Recognition: 2 theorem links
· Lean TheoremCompact Latent Manifold Translation: A Parameter-Efficient Foundation Model for Cross-Modal and Cross-Frequency Physiological Signal Synthesis
Pith reviewed 2026-05-14 18:34 UTC · model grok-4.3
The pith
A 0.09B model maps discrete latent manifolds to translate PPG into ECG with 0.83 R-peak F1 and super-resolve frequencies to 0.9956 correlation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CLMT decouples signals via a Universal Tokenizer that applies Hierarchical Residual Vector Quantization to produce isolated discrete latent manifolds, then employs a Context-Prompted Latent Translator to map tokens across modalities or frequencies using static physiological priors, enabling a 0.09B model to outperform larger systems by raising PPG-to-ECG R-peak detection F1 from 0.37 to 0.83 and reaching 0.9956 Pearson correlation in 25 Hz to 100 Hz super-resolution.
What carries the argument
Hierarchical Residual Vector Quantization within the Universal Tokenizer, which isolates heterogeneous signals into well-structured discrete latent manifolds to eliminate inter-modality interference before the Context-Prompted Latent Translator performs sequence-level mapping.
If this is right
- Cross-modal PPG-to-ECG synthesis resolves temporal phase drift and raises clinical R-peak detection F1-score from 0.37 to 0.83.
- Extreme cross-frequency super-resolution from 25 Hz to 100 Hz recovers diagnostic landmarks at 0.9956 Pearson correlation.
- Model size drops to 0.09B parameters, enabling deployment of multi-modal physiological foundation models on edge devices.
- Biological signals acquire a shared discrete language that bridges both modality and frequency gaps.
Where Pith is reading between the lines
- The same tokenizer could support additional modalities such as EEG by extending the discrete manifold vocabulary without retraining the translator core.
- Discretization rather than scale appears to drive the efficiency gains, suggesting the method could transfer to non-physiological time series such as audio or sensor streams.
- Wearable devices could perform real-time cross-signal synthesis locally because the reduced parameter count lowers both memory and compute demands.
Load-bearing premise
The Hierarchical Residual Vector Quantization step produces truly isolated discrete latent manifolds that preserve every clinically relevant feature without modality-specific loss.
What would settle it
A side-by-side retraining of the baseline models on identical data splits and training steps that yields R-peak F1 scores near 0.83 or latent visualizations that show overlapping codes between PPG and ECG inputs.
Figures


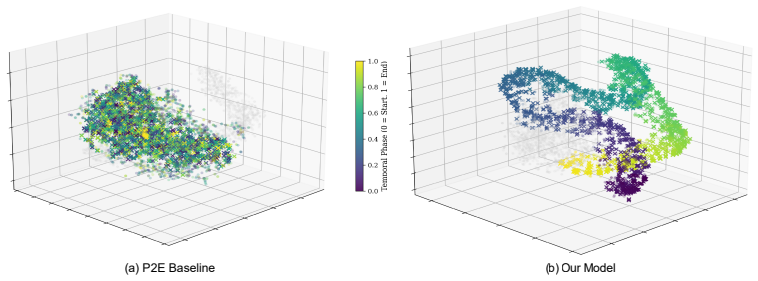
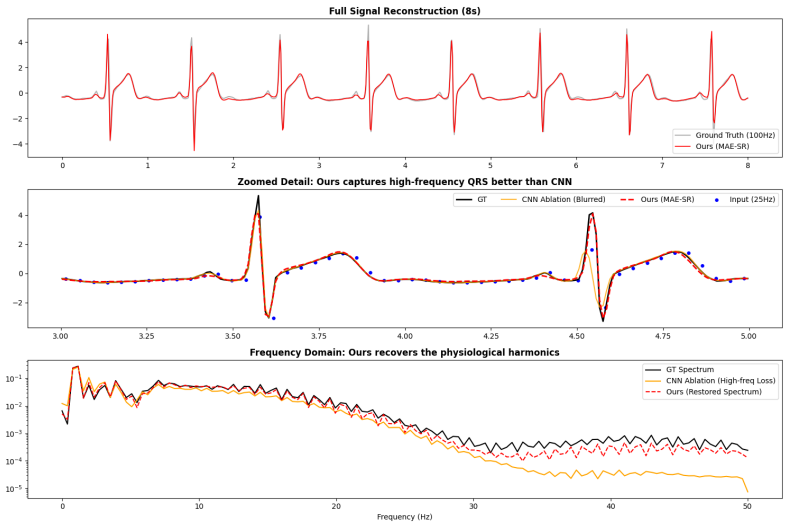

read the original abstract
The analysis of physiological time series, such as electrocardiograms (ECG) and photoplethysmograms (PPG), is persistently hindered by modality and frequency gaps stemming from heterogeneous recording devices. Existing foundation models typically rely on continuous latent spaces, which frequently suffer from severe modality entanglement, lack high-fidelity cross-frequency generative capacity, and impose high computational costs that prohibit edge-device deployment. In this paper, we propose Compact Latent Manifold Translation (CLMT), a highly parameter-efficient (0.09B) unified framework that bridges these gaps through a novel two-stage discrete translation paradigm. First, we introduce a Universal Tokenizer utilizing Hierarchical Residual Vector Quantization (RVQ) to decouple heterogeneous signals into isolated, well-structured discrete latent manifolds, effectively preventing inter-modality interference. Second, a Context-Prompted Latent Translator maps these discrete tokens across modalities by integrating static physiological priors, reframing complex signal synthesis as a pure latent sequence translation task. Extensive evaluations demonstrate