Recognition: unknown
STAR: Semantic-Temporal Adaptive Representation Learning for Few-Shot Action Recognition
Pith reviewed 2026-05-14 20:14 UTC · model grok-4.3
The pith
STAR resolves semantic-temporal misalignment in few-shot action recognition by aligning frame-level cues with text and refining prototypes via Mamba blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that semantic-temporal misalignment and inadequate multi-scale temporal modeling in few-shot action recognition are addressed by a Temporal Semantic Attention module that performs frame-level cross-modal alignment and a Semantic Temporal Prototype Refiner that integrates semantic-guided Mamba blocks with multi-frequency sampling and bidirectional refinement, together with LLM-derived class descriptors, to produce temporally consistent and discriminative prototypes for novel actions.
What carries the argument
The Temporal Semantic Attention (TSA) mechanism for frame-level semantic alignment and the Semantic Temporal Prototype Refiner (STPR) that uses semantic-guided Mamba blocks with multi-frequency temporal sampling.
If this is right
- Higher accuracy on SSv2-Full, SSv2-Small, and HMDB51 under the 1-shot protocol compared with prior few-shot methods.
- Better preservation of both short-term discriminative cues and long-range temporal dependencies in video sequences.
- Successful transfer of sequence-modeling capabilities from state-space models into the few-shot action recognition setting.
- Additional long-range semantic guidance supplied by temporally dependent class descriptors from large language models.
Where Pith is reading between the lines
- The same alignment and refinement strategy could be tested on other few-shot video tasks such as temporal action detection or video object segmentation.
- If the components prove robust, training costs for action recognition systems in domains with scarce labels would decrease.
- Further gains may appear when the Mamba-based refiner is combined with additional modalities or larger backbone models.
Load-bearing premise
The TSA and STPR components will transfer effectively to unseen real-world video distributions beyond the five evaluated benchmarks.
What would settle it
A controlled test on a held-out video dataset containing action categories with different temporal structures and visual sparsity patterns, where the full STAR framework shows no accuracy gain over a baseline that lacks the TSA and STPR modules.
Figures







read the original abstract
Few-shot action recognition (FSAR) requires models to generalize to novel action categories from only a handful of annotated samples. Despite progress with vision-language models, existing approaches still suffer from semantic-temporal misalignment, where static textual prompts fail to capture decisive visual cues that appear sparsely across sequences, and from inadequate modeling of multi-scale temporal dynamics, as short-term discriminative cues and long-range dependencies are often either oversmoothed or fragmented. To address these challenges, we propose Semantic Temporal Adaptive Representation Learning (STAR), a unified framework, consisting of a semantic-alignment component and a temporal-aware component, effectively bridging the semantic and temporal gaps and transferring the sequence modeling capability of Mamba into the FSAR. The semantic alignment module introduces a Temporal Semantic Attention (TSA) mechanism, which performs frame-level cross-modal alignment with textual cues, ensuring fine-grained semantic-temporal consistency. The temporal-aware module incorporates a Semantic Temporal Prototype Refiner (STPR) that integrates semantic-guided Mamba blocks with multi-frequency temporal sampling and bidirectional state-space refinement, yielding semantically aligned prototypes with enhanced discriminative fidelity and temporal consistency. Furthermore, temporally dependent class descriptors derived from large language models (LLMs) provide long-range semantic guidance. Extensive experiments on five FSAR benchmarks demonstrate the consistent superiority of STAR over state-of-the-art methods. For instance, STAR achieves up to 8.1% and 6.7% gains on the SSv2-Full and SSv2-Small datasets under the 1-shot setting, and 7.3% on HMDB51, validating its effectiveness under limited supervision. The code is available at https://github.com/HongliLiu1/STAR-main.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces STAR, a unified framework for few-shot action recognition that combines a Temporal Semantic Attention (TSA) module for frame-level cross-modal semantic alignment with a Semantic Temporal Prototype Refiner (STPR) that employs semantic-guided Mamba blocks, multi-frequency temporal sampling, and bidirectional state-space refinement, augmented by LLM-derived temporally dependent class descriptors. It reports consistent outperformance over prior methods on five FSAR benchmarks, with specific gains of up to 8.1% and 6.7% on SSv2-Full and SSv2-Small under the 1-shot protocol and 7.3% on HMDB51.
