Recognition: no theorem link
Comparing the Performance of Heterogeneous Conjugate Gradient and Cholesky Solvers on Various Hardware Using SYCL
Pith reviewed 2026-05-14 01:59 UTC · model grok-4.3
The pith
Heterogeneous CPU-GPU implementations of CG and Cholesky solvers run up to 32 percent faster than GPU-only versions for large matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
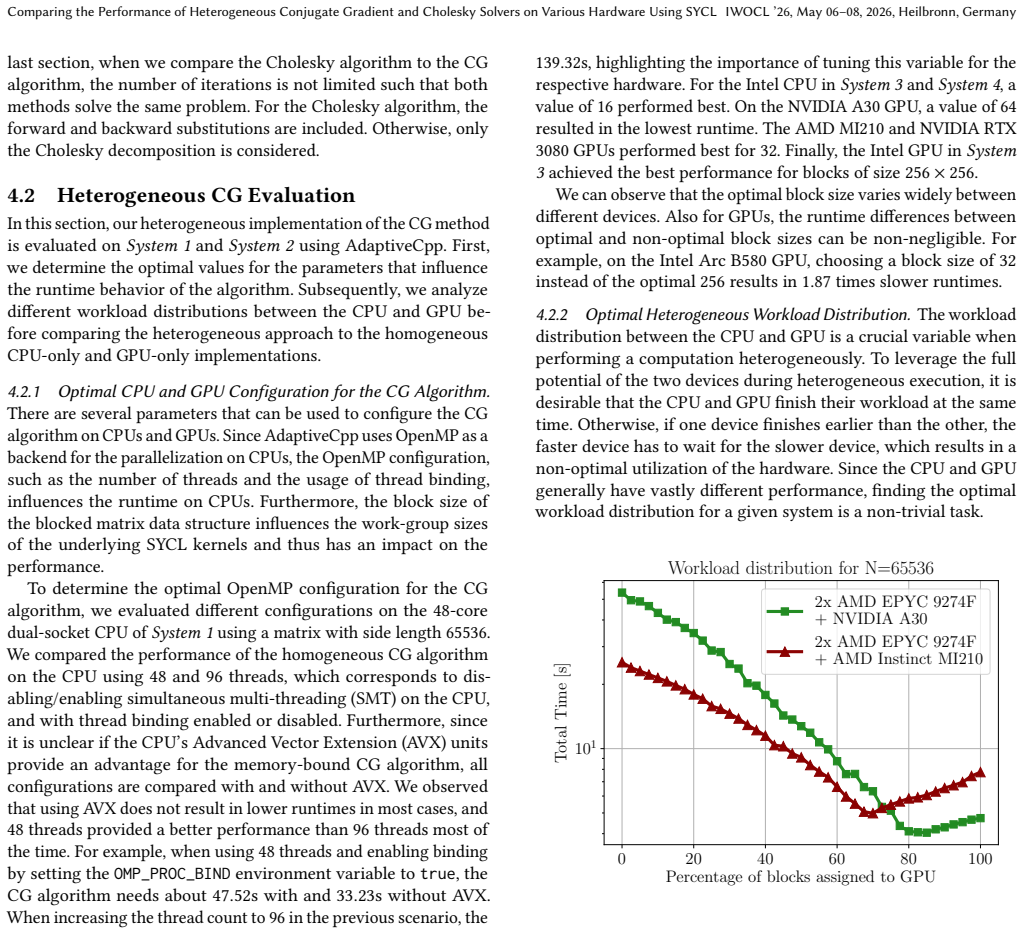
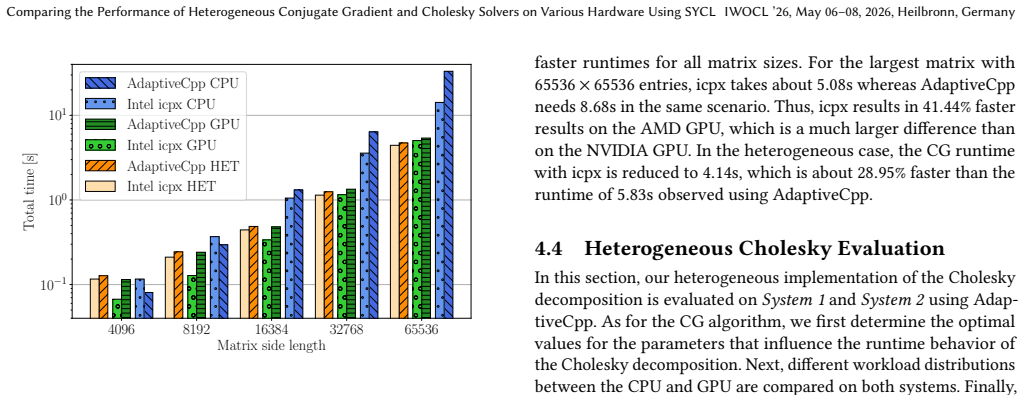
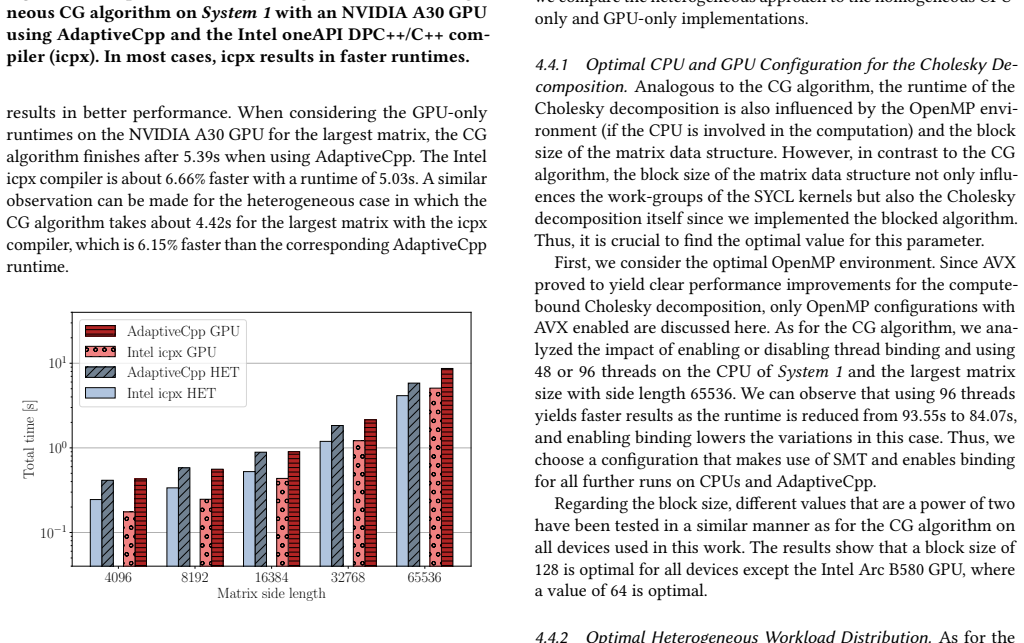
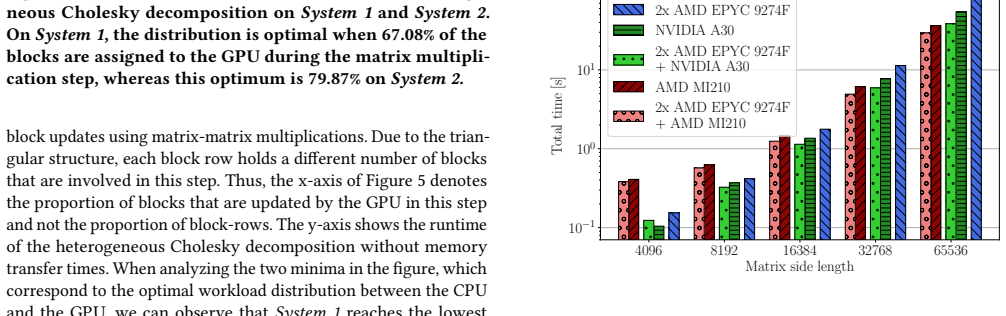
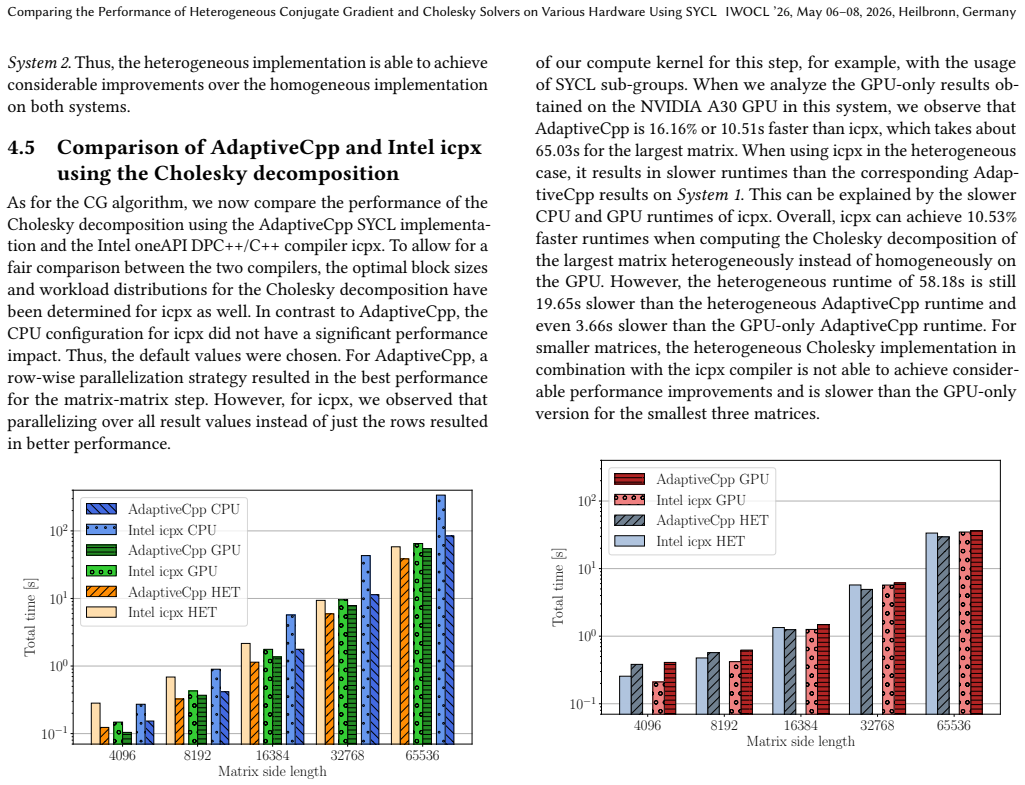
The heterogeneous implementations of the CG method and the Cholesky decomposition that leverage the CPU and GPU simultaneously