Recognition: unknown
What to Ignore, What to React: Visually Robust RL Fine-Tuning of VLA Models
Pith reviewed 2026-05-14 18:41 UTC · model grok-4.3
The pith
PAIR-VLA adds invariance and sensitivity objectives over paired visual variants to improve RL fine-tuning of VLA models under visual shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PAIR-VLA augments PPO optimization with an invariance objective that reduces action-distribution discrepancy on task-preserving visual pairs and a sensitivity objective that encourages separable distributions on task-altering pairs, converting visual variants into explicit guidance on which changes the policy must react to.
What carries the argument
The PAIR-VLA framework, which supplies paired action invariance and sensitivity objectives derived from task-preserving and task-altering visual variants during PPO fine-tuning of VLA policies.
If this is right
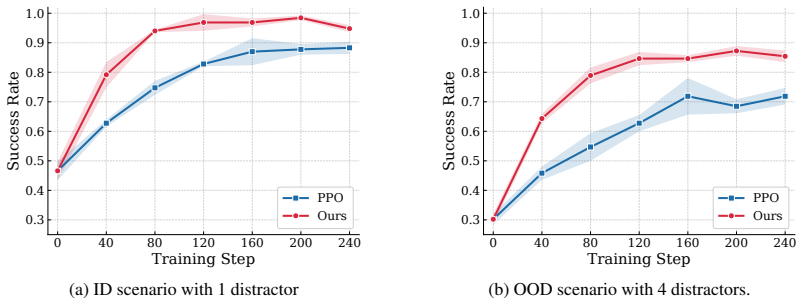
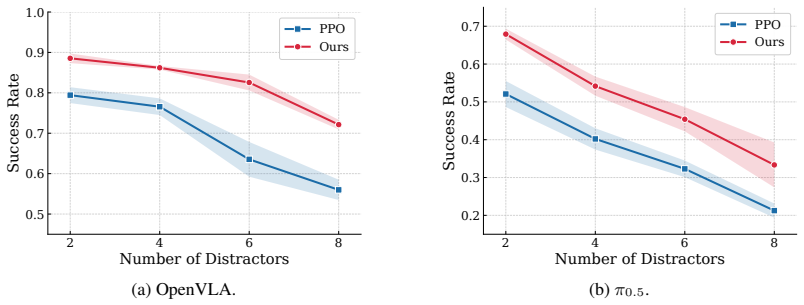
- Policies trained with PAIR-VLA achieve average success-rate gains of 16.62 percent on π0.5 and 9.10 percent on OpenVLA under diverse out-of-distribution visual conditions.
- Invariance signals learned from distractor and texture pairs transfer to unseen target-pose and lighting shifts.
- Sensitivity guidance applied to target-pose variants further strengthens robustness to nuisance variations.
- The method works across two representative VLA architectures without architecture-specific changes.
Where Pith is reading between the lines
- The transfer pattern suggests that behavior-level pairing can reduce the volume of real-world data needed by letting one set of variants inform robustness to others.
- If paired variants can be synthesized from simulation or self-supervised discovery, the same objectives could be applied to non-visual modalities such as tactile or audio shifts.
- In deployment, the learned distinction between ignore and react might allow robots to maintain performance with fewer retraining cycles when environments change gradually.
Load-bearing premise
That paired visual variants can be generated or labeled so they reliably separate task-preserving from task-altering changes without adding new biases.
What would settle it
Running the same PPO fine-tuning with and without the paired invariance and sensitivity terms on identical visual-shift test suites and observing no consistent success-rate gain or a reversal would falsify the central claim.
Figures


read the original abstract
Reinforcement learning (RL) fine-tuning has shown promise for Vision-Language-Action (VLA) models in robotic manipulation, but deployment-time visual shifts pose practical challenges. A key difficulty is that standard task rewards supervise task success, but offer limited guidance on whether a visual change is task-irrelevant or changes the behavior required for manipulation. We propose PAIR-VLA (Paired Action Invariance & Sensitivity for Visually Robust VLA), an RL fine-tuning framework to address this difficulty by adding two auxiliary objectives over paired visual variants during PPO optimization: an invariance term that reduces the discrepancy between action distributions for a task-preserving pair (e.g., different distractors), and a sensitivity objective that encourages separable action distributions for a task-altering pair (e.g., target object in a different pose). Together, these objectives turn visual variants from mere observation diversity into behavior-level guidance on policy responses during RL fine-tuning. We evaluate on ManiSkill3 across two representative VLA architectures, OpenVLA and $\pi_{0.5}$, under diverse out-of-distribution visual shifts including unseen distractors, texture changes, target object pose variation, viewpoint shifts, and lighting changes. Our method consistently improves over standard PPO, achieving average improvements of 16.62% on $\pi_{0.5}$ and 9.10% on OpenVLA. Notably, ablations further show generalization across visual shifts: invariance guidance learned from distractor and texture variants transfers to target-pose and lighting shifts, while adding sensitivity guidance on target-pose variants further improves robustness to nuisance shifts, highlighting the broader transferability of behavior-level RL guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PAIR-VLA, an RL fine-tuning framework for VLA models that augments PPO with two auxiliary objectives over paired visual variants: an invariance term reducing action-distribution discrepancy on task-preserving pairs (e.g., distractor changes) and a sensitivity term increasing discrepancy on task-altering pairs (e.g., target pose changes). Evaluated on ManiSkill3 with OpenVLA and π_{0.5} across five OOD visual shifts (unseen distractors, textures, poses, viewpoints, lighting), it reports average gains of 16.62% and 9.10% over standard PPO, with ablations indicating transfer of invariance guidance across shift types.
