Recognition: unknown
PanoWorld: Towards Spatial Supersensing in 360^circ Panorama World
Pith reviewed 2026-05-14 20:38 UTC · model grok-4.3
The pith
PanoWorld injects spherical geometry into MLLMs so they reason continuously over full 360-degree panoramas instead of sliced views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PanoWorld achieves pano-native spatial understanding in multimodal large language models by combining a metadata pipeline that supplies geometry-aware, language-grounded, depth-aware supervision with Spherical Spatial Cross-Attention that injects spherical structure into the visual encoding of equirectangular panoramas; the resulting model outperforms baselines on PanoSpace-Bench, H* Bench, and R2R-CE Val-Unseen without requiring explicit 3D reconstruction.
What carries the argument
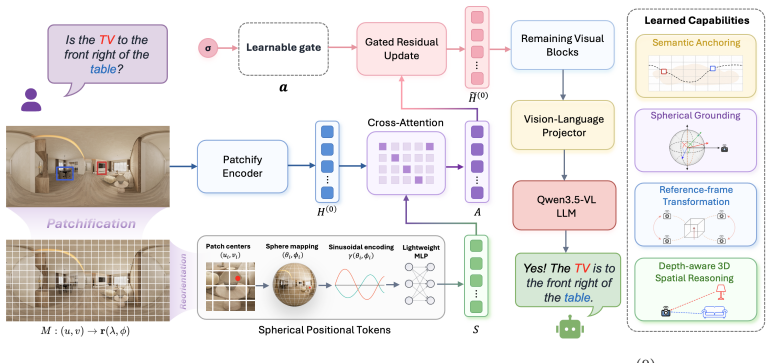
Spherical Spatial Cross-Attention, which embeds spherical geometry priors into the visual stream of an MLLM processing equirectangular projection images.
If this is right
- Robotic navigation systems can use a single panoramic input for continuous spatial planning instead of stitching multiple perspective frames.
- 3D scene understanding benchmarks gain a new diagnostic axis that isolates spherical localization errors from perspective cropping artifacts.
- Instruction-tuning datasets for vision-language models should prioritize geometry-aware ERP sources over perspective crops to support observer-centered reasoning.
- Reference-frame transformations become native operations inside the model rather than post-hoc geometric post-processing steps.
Where Pith is reading between the lines
- The same cross-attention pattern could be tested on non-ERP spherical representations such as icosahedral or cube-map projections to check whether the gain is specific to equirectangular layout.
- If the approach scales, panoramic video streams could replace multiple camera feeds in real-time embodied agents without increasing token count proportionally.
- The four defined abilities offer a natural taxonomy for evaluating future panoramic models even when they use different architectures.
Load-bearing premise
Cross-attention on equirectangular images is enough to give the model continuous observer-centered spatial reasoning without explicit 3D reconstruction or extra geometric losses.
What would settle it
Training an otherwise identical model without the Spherical Spatial Cross-Attention module and measuring whether it still matches or exceeds PanoWorld's scores on PanoSpace-Bench spatial-localization and depth-reasoning tasks.
