Recognition: 1 theorem link
· Lean TheoremAmortized Neural Clustering of Time Series based on Statistical Features
Pith reviewed 2026-05-14 18:17 UTC · model grok-4.3
The pith
Neural networks trained on simulated time series learn to cluster real data from statistical features without choosing algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that training neural networks to approximate the optimal partitioning rule from statistical features of simulated time series produces an amortized inference procedure that recovers clusters on real data without explicit algorithm choice, objective functions, or prior specification of cluster shapes, with one variant also determining the number of clusters automatically.
What carries the argument
An amortized neural network trained to approximate the optimal partitioning rule from statistical features such as autocorrelations and quantile autocorrelations of simulated time series.
If this is right
- The method reduces reliance on selecting and tuning specific clustering algorithms and their heuristics.
- One implementation variant removes the need for ad-hoc procedures to choose the number of clusters.
- Clustering accuracy remains competitive or superior even when traditional methods receive the true cluster count.
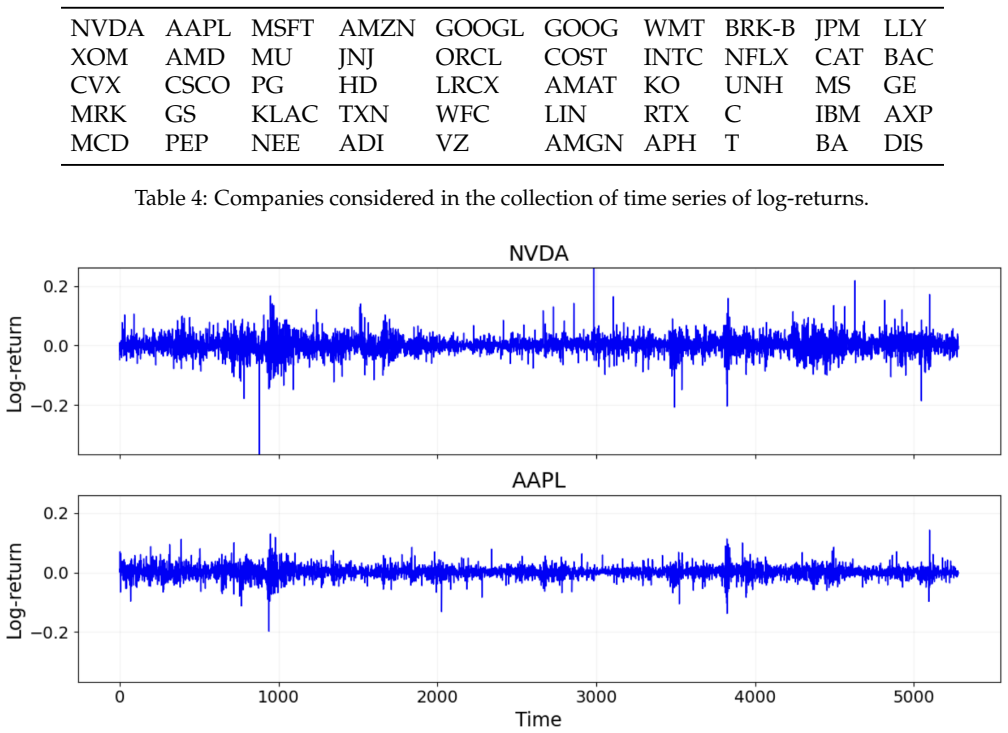
- The framework applies directly to domains such as financial time series of stock returns.
Where Pith is reading between the lines
- Periodic retraining on updated simulations could support clustering of streaming time series data.
- The same simulation-to-real transfer principle might extend to other unsupervised tasks that rely on statistical summaries.
- If simulations are generated to match target domain statistics closely, the approach could enable fully unsupervised clustering pipelines with minimal manual feature engineering.
Load-bearing premise
The optimal partitioning rule learned from simulated data transfers effectively to real-world time series without significant domain shift issues.
What would settle it
A real time series dataset on which the neural model trained on matching simulations yields substantially lower accuracy than conventional methods given the true number of clusters.
