeline, including query standardization steps and explicit confirmation that benchmark guideline texts were not retrievable, to support the conclusion that agentic search yields only modest gains. revision: yes
-
Referee: [§4] §4 (results): The assertion of a 'gradual linear decline' is presented without statistical support (e.g., linear-regression R², comparison against a step-function cutoff model, or confidence intervals on the slope). Adding these tests would strengthen the distinction from knowledge-cutoff behavior.
Authors: We acknowledge the need for statistical validation. The revised manuscript will include linear regression fits with reported R² values, 95% confidence intervals on the slopes, and a model comparison (linear vs. step-function) to demonstrate that the gradual decline is statistically preferred over a sharp cutoff, thereby reinforcing the distinction from conventional knowledge-cutoff behavior. revision: yes
Circularity Check
No circularity: direct empirical measurements on external guideline benchmark
full rationale
The paper's claims rest on constructing TempoMed-Bench from independently evolving medical guidelines and reporting measured LLM accuracies (gradual linear decline, historical accuracy 25.37-53.89% of current, temporal inconsistencies). These are observational results from benchmark evaluation, not reductions of predictions to fitted inputs, self-definitions, or self-citation chains. No equations, ansatzes, or uniqueness theorems are invoked that collapse back to the paper's own data or prior author work. The search-tool ablation is likewise an external control. The derivation is self-contained against real-world guideline changes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medical guidelines evolve over time in a way that creates clear temporal distinctions usable for benchmarking.
invented entities (1)
-
TempoMed-Bench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
The distracting effect: Understanding irrelevant passages in rag
Chen Amiraz, Florin Cuconasu, Simone Filice, and Zohar Karnin. The distracting effect: Understanding irrelevant passages in rag. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 18228–18258, 2025
2025
-
[3]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, et al. Healthbench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Jae Hyun Bae, Ji-Hee Haam, Eonju Jeon, Seo Young Kang, SuJin Song, Cheol-Young Park, Hyuktae Kwon, Committee of Clinical Practice Guidelines, et al. 2024 clinical practice guidelines for the diagnosis and pharmacologic treatment of overweight and obesity by the korean society for the study of obesity.Journal of Obesity & Metabolic Syndrome, 34(4):322, 2025
2024
-
[5]
Diagnostic accuracy of a large language model in pediatric case studies.JAMA pediatrics, 178(3):313–315, 2024
Joseph Barile, Alex Margolis, Grace Cason, Rachel Kim, Saia Kalash, Alexis Tchaconas, and Ruth Milanaik. Diagnostic accuracy of a large language model in pediatric case studies.JAMA pediatrics, 178(3):313–315, 2024
2024
-
[6]
Holistic evaluation of large language models for medical tasks with medhelm.Nature Medicine, pages 1–9, 2026
Suhana Bedi, Hejie Cui, Miguel Fuentes, Alyssa Unell, Michael Wornow, Juan M Banda, Nikesh Kotecha, Timothy Keyes, Yifan Mai, Mert Oez, et al. Holistic evaluation of large language models for medical tasks with medhelm.Nature Medicine, pages 1–9, 2026
2026
-
[7]
Tuberculosis in childhood: a systematic review of national and international guidelines.BMC infectious diseases, 14(Suppl 1):S3, 2014
Elettra Berti, Luisa Galli, Elisabetta Venturini, Maurizio de Martini, and Elena Chiappini. Tuberculosis in childhood: a systematic review of national and international guidelines.BMC infectious diseases, 14(Suppl 1):S3, 2014
2014
-
[8]
Temporal knowledge question answering via abstract reasoning induction
Ziyang Chen, Dongfang Li, Xiang Zhao, Baotian Hu, and Min Zhang. Temporal knowledge question answering via abstract reasoning induction. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4872–4889, 2024
2024
-
[9]
Timer: Temporal instruction modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025