Significance. If the empirical gains prove robust, the work offers a practical advance in FSAR by explicitly targeting semantic-temporal misalignment through integrated vision-language and state-space modeling components. The public code release provides a direct path for independent verification and extension, which strengthens the contribution relative to purely architectural proposals.
major comments (2)
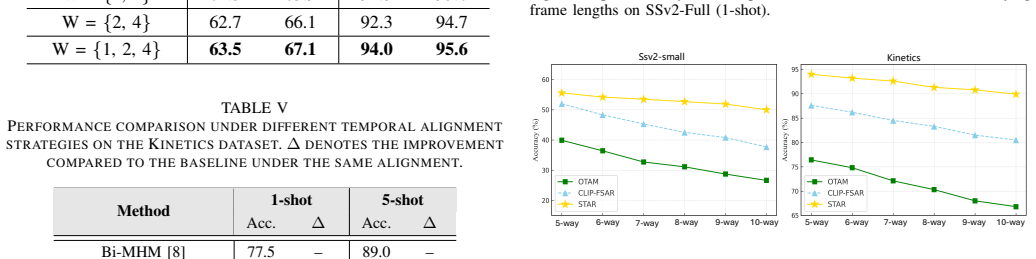
- [§4 (Experiments), Table 2 and Table 3] §4 (Experiments), Table 2 and Table 3: the reported improvements (e.g., 8.1% on SSv2-Full 1-shot) are given as single-point estimates without error bars, standard deviations across random seeds, or statistical significance tests; this leaves open whether the gains attributable to TSA and STPR exceed run-to-run variance and therefore weakens the central performance claim.
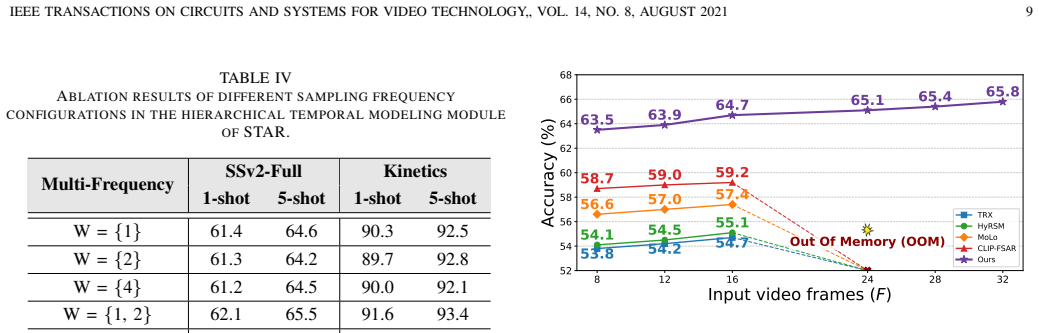
- [§3.2 (STPR description)] §3.2 (STPR description): the multi-frequency temporal sampling and bidirectional Mamba refinement are presented as key innovations, yet the ablation in Table 4 does not isolate the contribution of the frequency sampling schedule from the underlying Mamba blocks and LLM descriptors, making it impossible to attribute the reported prototype quality gains specifically to the proposed components.
minor comments (3)
- [Abstract] Abstract: the phrase 'transferring the sequence modeling capability of Mamba into the FSAR' is imprecise; FSAR is already defined earlier in the sentence, but the transfer mechanism should be stated more explicitly.
- [§3.1 (TSA)] §3.1 (TSA): the cross-modal attention formulation would benefit from an explicit equation showing how frame-level visual features are aligned with the LLM-derived textual cues, rather than relying solely on the prose description.