Figures






read the original abstract
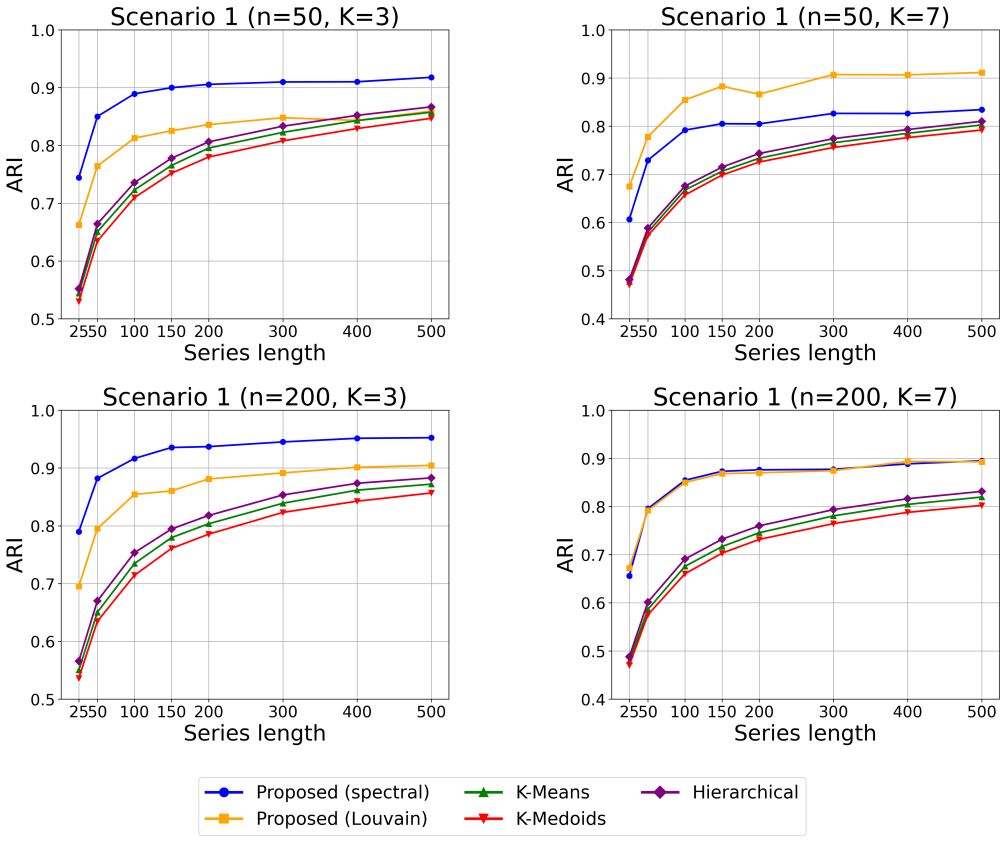
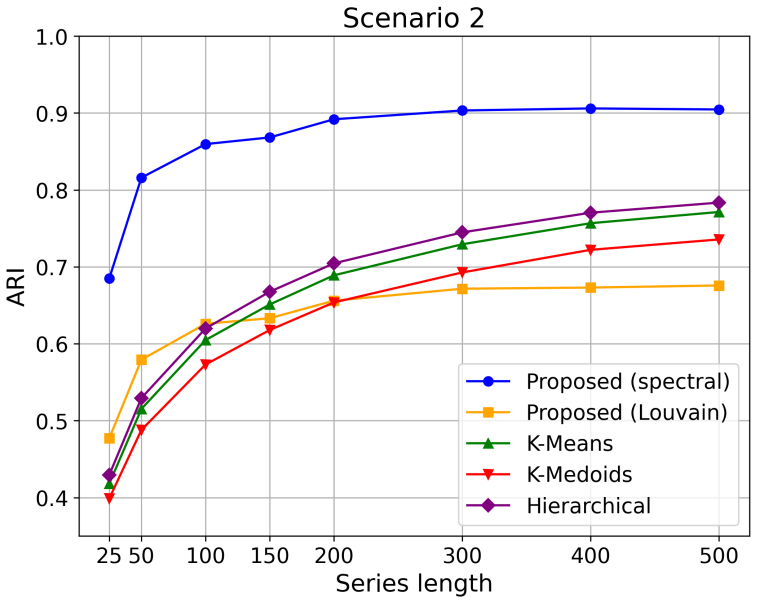
This paper introduces an algorithm-agnostic approach to feature-based time series clustering via amortized neural inference. By training neural networks to approximate the optimal partitioning rule from simulated data, the proposed framework reduces reliance on conventional clustering methods, such as $K$-means, $K$-medoids, or hierarchical clustering, and their associated objective functions and heuristics. Leveraging statistical features, such as autocorrelations and quantile autocorrelations, the approach learns a data-driven affinity structure from which clustering partitions can be recovered, without requiring explicit prior specification of cluster shapes or structures. In addition, one version of the method can automatically determine the number of clusters, avoiding ad-hoc selection procedures. Comprehensive empirical studies show that the proposed framework achieves competitive or superior clustering accuracy relative to traditional methods, even in challenging scenarios where competing techniques are provided with the true number of clusters. An application to financial time series of stock returns illustrates its practical utility. By reducing the need for algorithm selection and calibration, the proposed framework opens new possibilities for automated, adaptive, and data-driven clustering of temporal data across scientific and industrial domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an amortized neural inference framework for feature-based time series clustering. Neural networks are trained on simulated data to approximate an optimal partitioning rule using statistical features such as autocorrelations and quantile autocorrelations; the learned rule is then applied to recover clusters on real data without explicit specification of cluster shapes. A variant automatically determines the number of clusters. The central empirical claim is that the approach achieves competitive or superior clustering accuracy relative to traditional methods (K-means, K-medoids, hierarchical clustering), even when those baselines receive the true number of clusters, with an illustrative application to financial stock-return series.
Significance. If the simulation-to-real transfer is robust, the method could reduce reliance on algorithm selection and hyperparameter tuning in time series clustering, offering a more automated, data-driven alternative. The amortized formulation and use of statistical features are conceptually attractive for scalability. The automatic cluster-number variant addresses a common practical pain point. However, the absence of detailed experimental protocols, validation of simulation parameters against real-data moments, and quantitative results makes it impossible to gauge whether these advantages materialize.