using SYCL achieve up to 32 percent faster runtimes for the CG method and up to 29 percent faster for the Cholesky decomposition compared to the corresponding GPU-only implementations on large matrices. In addition, the heterogeneous Cholesky implementation achieves at least 12 percent faster runtimes across several systems with GPUs from NVIDIA, AMD, and Intel.
What carries the argument
Heterogeneous scheduling of CG iterations and Cholesky factorization steps across CPU and GPU using SYCL, with explicit management of data movement and synchronization.
If this is right
- For large matrices the heterogeneous CG solver finishes up to 32 percent sooner than the GPU-only version.
- For large matrices the heterogeneous Cholesky solver finishes up to 29 percent sooner than the GPU-only version.
- The heterogeneous Cholesky solver delivers at least 12 percent faster runtimes on systems containing NVIDIA, AMD, or Intel GPUs.
- GPU-only implementations leave the CPUs of modern HPC nodes idle during these linear solves.
Where Pith is reading between the lines
- The same heterogeneous split could be applied to other direct and iterative solvers for symmetric positive-definite systems.
- Better CPU utilization may reduce overall energy use in HPC runs that currently idle the CPU during GPU kernels.
- SYCL-based heterogeneous scheduling offers a practical path to portable performance gains without vendor-specific rewrites.