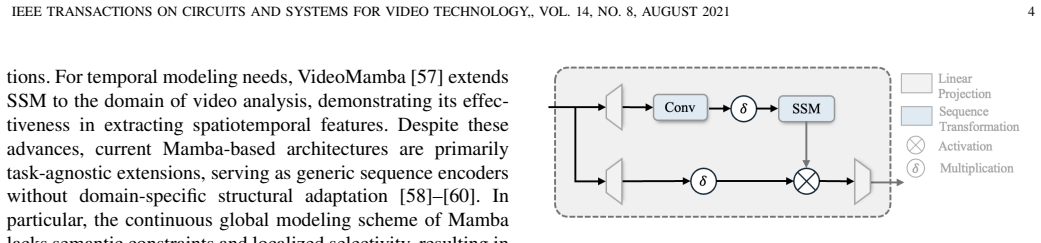
- [Figure 2] Figure 2: the diagram of the overall pipeline is clear, but the legend for the Mamba block colors and the bidirectional arrows is missing, reducing readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The comments highlight important aspects of empirical robustness and component isolation that we will address in the revised manuscript.
read point-by-point responses
-
Referee: [§4 (Experiments), Table 2 and Table 3] §4 (Experiments), Table 2 and Table 3: the reported improvements (e.g., 8.1% on SSv2-Full 1-shot) are given as single-point estimates without error bars, standard deviations across random seeds, or statistical significance tests; this leaves open whether the gains attributable to TSA and STPR exceed run-to-run variance and therefore weakens the central performance claim.
Authors: We agree that single-point estimates limit the strength of the performance claims. In the revision we will rerun the primary 1-shot and 5-shot experiments on SSv2-Full, SSv2-Small and HMDB51 using five independent random seeds, reporting mean accuracy together with standard deviation for all methods in Tables 2 and 3. We will also include a brief note on whether the observed margins exceed the reported standard deviations. revision: yes
-
Referee: [§3.2 (STPR description)] §3.2 (STPR description): the multi-frequency temporal sampling and bidirectional Mamba refinement are presented as key innovations, yet the ablation in Table 4 does not isolate the contribution of the frequency sampling schedule from the underlying Mamba blocks and LLM descriptors, making it impossible to attribute the reported prototype quality gains specifically to the proposed components.
Authors: We acknowledge that the current Table 4 ablation does not disentangle the multi-frequency sampling schedule from the Mamba blocks and LLM descriptors. In the revision we will add two new rows to Table 4: (i) STPR without multi-frequency sampling (uniform sampling only) and (ii) STPR with frequency sampling but without bidirectional refinement. These controlled variants will allow readers to attribute performance differences more precisely to each sub-component. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical engineering framework (STAR) with two new modules—TSA for frame-level cross-modal alignment and STPR for semantic-guided Mamba-based temporal refinement—plus LLM-derived descriptors. Claims rest on reported benchmark gains (e.g., +8.1% on SSv2-Full 1-shot) rather than any closed mathematical derivation. No equations, fitted parameters, or self-citations are shown that reduce the central results to inputs by construction. External components (Mamba, LLMs) and released code provide independent verification paths, so the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in supervised deep learning for video classification hold, including that training and test distributions share similar statistics.
Reference graph
Works this paper leans on
-
[1]
Tsm: Temporal shift module for efficient video understanding,
J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” in2019 IEEE/CVF International Conference on Computer Vision, 2019, pp. 7082–7092
work page 2019
-
[2]
Learn- ing spatiotemporal features with 3d convolutional networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learn- ing spatiotemporal features with 3d convolutional networks,” inIEEE International Conference on Computer Vision, 2015, pp. 4489–4497
work page 2015
-
[3]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the kinetics dataset,”CoRR, vol. abs/1705.07750, 2017. [Online]. Available: http://arxiv.org/abs/1705.07750
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Hu- man action recognition from various data modalities: A review,
Z. Sun, Q. Ke, H. Rahmani, M. Bennamoun, G. Wang, and J. Liu, “Hu- man action recognition from various data modalities: A review,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3200–3225, 2023
work page 2023
-
[5]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inIEEE/CVF International Confer- ence on Computer Vision, 2021, pp. 6836–6846
work page 2021
-
[6]
Compound memory networks for few-shot video classification,
L. Zhu and Y . Yang, “Compound memory networks for few-shot video classification,” inEuropean conference on computer vision, 2018, pp. 751–766