major comments (2)
- [Abstract] Abstract: the claim of 'comprehensive empirical studies' showing competitive or superior accuracy is unsupported by any description of datasets, baselines (with or without oracle cluster count), metrics, error bars, or statistical tests. This directly undermines evaluation of the central performance claim.
- [Method and empirical sections] Method and empirical sections: the simulation-to-real transfer of the learned partitioning rule is load-bearing for all accuracy claims on real data, including the financial application. No information is supplied on how simulation parameters were chosen or validated to reproduce real-data moments (e.g., autocorrelation structure), leaving open the possibility that reported gains are artifacts of the simulation design rather than genuine generalization.
minor comments (2)
- [Method] Clarify whether the neural network outputs a hard partition or a soft assignment matrix, and how the final clustering is extracted in the automatic-K variant.
- [Feature extraction] Add a table or figure summarizing the statistical features used (autocorrelations, quantile autocorrelations, etc.) with their exact definitions and lag ranges.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'comprehensive empirical studies' showing competitive or superior accuracy is unsupported by any description of datasets, baselines (with or without oracle cluster count), metrics, error bars, or statistical tests. This directly undermines evaluation of the central performance claim.
Authors: We agree that the abstract is too concise and does not adequately preview the empirical setup. The full manuscript describes synthetic datasets generated from ARMA, GARCH and other models, real financial stock-return series, baselines consisting of K-means, K-medoids and hierarchical clustering (both with and without the oracle number of clusters), and evaluation via clustering accuracy and adjusted Rand index with standard errors from repeated runs. We will revise the abstract to briefly reference these elements so that the performance claims are properly contextualized. revision: yes
-
Referee: [Method and empirical sections] Method and empirical sections: the simulation-to-real transfer of the learned partitioning rule is load-bearing for all accuracy claims on real data, including the financial application. No information is supplied on how simulation parameters were chosen or validated to reproduce real-data moments (e.g., autocorrelation structure), leaving open the possibility that reported gains are artifacts of the simulation design rather than genuine generalization.