Load-bearing premise
The overhead of data movement and synchronization between CPU and GPU remains low enough for the heterogeneous schedule to outperform a well-tuned GPU-only kernel on the tested matrix sizes and hardware configurations.
What would settle it
Runtime measurements on matrices large enough or interconnects slow enough that data-transfer costs exceed the benefit of CPU participation, producing slower heterogeneous times than the GPU-only baseline.
Figures



read the original abstract
Many important real-world applications, such as System Identification with Gaussian Processes, involve solving linear systems with symmetric positive-definite matrices. The iterative CG method and direct solvers based on the Cholesky decomposition are two popular methods that can be applied in this case. Since often very large systems have to be solved when dealing with such real-world scenarios, GPUs are commonly used to accelerate the computations. However, homogeneous approaches that only leverage the GPU in the system do not take full advantage of the often powerful CPUs located in modern HPC systems. In this work, we present multi-vendor, heterogeneous implementations of the CG method and the Cholesky decomposition that leverage the CPU and GPU of a heterogeneous system simultaneously using SYCL. Furthermore, we compare their runtime behavior to traditional, homogeneous approaches. The results show that for large matrices, our heterogeneous implementation is up to 32 percent faster for the CG method and up to 29 percent faster for the Cholesky decomposition compared to the corresponding GPU-only implementations. In addition, for large matrices, our heterogeneous implementation of the Cholesky decomposition can achieve at least 12 percent faster runtimes across several systems with GPUs from NVIDIA, AMD, and Intel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents multi-vendor heterogeneous implementations of the Conjugate Gradient (CG) method and Cholesky decomposition that simultaneously use CPU and GPU via SYCL. It reports empirical runtime comparisons against homogeneous GPU-only baselines, claiming up to 32% speedup for CG and 29% for Cholesky on large matrices, plus at least 12% Cholesky gains across NVIDIA, AMD, and Intel GPUs.
Significance. If the speedups can be substantiated with overhead breakdowns, the work would demonstrate practical benefits of heterogeneous scheduling for large symmetric positive-definite linear systems in HPC, with the SYCL-based multi-vendor portability as a notable strength for reproducibility across hardware.
major comments (2)
- [Results] Results section: aggregate timings are presented for the claimed 32% CG and 29% Cholesky speedups, but no breakdown of host-device data movement costs, synchronization stalls, or CPU kernel execution share is provided for the tested matrix sizes. This directly undermines verification that the heterogeneous schedule outperforms a well-tuned GPU-only baseline rather than arising from SYCL runtime or baseline differences.
- [Abstract and Results] Abstract and Results: concrete percentage speedups are stated without accompanying matrix dimensions, iteration counts, convergence tolerances, or precise baseline kernel details, preventing independent reproduction or assessment of whether the overhead assumption holds for the reported 'large matrices'.
minor comments (1)
- [Abstract] The abstract refers to 'several systems' for the 12% Cholesky claim but does not list the specific GPU models or matrix sizes used.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. The comments highlight important aspects for improving the clarity and reproducibility of our results on heterogeneous SYCL solvers. We address each major comment below and plan to revise the manuscript accordingly to strengthen the presentation of our findings.
read point-by-point responses
-
Referee: [Results] Results section: aggregate timings are presented for the claimed 32% CG and 29% Cholesky speedups, but no breakdown of host-device data movement costs, synchronization stalls, or CPU kernel execution share is provided for the tested matrix sizes. This directly undermines verification that the heterogeneous schedule outperforms a well-tuned GPU-only baseline rather than arising from SYCL runtime or baseline differences.
Authors: We agree that a detailed breakdown would enhance the verification of our claims. In the revised manuscript, we will add a new subsection or table in the Results section providing the breakdown of execution times for data movement, CPU kernel execution, and synchronization overheads for the largest matrix sizes. This will demonstrate that the observed speedups stem from effective heterogeneous scheduling rather than implementation artifacts. Our baselines are implemented consistently within the same SYCL framework to ensure comparability. revision: yes
-
Referee: [Abstract and Results] Abstract and Results: concrete percentage speedups are stated without accompanying matrix dimensions, iteration counts, convergence tolerances, or precise baseline kernel details, preventing independent reproduction or assessment of whether the overhead assumption holds for the reported 'large matrices'.
