Recognition: no theorem link
Code-Centric Detection of Vulnerability-Fixing Commits: A Unified Benchmark and Empirical Study
Pith reviewed 2026-05-14 18:35 UTC · model grok-4.3
The pith
Code language models acquire no transferable security understanding from vulnerability-fixing code changes alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We find no evidence that models acquire transferable security-relevant code understanding from code changes alone. When commit messages are available, they dominate model attention, and when removed, an attribution analysis shows that enriching diffs with additional intra-procedural semantic context does not shift model attention toward the code changes.
What carries the argument
A unified consolidation framework that merges fragmented VFC datasets and applies attention attribution analysis to compare model behavior on diffs alone versus diffs plus commit messages.
If this is right
- Group-stratified evaluation produces approximately 17 percent performance drops compared with random splits.
- Temporal splits on aggregated datasets become unreliable because of compositional shifts in the underlying project distributions.
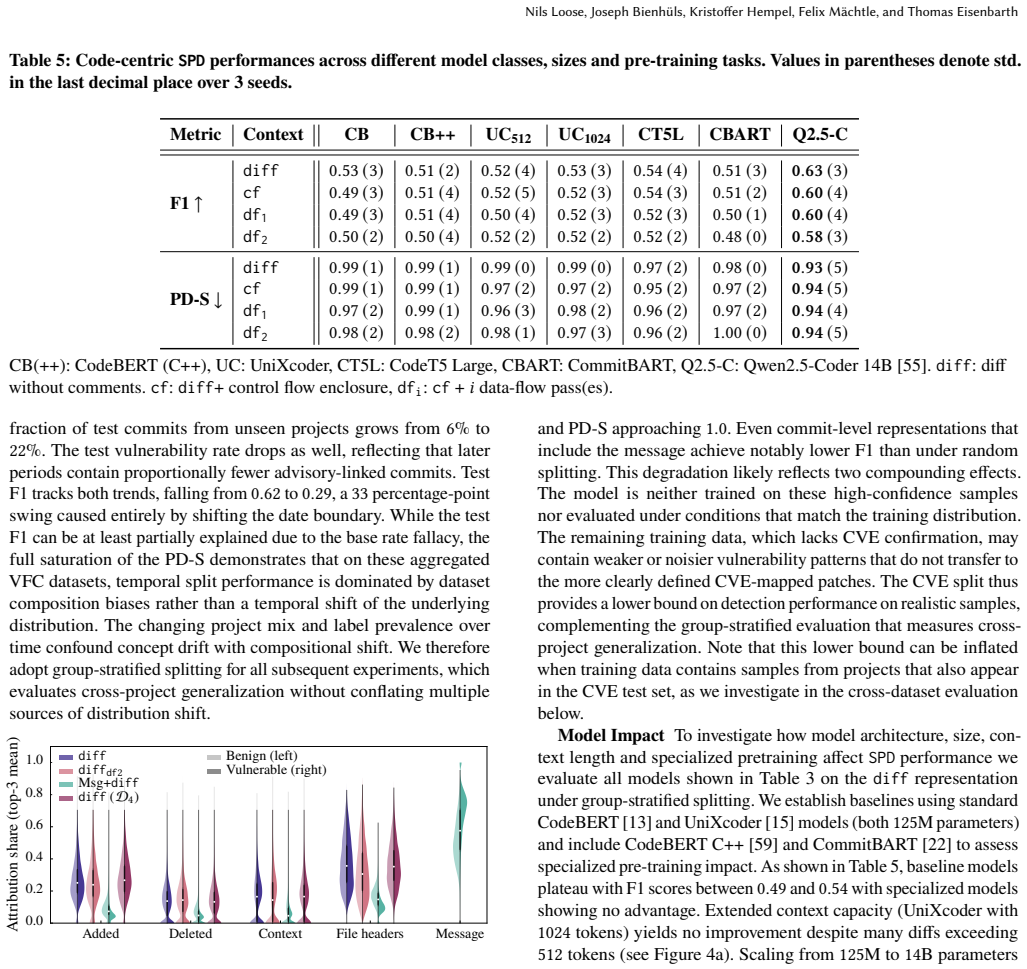
- At a false-positive rate of 0.5 percent, all fine-tuned code-only models miss more than 93 percent of vulnerabilities.