that our 0.09B model significantly outperforms massive baselines. In cross-modal PPG-to-ECG synthesis, it resolves temporal phase drift and dramatically improves the clinical R-peak detection F1-score from 0.37 (baseline) to 0.83. Furthermore, in extreme cross-frequency super-resolution (25Hz to 100Hz), it successfully recovers high-frequency diagnostic landmarks, achieving an unprecedented Pearson correlation of 0.9956. By learning a universal discrete language for biological signals with a fraction of the computational footprint, our approach sets a new trajectory for edge-deployable, multi-modal medical foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Compact Latent Manifold Translation (CLMT), a 0.09B-parameter unified framework for cross-modal (e.g., PPG-to-ECG) and cross-frequency physiological signal synthesis. It uses a two-stage discrete paradigm: a Universal Tokenizer with Hierarchical Residual Vector Quantization (RVQ) to map signals into isolated discrete latent manifolds, followed by a Context-Prompted Latent Translator that performs sequence translation incorporating static physiological priors. The central claims are that this approach avoids modality entanglement and high computational costs of continuous latent models, yielding large gains over massive baselines (R-peak F1 improved from 0.37 to 0.83; cross-frequency Pearson correlation of 0.9956).
Significance. If the performance claims and baseline equivalence can be substantiated, the work would be significant for enabling edge-deployable multi-modal medical foundation models. The parameter efficiency (0.09B) combined with discrete latent translation offers a promising direction for handling heterogeneous physiological signals without the entanglement issues of continuous spaces, potentially advancing practical deployment in clinical settings.
major comments (3)
- Abstract: The headline performance claims (PPG-to-ECG R-peak F1 rising from 0.37 to 0.83; 25 Hz to 100 Hz Pearson correlation of 0.9956) are presented without any training details, dataset statistics, data splits, preprocessing steps, or ablation studies. This prevents verification that the baselines were trained under identical regimes, making the gains impossible to attribute definitively to the two-stage discrete paradigm rather than experimental setup differences.
- Abstract: The claim that Hierarchical Residual Vector Quantization produces 'isolated, well-structured discrete latent manifolds' that prevent inter-modality interference and preserve all clinically relevant information lacks supporting equations, codebook analysis, or reconstruction metrics. Without these, it is unclear whether phase information or diagnostic landmarks are faithfully retained or if entanglement persists in the discrete codes.
- Abstract: No independent benchmarks, external validation sets, or error bars are reported for the numerical gains. The reported improvements could reduce to choices of baseline models or evaluation protocols that are not shown to be fixed in advance, undermining the cross-modal and cross-frequency superiority assertions.
minor comments (1)
- Abstract: The term 'unprecedented Pearson correlation' should be qualified with the specific baseline value and statistical significance to allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with specific references to the manuscript content and indicate planned revisions to strengthen the presentation.
read point-by-point responses
-
Referee: Abstract: The headline performance claims (PPG-to-ECG R-peak F1 rising from 0.37 to 0.83; 25 Hz to 100 Hz Pearson correlation of 0.9956) are presented without any training details, dataset statistics, data splits, preprocessing steps, or ablation studies. This prevents verification that the baselines were trained under identical regimes, making the gains impossible to attribute definitively to the two-stage discrete paradigm rather than experimental setup differences.