Figures



read the original abstract
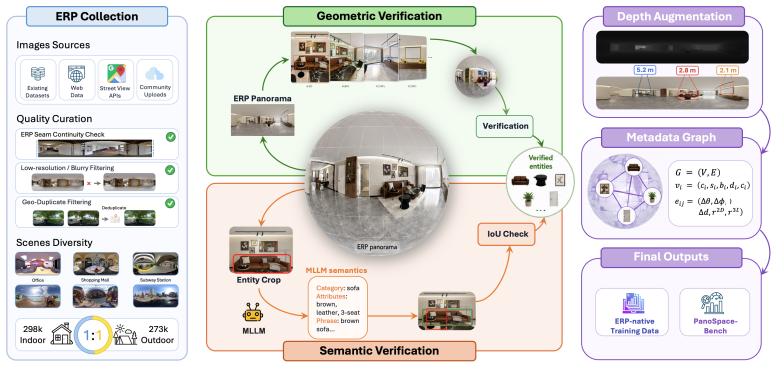
Multimodal large laboratory models (MLLMs) still struggle with spatial understanding under the dominant perspective-image paradigm, which inherits the narrow field of view of human-like perception. For navigation, robotic search, and 3D scene understanding, 360-degree panoramic sensing offers a form of supersensing by capturing the entire surrounding environment at once. However, existing MLLM pipelines typically decompose panoramas into multiple perspective views, leaving the spherical structure of equirectangular projection (ERP) largely implicit. In this paper, we study pano-native understanding, which requires an MLLM to reason over an ERP panorama as a continuous, observer-centered space. To this end, we first define the key abilities for pano-native understanding, including semantic anchoring, spherical localization, reference-frame transformation, and depth-aware 3D spatial reasoning. We then build a large-scale metadata construction pipeline that converts mixed-source ERP panoramas into geometry-aware, language-grounded, and depth-aware supervision, and instantiate these signals as capability-aligned instruction tuning data. On the model side, we introduce PanoWorld with Spherical Spatial Cross-Attention, which injects spherical geometry into the visual stream. We further construct PanoSpace-Bench, a diagnostic benchmark for evaluating ERP-native spatial reasoning. Experiments show that PanoWorld substantially outperforms both proprietary and open-source baselines on PanoSpace-Bench, H* Bench, and R2R-CE Val-Unseen benchmarks. These results demonstrate that robust panoramic reasoning requires dedicated pano-native supervision and geometry-aware model adaptation. All source code and proposed data will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PanoWorld, an MLLM for pano-native spatial understanding in 360° ERP panoramas. It defines capabilities including semantic anchoring, spherical localization, reference-frame transformation, and depth-aware 3D reasoning; constructs a metadata pipeline to generate geometry-aware, language-grounded instruction data from mixed-source panoramas; proposes Spherical Spatial Cross-Attention to inject spherical geometry into the visual stream; and releases PanoSpace-Bench for diagnostic evaluation. Experiments claim that PanoWorld substantially outperforms proprietary and open-source baselines on PanoSpace-Bench, H* Bench, and R2R-CE Val-Unseen.