- Larger and more diverse training data or generative approaches yield preliminary gains but leave the core limitations intact.
Where Pith is reading between the lines
- Models appear to learn surface-level textual cues in messages rather than deeper code semantics, implying that purely code-centric detectors may require entirely different training signals.
- The attention results suggest that adding intra-procedural context alone is insufficient; richer inter-procedural or data-flow features might need to be tested explicitly.
- Future benchmarks could isolate code changes by deliberately withholding messages during both training and inference to measure genuine code understanding.
- The 17 percent drop in group-stratified settings indicates that project-level leakage in random splits may inflate reported performance across many security tasks.
Load-bearing premise
The merged datasets contain accurate, unbiased labels for vulnerability-fixing commits and the random, group-stratified, and temporal splits reflect realistic deployment conditions without unmeasured shifts.
What would settle it
Training a code-only model on diffs without messages and observing it reach high recall at low false-positive rate in a temporal split on previously unseen projects would contradict the reported findings.
Figures








read the original abstract
Automated detection of vulnerability-fixing commits (VFCs) is critical for timely security patch deployment, as advisory databases lag patch releases by a median of 25 days and many fixes never receive advisories. We present a comprehensive evaluation of code language model based VFC detection through a unified framework consolidating over 20 fragmented datasets spanning more than 180000 commits. Across over 180 experiments with fine-tuned models from 125 M to 14 B parameters, we find no evidence that models acquire transferable security-relevant code understanding from code changes alone. When commit messages are available, they dominate model attention, and when removed, an attribution analysis shows that enriching diffs with additional intra-procedural semantic context does not shift model attention toward the code changes. Group-stratified evaluation exposes approximately 17% performance drops compared to random splits, while temporal splits on aggregated datasets prove unreliable due to compositional shift in the underlying project distributions. At a false positive rate of 0.5% all fine-tuned code-only models miss over 93% of vulnerabilities. Larger and more diverse training data or generative approaches show preliminary improvements but do not resolve the underlying limitations. To support future research on code-centric VFC detection, we release our unified framework and evaluation suite.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper consolidates over 20 prior VFC datasets into a unified benchmark of >180k commits and conducts >180 experiments with code LMs (125M–14B parameters). It reports no evidence that models learn transferable security-relevant understanding from code changes alone: commit messages dominate attention when present; enriching diffs with intra-procedural context does not redirect attribution toward the changes; group-stratified splits drop performance ~17% and temporal splits are unreliable due to project-distribution shift. At 0.5% FPR, code-only models miss >93% of vulnerabilities. The authors release the framework and evaluation suite.
Significance. If the negative findings are robust, the work is significant for establishing the practical limits of purely code-centric VFC detection and for supplying a reusable benchmark that future work can build upon. The scale of the experimental sweep across model sizes and the use of attribution analysis are strengths that support the empirical conclusions.
major comments (1)
- [Dataset Construction and Evaluation Methodology] The central claim that models acquire no transferable security understanding from code changes rests on the assumption that the consolidated labels (>180k commits from >20 sources) are sufficiently accurate and unbiased proxies for actual vulnerability fixes. No precision/recall figures on a manually verified held-out subset are reported, leaving open the possibility that label noise correlated with commit-message keywords or project identity explains the observed code-only performance and attribution results.
minor comments (1)
- [Abstract] The abstract states that temporal splits are 'unreliable due to compositional shift' but does not quantify the magnitude of the shift or provide per-project statistics that would allow readers to assess its severity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below and will revise the manuscript to incorporate additional analysis of label quality.
read point-by-point responses
-
Referee: [Dataset Construction and Evaluation Methodology] The central claim that models acquire no transferable security understanding from code changes rests on the assumption that the consolidated labels (>180k commits from >20 sources) are sufficiently accurate and unbiased proxies for actual vulnerability fixes. No precision/recall figures on a manually verified held-out subset are reported, leaving open the possibility that label noise correlated with commit-message keywords or project identity explains the observed code-only performance and attribution results.