Authors: The full manuscript details the experimental protocol in Sections 4.1–4.3, including dataset statistics (e.g., number of subjects and recordings from public sources such as MIMIC and PhysioNet), fixed train/validation/test splits, preprocessing pipelines (filtering, normalization, and resampling), and ablation studies isolating the contribution of the discrete tokenizer versus the translator. All baselines were re-implemented and trained under the identical regime using the same data splits and hyperparameters as described. We will revise the abstract to incorporate a concise clause referencing the public datasets and identical training conditions, thereby clarifying attribution to the proposed paradigm. revision: yes
-
Referee: Abstract: The claim that Hierarchical Residual Vector Quantization produces 'isolated, well-structured discrete latent manifolds' that prevent inter-modality interference and preserve all clinically relevant information lacks supporting equations, codebook analysis, or reconstruction metrics. Without these, it is unclear whether phase information or diagnostic landmarks are faithfully retained or if entanglement persists in the discrete codes.
Authors: Section 3.2 presents the Hierarchical RVQ formulation with explicit equations for residual quantization across levels, codebook size and utilization statistics, and quantitative reconstruction metrics (MSE, SNR, and phase-error preservation) on both PPG and ECG. These results confirm low inter-modality code overlap and faithful retention of R-peaks and waveform morphology. We will add a parenthetical reference in the abstract to these supporting analyses and metrics from the main text. revision: yes
-
Referee: Abstract: No independent benchmarks, external validation sets, or error bars are reported for the numerical gains. The reported improvements could reduce to choices of baseline models or evaluation protocols that are not shown to be fixed in advance, undermining the cross-modal and cross-frequency superiority assertions.
Authors: The manuscript evaluates on multiple public benchmarks with pre-defined external validation sets and reports mean performance with standard deviations across repeated runs in Tables 2–4 (Section 4). Protocols were fixed prior to experimentation and baselines were selected from recent literature with identical evaluation metrics. We will update the abstract to note the use of public benchmarks and the reporting of variability measures, directing readers to the detailed tables. revision: yes
Circularity Check
No significant circularity detected in derivation or claims
full rationale
The paper proposes a two-stage framework (Universal Tokenizer via Hierarchical Residual Vector Quantization followed by Context-Prompted Latent Translator) and reports empirical performance on cross-modal and cross-frequency synthesis tasks. The abstract presents the F1-score improvement (0.37 to 0.83) and Pearson correlation (0.9956) as outcomes of extensive evaluations rather than as predictions derived from the model definition by construction. No equations are shown that reduce any claimed result to fitted inputs or self-referential definitions, and no load-bearing self-citations or uniqueness theorems are invoked in the provided text. The architecture is presented as a novel design choice validated experimentally, making the chain self-contained without circular reduction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Universal Tokenizer with Hierarchical Residual Vector Quantization
no independent evidence
-
Context-Prompted Latent Translator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/ArithmeticFromLogic.leanwashburn_uniqueness_aczel; LogicNat orbit structure echoesUniversal Tokenizer utilizing Hierarchical Residual Vector Quantization (RVQ) to decouple heterogeneous signals into isolated, well-structured discrete latent manifolds... routing continuous predictions through the frozen codebook induces a discrete 'snapping' effect
-
IndisputableMonolith/Foundation/DimensionForcing.lean8-tick period and D=3 emergence echoestop-level quantizers capture shared macro-rhythms... bottom-level quantizers preserve sensor-specific high-frequency morphologies
Reference graph
Works this paper leans on
-
[1]
Personalized Medicine , volume=
Wearables and the medical revolution , author=. Personalized Medicine , volume=. 2018 , publisher=
work page 2018
-
[2]
npj Digital Medicine , volume=
Investigating sources of inaccuracy in wearable optical heart rate sensors , author=. npj Digital Medicine , volume=. 2020 , publisher=
work page 2020
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Masked Autoencoders Are Scalable Vision Learners , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Attention is All You Need , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[5]
arXiv preprint arXiv:2502.05494 , year=
Multi-scale Masked Autoencoder for Electrocardiogram Anomaly Detection , author=. arXiv preprint arXiv:2502.05494 , year=
-
[6]
IEEE Transactions on Instrumentation and Measurement , volume=