work page 2018
-
[7]
Few-shot video classification via temporal alignment,
K. Cao, J. Ji, Z. Cao, C.-Y . Chang, and J. C. Niebles, “Few-shot video classification via temporal alignment,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 615–10 624
work page 2020
-
[8]
Hybrid relation guided set matching for few-shot action recognition,
X. Wang, S. Zhang, Z. Qing, M. Tang, Z. Zuo, C. Gao, R. Jin, and N. Sang, “Hybrid relation guided set matching for few-shot action recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 19 948–19 957
work page 2022
-
[9]
Prototypical networks for few-shot learning,
J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,”Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[10]
Matching compound prototypes for few-shot action recognition,
Y . Huang, L. Yang, G. Chen, H. Zhang, F. Lu, and Y . Sato, “Matching compound prototypes for few-shot action recognition,”International Journal of Computer Vision, vol. 132, no. 9, pp. 3977–4002, 2024
work page 2024
-
[11]
Tarn: Temporal attentive relation network for few-shot and zero-shot action recognition,
M. Bishay, G. Zoumpourlis, and I. Patras, “Tarn: Temporal attentive relation network for few-shot and zero-shot action recognition,” in British Machine Vision Conference, 2019, p. 154
work page 2019
-
[12]
Temporal alignment- free video matching for few-shot action recognition,
S. Lee, W. Moon, H. S. Seong, and J.-P. Heo, “Temporal alignment- free video matching for few-shot action recognition,”arXiv preprint arXiv:2504.05956, 2025
-
[13]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[14]
Clip-guided prototype modulating for few-shot action recognition,
X. Wang, S. Zhang, J. Cen, C. Gao, Y . Zhang, D. Zhao, and N. Sang, “Clip-guided prototype modulating for few-shot action recognition,” International Journal of Computer Vision, vol. 132, no. 6, pp. 1899– 1912, 2024
work page 1912
-
[15]
Temporal-attentive covariance pooling networks for video recognition,
Z. Gao, Q. Wang, B. Zhang, Q. Hu, and P. Li, “Temporal-attentive covariance pooling networks for video recognition,”Advances in Neural Information Processing Systems, vol. 34, pp. 13 587–13 598, 2021
work page 2021
-
[16]
Compound prototype matching for few- shot action recognition,
Y . Huang, L. Yang, and Y . Sato, “Compound prototype matching for few- shot action recognition,” inEuropean Conference on Computer Vision, 2022, pp. 351–368
work page 2022
-
[17]
Slowfocus: Enhancing fine-grained temporal understanding in video llm,
M. Nie, D. Ding, C. Wang, Y . Guo, J. Han, H. Xu, and L. Zhang, “Slowfocus: Enhancing fine-grained temporal understanding in video llm,” inAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[18]
Mvp-shot: Multi-velocity progressive-alignment framework for few-shot action recognition,
H. Qu, R. Yan, X. Shu, H. Gao, P. Huang, and G.-S. Xie, “Mvp-shot: Multi-velocity progressive-alignment framework for few-shot action recognition,”arXiv preprint arXiv:2405.02077, 2024
-
[19]
Frame order matters: A temporal sequence-aware model for few-shot action recognition,
B. Li, M. Liu, G. Wang, and Y . Yu, “Frame order matters: A temporal sequence-aware model for few-shot action recognition,”arXiv preprint arXiv:2408.12475, 2024
-
[20]
Mamba: Linear-time sequence modeling with selective state spaces,
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” inFirst Conference on Language Modeling, 2024
work page 2024
-
[21]
Reallocating and evolving general knowledge for few-shot learning,
Y . Su, X. Liu, Z. Huang, J. He, R. Hong, and M. Wang, “Reallocating and evolving general knowledge for few-shot learning,”IEEE Transac- tions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[22]
Few-shot cross-domain object detection with instance-level prototype-based meta-learning,
L. Zhang, B. Zhang, B. Shi, J. Fan, and T. Chen, “Few-shot cross-domain object detection with instance-level prototype-based meta-learning,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9078–9089, 2024
work page 2024
-
[23]
Matching networks for one shot learning,
O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” inAdvances in Neural Information Processing Systems, vol. 29, 2016, pp. 3637–3645
work page 2016
-
[24]
Learning to compare: Relation network for few-shot learning,