Significance. If the performance claims hold with full quantitative support, the work would advance MLLM spatial reasoning beyond narrow-FOV perspective images toward continuous observer-centered panoramic understanding, with direct relevance to robotics, navigation, and 3D scene tasks. The planned public release of code and data would strengthen reproducibility.
major comments (3)
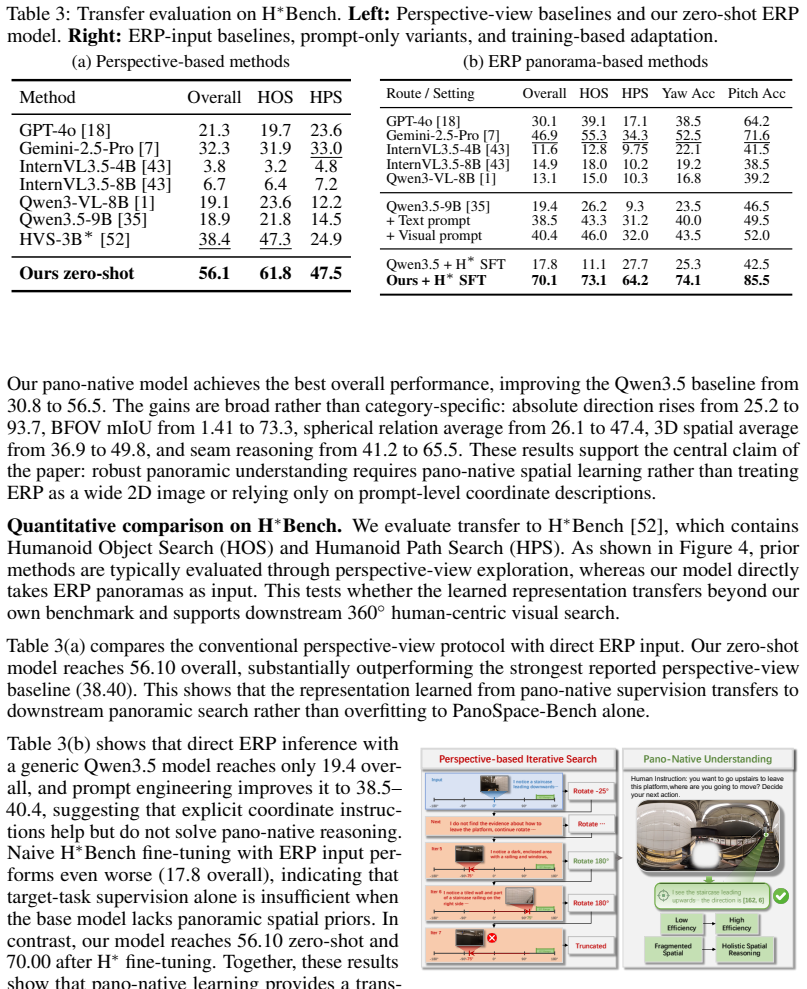
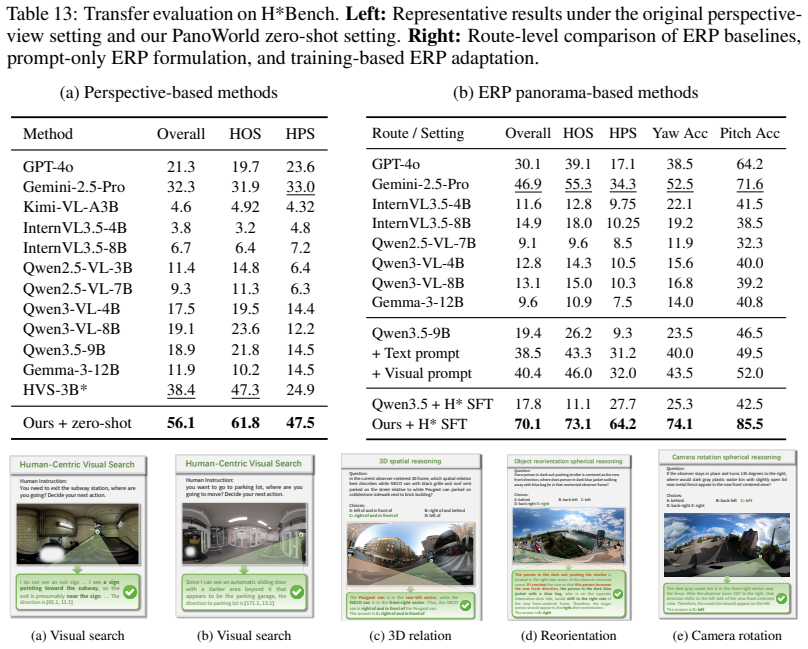
- [Abstract / Experiments] Abstract and Experiments section: the central claim that PanoWorld 'substantially outperforms' baselines on three benchmarks is stated without any numerical metrics, error bars, ablation tables, training-data scale, or statistical tests. This absence directly undermines verification of the headline result and the conclusion that pano-native supervision plus geometry-aware adaptation are required.
- [Model Architecture] Model architecture description: Spherical Spatial Cross-Attention is presented as the mechanism that injects spherical geometry via cross-attention on standard ERP features, yet the text provides no pole-aware positional encodings, spherical harmonics, explicit distortion correction, or auxiliary geometric losses. Without these, it is unclear whether the module compensates for latitude-dependent stretching or merely benefits from the new instruction data.
- [Benchmark Construction / Data Pipeline] Benchmark and data pipeline sections: PanoSpace-Bench and the instruction-tuning data are constructed internally from the same metadata pipeline. This creates a risk of circular evaluation; additional controls (e.g., held-out external panoramas, cross-dataset transfer results) are needed to establish that gains reflect genuine geometry-aware reasoning rather than benchmark-specific overfitting.
minor comments (2)
- [Abstract] Abstract: 'multimodal large laboratory models' is presumably a typo for 'multimodal large language models'.