Significance. If the results hold, the work supplies a concrete mechanism for converting visual diversity into behavior-level supervision during RL fine-tuning, addressing a practical gap in VLA robustness. The reported cross-shift transfer in ablations is a positive signal for broader applicability in manipulation tasks.
major comments (2)
- [Abstract and Evaluation] Abstract and Evaluation section: the central performance claims (average 16.62% gain on π_{0.5}, 9.10% on OpenVLA) are stated without error bars, number of random seeds, or statistical significance tests. In RL settings with high variance, this omission makes it impossible to assess whether the reported improvements are reliable or could be explained by training stochasticity.
- [Method (PAIR-VLA)] Method section describing PAIR-VLA: the invariance and sensitivity objectives are only valid if task-preserving versus task-altering pairs are correctly generated and labeled. The manuscript supplies no concrete procedure, algorithm, or criteria for constructing these pairs during training, leaving open the possibility that mislabeling (e.g., pose changes treated as distractors) would invert the intended gradients and nullify or reverse the gains over PPO.
minor comments (1)
- [Introduction] Notation for the two base models (OpenVLA and π_{0.5}) should be introduced once with consistent subscripts and then used uniformly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical reporting and methodological clarity. We agree that both points identify genuine gaps in the current manuscript and will revise accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and Evaluation] Abstract and Evaluation section: the central performance claims (average 16.62% gain on π_{0.5}, 9.10% on OpenVLA) are stated without error bars, number of random seeds, or statistical significance tests. In RL settings with high variance, this omission makes it impossible to assess whether the reported improvements are reliable or could be explained by training stochasticity.
Authors: We fully agree. The reported averages were computed over multiple runs but the manuscript omitted the supporting statistics. In the revision we will rerun the full evaluation suite with 5 independent random seeds per method and environment, report mean ± standard deviation as error bars on all tables and figures, and include paired t-test p-values comparing PAIR-VLA against standard PPO. These additions will be placed in the Evaluation section and referenced from the abstract. revision: yes
-
Referee: [Method (PAIR-VLA)] Method section describing PAIR-VLA: the invariance and sensitivity objectives are only valid if task-preserving versus task-altering pairs are correctly generated and labeled. The manuscript supplies no concrete procedure, algorithm, or criteria for constructing these pairs during training, leaving open the possibility that mislabeling (e.g., pose changes treated as distractors) would invert the intended gradients and nullify or reverse the gains over PPO.
Authors: We acknowledge the omission. The original implementation distinguishes pairs by whether the underlying manipulation task (object identity, goal pose, grasp location) remains identical. Task-preserving pairs are generated by applying visual augmentations (distractor insertion, texture swap, lighting shift, viewpoint change) while freezing object poses and goal specifications; task-altering pairs are generated by perturbing target object poses or goal locations while keeping visual appearance otherwise fixed. We will add a dedicated subsection (3.3) with pseudocode, explicit labeling rules, and an example of how pairs are sampled on-the-fly during PPO rollouts to make the procedure fully reproducible. revision: yes
Circularity Check
No significant circularity; auxiliary objectives supply independent behavior-level guidance on held-out shifts
full rationale
The paper defines PAIR-VLA by adding an invariance term (reducing action discrepancy on task-preserving pairs) and sensitivity term (increasing discrepancy on task-altering pairs) as auxiliary objectives inside standard PPO. These terms are constructed from explicitly generated or labeled visual variant pairs and are evaluated on held-out OOD visual shifts (unseen distractors, textures, poses, viewpoints, lighting). No equation reduces the reported 9-16% gains to a fitted parameter by construction, no self-citation is load-bearing for the central claim, and no ansatz or uniqueness result is smuggled in. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Paired visual variants can be generated such that one pair preserves required action and the other alters it
Reference graph
Works this paper leans on
-
[1]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[2]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnik...