Authors: We acknowledge this is a valid methodological concern. The unified benchmark aggregates labels directly from more than 20 previously published datasets that have been used as proxies for VFCs in the literature; we did not perform a fresh end-to-end manual verification of all 180k+ commits. To address the referee's point, the revised manuscript will add a new subsection on label quality. We will manually inspect a stratified random sample of 1,000 commits (balanced across sources, labels, and presence/absence of commit messages), report estimated precision and recall, and analyze whether any observed noise correlates with commit-message keywords or project identity. We will also discuss how the consistency of our attribution, message-ablation, and group/temporal-split results across independent source datasets provides supporting evidence that is not fully explained by uniform label noise. We believe these additions will strengthen the presentation of our negative findings without altering the core conclusions. revision: partial
Circularity Check
No circularity: purely empirical benchmarking with held-out evaluation
full rationale
The paper is an empirical study that consolidates >20 prior datasets into >180k commits and reports model performance across fine-tuning experiments (125M–14B parameters), split variants, and attribution analyses. All central claims (no transferable code-only understanding, message dominance, 17% group-stratified drop, >93% miss rate at 0.5% FPR) are direct outputs of standard train/test procedures on held-out data; no equations, fitted parameters, or self-citation chains are invoked to derive the results. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing datasets provide accurate labels for vulnerability-fixing commits without significant noise or selection bias.
Reference graph
Works this paper leans on
-
[1]
Jafar Akhoundali, Sajad Rahim Nouri, Kristian F. D. Rietveld, and Olga Gady- atskaya. 2024. MoreFixes: A Large-Scale Dataset of CVE Fix Commits Mined through Enhanced Repository Discovery. InProceedings of the 20th International Conference on Predictive Models and Data Analytics in Software Engineering, PROMISE 2024. ACM. https://doi.org/10.1145/3663533.3664036
-
[2]
Dos and Don’ts of Machine Learning in Computer Security
Daniel Arp, Erwin Quiring, Feargus Pendlebury, Alexander Warnecke, Fabio Pierazzi,ChristianWressnegger,LorenzoCavallaro,andKonradRieck.2022. Dos and Don’ts of Machine Learning in Computer Security. In31st USENIX Security Symposium, USENIX Security 2022, Boston, MA, USA, August 10-12, 2022, Kevin R. B. Butler and Kurt Thomas (Eds.). USENIX Association, 397...
2022
-
[3]
Guru Prasad Bhandari, Amara Naseer, and Leon Moonen. 2021. CVEfixes: automated collection of vulnerabilities and their fixes from open-source software. InPROMISE ’21: 17th International Conference on Predictive Models and Data Code-Centric Detection of Vulnerability-Fixing Commits: A Unified Benchmark and Empirical Study Analytics in Software Engineering,...
-
[4]
Max Brunsfeld. [n.d.]. Tree-sitter. https://github.com/tree-sitter/tree-sitter
-
[5]
Tianyu Chen, Lin Li, Taotao Qian, Jingyi Liu, Wei Yang, Ding Li, Guangtai Liang, Qianxiang Wang, and Tao Xie. 2024. CompVPD: Iteratively Identifying Vulnerability Patches Based on Human Validation Results with a Precise Context. arXiv:2310.02530 [cs.CR] https://arxiv.org/abs/2310.02530
-
[6]
Yizheng Chen, Zhoujie Ding, Lamya Alowain, Xinyun Chen, and David A. Wagner. 2023. DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection. InProceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, RAID 2023. ACM. https://doi.org/10.1145/3607199.3607242
-
[7]
TheoChow,MarioD’Onghia,LorenzLinhardt,ZeliangKan,DanielArp,Lorenzo Cavallaro, and Fabio Pierazzi. 2026. Beyond the TESSERACT: Trustworthy Dataset Curation for Sound Evaluations of Android Malware Classifiers. In Proceedings of the 4th IEEE Conference on Secure and Trustworthy Machine Learning. https://discovery.ucl.ac.uk/id/eprint/10220473/
-
[9]
https://doi.org/10.48550/ARXIV.2403.18624 arXiv:2403.18624
Vulnerability Detection with Code Language Models: How Far Are We? CoRRabs/2403.18624 (2024). https://doi.org/10.48550/ARXIV.2403.18624 arXiv:2403.18624
-
[10]
Wagner, Baishakhi Ray, and Yizheng Chen
Yangruibo Ding, Yanjun Fu, Omniyyah Ibrahim, Chawin Sitawarin, Xinyun Chen, Basel Alomair, David A. Wagner, Baishakhi Ray, and Yizheng Chen
-
[11]