F. Sung, Y . Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” inIEEE conference on computer vision and pattern recognition, 2018, pp. 1199– 1208
work page 2018
-
[25]
Unify the views: View-consistent prototype learning for few-shot segmentation,
H. Liu, Y . Wang, and S. Zhao, “Unify the views: View-consistent prototype learning for few-shot segmentation,” 2026. [Online]. Available: https://arxiv.org/abs/2603.05952
-
[26]
Few-shot metric learning: Online adaptation of embedding for retrieval,
D. Jung, D. Kang, S. Kwak, and M. Cho, “Few-shot metric learning: Online adaptation of embedding for retrieval,” inProceedings of the Asian Conference on Computer Vision, 2022, pp. 1875–1891
work page 2022
-
[27]
Revisiting few-shot learning from a causal perspective,
G. Lin, Y . Xu, H. Lai, and J. Yin, “Revisiting few-shot learning from a causal perspective,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6908–6919, 2024
work page 2024
-
[28]
Learning attention-guided pyrami- dal features for few-shot fine-grained recognition,
H. Tang, C. Yuan, Z. Li, and J. Tang, “Learning attention-guided pyrami- dal features for few-shot fine-grained recognition,”Pattern Recognition, vol. 130, p. 108792, 2022
work page 2022
-
[29]
Blockmix: meta regularization and self-calibrated inference for metric-based meta-learning,
H. Tang, Z. Li, Z. Peng, and J. Tang, “Blockmix: meta regularization and self-calibrated inference for metric-based meta-learning,” inProceedings of the 28th ACM international conference on multimedia, 2020, pp. 610– 618
work page 2020
-
[30]
Model-agnostic meta-learning for fast adaptation of deep networks,
C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” inInternational conference on machine learning. PMLR, 2017, pp. 1126–1135
work page 2017
-
[31]
Meta-exploiting frequency prior for cross-domain few-shot learning,
F. Zhou, P. Wang, L. Zhang, Z. Chen, W. Wei, C. Ding, G. Lin, and Y . Zhang, “Meta-exploiting frequency prior for cross-domain few-shot learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 116 783–116 814, 2024
work page 2024
-
[32]
On the stability and generalization of meta- learning,
Y . Wang and R. Arora, “On the stability and generalization of meta- learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 83 665–83 710, 2024
work page 2024
-
[33]
Few-shot action recognition via multi-view representation learning,
X. Wang, Y . Lu, W. Yu, Y . Pang, and H. Wang, “Few-shot action recognition via multi-view representation learning,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 9, pp. 8522– 8535, 2024
work page 2024
-
[34]
Task- adapter: Task-specific adaptation of image models for few-shot action recognition,
C. Cao, Y . Zhang, Y . Yu, Q. Lv, L. Min, and Y . Zhang, “Task- adapter: Task-specific adaptation of image models for few-shot action recognition,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 9038–9047
work page 2024
-
[35]
Cross-modal contrastive pre-training for few-shot skeleton action recognition,
M. Lu, S. Yang, X. Lu, and J. Liu, “Cross-modal contrastive pre-training for few-shot skeleton action recognition,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 10, pp. 9798–9807, 2024
work page 2024
-
[36]
Dual-recommendation disentanglement network for view fuzz in action recognition,
W. Liu, X. Zhong, Z. Zhou, K. Jiang, Z. Wang, and C.-W. Lin, “Dual-recommendation disentanglement network for view fuzz in action recognition,”IEEE Transactions on Image Processing, vol. 32, pp. 2719– 2733, 2023
work page 2023
-
[37]
Motion- consistent representation learning for uav-based action recognition,
W. Liu, X. Zhong, Y . Dai, X. Jia, Z. Wang, and S. Satoh, “Motion- consistent representation learning for uav-based action recognition,” IEEE Transactions on Intelligent Transportation Systems, 2025
work page 2025
-
[38]
Depth guided adaptive meta-fusion network for few-shot video recognition,
Y . Fu, L. Zhang, J. Wang, Y . Fu, and Y .-G. Jiang, “Depth guided adaptive meta-fusion network for few-shot video recognition,” inACM International Conference on Multimedia, 2020, p. 1142–1151
work page 2020
-
[39]
Temporal-relational crosstransformers for few-shot action recognition,
T. Perrett, A. Masullo, T. Burghardt, M. Mirmehdi, and D. Damen, “Temporal-relational crosstransformers for few-shot action recognition,” inComputer Vision and Pattern Recognition, 2021, pp. 475–484