2023
-
[4]
Octo: An open-source generalist robot policy, 2024
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yun- liang Chen, Pannag Sanketi, Quan Vuong, Ted Xiao, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy, 2024
2024
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
What makes pre-trained visual representations successful for robust manipulation?, 2023
Kaylee Burns, Zach Witzel, Jubayer Ibn Hamid, Tianhe Yu, Chelsea Finn, and Karol Hausman. What makes pre-trained visual representations successful for robust manipulation?, 2023
2023
-
[7]
Shortcut learning in generalist robot policies: The role of dataset diversity and fragmentation, 2025
Youguang Xing, Xu Luo, Junlin Xie, Lianli Gao, Hengtao Shen, and Jingkuan Song. Shortcut learning in generalist robot policies: The role of dataset diversity and fragmentation, 2025
2025
-
[8]
Simplevla-rl: Scaling vla training via reinforcement learning, 2025
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, Dehui Wang, Dingxiang Luo, Yuchen Fan, Youbang Sun, Jia Zeng, Jiangmiao Pang, Shanghang Zhang, Yu Wang, Yao Mu, Bowen Zhou, and Ning Ding. Simplevla-rl: Scaling vla training via reinforcement learning, 2025
2025
-
[9]
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, et al. Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation.arXiv preprint arXiv:2509.15965, 2025
-
[10]
What can rl bring to vla generalization? an empirical study, 2026
Jijia Liu, Feng Gao, Bingwen Wei, Xinlei Chen, Qingmin Liao, Yi Wu, Chao Yu, and Yu Wang. What can rl bring to vla generalization? an empirical study, 2026
2026
-
[11]
Kang Chen, Zhihao Liu, Tonghe Zhang, Zhen Guo, Si Xu, Hao Lin, Hongzhi Zang, Xiang Li, Quanlu Zhang, Zhaofei Yu, Guoliang Fan, Tiejun Huang, Yu Wang, and Chao Yu.πRL: Online rl fine-tuning for flow-based vision-language-action models, 2026
2026
-
[12]
Rlinf-vla: A unified and efficient framework for reinforcement learning of vision-language-action models, 2026
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Peihong Wang, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, Zhihao Liu, Kang Chen, Wenhao Tang, Quanlu Zhang, Weinan Zhang, Chao Yu, and Yu Wang. Rlinf-vla: A unified and efficient framework for reinforcement learning of vision-language-action models, 2026
2026
-
[13]
Hongyin Zhang, Shuo Zhang, Junxi Jin, Qixin Zeng, Runze Li, and Donglin Wang. Robustvla: Robustness-aware reinforcement post-training for vision-language-action models.arXiv preprint arXiv:2511.01331, 2025. 11
-
[14]
Image augmentation is all you need: Regularizing deep reinforcement learning from pixels, 2021
Ilya Kostrikov, Denis Yarats, and Rob Fergus. Image augmentation is all you need: Regularizing deep reinforcement learning from pixels, 2021
2021
-
[15]
Reinforcement learning with augmented data, 2020
Michael Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, and Aravind Srinivas. Reinforcement learning with augmented data, 2020
2020
-
[16]
Mastering visual continuous control: Improved data-augmented reinforcement learning, 2021
Denis Yarats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Mastering visual continuous control: Improved data-augmented reinforcement learning, 2021
2021
-
[17]
Domain randomization for transferring deep neural networks from simulation to the real world
Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017
2017
-
[18]
Training deep networks with synthetic data: Bridging the reality gap by domain randomization
Jonathan Tremblay, Aayush Prakash, David Acuna, Mark Brophy, Varun Jampani, Cem Anil, Thang To, Eric Cameracci, Shaad Boochoon, and Stan Birchfield. Training deep networks with synthetic data: Bridging the reality gap by domain randomization. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 969–977, 2018
2018
-
[19]
Active domain randomization
Bhairav Mehta, Manfred Diaz, Florian Golemo, Christopher J Pal, and Liam Paull. Active domain randomization. InConference on Robot Learning, pages 1162–1176. PMLR, 2020
2020
-
[20]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse-kai Chan, et al. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.arXiv preprint arXiv:2410.00425, 2024
-
[22]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: A vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine-tuning
Jiaheng Hu, Rose Hendrix, Ali Farhadi, Aniruddha Kembhavi, Roberto Martín-Martín, Peter Stone, Kuo-Hao Zeng, and Kiana Ehsani. Flare: Achieving masterful and adaptive robot policies with large-scale reinforcement learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3617–3624. IEEE, 2025