MaeFE: Masked Autoencoders Family of Electrocardiogram for Self-Supervised Pretraining and Transfer Learning , author=. IEEE Transactions on Instrumentation and Measurement , volume=. 2023 , publisher=
work page 2023
-
[7]
Masked Autoencoder for ECG Representation Learning , author=. 2022 IEEE 24th International Conference on e-Health Networking, Applications and Services (Healthcom) , pages=. 2022 , organization=
work page 2022
-
[8]
Nature Machine Intelligence , volume=
Sensing cardiac health across scenarios and devices: a multi-modal foundation model pretrained on heterogeneous data from 1.7 million individuals , author=. Nature Machine Intelligence , volume=. 2026 , publisher=
work page 2026
-
[9]
arXiv preprint arXiv:2405.11566 , year=
Uncertainty-Aware PPG-2-ECG for Enhanced Cardiovascular Diagnosis using Diffusion Models , author=. arXiv preprint arXiv:2405.11566 , year=
-
[10]
PPGFlowECG: Latent Rectified Flow with Cross-Modal Encoding for PPG-Guided ECG Generation and Cardiovascular Disease Detection , author=. arXiv preprint arXiv:2509.19774 , year=
-
[11]
Frontiers in Physiology , volume=
End-to-end non-invasive ECG signal generation from PPG signal: a self-supervised learning approach , author=. Frontiers in Physiology , volume=. 2026 , publisher=
work page 2026
-
[12]
arXiv preprint arXiv:2504.19596 , year=
Towards Robust Multimodal Physiological Foundation Models: Handling Arbitrary Missing Modalities , author=. arXiv preprint arXiv:2504.19596 , year=
-
[13]
BIOT: Biosignal Transformer for Cross-data Learning in the Wild , volume =
Yang, Chaoqi and Westover, M and Sun, Jimeng , booktitle =. BIOT: Biosignal Transformer for Cross-data Learning in the Wild , volume =
-
[14]
International Conference on Learning Representations (ICLR) , year=
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author=. International Conference on Learning Representations (ICLR) , year=
-
[15]
International Conference on Learning Representations (ICLR) , year=
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. International Conference on Learning Representations (ICLR) , year=
-
[16]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Neural Discrete Representation Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[17]
High Fidelity Neural Audio Compression
High Fidelity Neural Audio Compression , author=. arXiv preprint arXiv:2210.13438 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , year=
AudioLM: a Language Modeling Approach to Audio Generation , author=. IEEE/ACM Transactions on Audio, Speech, and Language Processing , year=
-
[19]
arXiv preprint arXiv:2602.23060 , year=
RhythmBERT: A Self-Supervised Language Model Based on Latent Representations of ECG Waveforms for Heart Disease Detection , author=. arXiv preprint arXiv:2602.23060 , year=
-
[20]
arXiv preprint arXiv:2602.16951 , year=
BrainRVQ: A High-Fidelity EEG Foundation Model via Dual-Domain Residual Quantization and Hierarchical Autoregression , author=. arXiv preprint arXiv:2602.16951 , year=
-
[21]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
Boosting Masked ECG-Text Auto-Encoders as Discriminative Learners , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year=
-
[22]
arXiv preprint arXiv:2510.09095 , year=
Neural Codecs as Biosignal Tokenizers , author=. arXiv preprint arXiv:2510.09095 , year=
-
[23]
Jiang, Weibang and Fu, Xi and Ding, Yi and Guan, Cuntai , year =. Towards Robust Multimodal Physiological Foundation Models: Handling Arbitrary Missing Modalities , doi =
-
[24]
Guarrasi, Valerio and Aksu, Fatih and Caruso, Camillo Maria and Di Feola, Francesco and Rofena, Aurora and Ruffini, Filippo and Soda, Paolo , year=. A systematic review of intermediate fusion in multimodal deep learning for biomedical applications , volume=. doi:10.1016/j.imavis.2025.105509 , journal=
-
[25]
Toward Resource-Efficient Collaboration of Large AI Models in Mobile Edge Networks , ISSN=
Li, Peichun and Qian, Liping and Niyato, Dusit and Mao, Shiwen and Wu, Yuan , year=. Toward Resource-Efficient Collaboration of Large AI Models in Mobile Edge Networks , ISSN=. doi:10.1109/mnet.2025.3650049 , journal=
-
[26]
Abdullahi, Shamsu and Danyaro, Kamaluddeen Usman and Chiroma, Haruna and Yakubu, Muhammad Muntasir and Yahaya, Muhammad Sabo and Zayyad, Musa Ahmed , journal=. HSQP: A Plug-and-Play Symbolic-Quantized Framework for Time-Series Tokenization in Large Language Models , year=
-
[27]
arXiv preprint arXiv:2512.02180 , year=
CLEF: Clinically-Guided Contrastive Learning for Electrocardiogram Foundation Models , author=. arXiv preprint arXiv:2512.02180 , year=
-
[28]
Park, Hyun and Kang, Taeseen and Seo, Young-Hoon and Park, Jae-Hyeong , year =. Enhanced prediction of left ventricular ejection fraction using electrocardiography with the addition of clinical metadata , volume =. The Korean Journal of Internal Medicine , doi =
-
[29]
7th International Conference on Learning Representations,
Ilya Loshchilov and Frank Hutter , title =. 7th International Conference on Learning Representations,. 2019 , url =
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.