Authors: We acknowledge that explicit validation of the simulation design is necessary to support the transfer claims. Simulation parameters were drawn from standard ranges for ARMA, MA and GARCH processes chosen to produce realistic autocorrelation and volatility patterns. In the revised manuscript we will add a dedicated subsection that (i) states the exact parameter ranges, (ii) reports moment-matching diagnostics (autocorrelation functions and quantile autocorrelations) between simulated and real data, and (iii) includes a sensitivity study showing robustness to moderate changes in simulation parameters. This material will be placed in the method section before the real-data experiments. revision: yes
Circularity Check
No circularity: independent simulation training with external validation
full rationale
The derivation trains neural networks on independently generated simulated time series to approximate an optimal partitioning rule from statistical features, then applies the fixed model to real data without refitting. This is self-contained because the training distribution is constructed separately from the target evaluation sets, with no equations or steps that reduce the reported accuracy to a fit on the same data by construction. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises, and the competitive accuracy claims rest on direct comparison to baseline methods on held-out real series rather than renaming or self-referential prediction.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of clusters (in some versions)
axioms (1)
- domain assumption Simulated data can be generated to represent real clustering scenarios
Reference graph
Works this paper leans on
-
[1]
Aghabozorgi, S., Shirkhorshidi, A. S. and Wah, T. Y. (2015), ‘Time-series clustering – a decade review’,Information Systems53, 16–38
work page 2015
-
[2]
Alelyani, S., Tang, J. and Liu, H. (2013), Feature selection for clustering: A review,inC. C. Aggarwal and C. K. Reddy, eds, ‘Data Clustering: Algorithms and Applications’, CRC Press, pp. 29–60
work page 2013
-
[3]
Alonso, A. M., Nogales, F. J. and Ruiz, C. (2020), ‘Hierarchical clustering for smart meter electricity loads based on quantile autocovariances’,IEEE Transactions on Smart Grid11(5), 4522–4530. 30 Ann Maharaj, E., D’Urso, P . and Galagedera, D. U. (2010), ‘Wavelet-based fuzzy clustering of time series’,Journal of Classification27(2), 231–275
work page 2020
-
[4]
Ardia, D. and Hoogerheide, L. F. (2010), ‘Bayesian estimation of the GARCH(1,1) model with Student-t innovations’,The R Journal2(2), 41–47
work page 2010
-
[5]
Beaumont, M. A. (2010), ‘Approximate Bayesian computation in evolution and ecology’,Annual Review of Ecology, Evolution, and Systematics41(1), 379–406
work page 2010
-
[6]
Beaumont, M. A., Zhang, W. and Balding, D. J. (2002), ‘Approximate Bayesian computation in population genetics’,Genetics162(4), 2025–2035
work page 2002
-
[7]
D., Guillaume, J.-L., Lambiotte, R
Blondel, V . D., Guillaume, J.-L., Lambiotte, R. and Lefebvre, E. (2008), ‘Fast unfolding of communi- ties in large networks’,Journal of Statistical Mechanics: Theory and Experiment2008, P10008
work page 2008
-
[8]
Bollerslev, T. (1986), ‘Generalized autoregressive conditional heteroskedasticity’,Journal of Econo- metrics31(3), 307–327
work page 1986
-
[9]
Bougerol, P . and Picard, N. (1992), ‘Stationarity of GARCH processes and of some nonnegative time series’,Journal of Econometrics52(1-2), 115–127
work page 1992
-
[10]
Cranmer, K., Brehmer, J. and Louppe, G. (2020), ‘The frontier of simulation-based inference’, Proceedings of the National Academy of Sciences117(48), 30055–30062. De Gooijer, J. G. and De Bruin, P . T. (1998), ‘On forecasting setar processes’,Statistics & Probability Letters37(1), 7–14
work page 2020
-
[11]
(1960), ‘The fitting of time-series models’,Revue de l’Institut International de Statistique pp
Durbin, J. (1960), ‘The fitting of time-series models’,Revue de l’Institut International de Statistique pp. 233–244. D’Urso, P ., De Giovanni, L. and Massari, R. (2016), ‘GARCH-based robust clustering of time series’, Fuzzy Sets and Systems305, 1–28. D’Urso, P . and Maharaj, E. A. (2012), ‘Wavelets-based clustering of multivariate time series’,Fuzzy Sets ...