InProceedings of the 47th IEEE/ACM international conference on software engineering
Vulnerability Detection with Code Language Models: How Far are We?. In47th IEEE/ACM International Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 1729–1741. https: //doi.org/10.1109/ICSE55347.2025.00038
-
[12]
Trevor Dunlap, Elizabeth Lin, William Enck, and Bradley Reaves. 2024. VFCFinder: Pairing Security Advisories and Patches. InProceedings of the 19th ACM Asia Conference on Computer and Communications Security, ASIA CCS 2024, Singapore, July 1-5, 2024,JianyingZhou,TonyQ.S.Quek,DebinGao, and Alvaro A. Cárdenas (Eds.). ACM. https://doi.org/10.1145/3634737.3657007
-
[13]
Jonathan Evertz, Niklas Risse, Nicolai Neuer, Andreas Müller, Philipp Normann, Gaetano Sapia, Srishti Gupta, David Pape, Soumya Shaw, Devansh Srivastav, Christian Wressnegger, Erwin Quiring, Thorsten Eisenhofer, Daniel Arp, and Lea Schönherr. 2025. Chasing Shadows: Pitfalls in LLM Security Research. CoRRabs/2512.09549 (2025). https://doi.org/10.48550/ARXI...
-
[14]
Jean-Rémy Falleri and Matias Martinez. 2024. Fine-grained, accurate and scalable source differencing. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20,
2024
-
[15]
https://doi.org/10.1145/3597503.3639148
ACM, 231:1–231:12. https://doi.org/10.1145/3597503.3639148
-
[16]
CodeBERT: A Pre-Trained Model for Programming and Natural Languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, LinjunShou,BingQin,TingLiu,DaxinJiang,andMingZhou.2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020), Trevor Cohn, Yul...
-
[17]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
GLM.2025.GLM-4.5:Agentic,Reasoning,andCoding(ARC)FoundationModels. CoRRabs/2508.06471 (2025). https://doi.org/10.48550/ARXIV.2508.06471 arXiv:2508.06471
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.06471 2025
-
[18]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InPro- ceedings of the 60th Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, SmarandaMuresan,PreslavNakov,andAlineVillavicencio(...
-
[19]
Jingxuan He and Martin T. Vechev. 2023. Large Language Models for Code: Security Hardening and Adversarial Testing. InProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, CCS 2023, Copenhagen, Denmark, November 26-30, 2023. ACM. https://doi.org/10.1145/ 3576915.3623175
-
[20]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[21]
Nasif Imtiaz, Aniqa Khanom, and Laurie A. Williams. 2023. Open or Sneaky? Fast or Slow? Light or Heavy?: Investigating Security Releases of Open Source Packages.IEEE Trans. Software Eng.49, 4 (2023), 1540–1560. https://doi.org/ 10.1109/TSE.2022.3181010
-
[22]
ZeliangKan,ShaeMcFadden,DanielArp,FeargusPendlebury,RobertoJordaney, Johannes Kinder, Fabio Pierazzi, and Lorenzo Cavallaro. 2024. TESSERACT: Eliminating Experimental Bias in Malware Classification across Space and Time (Extended Version).CoRRabs/2402.01359 (2024). https://doi.org/10.48550/ ARXIV.2402.01359 arXiv:2402.01359
-
[23]
Jian Yi David Lee and Hai Leong Chieu. 2021. Co-training for Commit Classi- fication. InProceedings of the Seventh Workshop on Noisy User-generated Text, W-NUT 2021, Online, November 11, 2021, Wei Xu, Alan Ritter, Tim Baldwin, and Afshin Rahimi (Eds.). Association for Computational Linguistics, 389–395. https://doi.org/10.18653/V1/2021.WNUT-1.43
-
[24]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han
-
[25]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration.CoRRabs/2306.00978 (2023). https://doi.org/10.48550/ARXIV. 2306.00978 arXiv:2306.00978
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[26]
Shangqing Liu, Yanzhou Li, and Yang Liu. 2022. CommitBART: A Large Pre-trained Model for GitHub Commits.CoRRabs/2208.08100 (2022). https: //doi.org/10.48550/ARXIV.2208.08100 arXiv:2208.08100
-
[27]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net. https://openreview.net/ forum?id=Bkg6RiCqY7
2019
-
[28]
ICVul:AWell- labeled C/C++ Vulnerability Dataset with Comprehensive Metadata and VCCs
ChaomengLu,TianyuLi,ToonDehaene,andBertLagaisse.2025. ICVul:AWell- labeled C/C++ Vulnerability Dataset with Comprehensive Metadata and VCCs. In22nd IEEE/ACM International Conference on Mining Software Repositories, MSR@ICSE 2025, Ottawa, ON, Canada, April 28-29, 2025. IEEE, 154–158. https://doi.org/10.1109/MSR66628.2025.00034
-
[29]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambro- sio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Unde...
