Recognition: no theorem link
ERPPO: Entropy Regularization-based Proximal Policy Optimization
Pith reviewed 2026-05-14 19:29 UTC · model grok-4.3
The pith
ERPPO adds a DSA-based ambiguity estimator to MAPPO and switches between L1 and L2 entropy regularization to improve exploration and stability in non-stationary multi-dimensional observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on a testbed with AirSim-based maritime searching scenarios show that the proposed ERPPO improves accuracy performance. Our proposed method improves higher gradient than MAPPO. Qualitative results confirm that ERPPO effectiveness in terms of suppressing false detection in visually uncertain conditions.
Load-bearing premise
That the DSA learner produces a reliable scalar measure of object detection ambiguity under non-stationary multi-agent observations and that switching between L1 and L2 entropy regularization on the basis of this scalar improves policy quality without introducing instability or bias.
Figures




read the original abstract
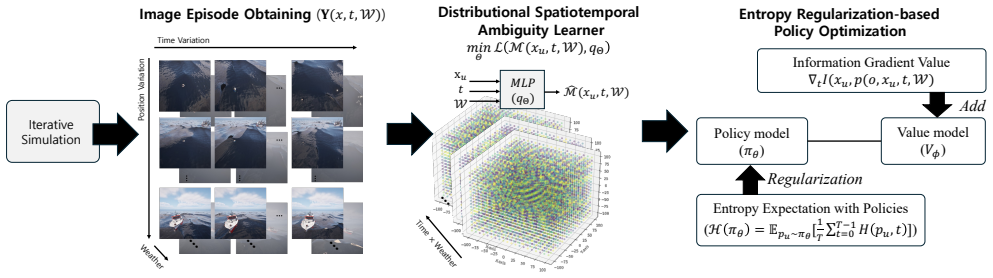
Multi-Agent Proximal Policy Optimization (MAPPO) is a variant of the Proximal Policy Optimization (PPO) algorithm, specifically tailored for multi-agent reinforcement learning (MARL). MAPPO optimizes cooperative multi-agent settings by employing a centralized critic with decentralized actors. However, in case of multi-dimensional environment, MAPPO can not extract optimal policy due to non-stationary agent observation. To overcome this problem, we introduce a novel approach, Entropy Regularization-based Proximal Policy Optimization (ERPPO). For the policy optimization, we first define the object detection ambiguity under multi-dimensional observation environment. Distributional Spatiotemporal Ambiguity (DSA) learner is trained to estimate object detection uncertainty in non-stationary constraints. Then, we enhance PPO with a novel Entropy Regularization term. This regularization dynamically adjusts the policy update by applying a stronger (L1) regularization in high-ambiguity observation to encourage significant exploratory actions and a weaker (L2) regularization in low-ambiguity observation to stabilize the proximal policy optimization. This approach is designed to enhance the probability of successful object localization in time-critical operations by reducing detection failures and optimizing search policy. Experiments on a testbed with AirSim-based maritime searching scenarios show that the proposed ERPPO improves accuracy performance. Our proposed method improves higher gradient than MAPPO. Qualitative results confirm that ERPPO effectiveness in terms of suppressing false detection in visually uncertain conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ERPPO as an extension of MAPPO for multi-agent reinforcement learning in non-stationary, multi-dimensional observation settings. It defines object detection ambiguity via a Distributional Spatiotemporal Ambiguity (DSA) learner and augments the PPO objective with a dynamic entropy regularization term that applies stronger L1 regularization under high ambiguity (to promote exploration) and weaker L2 regularization under low ambiguity (to stabilize updates). Experiments in AirSim-based maritime search scenarios are claimed to show improved accuracy, higher policy gradients than MAPPO, and reduced false detections in visually uncertain conditions.
Significance. If the central mechanism were shown to work, the dynamic L1/L2 switch conditioned on a learned ambiguity scalar could address a practical gap in MARL for time-critical search tasks under partial observability. The idea of tying regularization strength to an online uncertainty estimate is conceptually appealing for balancing exploration and stability. However, the manuscript supplies neither the required equations, ablation studies, nor quantitative results, so the significance cannot yet be assessed beyond the level of an untested proposal.
major comments (3)
- [Abstract and §3] Abstract and §3 (method description): the entropy regularization term is introduced as novel but no equation is given for its functional form, the precise L1-vs-L2 switching rule, or how the DSA scalar modulates the coefficient. Without this derivation it is impossible to verify that the claimed exploration/stability tradeoff is achieved rather than being an arbitrary hyper-parameter schedule.