- [Abstract] Notation: the acronym 'ERP' is used without an initial expansion in the abstract; add it on first use for clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify the presentation of our results and strengthen the manuscript. We address each major comment below and have revised the paper to incorporate additional quantitative details, architectural clarifications, and evaluation controls.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that PanoWorld 'substantially outperforms' baselines on three benchmarks is stated without any numerical metrics, error bars, ablation tables, training-data scale, or statistical tests. This absence directly undermines verification of the headline result and the conclusion that pano-native supervision plus geometry-aware adaptation are required.
Authors: We agree that explicit numerical support is essential for verifying the headline claims. In the revised manuscript we have expanded both the abstract and the Experiments section to report concrete performance numbers (accuracy and success rates) on PanoSpace-Bench, H* Bench, and R2R-CE Val-Unseen, together with baseline comparisons, ablation tables, training-data scale, and standard-error bars. These additions directly substantiate the statement that pano-native supervision and geometry-aware adaptation are required. revision: yes
-
Referee: [Model Architecture] Model architecture description: Spherical Spatial Cross-Attention is presented as the mechanism that injects spherical geometry via cross-attention on standard ERP features, yet the text provides no pole-aware positional encodings, spherical harmonics, explicit distortion correction, or auxiliary geometric losses. Without these, it is unclear whether the module compensates for latitude-dependent stretching or merely benefits from the new instruction data.
Authors: The Spherical Spatial Cross-Attention module operates on standard ERP features and learns to mitigate latitude-dependent distortion through the geometry-aware instruction data and the cross-attention mechanism itself. While we did not employ explicit spherical harmonics or auxiliary geometric losses, the attention weights are conditioned on spherical coordinate embeddings that implicitly encode pole and equator effects. To remove ambiguity we have added a dedicated paragraph in the revised Model Architecture section that details the coordinate embedding construction and confirms that performance gains arise from the combination of architecture and data rather than data alone. revision: partial
-
Referee: [Benchmark Construction / Data Pipeline] Benchmark and data pipeline sections: PanoSpace-Bench and the instruction-tuning data are constructed internally from the same metadata pipeline. This creates a risk of circular evaluation; additional controls (e.g., held-out external panoramas, cross-dataset transfer results) are needed to establish that gains reflect genuine geometry-aware reasoning rather than benchmark-specific overfitting.
Authors: We share the concern about potential circularity. In the revised manuscript we have added two sets of controls: (1) evaluation on a held-out collection of external panoramas never seen during instruction tuning, and (2) cross-dataset transfer results on an independent panoramic source. These experiments show that the performance advantage persists, indicating that the gains reflect genuine geometry-aware reasoning rather than overfitting to the internal pipeline. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines pano-native abilities, constructs a data pipeline and PanoSpace-Bench to match those definitions, then reports empirical gains on both the custom benchmark and external ones (H* Bench, R2R-CE). No equations are shown that reduce any claimed prediction or result to a fitted input or self-definition by construction. The Spherical Spatial Cross-Attention is presented as an architectural addition rather than a tautological renaming or self-citation load-bearing step. Self-constructed artifacts are common in new-task papers and do not trigger the enumerated circularity patterns here.