Hejie Cui, Alyssa Unell, Bowen Chen, Jason Alan Fries, Emily Alsentzer, Sanmi Koyejo, and Nigam H Shah. Timer: Temporal instruction modeling and evaluation for longitudinal clinical records.npj Digital Medicine, 8(1):577, 2025
2025
-
[10]
Democratizing ai scientists using tooluniverse.arXiv preprint arXiv:2509.23426, 2025
Shanghua Gao, Richard Zhu, Pengwei Sui, Zhenglun Kong, Sufian Aldogom, Yepeng Huang, Ayush Noori, Reza Shamji, Krishna Parvataneni, Theodoros Tsiligkaridis, et al. Democratizing ai scientists using tooluniverse.arXiv preprint arXiv:2509.23426, 2025
-
[11]
Timing errors and temporal uncertainty in clinical databases—a narrative review.Frontiers in Digital Health, 4:932599, 2022
Andrew J Goodwin, Danny Eytan, William Dixon, Sebastian D Goodfellow, Zakary Doherty, Robert W Greer, Alistair McEwan, Mark Tracy, Peter C Laussen, Azadeh Assadi, et al. Timing errors and temporal uncertainty in clinical databases—a narrative review.Frontiers in Digital Health, 4:932599, 2022
2022
-
[12]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Biomni: A general-purpose biomedical ai agent
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, et al. Biomni: A general-purpose biomedical ai agent. biorxiv, 2025
2025
-
[14]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021. 11
2021
-
[15]
Pubmedqa: A dataset for biomedical research question answering
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567–2577, 2019
2019
-
[16]
Biomedical question answering: a survey of approaches and challenges.ACM Computing Surveys (CSUR), 55(2):1–36, 2022
Qiao Jin, Zheng Yuan, Guangzhi Xiong, Qianlan Yu, Huaiyuan Ying, Chuanqi Tan, Mosha Chen, Songfang Huang, Xiaozhong Liu, and Sheng Yu. Biomedical question answering: a survey of approaches and challenges.ACM Computing Surveys (CSUR), 55(2):1–36, 2022
2022
-
[17]
Kyoung-Kon Kim, Ji-Hee Haam, Bom Taeck Kim, Eun Mi Kim, Jung Hwan Park, Sang Youl Rhee, Eonju Jeon, Eungu Kang, Ga Eun Nam, Hye Yeon Koo, et al. Evaluation and treatment of obesity and its comorbidities: 2022 update of clinical practice guidelines for obesity by the korean society for the study of obesity.Journal of Obesity & Metabolic Syndrome, 32(1):1, 2023
2022
-
[18]
Medexqa: Medical question answering benchmark with multiple explanations
Yunsoo Kim, Jinge Wu, Yusuf Abdulle, and Honghan Wu. Medexqa: Medical question answering benchmark with multiple explanations. InProceedings of the 23rd Workshop on biomedical natural language processing, pages 167–181, 2024
2024
-
[19]
Junhong Lin, Song Wang, Xiaojie Guo, Julian Shun, and Yada Zhu. Temporal reason- ing with large language models augmented by evolving knowledge graphs.arXiv preprint arXiv:2509.15464, 2025
-
[20]
Do llms know when to not answer? investigating abstention abilities of large language models
Nishanth Madhusudhan, Sathwik Tejaswi Madhusudhan, Vikas Yadav, and Masoud Hashemi. Do llms know when to not answer? investigating abstention abilities of large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 9329–9345, 2025
2025
-
[21]
Nonparametric tests against trend.Econometrica: Journal of the econometric society, pages 245–259, 1945
Henry B Mann. Nonparametric tests against trend.Econometrica: Journal of the econometric society, pages 245–259, 1945
1945
-
[22]
Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment.JAMA ophthalmology, 141(6):589– 597, 2023
Andrew Mihalache, Marko M Popovic, and Rajeev H Muni. Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment.JAMA ophthalmology, 141(6):589– 597, 2023
2023
-
[23]
Dyknow: Dynamically verify- ing time-sensitive factual knowledge in llms
Seyed Mahed Mousavi, Simone Alghisi, and Giuseppe Riccardi. Dyknow: Dynamically verify- ing time-sensitive factual knowledge in llms. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8014–8029, 2024
2024
-
[24]
Nishanth Sridhar Nakshatri, Shamik Roy, Manoj Ghuhan Arivazhagan, Hanhan Zhou, Vinayshekhar Bannihatti Kumar, and Rashmi Gangadharaiah. When facts change: Probing llms on evolving knowledge with evolveqa.arXiv preprint arXiv:2510.19172, 2025
-