Authors: We acknowledge the need for these details to support reproducibility. We will revise the abstract and expand the Results section to explicitly state the matrix dimensions used (ranging from small to large, with specifics for the reported speedups), the number of iterations, the convergence tolerance (1e-6), and precise descriptions of the baseline GPU-only kernels. This will allow readers to assess the applicability of our overhead assumptions. revision: yes
Circularity Check
Empirical runtime comparison with no derivations or self-referential predictions
full rationale
The paper reports measured wall-clock times for SYCL-based CG and Cholesky implementations on CPU+GPU versus GPU-only baselines across several matrix sizes and vendors. No equations, fitted parameters, uniqueness theorems, or ansatzes are introduced; the central claims are direct empirical deltas (up to 32% and 29% faster) obtained from benchmark runs. No load-bearing step reduces to a self-citation or to a quantity defined from the same data. The work is therefore self-contained against external timing measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ahmad Abdelfattah, Natalie Beams, Robert Carson, Pieter Ghysels, Tzanio Kolev, Thomas Stitt, Arturo Vargas, Stanimire Tomov, and Jack Dongarra. 2024. MAGMA: Enabling exascale performance with accelerated BLAS and LAPACK for diverse GPU architectures.The International Journal of High Performance Computing Applications38, 5 (2024), 468–490. doi:10.1177/1094...
-
[2]
Pedro Alonso, Manuel F. Dolz, Francisco D. Igual, Rafael Mayo, and Enrique S. Quintana-Ortí. 2012. Reducing Energy Consumption of Dense Linear Alge- bra Operations on Hybrid CPU-GPU Platforms. In2012 IEEE 10th International Symposium on Parallel and Distributed Processing with Applications. IEEE, 56–62. doi:10.1109/ISPA.2012.16
-
[3]
Aksel Alpay and Vincent Heuveline. 2020. SYCL beyond OpenCL: The archi- tecture, current state and future direction of hipSYCL. InProceedings of the International Workshop on OpenCL (IWOCL ’20). Association for Computing Machinery, New York, NY, USA, 1 pages. doi:10.1145/3388333.3388658
-
[4]
AMD. 2022. AMD INSTINCT™MI210 ACCELERATOR. https: //www.amd.com/content/dam/amd/en/documents/instinct-business- docs/product-briefs/instinct-mi210-brochure.pdf
work page 2022
-
[5]
AMD. 2023. AMD EPYC™9004 SERIES PROCESSORS. https://www.amd.com/ content/dam/amd/en/documents/epyc-business-docs/datasheets/amd-epyc- 9004-series-processors-datasheet.pdf
work page 2023
-
[6]
Igor Baratta, Chris Richardson, and Garth Wells. 2022. Performance analysis of matrix-free conjugate gradient kernels using SYCL. InProceedings of the 10th International Workshop on OpenCL (IWOCL ’22). Association for Computing Machinery, New York, NY, USA, 10 pages. doi:10.1145/3529538.3529993
-
[7]
Ravi Bhargava and Kai Troester. 2024. AMD Next-Generation “Zen 4” Core and 4th Gen AMD EPYC Server CPUs.IEEE Micro44, 3 (2024), 8–17. doi:10.1109/MM. 2024.3375070
work page doi:10.1109/mm 2024
-
[8]
Salvatore Cali, William Detmold, Grzegorz Korcyl, Piotr Korcyl, and Phiala Shana- han. 2021. Implementation of the conjugate gradient algorithm for heterogeneous systems. doi:10.48550/arXiv.2111.14958
-
[9]
S. Chakraborty and B. Bhattacharyya. 2002. An efficient 3D stochastic finite element method.International Journal of Solids and Structures39, 9 (2002), 2465–
work page 2002
-
[10]
doi:10.1016/S0020-7683(02)00080-X
-
[11]
DeepL SE. 2026. DeepL Translator. https://www.deepl.com/translator. Accessed: 2026-01-14
work page 2026
-
[12]
Jack Dongarra, Mark Gates, Azzam Haidar, Jakub Kurzak, Piotr Luszczek, Panruo Wu, Ichitaro Yamazaki, Asim Yarkhan, Maksims Abalenkovs, Negin Bagherpour, Sven Hammarling, Jakub Šístek, David Stevens, Mawussi Zounon, and Samuel D. Relton. 2019. PLASMA: Parallel Linear Algebra Software for Multicore Using OpenMP.ACM Trans. Math. Softw.45, 2, Article 16 (2019...