work page 2021
-
[40]
Semantic-guided relation propagation network for few-shot action recognition,
X. Wang, W. Ye, Z. Qi, X. Zhao, G. Wang, Y . Shan, and H. Wang, “Semantic-guided relation propagation network for few-shot action recognition,” inACM International Conference on Multimedia, 2021, pp. 816–825
work page 2021
-
[41]
Molo: Motion-augmented long-short contrastive learning for few-shot action recognition,
X. Wang, S. Zhang, Z. Qing, C. Gao, Y . Zhang, D. Zhao, and N. Sang, “Molo: Motion-augmented long-short contrastive learning for few-shot action recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 18 011–18 021
work page 2023
-
[42]
M3net: multi- view encoding, matching, and fusion for few-shot fine-grained action recognition,
H. Tang, J. Liu, S. Yan, R. Yan, Z. Li, and J. Tang, “M3net: multi- view encoding, matching, and fusion for few-shot fine-grained action recognition,” inProceedings of the 31st ACM international conference on multimedia, 2023, pp. 1719–1728
work page 2023
-
[43]
Hierarchy- aware interactive prompt learning for few-shot classification,
X. Yin, J. Wu, W. Yang, X. Zhou, S. Zhang, and T. Zhang, “Hierarchy- aware interactive prompt learning for few-shot classification,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
work page 2024
-
[44]
Rethinking few-shot adaptation of vision-language models in two stages,
M. Farina, M. Mancini, G. Iacca, and E. Ricci, “Rethinking few-shot adaptation of vision-language models in two stages,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 29 989–29 998
work page 2025
-
[45]
Connecting giants: synergistic knowledge transfer of large multimodal models for few-shot learning,
H. Tang, S. He, and J. Qin, “Connecting giants: synergistic knowledge transfer of large multimodal models for few-shot learning,” inProceed- ings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, ser. IJCAI ’25, 2025, pp. 6227–6235. IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY ,, VOL. 14, NO. 8, AUGUST 2021 14
work page 2025
-
[46]
Cross-modal proxy evolving for ood detection with vision-language models,
H. Tang, Y . Liu, S. Yan, F. Shen, S. He, and J. Qin, “Cross-modal proxy evolving for ood detection with vision-language models,”Proceedings of the AAAI Conference on Artificial Intelligence, no. 18, pp. 15 770– 15 778, 2026
work page 2026
-
[47]
Multi-speed global contextual subspace matching for few-shot action recognition,
T. Yu, P. Chen, Y . Dang, R. Huan, and R. Liang, “Multi-speed global contextual subspace matching for few-shot action recognition,” inACM International Conference on Multimedia, 2023, pp. 2344–2352
work page 2023
-
[48]
On the importance of spatial relations for few-shot action recognition,
Y . Zhang, Y . Fu, X. Ma, L. Qi, J. Chen, Z. Wu, and Y .-G. Jiang, “On the importance of spatial relations for few-shot action recognition,” in ACM International Conference on Multimedia, 2023, pp. 2243–2251
work page 2023
-
[49]
Combining recurrent, convolutional, and continuous-time models with linear state space layers,
A. Gu, I. Johnson, K. Goel, K. Saab, T. Dao, A. Rudra, and C. R ´e, “Combining recurrent, convolutional, and continuous-time models with linear state space layers,”Advances in Neural Information Processing Systems, vol. 34, pp. 572–585, 2021
work page 2021
-
[50]
Efficiently modeling long sequences with structured state spaces,
A. Gu, K. Goel, and C. Re, “Efficiently modeling long sequences with structured state spaces,” inInternational Conference on Learning Representations, 2022
work page 2022
-
[51]
Selective structured state-spaces for long-form video understanding,
J. Wang, W. Zhu, P. Wang, X. Yu, L. Liu, M. Omar, and R. Hamid, “Selective structured state-spaces for long-form video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6387–6397
work page 2023
-
[52]
T. Dao and A. Gu, “Transformers are ssms: generalized models and effi- cient algorithms through structured state space duality,” inInternational Conference on Machine Learning, 2024, pp. 10 041–10 071
work page 2024
-
[53]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inProceedings of the 31st International Conference on Neural Information Processing Systems, 2017, pp. 6000–6010
work page 2017
-
[54]
Mambaout: Do we really need mamba for vision?