work page 1960
-
[12]
Engle, R. F. (1982), ‘Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation’,Econometrica: Journal of the Econometric Societypp. 987–1007
work page 1982
-
[13]
Fong, S., Deb, S., Yang, X.-S. and Zhuang, Y. (2014), ‘Towards enhancement of performance of K-means clustering using nature-inspired optimization algorithms’,The Scientific World Journal 2014(1), 564829
work page 2014
-
[14]
Francq, C. and Zakoian, J.-M. (2019),GARCH models: structure, statistical inference and financial applications, John Wiley & Sons
work page 2019
-
[15]
Fu, T. C. et al. (2011), ‘A review on time series data mining’,Engineering Applications of Artificial Intelligence24(1), 164–181. Gonc ¸alves, P . J., Lueckmann, J.-M., Deistler, M., Nonnenmacher, M.,¨Ocal, K., Bassetto, G., Chin- taluri, C., Podlaski, W. F., Haddad, S. A., Vogels, T. P . et al. (2020), ‘Training deep neural density estimators to identify...
work page 2011
-
[16]
Harris, S. and De Amorim, R. C. (2022), ‘An extensive empirical comparison ofK-means initializa- tion algorithms’,Ieee Access10, 58752–58768
work page 2022
-
[17]
Neural network-based clustering using pairwise constraints
Hsu, Y.-C. and Kira, Z. (2015), ‘Neural network-based clustering using pairwise constraints’,arXiv preprint arXiv:1511.06321
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[18]
Huang, D., Bharti, A., Souza, A., Acerbi, L. and Kaski, S. (2023), ‘Learning robust statistics for simulation-based inference under model misspecification’,Advances in Neural Information Processing Systems36, 7289–7310
work page 2023
-
[19]
Hubert, L. J. and Arabie, P . (1985), ‘Comparing partitions’,Journal of Classification2, 193–218
work page 1985
-
[20]
Kingma, D. P . and Welling, M. (2013), ‘Auto-encoding variational bayes’,arXiv preprint arXiv:1312.6114. 32
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[21]
Kuzudisli, C., Hasan, S., Zain, J. and Yahya, A. (2023), ‘Review of feature selection approaches based on grouping of features’,PeerJ11, e15666
work page 2023
-
[22]
Lafuente-Rego, B., D’Urso, P . and Vilar, J. A. (2020), ‘Robust fuzzy clustering based on quantile autocovariances’,Statistical Papers61(6), 2393–2448
work page 2020
-
[23]
Lafuente-Rego, B. and Vilar, J. A. (2016), ‘Clustering of time series using quantile autocovariances’, Advances in Data Analysis and Classification10(3), 391–415
work page 2016
-
[24]
Liu, H., Wang, J. and Jing, L. (2021), Cluster-wise hierarchical generative model for deep amortized clustering,in‘Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition’, pp. 15109–15118
work page 2021
-
[25]
Liu, Y., Li, Z., Xiong, H., Gao, X. and Wu, J. (2010), Understanding of internal clustering validation measures,in‘2010 IEEE international conference on data mining’, Ieee, pp. 911–916. L´opez-Oriona, ´A., D’Urso, P ., Vilar, J. A. and Lafuente-Rego, B. (2021), ‘Spatial weighted robust clustering of multivariate time series based on quantile dependence wi...