work page 2019
-
[13]
Joseph Dorris, Jakub Kurzak, Piotr Luszczek, Asim YarKhan, and Jack Dongarra
-
[14]
Task-Based Cholesky Decomposition on Knights Corner Using OpenMP. In High Performance Computing. Springer International Publishing, Cham, 544–562. doi:10.1007/978-3-319-46079-6_37
-
[15]
Mark Harris. [n. d.].Optimizing Parallel Reduction in CUDA. https://developer. download.nvidia.com/assets/cuda/files/reduction.pdf
-
[17]
2025.Replication Data for: GPRat: Gaussian Process Regression with Asynchronous Tasks
Maksim Helmann, Alexander Strack, and Dirk Pflüger. 2025.Replication Data for: GPRat: Gaussian Process Regression with Asynchronous Tasks. doi:10.18419/ DARUS-4743
work page 2025
-
[18]
Magnus R Hestenes and Eduard Stiefel. 1952. Methods of conjugate gradients for solving linear systems.Journal of research of the National Bureau of Standards49, 6 (1952), 409–436. https://nvlpubs.nist.gov/nistpubs/jres/049/jresv49n6p409_a1b. pdf
work page 1952
-
[19]
Intel. 2019. Intel®Core™i9-10980XE Extreme Edition Processor. https://www. intel.com/content/www/us/en/products/sku/198017/intel-core-i910980xe- extreme-edition-processor-24-75m-cache-3-00-ghz/specifications.html
work page 2019
-
[20]
Intel. 2024. Intel®Arc™B580 Grafik. https://www.intel.de/content/www/de/ de/products/sku/241598/intel-arc-b580-graphics/specifications.html
work page 2024
-
[21]
Khronos-Group. [n. d.].SYCL - C++ Programming for Heterogeneous Parallel Computing. https://www.khronos.org/sycl/
-
[22]
2016.Modelling and Control of Dynamic Systems Using Gaussian Process Models
Juš Kocijan. 2016.Modelling and Control of Dynamic Systems Using Gaussian Process Models. Springer International Publishing, Cham. doi:10.1007/978-3-319- 21021-6
-
[23]
Jens Lang and Gudula Rünger. 2013. Dynamic Distribution of Workload between CPU and GPU for a Parallel Conjugate Gradient Method in an Adaptive FEM. Procedia Computer Science18 (2013), 299–308. doi:10.1016/j.procs.2013.05.193 2013 International Conference on Computational Science
-
[24]
Hatem Ltaief, Stanimire Tomov, Rajib Nath, and Jack Dongarra. 2010. Hybrid multicore cholesky factorization with multiple gpu accelerators. (2010). https://www.netlib.org/utk/people/JD/JackDongarra/PAPERS/hybrid- multicore-cholesky.pdf
work page 2010
-
[25]
Trevor Maguire. 2011. Multi-processor cholesky decomposition of conductance matrices. InProceeding of the 2011 International Conference on Power System Transients (IPST-2011), Delft, The Netherlands. https://www.ipstconf.org/papers/ Proc_IPST2011/11IPST106.pdf
work page 2011
-
[26]
Rajib Nath, Stanimire Tomov, Tingxing "Tim" Dong, and Jack Dongarra. 2011-11. Optimizing symmetric dense matrix-vector multiplication on GPUs. InProceed- ings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis. 10 pages. doi:10.1145/2063384.2063392
-
[27]
Nikita S. Nedozhogin, Sergey P. Kopysov, and Alexandr K. Novikov. 2022. Scal- ability Pipelined Algorithm of the Conjugate Gradient Method on Heteroge- neous Platforms. InMesh Methods for Boundary-Value Problems and Applications. Springer International Publishing, Cham, 347–362. doi:10.1007/978-3-030-87809- 2_27
-
[28]
NVIDIA. 2021. NVIDIA AMPERE GA102 GPU ARCHITECTURE. https://www.nvidia.com/content/PDF/nvidia-ampere-ga-102-gpu- architecture-whitepaper-v2.pdf
work page 2021
-
[29]
NVIDIA. 2022. NVIDIA A30 TENSOR CORE GPU. https://www.nvidia. com/content/dam/en-zz/Solutions/data-center/products/a30-gpu/pdf/a30- datasheet.pdf
work page 2022
-
[30]
OpenAI. 2025. ChatGPT 5. https://openai.com/chatgpt. Accessed: 2026-01-14
work page 2025
-
[31]
Superhuman Platform. 2026. Grammarly. https://www.grammarly.com/. Ac- cessed: 2026-01-14
work page 2026
-
[32]
2023.Parallel Programming for Multicore and Cluster Systems(3 ed.)