2021
-
[30]
Changhua Luo, Wei Meng, and Shuai Wang. 2024. Strengthening Supply Chain Security with Fine-grained Safe Patch Identification. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 89:1–89:12. https://doi.org/10.1145/3597503. 3639104
-
[31]
Santosa, Asankhaya Sharma, and Ming Yi Ang
Giang Nguyen-Truong, Hong Jin Kang, David Lo, Abhishek Sharma, Andrew E. Santosa, Asankhaya Sharma, and Ming Yi Ang. 2022. HERMES: Using Commit- Issue Linking to Detect Vulnerability-Fixing Commits. InIEEE International Conference on Software Analysis, Evolution and Reengineering, SANER 2022, Honolulu, HI, USA, March 15-18, 2022. IEEE, 51–62. https://doi....
-
[32]
Chao Ni, Liyu Shen, Xiaohu Yang, Yan Zhu, and Shaohua Wang. 2024. MegaVul: A C/C++ Vulnerability Dataset with Comprehensive Code Representations. In 21st IEEE/ACM International Conference on Mining Software Repositories, MSR 2024, Lisbon, Portugal, April 15-16, 2024, Diomidis Spinellis, Alberto Bacchelli, and Eleni Constantinou (Eds.). ACM, 738–742. https...
-
[33]
Georgios Nikitopoulos, Konstantina Dritsa, Panos Louridas, and Dimitris Mitropoulos. 2021. CrossVul: a cross-language vulnerability dataset with com- mit data. InESEC/FSE ’21: 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM. https://doi.org/10.1145/3468264.3473122
-
[34]
NIST. [n.d.]. National Vulnerability Database. https://nvd.nist.gov/ accessed 2025-09
2025
-
[35]
Serena Elisa Ponta, Henrik Plate, Antonino Sabetta, Michele Bezzi, and Cédric Dangremont. 2019. A manually-curated dataset of fixes to vulnerabilities of open-source software. InProceedings of the 16th International Conference on Mining Software Repositories, MSR 2019. IEEE / ACM. https://doi.org/10.1109/ MSR.2019.00064
-
[36]
Sofia Reis and Rui Abreu. 2017. SECBENCH: A Database of Real Security Vulnerabilities. InProceedings of the International Workshop on Secure Software Engineering in DevOps and Agile Development co-located with the 22nd European Symposium on Research in Computer Security (ESORICS 2017) (CEUR Workshop Proceedings, Vol. 1977).CEUR-WS.org. https://ceur-ws.org...
2017
- [37]
-
[38]
In33rd USENIX Security Symposium, USENIX Security 2024.USENIXAssociation
NiklasRisseandMarcelBöhme.2024.UncoveringtheLimitsofMachineLearning for Automatic Vulnerability Detection. In33rd USENIX Security Symposium, USENIX Security 2024.USENIXAssociation. https://www.usenix.org/conference/ usenixsecurity24/presentation/risse
2024
-
[39]
Niklas Risse, Jing Liu, and Marcel Böhme. 2025. Top Score on the Wrong Exam: On Benchmarking in Machine Learning for Vulnerability Detection.Proc. ACM Softw. Eng.2, ISSTA (2025), 388–410. https://doi.org/10.1145/3728887
-
[40]
Antonino Sabetta and Michele Bezzi. 2018. A Practical Approach to the Automatic Classification of Security-Relevant Commits. In2018 IEEE Inter- national Conference on Software Maintenance and Evolution, ICSME 2018, Nils Loose, Joseph Bienhüls, Kristoffer Hempel, Felix Mächtle, and Thomas Eisenbarth Madrid, Spain, September 23-29, 2018. IEEE Computer Socie...