- [Experiments] Experiments section: the claims that ERPPO “improves accuracy performance” and “improves higher gradient than MAPPO” are stated without any numerical results, tables, learning curves, or statistical tests. The absence of even a single quantitative comparison or ablation isolating the dynamic switch from fixed-entropy MAPPO leaves the central empirical claim unsupported.
- [§3.1] §3.1 (DSA learner): the manuscript asserts that the DSA learner produces a reliable scalar measure of detection ambiguity, yet provides no training objective, loss function, or validation showing correlation between this scalar and actual detection uncertainty or downstream policy improvement. This assumption is load-bearing for the entire switching mechanism.
minor comments (2)
- [Abstract] Abstract: the phrase “improves higher gradient than MAPPO” is grammatically unclear; a precise statement of the gradient-norm or advantage metric used would improve readability.
- [§3] Notation: the manuscript introduces “DSA learner” and “object detection ambiguity” without defining the input features or output range of the learner, making it difficult to reproduce the method.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that several key details were insufficiently specified in the initial submission and will revise the paper to address each point.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): the entropy regularization term is introduced as novel but no equation is given for its functional form, the precise L1-vs-L2 switching rule, or how the DSA scalar modulates the coefficient. Without this derivation it is impossible to verify that the claimed exploration/stability tradeoff is achieved rather than being an arbitrary hyper-parameter schedule.
Authors: We agree that the functional form of the entropy regularization term, the L1-vs-L2 switching rule, and the modulation by the DSA scalar were not explicitly derived. In the revised manuscript we will add the complete mathematical definition of the dynamic entropy regularization term, including the precise switching condition based on the DSA scalar and the resulting coefficient schedule, so that the exploration/stability tradeoff can be verified analytically. revision: yes
-
Referee: [Experiments] Experiments section: the claims that ERPPO “improves accuracy performance” and “improves higher gradient than MAPPO” are stated without any numerical results, tables, learning curves, or statistical tests. The absence of even a single quantitative comparison or ablation isolating the dynamic switch from fixed-entropy MAPPO leaves the central empirical claim unsupported.
Authors: We acknowledge that the current version lacks quantitative support. The revised manuscript will include numerical performance metrics, learning curves, comparison tables, ablation studies that isolate the dynamic L1/L2 switch, and statistical tests demonstrating the claimed improvements in accuracy and policy gradients over MAPPO. revision: yes
-
Referee: [§3.1] §3.1 (DSA learner): the manuscript asserts that the DSA learner produces a reliable scalar measure of detection ambiguity, yet provides no training objective, loss function, or validation showing correlation between this scalar and actual detection uncertainty or downstream policy improvement. This assumption is load-bearing for the entire switching mechanism.
Authors: We recognize that the training objective, loss function, and validation of the DSA learner were not provided. In the revision we will specify the exact loss used to train the DSA learner and include validation results showing correlation between the learned scalar and both detection uncertainty and downstream policy improvement. revision: yes
Circularity Check
No significant circularity in the ERPPO derivation chain
full rationale
The paper introduces ERPPO by first defining object detection ambiguity, training a DSA learner to estimate uncertainty under non-stationary observations, and then proposing a novel dynamic entropy regularization that applies L1 in high-ambiguity cases and L2 in low-ambiguity cases to adjust PPO updates. No equations, self-citations, or fitted parameters are shown that reduce the regularization term, the L1/L2 switch, or the claimed performance gains to quantities already present in the inputs by construction. The approach is presented as a novel enhancement without load-bearing self-references or ansatzes imported from prior author work, and the AirSim experimental results are offered as external validation rather than tautological outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Object detection ambiguity under non-stationary multi-agent observations can be quantified by a separate DSA learner.