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Equirectangular projection preserves enough spherical geometry for cross-attention to recover continuous observer-centered spatial relations without explicit 3D lifting.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, et al. Qwen3-vl technical report, 2025. URL https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, et al. Qwen2.5-vl technical report, 2025. URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Panda: Towards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation
Zidong Cao, Jinjing Zhu, Weiming Zhang, Hao Ai, Haotian Bai, Hengshuang Zhao, and Lin Wang. Panda: Towards panoramic depth anything with unlabeled panoramas and mobius spatial augmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 982–992, 2025
2025
-
[4]
Boyang Chen, Ruijie Xu, Xinyu Zhang, et al. SpatialVLM: Endowing vision-language models with spatial reasoning capabilities.arXiv preprint arXiv:2401.12168, 2024
-
[5]
360+x: A panoptic multi-modal scene understanding dataset
Hao Chen, Yuqi Hou, Chenyuan Qu, Irene Testini, Xiaohan Hong, and Jianbo Jiao. 360+x: A panoptic multi-modal scene understanding dataset. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[6]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. In Advances in Neural Information Processing Systems, 2024
2024
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities, 2025. URLhttps://arxiv.org/abs/2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Spherenet: Learning spher- ical representations for detection and classification in omnidirectional images
Benjamin Coors, Alexandru Paul Condurache, and Andreas Geiger. Spherenet: Learning spher- ical representations for detection and classification in omnidirectional images. InProceedings of the European conference on computer vision (ECCV), pages 518–533, 2018
2018
-
[9]
Lau-net: Latitude adaptive upscaling network for omnidirectional image super-resolution
Xin Deng, Hao Wang, Mai Xu, Yichen Guo, Yuhang Song, and Li Yang. Lau-net: Latitude adaptive upscaling network for omnidirectional image super-resolution. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9189–9198, 2021
2021
-
[10]
Are multimodal large language models ready for omnidirectional spatial reasoning?, 2025
Zihao Dongfang, Xu Zheng, Ziqiao Weng, Yuanhuiyi Lyu, Danda Pani Paudel, Luc Van Gool, Kailun Yang, and Xuming Hu. Are multimodal large language models ready for omnidirectional spatial reasoning?, 2025. URLhttps://arxiv.org/abs/2505.11907
-
[11]
More than the Sum: Panorama-Language Models for Adverse Omni-Scenes
Weijia Fan, Ruiping Liu, Jiale Wei, Yufan Chen, Junwei Zheng, Zichao Zeng, Jiaming Zhang, Qiufu Li, Linlin Shen, and Rainer Stiefelhagen. More than the sum: Panorama-language models for adverse omni-scenes.arXiv preprint arXiv:2603.09573, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Haoran Feng, Dizhe Zhang, Xiangtai Li, Bo Du, and Lu Qi. Dit360: High-fidelity panoramic image generation via hybrid training.arXiv preprint arXiv:2510.11712, 2025
-
[13]
Wedetect: Fast open-vocabulary object detection as retrieval.arXiv preprint arXiv:2512.12309, 2025
Shenghao Fu, Yukun Su, Fengyun Rao, Jing Lyu, Xiaohua Xie, and Wei-Shi Zheng. Wedetect: Fast open-vocabulary object detection as retrieval.arXiv preprint arXiv:2512.12309, 2025
-
[14]
Airsim360: A panoramic simulation platform within drone view.arXiv preprint arXiv:2512.02009, 2025
Xian Ge, Yuling Pan, Yuhang Zhang, Xiang Li, Weijun Zhang, Dizhe Zhang, Zhaoliang Wan, Xin Lin, Xiangkai Zhang, Juntao Liang, et al. Airsim360: A panoramic simulation platform within drone view.arXiv preprint arXiv:2512.02009, 2025
-
[15]
Panovggt: Feed-forward 3d reconstruction from panoramic imagery, 2026
Yijing Guo, Mengjun Chao, Luo Wang, Tianyang Zhao, Haizhao Dai, Yingliang Zhang, Jingyi Yu, and Yujiao Shi. Panovggt: Feed-forward 3d reconstruction from panoramic imagery, 2026. URLhttps://arxiv.org/abs/2603.17571