-
[41]
ZayneReaSprague,FangcongYin,JuanDiegoRodriguez,DongweiJiang,Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett
-
[42]
InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
To CoT or not to CoT? Chain-of-thought helps mainly on math and symbolic reasoning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/forum?id=w6nlcS8Kkn
2025
-
[43]
Benjamin Steenhoek, Md Mahbubur Rahman, Richard Jiles, and Wei Le. 2023. An Empirical Study of Deep Learning Models for Vulnerability Detection. In 45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2237–2248. https://doi.org/10. 1109/ICSE48619.2023.00188
-
[44]
Jiamou Sun, Zhenchang Xing, Qinghua Lu, Xiwei Xu, Liming Zhu, Thong Hoang, and Dehai Zhao. 2023. Silent Vulnerable Dependency Alert Prediction with Vulnerability Key Aspect Explanation. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 970–982. https://doi.org/10.1109/ICSE48619.2023.00089
-
[45]
Shiyu Sun, Shu Wang, Xinda Wang, Yunlong Xing, Elisa Zhang, and Kun Sun. 2023. Exploring Security Commits in Python. InIEEE International Conference on Software Maintenance and Evolution, ICSME 2023. IEEE. https: //doi.org/10.1109/ICSME58846.2023.00027
-
[46]
AxiomaticAttributionfor Deep Networks
MukundSundararajan,AnkurTaly,andQiqiYan.2017. AxiomaticAttributionfor Deep Networks. InProceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 (Proceedings of Machine Learning Research), Doina Precup and Yee Whye Teh (Eds.). PMLR, 3319–3328. http://proceedings.mlr.press/v70/sundararajan17a.html
2017
-
[47]
Xunzhu Tang, Zhenghan Chen, Saad Ezzini, Haoye Tian, Yewei Song, Jacques Klein, and Tegawendé F. Bissyandé. 2023. Multilevel Semantic Embedding of Software Patches: A Fine-to-Coarse Grained Approach Towards Security Patch Detection.CoRRabs/2308.15233 (2023). https://doi.org/10.48550/ARXIV.2308. 15233 arXiv:2308.15233
-
[48]
Just-in-TimeDetectionofSilentSecurityPatches
Xunzhu Tang, Kisub Kim, Saad Ezzini, Yewei Song, Haoye Tian, Jacques Klein, andTegawendeBissyande.2025. Just-in-TimeDetectionofSilentSecurityPatches. ACM Trans. Softw. Eng. Methodol.(July 2025). https://doi.org/10.1145/3749370 Just Accepted
-
[49]
https://doi.org/10.5281/zenodo.19250701 Zenodo artifact archive
VFCDetective Artifact 2026. https://doi.org/10.5281/zenodo.19250701 Zenodo artifact archive
-
[50]
Shu Wang, Xinda Wang, Kun Sun, Sushil Jajodia, Haining Wang, and Qi Li. 2023. GraphSPD:Graph-BasedSecurityPatchDetectionwithEnrichedCodeSemantics. In2023 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, Los Alamitos, CA, USA, 2409–2426. https://doi.org/10.1109/SP46215.2023. 00035
-
[51]
Shichao Wang, Yun Zhang, Liagfeng Bao, Xin Xia, and Minghui Wu. 2022. VCMatch:ARanking-basedApproachforAutomaticSecurityPatchesLocalization for OSS Vulnerabilities. InIEEE International Conference on Software Analysis, Evolution and Reengineering, SANER 2022, Honolulu, HI, USA, March 15-18,
2022
-
[52]
Santosa, Asankhaya Sharma, and Ming Yi Ang
IEEE, 589–600. https://doi.org/10.1109/SANER53432.2022.00076
-
[53]
Xinda Wang, Shu Wang, Pengbin Feng, Kun Sun, and Sushil Jajodia. 2021. PatchDB: A Large-Scale Security Patch Dataset. In51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks, DSN 2021. IEEE. https://doi.org/10.1109/DSN48987.2021.00030
-
[54]