2025
-
[25]
Fine-tuning vision-language-action models: Optimizing speed and success, 2025
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success, 2025
2025
-
[26]
Bram Grooten, Tristan Tomilin, Gautham Vasan, Matthew E Taylor, A Rupam Mahmood, Meng Fang, Mykola Pechenizkiy, and Decebal Constantin Mocanu. Madi: Learning to mask distrac- tions for generalization in visual deep reinforcement learning.arXiv preprint arXiv:2312.15339, 2023
-
[27]
Sangmim Song, Sarath Kodagoda, Marc Carmichael, and Karthick Thiyagarajan. Overcoming visual clutter in vision language action models via concept-gated visual distillation.arXiv preprint arXiv:2603.10340, 2026
-
[28]
Policy Contrastive Decoding for Robotic Foundation Models
Shihan Wu, Xu Luo, Ji Zhang, Junlin Xie, Jingkuan Song, Heng Tao Shen, and Lianli Gao. Policy contrastive decoding for robotic foundation models.arXiv preprint arXiv:2505.13255, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Hancock, Allen Z
Asher J. Hancock, Allen Z. Ren, and Anirudha Majumdar. Run-time observation interventions make vision-language-action models more visually robust, 2024
2024
-
[30]
Scaling robot learning with semantically imagined experience.arXiv preprint arXiv:2302.11550, 2023
Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Jodilyn Peralta, Brian Ichter, et al. Scaling robot learning with semantically imagined experience.arXiv preprint arXiv:2302.11550, 2023. 12
-
[31]
Retinagan: An object-aware approach to sim-to-real transfer
Daniel Ho, Kanishka Rao, Zhuo Xu, Eric Jang, Mohi Khansari, and Yunfei Bai. Retinagan: An object-aware approach to sim-to-real transfer. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 10920–10926. IEEE, 2021
2021
-
[32]
Amy Zhang, Rowan McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction.arXiv preprint arXiv:2006.10742, 2020
-
[33]
A simple frame- work for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple frame- work for contrastive learning of visual representations. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1597–1607. PMLR, 13–18 Jul 2020
2020
-
[34]
Curl: Contrastive unsupervised repre- sentations for reinforcement learning
Michael Laskin, Aravind Srinivas, and Pieter Abbeel. Curl: Contrastive unsupervised repre- sentations for reinforcement learning. InInternational conference on machine learning, pages 5639–5650. PMLR, 2020
2020
-
[35]
Look where you look! saliency-guided q-networks for generalization in visual reinforcement learning.Advances in neural information processing systems, 35:30693–30706, 2022
David Bertoin, Adil Zouitine, Mehdi Zouitine, and Emmanuel Rachelson. Look where you look! saliency-guided q-networks for generalization in visual reinforcement learning.Advances in neural information processing systems, 35:30693–30706, 2022
2022
-
[36]
Salience-invariant consistent policy learning for generalization in visual reinforcement learning, 2025
Jingbo Sun, Songjun Tu, Qichao Zhang, Ke Chen, and Dongbin Zhao. Salience-invariant consistent policy learning for generalization in visual reinforcement learning, 2025
2025
-
[37]
Invariance co-training for robot visual generalization.arXiv preprint arXiv:2512.05230, 2025
Jonathan Yang, Chelsea Finn, and Dorsa Sadigh. Invariance co-training for robot visual generalization.arXiv preprint arXiv:2512.05230, 2025
-
[38]
Q-attention: Enabling efficient learning for vision-based robotic manipulation.IEEE Robotics and Automation Letters, 7(2):1612–1619, 2022
Stephen James and Andrew J Davison. Q-attention: Enabling efficient learning for vision-based robotic manipulation.IEEE Robotics and Automation Letters, 7(2):1612–1619, 2022
2022
-
[39]
Learning task-driven control policies via information bottlenecks, 2020
Vincent Pacelli and Anirudha Majumdar. Learning task-driven control policies via information bottlenecks, 2020
2020
-
[40]
Shuoshuo Zhang, Yizhen Zhang, Jingjing Fu, Lei Song, Jiang Bian, Yujiu Yang, and Rui Wang. See less, see right: Bi-directional perceptual shaping for multimodal reasoning.arXiv preprint arXiv:2512.22120, 2025
-
[41]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[42]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Distractor-N
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 13 A SFT and RL Training Details A.1 SFT Checkpoints The VLA models are pre-trained on large-scale demonstration data. However, they still struggle to perform the downstr...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.