invented entities (1)
-
DSA learner
no independent evidence
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Intelligent Transportation Systems , volume=
Maritime anomaly detection in a real-world scenario: Ever Given grounding in the Suez Canal , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2021 , publisher=
2021
-
[2]
IEEE Transactions on Signal Processing , volume=
Detecting anomalous deviations from standard maritime routes using the Ornstein--Uhlenbeck process , author=. IEEE Transactions on Signal Processing , volume=. 2018 , publisher=
2018
-
[3]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Multimedia Tools and Applications , volume=
Maritime traffic situation awareness analysis via high-fidelity ship imaging trajectory , author=. Multimedia Tools and Applications , volume=. 2024 , publisher=
2024
-
[5]
Remote Sensing , volume=
Unmanned aerial vehicles for search and rescue: A survey , author=. Remote Sensing , volume=. 2023 , publisher=
2023
-
[6]
IEEE Journal on Miniaturization for Air and Space Systems , volume=
UAV-based real-time survivor detection system in post-disaster search and rescue operations , author=. IEEE Journal on Miniaturization for Air and Space Systems , volume=. 2021 , publisher=
2021
-
[7]
Advances in neural information processing systems , volume=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in neural information processing systems , volume=
-
[8]
Journal of Machine Learning Research , volume=
Monotonic value function factorisation for deep multi-agent reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[9]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning with double q-learning , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[10]
Remote Sensing , VOLUME =
Diana, Lorenzo and Dini, Pierpaolo , TITLE =. Remote Sensing , VOLUME =. 2024 , NUMBER =
2024
-
[11]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , year=
AI Techniques for Near Real-Time Monitoring of Contaminants in Coastal Waters on Board Future Phi sat-2 Mission , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , year=
-
[12]
arXiv preprint arXiv:1910.01465 , year=
Reducing overestimation bias in multi-agent domains using double centralized critics , author=. arXiv preprint arXiv:1910.01465 , year=
-
[13]
20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) , pages=
\ SHEPHERD \ : Serving \ DNNs \ in the wild , author=. 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23) , pages=
-
[14]
IEEE Access , volume=
Region proposal and regression network for fishing spots detection from sea environment , author=. IEEE Access , volume=. 2021 , publisher=
2021
-
[15]
IEEE Open Journal of Intelligent Transportation Systems , volume=
Uncertainty estimation of pedestrian future trajectory using Bayesian approximation , author=. IEEE Open Journal of Intelligent Transportation Systems , volume=. 2022 , publisher=
2022
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Robust test-time adaptation in dynamic scenarios , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
Tent: Fully test-time adaptation by entropy minimization , author=. arXiv preprint arXiv:2006.10726 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
xview3-sar: Detecting dark fishing activity using synthetic aperture radar imagery , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Ocean Engineering , volume=
A context-aware approach for vessels’ trajectory prediction , author=. Ocean Engineering , volume=. 2023 , publisher=
2023
-
[20]
2024 International Conference on Unmanned Aircraft Systems (ICUAS) , pages=
Uav-assisted maritime search and rescue: A holistic approach , author=. 2024 International Conference on Unmanned Aircraft Systems (ICUAS) , pages=. 2024 , organization=
2024
-
[21]
IEEE Access , volume=
UAV positioning based on multi-sensor fusion , author=. IEEE Access , volume=. 2020 , publisher=
2020
-
[22]
arXiv preprint arXiv:2411.07649 , year=
Maritime Search and Rescue Missions with Aerial Images: A Survey , author=. arXiv preprint arXiv:2411.07649 , year=
-
[23]
IEEE Transactions on neural networks and learning systems , year=
Multiagent reinforcement learning with graphical mutual information maximization , author=. IEEE Transactions on neural networks and learning systems , year=
-
[24]
Advances in Neural Information Processing Systems , volume=
Mutual-information regularized multi-agent policy iteration , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
arXiv preprint arXiv:2308.07470 , year=
Symphony: Optimized DNN Model Serving using Deferred Batch Scheduling , author=. arXiv preprint arXiv:2308.07470 , year=
-
[26]
Proceedings of the 27th ACM Symposium on Operating Systems Principles , pages=
Nexus: A GPU cluster engine for accelerating DNN-based video analysis , author=. Proceedings of the 27th ACM Symposium on Operating Systems Principles , pages=
-
[27]
14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20) , pages=
Serving \ DNNs \ like clockwork: Performance predictability from the bottom up , author=. 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20) , pages=