-
[16]
3d-llm: Injecting the 3d world into large language models
Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, and Chuang Gan. 3d-llm: Injecting the 3d world into large language models. InAdvances in Neural Information Processing Systems, 2023
2023
-
[17]
An embodied generalist agent in 3d world
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. InInternational Conference on Machine Learning, 2024. 12
2024
-
[18]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, Aaron Ostrow, Alethea Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Sim-2-sim transfer for vision-and-language navigation in continu- ous environments
Jacob Krantz and Stefan Lee. Sim-2-sim transfer for vision-and-language navigation in continu- ous environments. InEuropean Conference on Computer Vision (ECCV), 2022
2022
-
[20]
Beyond the nav- graph: Vision-and-language navigation in continuous environments
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee. Beyond the nav- graph: Vision-and-language navigation in continuous environments. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
2020
-
[21]
Waypoint models for instruction-guided navigation in continuous environments
Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Stefan Lee, and Oleksandr Maksymets. Waypoint models for instruction-guided navigation in continuous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[22]
Da 2: Depth anything in any direction.arXiv preprint arXiv:2509.26618, 2025
Haodong Li, Wangguangdong Zheng, Jing He, Yuhao Liu, Xin Lin, Xin Yang, Ying-Cong Chen, and Chunchao Guo. Da 2: Depth anything in any direction.arXiv preprint arXiv:2509.26618, 2025
-
[23]
Realsee3d: A large-scale multi-view rgb-d dataset of indoor scenes (version 1.0), 2025
Linyuan Li, Yan Wu, Xi Li, Lingli Wang, Tong Rao, Jie Zhou, Cihui Pan, and Xinchen Hui. Realsee3d: A large-scale multi-view rgb-d dataset of indoor scenes (version 1.0), 2025. URL https://doi.org/10.5281/zenodo.17826243
-
[24]
Xin Lin, Xian Ge, Dizhe Zhang, Zhaoliang Wan, Xianshun Wang, Xiangtai Li, Wenjie Jiang, Bo Du, Dacheng Tao, Ming-Hsuan Yang, et al. One flight over the gap: A survey from perspective to panoramic vision.arXiv preprint arXiv:2509.04444, 2025
-
[25]
Xin Lin, Meixi Song, Dizhe Zhang, Wenxuan Lu, Haodong Li, Bo Du, Ming-Hsuan Yang, Truong Nguyen, and Lu Qi. Depth any panoramas: A foundation model for panoramic depth estimation.arXiv preprint arXiv:2512.16913, 2025
-
[26]
Zekai Lin and Xu Zheng. PanoEnv: Exploring 3d spatial intelligence in panoramic environments with reinforcement learning.arXiv preprint arXiv:2602.21992, 2026
-
[27]
Panoswin: A pano-style swin transformer for panorama understanding
Zhixin Ling, Zhen Xing, Xiangdong Zhou, Manliang Cao, and Guichun Zhou. Panoswin: A pano-style swin transformer for panorama understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[28]
Alexander H. Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, et al. Ministral 3, 2026. URLhttps://arxiv.org/abs/2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Weichen Liu, Qiyao Xue, Haoming Wang, Xiangyu Yin, Boyuan Yang, and Wei Gao. Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722, 2025
-
[30]
Yuheng Liu, Xin Lin, Xinke Li, Baihan Yang, Chen Wang, Kalyan Sunkavalli, Yannick Hold- Geoffroy, Hao Tan, Kai Zhang, Xiaohui Xie, et al. Omniroam: World wandering via long- horizon panoramic video generation.arXiv preprint arXiv:2603.30045, 2026
-
[31]
Sqa3d: Situated question answering in 3d scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes. InInternational Conference on Learning Representations, 2023
2023
-
[32]
Openeqa: Embodied question answering in the era of foundation models
Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, Karmesh Yadav, Qiyang Li, Ben Newman, Mohit Sharma, Vincent Berges, Shiqi Zhang, Pulkit Agrawal, Yonatan Bisk, Dhruv Batra, Mrinal Kalakrishnan, Franziska Meier, Chris Paxton, Alexander Sax, and Aravind ...