W. Yu and X. Wang, “Mambaout: Do we really need mamba for vision?” arXiv preprint arXiv:2405.07992, 2024
-
[55]
Vision mamba: efficient visual representation learning with bidirectional state space model,
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, and X. Wang, “Vision mamba: efficient visual representation learning with bidirectional state space model,” inInternational Conference on Machine Learning, 2024, pp. 62 429–62 442
work page 2024
-
[56]
Vmamba: Visual state space model,
Y . Liu, Y . Tian, Y . Zhao, H. Yu, L. Xie, Y . Wang, Q. Ye, J. Jiao, and Y . Liu, “Vmamba: Visual state space model,”Advances in Neural Information Processing Systems, vol. 37, pp. 103 031–103 063, 2024
work page 2024
-
[57]
Videomamba: State space model for efficient video understanding,
K. Li, X. Li, Y . Wang, Y . He, Y . Wang, L. Wang, and Y . Qiao, “Videomamba: State space model for efficient video understanding,” in European Conference on Computer Vision, 2024, pp. 237–255
work page 2024
-
[58]
Mamba-adaptor: State space model adaptor for visual recognition,
F. Xie, J. Nie, Y . Tang, W. Zhang, and H. Zhao, “Mamba-adaptor: State space model adaptor for visual recognition,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 20 124–20 134
work page 2025
-
[59]
Mambavision: A hybrid mamba- transformer vision backbone,
A. Hatamizadeh and J. Kautz, “Mambavision: A hybrid mamba- transformer vision backbone,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 25 261–25 270
work page 2025
-
[60]
Groupmamba: Efficient group-based visual state space model,
A. Shaker, S. T. Wasim, S. Khan, J. Gall, and F. S. Khan, “Groupmamba: Efficient group-based visual state space model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 14 912– 14 922
work page 2025
-
[61]
Spatial channel attention for deep convolutional neural networks,
T. Liu, R. Luo, L. Xu, D. Feng, L. Cao, S. Liu, and J. Guo, “Spatial channel attention for deep convolutional neural networks,”Mathematics, vol. 10, no. 10, p. 1750, 2022
work page 2022
-
[62]
Hmdb: A large video database for human motion recognition,
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: A large video database for human motion recognition,” in2011 Interna- tional Conference on Computer Vision, 2011, pp. 2556–2563
work page 2011
-
[63]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[64]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset ,
J. Carreira and A. Zisserman, “ Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset ,” inComputer Vision and Pattern Recognition, 2017, pp. 4724–4733
work page 2017
-
[65]
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. West- phal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitaget al., “The” something something” video database for learning and evaluating visual common sense,” inIEEE International Conference on Computer Vision, 2017, pp. 5842–5850
work page 2017
-
[66]
Few-shot action recognition with permutation-invariant attention,
H. Zhang, L. Zhang, X. Qi, H. Li, P. H. Torr, and P. Koniusz, “Few-shot action recognition with permutation-invariant attention,” inEuropean Conference on Computer Vision, 2020, pp. 525–542
work page 2020
-
[67]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inComputer Vision and Pattern Recognition, 2016, pp. 770–778
work page 2016
-
[68]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations, 2021
work page 2021
-
[69]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[70]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[71]
OpenAI, “Hello gpt-4o,” https://openai.com/index/hello-gpt-4o, 2024, accessed: 2025-08-05
work page 2024
-
[72]
Gemini 2.5: Our most intelligent ai model,
Google DeepMind, “Gemini 2.5: Our most intelligent ai model,” https://blog.google/technology/google-deepmind/ gemini-model-thinking-updates-march-2025/, 2025, accessed: 2025- 08-05. Hongli LiuHongli Liu is currently pursuing the Ph.D. degree with the School of Computer Science, Tongji University, Shanghai, China. Her main re- search interests include comp...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.