[25]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. InConference on health, inference, and learning, pages 248–260. PMLR, 2022
2022
-
[27]
Large language models sensitivity to the order of options in multiple-choice questions
Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple-choice questions. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2006–2017, 2024
2024
-
[28]
Qwen2.5 technical report, 2025
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
2025
-
[29]
Comparative evaluation of llms in clinical oncology
Nicholas R Rydzewski, Deepak Dinakaran, Shuang G Zhao, Eytan Ruppin, Baris Turkbey, Deborah E Citrin, and Krishnan R Patel. Comparative evaluation of llms in clinical oncology. Nejm ai, 1(5):AIoa2300151, 2024
2024
-
[30]
Andrew Sellergren, Chufan Gao, Fereshteh Mahvar, Timo Kohlberger, Fayaz Jamil, Madeleine Traverse, Alberto Tono, Bashir Sadjad, Lin Yang, Charles Lau, et al. Medgemma 1.5 technical report.arXiv preprint arXiv:2604.05081, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
2018 korean society for the study of obesity guideline for the management of obesity in korea.Journal of obesity & metabolic syndrome, 28(1):40, 2019
Mi Hae Seo, Won-Young Lee, Sung Soo Kim, Jae-Heon Kang, Jee-Hyun Kang, Kyoung Kon Kim, Bo-Yeon Kim, Yang-Hyun Kim, Won-Jun Kim, Eun Mi Kim, et al. 2018 korean society for the study of obesity guideline for the management of obesity in korea.Journal of obesity & metabolic syndrome, 28(1):40, 2019
2018
-
[33]
Large language models can be easily distracted by irrelevant context
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. InInternational Conference on Machine Learning, pages 31210–31227. PMLR, 2023
2023
-
[34]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
2023
-
[35]
Evowiki: Evaluating llms on evolving knowledge
Wei Tang, Yixin Cao, Yang Deng, Jiahao Ying, Bo Wang, Yizhe Yang, Yuyue Zhao, Qi Zhang, Xuan-Jing Huang, Yu-Gang Jiang, et al. Evowiki: Evaluating llms on evolving knowledge. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 948–964, 2025
2025
-
[36]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Large language models-guided dynamic adaptation for temporal knowledge graph reasoning.Advances in Neural Information Processing Systems, 37:8384–8410, 2024
Jiapu Wang, Kai Sun, Linhao Luo, Wei Wei, Yongli Hu, Alan W Liew, Shirui Pan, and Baocai Yin. Large language models-guided dynamic adaptation for temporal knowledge graph reasoning.Advances in Neural Information Processing Systems, 37:8384–8410, 2024
2024
-
[38]
Towards evaluating and building versatile large language models for medicine.npj Digital Medicine, 8(1):58, 2025
Chaoyi Wu, Pengcheng Qiu, Jinxin Liu, Hongfei Gu, Na Li, Ya Zhang, Yanfeng Wang, and Weidi Xie. Towards evaluating and building versatile large language models for medicine.npj Digital Medicine, 8(1):58, 2025
2025
-
[39]
Assessing and mitigating medical knowledge drift and conflicts in large language models
Weiyi Wu, Xinwen Xu, Chongyang Gao, Xingjian Diao, Siting Li, Lucas A Salas, and Jiang Gui. Assessing and mitigating medical knowledge drift and conflicts in large language models. arXiv preprint arXiv:2505.07968, 2025
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Large language models are not robust multiple choice selectors.arXiv preprint arXiv:2309.03882, 2023
Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors.arXiv preprint arXiv:2309.03882, 2023
-
[42]
Evolvebench: A comprehensive benchmark for assessing temporal awareness in llms on evolving knowledge
Zhiyuan Zhu, Yusheng Liao, Zhe Chen, Yuhao Wang, Yunfeng Guan, Yanfeng Wang, and Yu Wang. Evolvebench: A comprehensive benchmark for assessing temporal awareness in llms on evolving knowledge. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16173–16188, 2025
2025
-
[43]
Yuxin Zuo, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu, Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. Medxpertqa: Benchmarking expert-level medical reasoning and understanding.arXiv preprint arXiv:2501.18362, 2025. 13 Appendix Contents A Data Collection Pipeline. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A...