work page 2010
-
[26]
Lu, Z. (2007), Semi-supervised clustering with pairwise constraints: A discriminative approach,in ‘Artificial Intelligence and Statistics’, PMLR, pp. 299–306
work page 2007
-
[27]
Madhulatha, T. S. (2011), Comparison between K-means and K-medoids clustering algorithms,in ‘International Conference on Advances in Computing and Information Technology’, Springer, pp. 472–481
work page 2011
-
[28]
Maharaj, E. A., D’Urso, P . and Caiado, J. (2019),Time series clustering and classification, Chapman and Hall/CRC. 33
work page 2019
-
[29]
Mirkin, B. (2011), ‘Choosing the number of clusters’,Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery1(3), 252–260
work page 2011
-
[30]
Montero-Manso, P . and Hyndman, R. J. (2021), ‘Principles and algorithms for forecasting groups of time series: Locality and globality’,International Journal of Forecasting37(4), 1632–1653
work page 2021
-
[31]
Ng, A., Jordan, M. I. and Weiss, Y. (2001), On spectral clustering: Analysis and an algorithm,in ‘Neural Information Processing Systems’
work page 2001
-
[32]
Pakman, A., Wang, Y., Mitelut, C., Lee, J. and Paninski, L. (2020), ‘Neural clustering processes’, arXiv preprint arXiv:1901.00409
-
[33]
Papamakarios, G., Sterratt, D. and Murray, I. (2019), Sequential neural likelihood: Fast likelihood- free inference with autoregressive flows,in‘The 22nd international conference on artificial intelligence and statistics’, PMLR, pp. 837–848
work page 2019
-
[34]
Paparrizos, J. et al. (2024), ‘A comprehensive survey of time series clustering’,ACM Computing Surveys57(3), 1–45
work page 2024
-
[35]
Piccolo, D. (1990), ‘A distance measure for classifying arima models’,Journal of Time Series Analysis 11(2), 153–164
work page 1990
-
[36]
Pitman, J. (2006),Combinatorial stochastic processes: Ecole d’et´ e de probabilit´ es de saint-flour xxxii-2002, Springer Science & Business Media
work page 2006
-
[37]
Price, L. F., Drovandi, C. C., Lee, A. and Nott, D. J. (2018), ‘Bayesian synthetic likelihood’,Journal of Computational and Graphical Statistics27(1), 1–11
work page 2018
-
[38]
Rodriguez, M. Z., Comin, C. H., Casanova, D., Bruno, O. M., Amancio, D. R., Costa, L. d. F. and Ro- drigues, F. A. (2019), ‘Clustering algorithms: A comparative approach’,PloS One14(1), e0210236
work page 2019
-
[39]
Ryan, J. A. and Ulrich, J. M. (2025),quantmod: Quantitative Financial Modelling Framework. R package version 0.4.28. URL:https://CRAN.R-project.org/package=quantmod
work page 2025
-
[40]
Sadeghi, M. and Armanfard, N. (2024), ‘Deep clustering with self-supervision using pairwise similarities’,arXiv preprint arXiv:2405.03590. 34
-
[41]
Schubert, E. (2023), ‘Stop using the elbow criterion forK-means and how to choose the number of clusters instead’,ACM SIGKDD Explorations Newsletter25(1), 36–42
work page 2023
-
[42]
Thorndike, R. L. (1953), ‘Who belongs in the family?’,Psychometrika18(4), 267–276
work page 1953
-
[43]
Tong, C., Hansen, P . R. and Archakov, I. (2026), ‘Cluster garch’,Journal of Business & Economic Statistics44(1), 148–161
work page 2026
-
[44]
(2012),Threshold models in non-linear time series analysis, Springer Science & Business Media
Tong, H. (2012),Threshold models in non-linear time series analysis, Springer Science & Business Media
work page 2012
-
[45]
Tsay, R. S. (2005),Analysis of financial time series, John Wiley & Sons. Van der Maaten, L. and Hinton, G. (2008), ‘Visualizing data using t-sne.’,Journal of Machine Learning Research9(11). von Luxburg, U. (2007), ‘A tutorial on spectral clustering’,Statistics and Computing17, 395–416
work page 2005
-
[46]
Wang, X., Wirth, A. and Wang, L. (2007), ‘Structure-based statistical features and multivariate time series clustering’,Seventh IEEE International Conference on Data Mining (ICDM 2007)pp. 351–360
work page 2007
-
[47]
Zaheer, M., Kottur, S., Ravanbakhsh, S., P´oczos, B., Salakhutdinov, R. and Smola, A. J. (2017), Deep sets,in‘Advances in Neural Information Processing Systems’
work page 2017
-
[48]
Zammit-Mangion, A., Sainsbury-Dale, M. and Huser, R. (2025), ‘Neural methods for amortized inference’,Annual Review of Statistics and Its Application12, 311–335. 35
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.