Xinda Wang, Shu Wang, Pengbin Feng, Kun Sun, Sushil Jajodia, Sanae Ben- chaaboun,andFrankGeck.2021. PatchRNN:ADeepLearning-BasedSystemfor SecurityPatchIdentification.In2021 IEEE Military Communications Conference, MILCOM 2021, San Diego, CA, USA, November 29 - Dec. 2, 2021.IEEE,595–600. https://doi.org/10.1109/MILCOM52596.2021.9652940
-
[55]
Joty, and Steven C
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Under- standing and Generation. InEMNLP. Association for Computational Linguistics, 8696–8708
2021
-
[56]
LauraWartschinski,YannicNoller,ThomasVogel,TimoKehrer,andLarsGrunske
-
[57]
VUDENC: Vulnerability Detection with Deep Learning on a Natural Codebase for Python.Inf. Softw. Technol.144 (2022). https://doi.org/10.1016/J. INFSOF.2021.106809
work page doi:10.1016/j 2022
- [58]
-
[59]
CongyingXu,BihuanChen,ChenhaoLu,KaifengHuang,XinPeng,andYangLiu
-
[60]
Trackingpatchesforopensourcesoftwarevulnerabilities.InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14-18, 2022, Abhik Roychoudhury, Cristian Cadar, and Miryung Kim (Eds.). ACM, 860–871. https://doi.org/10.1145/3540250.3549125
-
[63]
Fabian Yamaguchi, Nico Golde, Daniel Arp, and Konrad Rieck. 2014. Modeling and Discovering Vulnerabilities with Code Property Graphs. In2014 IEEE Symposium on Security and Privacy, SP 2014, Berkeley, CA, USA, May 18-21,
2014
-
[64]
https://doi.org/10.1109/SP.2014.44
IEEE Computer Society, 590–604. https://doi.org/10.1109/SP.2014.44
-
[65]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, JianhongTu,JianweiZhang,JianxinYang,JiaxiYang,JingrenZhou,JunyangLin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[66]
Xu Yang, Wenhan Zhu, Michael Pacheco, Jiayuan Zhou, Shaowei Wang, Xing Hu, and Kui Liu. 2025. Code Change Intention, Development Artifact, and History Vulnerability: Putting Them Together for Vulnerability Fix Detection by LLM. Proc. ACM Softw. Eng.2,FSE(2025),489–510. https://doi.org/10.1145/3715738
-
[67]
Jiayuan Zhou, Michael Pacheco, Jinfu Chen, Xing Hu, Xin Xia, David Lo, and Ahmed E. Hassan. 2023. CoLeFunDa: Explainable Silent Vulnerability Fix Identification. In45th IEEE/ACM International Conference on Software Engineering, ICSE 2023, Melbourne, Australia, May 14-20, 2023. IEEE, 2565–
2023
-
[68]
https://doi.org/10.1109/ICSE48619.2023.00214
-
[69]
Jiayuan Zhou, Michael Pacheco, Zhiyuan Wan, Xin Xia, David Lo, Yuan Wang, and Ahmed E. Hassan. 2021. Finding A Needle in a Haystack: Automated Mining of Silent Vulnerability Fixes. In36th IEEE/ACM International Conference on Automated Software Engineering, ASE 2021, Melbourne, Australia, November 15-19, 2021. IEEE, 705–716. https://doi.org/10.1109/ASE5152...
-
[70]
Shuyan Zhou, Uri Alon, Sumit Agarwal, and Graham Neubig. 2023. Code- BERTScore: Evaluating Code Generation with Pretrained Models of Code. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Lin...
-
[71]
Yaqin Zhou, Shangqing Liu, Jing Kai Siow, Xiaoning Du, and Yang Liu. 2019. Devign: Effective Vulnerability Identification by Learning Comprehensive Pro- gram Semantics via Graph Neural Networks. InAdvances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019. https://proceedings.neurips...
2019
-
[72]
Yaqin Zhou, Jing Kai Siow, Chenyu Wang, Shangqing Liu, and Yang Liu. 2022. SPI: Automated Identification of Security Patches via Commits.ACM Trans. Softw. Eng. Methodol.31,1(2022),13:1–13:27. https://doi.org/10.1145/3468854
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.