2024
-
[33]
Panoformer: Panorama transformer for indoor 360◦ depth estimation
Zhijie Shen, Chunyu Lin, Kang Liao, Lang Nie, Zishuo Zheng, and Yao Zhao. Panoformer: Panorama transformer for indoor 360◦ depth estimation. InEuropean Conference on Computer Vision (ECCV), 2022. 13
2022
- [34]
-
[35]
Qwen3.5: Accelerating productivity with native multimodal agents, February
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February
-
[36]
URLhttps://qwen.ai/blog?id=qwen3.5
-
[37]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Ziteng Wang, Rob Fergus, Yann LeCun, and Saining Xie. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. InAdvances in Neural Information Processing Systems, 2024
2024
-
[38]
From illusion to intention: Visual rationale learning for vision-language reasoning, 2025
Changpeng Wang, Haozhe Wang, Xi Chen, Junhan Liu, Taofeng Xue, Chong Peng, Donglian Qi, Fangzhen Lin, and Yunfeng Yan. From illusion to intention: Visual rationale learning for vision-language reasoning, 2025. URLhttps://arxiv.org/abs/2511.23031
-
[39]
Dreamwalker: Mental planning for continuous vision-language navigation
Hanqing Wang, Wenguan Wang, Tianmin Shu, Wei Liang, and Jianbing Shen. Dreamwalker: Mental planning for continuous vision-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[40]
Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. arXiv preprint arXiv:2504.08837, 2025
-
[41]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, , Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning.arXiv preprint arXiv:2505.15966, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
Haozhe Wang, Cong Wei, Weiming Ren, Jiaming Liu, Fangzhen Lin, and Wenhu Chen. Ra- tionalrewards: Reasoning rewards scale visual generation both training and test time.arXiv preprint arXiv:2604.11626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Ning-Hsu Wang and Yu-Lun Liu. Depth anywhere: Enhancing 360 monocular depth estimation via perspective distillation and unlabeled data augmentation.Advances in Neural Information Processing Systems, 37:127739–127764, 2024
2024
-
[44]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025. URL https: //arxiv.org/abs/2508.18265
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Gridmm: Grid memory map for vision-and-language navigation
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. Gridmm: Grid memory map for vision-and-language navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[46]
Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and-language navigation
Zihan Wang, Seungjun Lee, and Gim Hee Lee. Dynam3d: Dynamic layered 3d tokens empower vlm for vision-and-language navigation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[47]
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, Xihui Liu, and Jiangmiao Pang. Streamvln: Streaming vision-and-language navigation via slowfast context modeling.arXiv preprint arXiv:2507.05240, 2025
-
[48]
Mimo-v2.5
Xiaomi MiMo Team. Mimo-v2.5. https://huggingface.co/collections/XiaomiMiMo/ mimo-v25, 2026. Accessed: 2026-05-06
2026
-
[49]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[50]
Liu Yang, Huiyu Duan, Ran Tao, Juntao Cheng, Sijing Wu, Yunhao Li, Jing Liu, Xiongkuo Min, and Guangtao Zhai. ODI-Bench: Can MLLMs understand immersive omnidirectional environments?arXiv preprint arXiv:2510.11549, 2025. 14
-
[51]
Cambrian-s: Towards spatial supersens- ing in video.arXiv preprint arXiv:2511.04670, 2025
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, Zihan Zheng, Yifan Xu, Muhan Wang, Daohan Lu, Rob Fergus, Yann LeCun, Li Fei- Fei, and Saining Xie. Cambrian-s: Towards spatial supersensing in video.arXiv preprint arXiv:2511.04670, 2025
-
[52]
Osrt: Omni- directional image super-resolution with distortion-aware transformer