-
[28]
TensorFlow-Serving: Flexible, High-Performance ML Serving
Tensorflow-serving: Flexible, high-performance ml serving , author=. arXiv preprint arXiv:1712.06139 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
GitHub repository , howpublished =
, title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[30]
2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=
Pylot: A modular platform for exploring latency-accuracy tradeoffs in autonomous vehicles , author=. 2021 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2021 , organization=
2021
-
[31]
IEEE Transactions on Vehicular Technology , volume=
Adaptive computing scheduling for edge-assisted autonomous driving , author=. IEEE Transactions on Vehicular Technology , volume=. 2021 , publisher=
2021
-
[32]
IEEE Transactions on Industrial Informatics , volume=
Adaptive priority adjustment scheduling approach with response-time analysis in time-sensitive networks , author=. IEEE Transactions on Industrial Informatics , volume=. 2022 , publisher=
2022
-
[33]
14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17) , pages=
Live video analytics at scale with approximation and \ Delay-Tolerance \ , author=. 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17) , pages=
-
[34]
2019 IEEE Global Communications Conference (GLOBECOM) , pages=
Delay-aware IoT task scheduling in space-air-ground integrated network , author=. 2019 IEEE Global Communications Conference (GLOBECOM) , pages=. 2019 , organization=
2019
-
[35]
arXiv preprint arXiv:2411.15845 , year=
Space-ground fluid AI for 6G edge intelligence , author=. arXiv preprint arXiv:2411.15845 , year=
-
[36]
arXiv preprint arXiv:2501.09967 , year=
Explainable artificial intelligence (XAI): from inherent explainability to large language models , author=. arXiv preprint arXiv:2501.09967 , year=
-
[37]
Jocher, Glenn and Qiu, Jing and Chaurasia, Ayush , license =
-
[38]
Communications of the ACM , volume=
The JPEG still picture compression standard , author=. Communications of the ACM , volume=. 1991 , publisher=
1991
-
[39]
Reinforcement Learning through Asynchronous Advantage Actor-Critic on a GPU
Reinforcement learning through asynchronous advantage actor-critic on a gpu , author=. arXiv preprint arXiv:1611.06256 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
2018 IEEE international conference on robotics and automation (ICRA) , pages=
Learning with training wheels: speeding up training with a simple controller for deep reinforcement learning , author=. 2018 IEEE international conference on robotics and automation (ICRA) , pages=. 2018 , organization=
2018
-
[41]
IEEE Transactions on Games , volume=
Creating pro-level AI for a real-time fighting game using deep reinforcement learning , author=. IEEE Transactions on Games , volume=. 2021 , publisher=
2021
-
[42]
International Conference on Machine Learning , pages=
Time limits in reinforcement learning , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[43]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
Pytorch: An imperative style, high-performance deep learning library , author=. arXiv preprint arXiv:1912.01703 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[45]
5th International Conference on Fog, Fog Collection and Dew, M
Visibility parameterization for forecasting model applications , author=. 5th International Conference on Fog, Fog Collection and Dew, M
-
[46]
, author=
Review of leeway: Field experiments and implementation. , author=
-
[47]
Journal of Manufacturing Systems , volume=
A digital twin to train deep reinforcement learning agent for smart manufacturing plants: Environment, interfaces and intelligence , author=. Journal of Manufacturing Systems , volume=. 2021 , publisher=
2021
-
[48]
IEEE Journal of Solid-State Circuits , volume=
EPU: An energy-efficient explainable AI accelerator with sparsity-free computation and heat map compression/pruning , author=. IEEE Journal of Solid-State Circuits , volume=. 2024 , publisher=
2024
-
[49]
Advances in neural information processing systems , volume=
The surprising effectiveness of ppo in cooperative multi-agent games , author=. Advances in neural information processing systems , volume=
-
[50]
2018 IEEE winter conference on applications of computer vision (WACV) , pages=
Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks , author=. 2018 IEEE winter conference on applications of computer vision (WACV) , pages=. 2018 , organization=
2018
-
[51]
You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery
You only look twice: Rapid multi-scale object detection in satellite imagery , author=. arXiv preprint arXiv:1805.09512 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
IEEE Transactions on communications , volume=
An algorithm for vector quantizer design , author=. IEEE Transactions on communications , volume=. 2003 , publisher=
2003
-
[53]
IEEE Transactions on Image Processing , volume=