-
[44]
- If no, do not record any prior guidelines and set the prior guidelines as an empty list.,→
Determine whether the paper itself is a clinical guideline issued by a professional society (e.g., the American College of Rheumatology).,→ - If yes, proceed with the steps below and extract prior guidelines. - If no, do not record any prior guidelines and set the prior guidelines as an empty list.,→
-
[45]
Examine the *Introduction*, *Related Works* or *Literature Review* sections to identify documents cited as prior guidelines that **meet the above criteria**;,→
-
[46]
Record the`year`,`PMID`,`Organization`, and`title`of each previous guideline.,→
-
[47]
Topic":
Explain why each document is identified as a prior guideline that precedes the current one (e.g., explicit citation, chronological ordering, or stated replacement). ,→ ,→ ## Important Notes: - If multiple prior guidelines exist, include all of them. 17 - If a field is not available, return`None`for that field. For example, if the old guideline is from the...
2025
-
[48]
- The corresponding recommendation in the PRIOR guideline
Please Extract: - The key clinical recommendation in the CURRENT guideline. - The corresponding recommendation in the PRIOR guideline
-
[49]
For each extracted change, the topic must be **identical** between the prior and current recommendations (i.e., a strict head-to-head comparison).,→ - For example, the prior recommendation and the current recommendation are different treatments based on the **SAME disease**,→
-
[50]
,→ ,→ - Each pair of`current_recommendation`and`prior_recommendation`must represent a direct **head-to-head comparison** and be **meaningfully different**
Focus only on recommendations that have changed substantially, for example: - The prior guideline recommends therapy A for disease C, whereas the current guideline recommends therapy B for the **SAME disease** C based on new clinical evidence. ,→ ,→ - Each pair of`current_recommendation`and`prior_recommendation`must represent a direct **head-to-head compa...
-
[51]
**MUST exclude minor or incremental updates**, including but not limited to: - The prior guideline lacked specific guidance, and the current guideline merely adds clarification or detail.,→ - Both guidelines recommend the same intervention, with the current guideline only expanding on context, rationale, or implementation details.,→
-
[52]
If the prior and current guidelines address different clinical topics, return an empty list.,→
-
[53]
Do not use vague words and try to be more specific and detailed
Each generated`current_recommendation`and`prior_recommendation`must be self-contained, precise, and clinically interpretable, explicitly stating any necessary background conditions or patient populations. Do not use vague words and try to be more specific and detailed. ,→ ,→ ,→
-
[54]
DO NOT fabricate any new clinical terms or conditions
Your recommendation text in`current_recommendation`and`prior_recommendation` MUST be faithful to the corresponding raw texts. DO NOT fabricate any new clinical terms or conditions. ,→ ,→
-
[55]
complicated diverticulitis
Identify as many differences as possible. Listing 3: Prompt for extracting differences from the guideline trajectory. ### Assignment You are evaluating whether the **prior** and **current** clinical guideline recommendations shown below exhibit a **strict head-to-head change**.,→ Your task is to determine whether the current recommendation truly replaces,...
2023
-
[56]
Test APPLICATION of knowledge, not recall of isolated facts
-
[57]
Use a clinical vignette structured as: - patient demographics - chief complaint - relevant history - physical examination - laboratory or imaging findings
-
[58]
Write a CLOSED and FOCUSED lead-in question. Acceptable lead-ins include: - Which of the following is the most appropriate next step in management? - Which of the following is recommended according to the guideline? - Which of the following interventions should be initiated? Avoid vague lead-ins such as: - Which statement is true? - What is associated wit...
-
[59]
Rules for options: - Only ONE option is the best answer
Create EXACTLY FOUR answer options (A–D). Rules for options: - Only ONE option is the best answer. - All options must be HOMOGENEOUS (same category such as treatments, tests, or diagnoses).,→ - Distractors must be medically plausible. - Options must have similar length and grammatical structure
-
[60]
- Avoid vague terms such as'often','usually','frequently'
Avoid technical flaws: - Do NOT use'all of the above'or'none of the above'. - Avoid vague terms such as'often','usually','frequently'. - Avoid absolute terms such as'always'or'never'. - Avoid grammatical cues that reveal the correct answer. - Avoid repeating distinctive words from the vignette in only one option
-
[61]
Apply the COVER-THE-OPTIONS rule: A knowledgeable reader should be able to infer the correct answer after reading the vignette and lead-in before seeing the options.,→
-
[62]
Ensure the question tests clinical reasoning and guideline application. Important: Do not encode the guideline change into the patient scenario unless the guideline explicitly conditions the recommendation on those features.,→ Listing 5: Prompt for generating NBME-style QA questions from the extracted difference. C Examples C.1 Examples of the Extracted G...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.