Thomas Rauber and Gudula Rünger. 2023.Parallel Programming for Multicore and Cluster Systems(3 ed.). Springer International Publishing. doi:10.1007/978-3- 031-28924-8
-
[33]
Jonathan Richard Shewchuk. 1994. An Introduction to the Conjugate Gradient Method Without the Agonizing Pain. (1994)
work page 1994
-
[34]
Fengguang Song and Jack Dongarra. 2015. A scalable approach to solving dense linear algebra problems on hybrid CPU-GPU systems.Concurrency and Compu- tation: Practice and Experience27, 14 (2015), 3702–3723. doi:10.1002/cpe.3403
-
[35]
Fengguang Song, Stanimire Tomov, and Jack Dongarra. 2012. Enabling and scaling matrix computations on heterogeneous multi-core and multi-GPU systems. In Proceedings of the 26th ACM international conference on Supercomputing (ICS ’12). Association for Computing Machinery, New York, NY, USA, 365–376. doi:10. 1145/2304576.2304625
-
[36]
Guangming Tan, Linchuan Li, Sean Triechle, Everett Phillips, Yungang Bao, and Ninghui Sun. 2011. Fast implementation of DGEMM on Fermi GPU. InProceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’11). Association for Computing Machinery, New York, NY, USA, Article 35, 11 pages. doi:10.1145/20633...
-
[37]
2025.Heterogeneous Solvers for Linear Systems with Symmetric Positive-Definite Matrices Using SYCL
Tim Thüring. 2025.Heterogeneous Solvers for Linear Systems with Symmetric Positive-Definite Matrices Using SYCL. Master Thesis. University of Stuttgart
work page 2025
-
[38]
Manasi Tiwari and Sathish Vadhiyar. 2021. Efficient executions of Pipelined Conjugate Gradient Method on Heterogeneous Architectures. doi:10.48550/arXiv. 2105.06176
work page internal anchor Pith review doi:10.48550/arxiv 2021
-
[39]
S Tomov, J Dongarra, V Volkov, and J Demmel. 2009.Magma library. https: //icl.utk.edu/projectsfiles/magma/docs/magma.pdf
work page 2009
-
[40]
Unified Acceleration (UXL) Foundation. [n. d.].oneAPI Math Library (oneMath). https://github.com/uxlfoundation/oneMath
-
[41]
Alexander Van Craen, Marcel Breyer, and Dirk Pflüger. 2022. PLSSVM: A (multi- )GPGPU-accelerated Least Squares Support Vector Machine. In2022 IEEE In- ternational Parallel and Distributed Processing Symposium Workshops (IPDPSW). 818–827. doi:10.1109/IPDPSW55747.2022.00138
-
[42]
2007.The science of pro- gramming matrix computations(1 ed.)
Robert A Van De Geijn and Enrique S Quintana-Ortí. 2007.The science of pro- gramming matrix computations(1 ed.). https://www.cs.utexas.edu/~rvdg/tmp/ TSoPMC.pdf
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.