Fanghua Yu, Xintao Wang, Mingdeng Cao, Gen Li, Ying Shan, and Chao Dong. Osrt: Omni- directional image super-resolution with distortion-aware transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13283–13292, 2023
2023
-
[53]
Thinking in 360 ◦: Humanoid visual search in the wild.arXiv preprint arXiv:2511.20351, 2025
Heyang Yu, Yinan Han, Xiangyu Zhang, Baiqiao Yin, Bowen Chang, Xiangyu Han, Xinhao Liu, Jing Zhang, Marco Pavone, Chen Feng, Saining Xie, and Yiming Li. Thinking in 360 ◦: Humanoid visual search in the wild.arXiv preprint arXiv:2511.20351, 2025
-
[54]
Pano-avqa: Grounded audio-visual question answering on 360 ◦ videos, 2021
Heeseung Yun, Youngjae Yu, Wonsuk Yang, Kangil Lee, and Gunhee Kim. Pano-avqa: Grounded audio-visual question answering on 360 ◦ videos, 2021. URL https://arxiv. org/abs/2110.05122
-
[55]
How to enable llm with 3d capacity? a survey of spatial reasoning in llm
Junsheng Zha et al. How to enable llm with 3d capacity? a survey of spatial reasoning in llm. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, 2025
2025
-
[56]
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224, 2024
-
[57]
Omnidirectional spatial modeling from correlated panoramas.arXiv preprint arXiv:2509.02164, 2025
Xinshen Zhang, Tongxi Fu, and Xu Zheng. Omnidirectional spatial modeling from correlated panoramas.arXiv preprint arXiv:2509.02164, 2025
-
[58]
Xinshen Zhang, Zhen Ye, and Xu Zheng. Towards omnidirectional reasoning with 360-r1: A dataset, benchmark, and GRPO-based method.arXiv preprint arXiv:2505.14197, 2025
-
[59]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Efficient-vln: A training-efficient vision-language navigation model.arXiv preprint arXiv:2512.10310, 2025
-
[60]
Video-3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8995–9006, 2025
2025
-
[61]
Structured3d: A large photo-realistic dataset for structured 3d modeling
Jia Zheng, Junfei Zhang, Jing Li, Rui Tang, Shenghua Gao, and Zihan Zhou. Structured3d: A large photo-realistic dataset for structured 3d modeling. InEuropean Conference on Computer Vision, pages 519–535. Springer, 2020
2020
-
[62]
Xu Zheng, Zihao Dongfang, Lutao Jiang, Boyuan Zheng, Yulong Guo, Zhenquan Zhang, Giuliano Albanese, Runyi Yang, Mengjiao Ma, Zixin Zhang, Chenfei Liao, Dingcheng Zhen, Yuanhuiyi Lyu, Yuqian Fu, Bin Ren, Linfeng Zhang, Danda Pani Paudel, Nicu Sebe, Luc Van Gool, and Xuming Hu. Multimodal spatial reasoning in the large model era: A survey and benchmarks.arX...
-
[63]
Omnisam: Omnidirectional segment anything model for uda in panoramic semantic segmentation
Ding Zhong, Xu Zheng, Chenfei Liao, Yuanhuiyi Lyu, Jialei Chen, Shengyang Wu, Linfeng Zhang, and Xuming Hu. Omnisam: Omnidirectional segment anything model for uda in panoramic semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23892–23901, 2025
2025
-
[64]
Dense360: Dense understanding from omnidirectional panoramas.arXiv preprint arXiv:2506.14471, 2025
Yikang Zhou, Tao Zhang, Dizhe Zhang, Shunping Ji, Xiangtai Li, and Lu Qi. Dense360: Dense understanding from omnidirectional panoramas.arXiv preprint arXiv:2506.14471, 2025
-
[65]
Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities
Chenming Zhu, Tai Wang, Wenwei Zhang, Jiangmiao Pang, and Xihui Liu. Llava-3d: A simple yet effective pathway to empowering lmms with 3d capabilities. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4295–4305, 2025
2025
-
[66]
Weiye Zhu, Zekai Zhang, Xiangchen Wang, Hewei Pan, Teng Wang, Tiantian Geng, Rongtao Xu, and Feng Zheng. Navida: Vision-language navigation with inverse dynamics augmentation. arXiv preprint arXiv:2601.18188, 2026. 15 A Dataset Details A.1 ERP Corpus Composition Table 9 summarizes the ERP image sources. Our ERP corpus contains 570,321 full-surround panora...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.