Layercam: Exploring hierarchical class activation maps for localization , author=. IEEE Transactions on Image Processing , volume=. 2021 , publisher=
2021
-
[54]
IEEE Geoscience and Remote Sensing Letters , volume=
Scale adaptive proposal network for object detection in remote sensing images , author=. IEEE Geoscience and Remote Sensing Letters , volume=. 2019 , publisher=
2019
-
[55]
Proceedings of the IEEE international conference on computer vision , pages=
Grad-cam: Visual explanations from deep networks via gradient-based localization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[56]
Neurocomputing , volume=
Multi-scale network (MsSG-CNN) for joint image and saliency map learning-based compression , author=. Neurocomputing , volume=. 2021 , publisher=
2021
-
[57]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
DOTA: A large-scale dataset for object detection in aerial images , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[58]
International conference on machine learning , pages=
RLlib: Abstractions for distributed reinforcement learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[59]
AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles
Shital Shah and Debadeepta Dey and Chris Lovett and Ashish Kapoor , title =. 2017 , booktitle =. arXiv:1705.05065 , url =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[60]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Yolo-world: Real-time open-vocabulary object detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[61]
IEEE Transactions on Geoscience and Remote Sensing , year=
Yoloow: A spatial scale adaptive real-time object detection neural network for open water search and rescue from uav aerial imagery , author=. IEEE Transactions on Geoscience and Remote Sensing , year=
-
[62]
2016 , publisher=
A concise introduction to decentralized POMDPs , author=. 2016 , publisher=
2016
-
[63]
Conference on Lifelong Learning Agents , pages=
Dealing with non-stationarity in decentralized cooperative multi-agent deep reinforcement learning via multi-timescale learning , author=. Conference on Lifelong Learning Agents , pages=. 2023 , organization=
2023
-
[64]
Dealing with Non-Stationarity in Multi-Agent Deep Reinforcement Learning
Dealing with non-stationarity in multi-agent deep reinforcement learning , author=. arXiv preprint arXiv:1906.04737 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[65]
arXiv preprint arXiv:2408.04295 , year=
Assigning credit with partial reward decoupling in multi-agent proximal policy optimization , author=. arXiv preprint arXiv:2408.04295 , year=
-
[66]
arXiv preprint arXiv:2409.03052 , year=
An introduction to centralized training for decentralized execution in cooperative multi-agent reinforcement learning , author=. arXiv preprint arXiv:2409.03052 , year=
-
[67]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
1948
-
[68]
IEEE Transactions on Circuits and Systems for Video Technology , volume=
Revisiting open world object detection , author=. IEEE Transactions on Circuits and Systems for Video Technology , volume=. 2023 , publisher=
2023
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Prob: Probabilistic objectness for open world object detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Detecting everything in the open world: Towards universal object detection , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
European conference on computer vision , pages=
Ssd: Single shot multibox detector , author=. European conference on computer vision , pages=. 2016 , organization=
2016
-
[72]
1990 , publisher=
Generalized diffusion processes , author=. 1990 , publisher=
1990
-
[73]
Sensors , volume=
Real-time object detection and classification by UAV equipped with SAR , author=. Sensors , volume=. 2022 , publisher=
2022
-
[74]
Journal of Marine Science and Engineering , volume=
Maritime anomaly detection for vessel traffic services: A survey , author=. Journal of Marine Science and Engineering , volume=. 2023 , publisher=
2023
-
[75]
the Journal of Navigation , volume=
Automatic Identification System (AIS): Data reliability and human error implications , author=. the Journal of Navigation , volume=. 2007 , publisher=
2007
-
[76]
Green steaming: A methodology for estimating carbon emissions avoided , author=
-
[77]
Workshop on Moving objects at Sea , year=
Data fusion for wide-area maritime surveillance , author=. Workshop on Moving objects at Sea , year=
-
[78]
2004 , publisher=
1028 On the Automatic Identification System (AIS) Volume 1, Part I, Operational Issues , author=. 2004 , publisher=
2004
-
[79]
YOLOv11: An Overview of the Key Architectural Enhancements
Yolov11: An overview of the key architectural enhancements , author=. arXiv preprint arXiv:2410.17725 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Sensors , volume=
Agricultural greenhouses detection in high-resolution satellite images based on convolutional neural networks: Comparison of faster R-CNN, YOLO v3 and SSD , author=. Sensors , volume=. 2020 , publisher=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.