Recognition: 2 theorem links
· Lean TheoremDiscrete Diffusion for Complex and Congested Multi-Agent Path Finding with Sparse Social Attention
Pith reviewed 2026-05-14 19:28 UTC · model grok-4.3
The pith
A discrete diffusion model generates initial joint plans that let a repair solver achieve 95.8 percent success on crowded multi-agent path problems with hundreds of agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiffLNS integrates a discrete denoising diffusion probabilistic model with sparse social attention to initialize plans for the LNS2 repair-based solver in multi-agent path finding. The model learns a spatiotemporal prior over joint action trajectories from expert demonstrations on small instances and samples multiple diverse joint plans that serve as warm starts. These drafts are completed and conflict-resolved by the downstream repair step under hard MAPF constraints, resulting in an average success rate of 95.8 percent across twenty complex congested settings while generalizing to agent counts more than three times larger than those seen in training.
What carries the argument
Discrete denoising diffusion probabilistic model with sparse social attention that samples multimodal joint plans directly in the categorical action space to produce repair-friendly initial trajectories.
Load-bearing premise
The spatiotemporal prior learned by the diffusion model from expert demonstrations on small instances remains useful and produces repair-friendly drafts when applied to much larger agent counts and unseen congested layouts.
What would settle it
A sharp drop in success rate or repeated failure of the repair step when the same model is tested on environments whose topology or agent density lies outside the distribution of the original training demonstrations.
Figures





read the original abstract
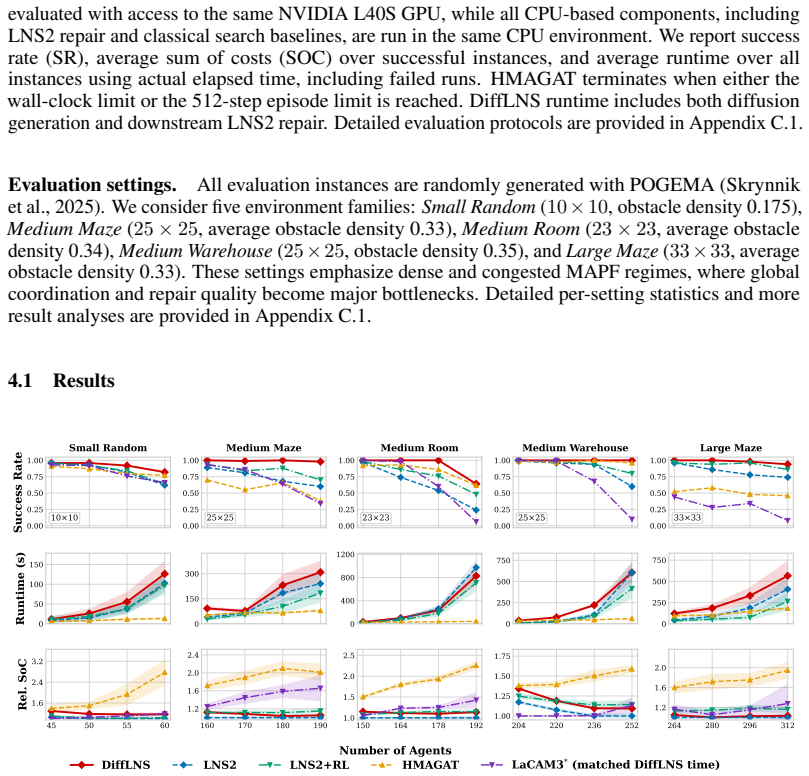
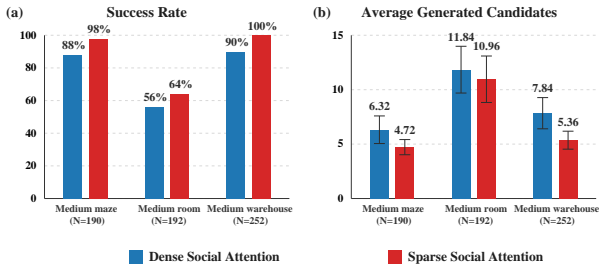
Multi-Agent Path Finding (MAPF) is a coordination problem that requires computing globally consistent, collision-free trajectories from individual start positions to assigned goal positions under combinatorial planning complexity. In dense environments, suboptimal initial plans induce compound conflicts that hinder feasible repair. For repair-based solvers like LNS2, initial plan quality critically affects downstream repair, yet this factor remains underexplored. We propose DiffLNS, a hybrid framework that integrates a discrete denoising diffusion probabilistic model (D3PM) with LNS2. The D3PM serves as an initializer with sparse social attention that learns a spatiotemporal prior over coordinated multi-agent action trajectories from expert demonstrations and samples multiple joint plans. Operating directly on the categorical action space, our discrete diffusion preserves the MAPF action structure and samples from a multimodal joint-plan distribution to produce diverse drafts well suited for neighborhood repair. These drafts act as warm starts for downstream repair, which completes unfinished trajectories and resolves remaining conflicts under hard MAPF constraints. Experimental results show that despite being trained only on instances with at most 96 agents, the initializer generalizes to scenarios with up to 312 agents at inference time. Across 20 complex and congested settings, DiffLNS achieves an average success rate of 95.8%, outperforming the strongest tested baseline by 9.6 percentage points and matching or exceeding all baselines in all 20 settings. To the best of our knowledge, this is the first work to leverage discrete diffusion for warm-starting an LNS-based MAPF solver.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiffLNS, a hybrid MAPF solver that uses a discrete denoising diffusion probabilistic model (D3PM) with sparse social attention as an initializer to generate diverse joint plans from a learned spatiotemporal prior, which are then repaired by LNS2. Trained only on instances with at most 96 agents, the initializer is claimed to generalize to up to 312 agents at inference. Across 20 complex congested settings, DiffLNS reports 95.8% average success rate, outperforming the strongest baseline by 9.6 percentage points while matching or exceeding all baselines in every setting. It positions itself as the first application of discrete diffusion for warm-starting LNS-based MAPF.
Significance. If the generalization and performance claims hold under scrutiny, the work would be significant for demonstrating that discrete diffusion can learn useful multimodal priors over coordinated trajectories in MAPF, improving initialization quality for repair-based solvers in dense environments. The reported ability to scale from training on <=96 agents to inference on 312 agents, combined with consistent outperformance, suggests a practical advance for congested MAPF instances where traditional initializers struggle. Explicit credit is due for the empirical coverage across all 20 test settings and for operating directly on categorical action spaces.
major comments (3)
- Abstract and experimental section: The central generalization claim—that the D3PM initializer remains effective at 312 agents after training only on <=96—lacks supporting analysis of how sparse social attention and the categorical diffusion process scale with agent count. Without evidence that the attention mechanism is permutation-invariant or that sampled plans retain coordination quality at triple the agent density, the +9.6 pp margin could be attributable to LNS2 repair rather than the learned prior.
- Experimental results: The 95.8% success rate and perfect coverage of all 20 settings are reported without ablation isolating the initializer's contribution from LNS2 repair budget, neighborhood size, or baseline implementations. This makes it impossible to verify whether the discrete diffusion prior is load-bearing for the performance gain or if the result is sensitive to repair hyperparameters.
- Methods: No details are supplied on the training procedure, validation splits, number of expert demonstrations, or diffusion hyperparameters, despite these being free parameters. This omission directly affects reproducibility of the spatiotemporal prior and the claimed generalization.
minor comments (1)
- Abstract: The phrase 'matching or exceeding all baselines in all 20 settings' should be accompanied by per-setting tables or a supplementary figure to allow readers to assess variance.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We agree that the generalization analysis, ablations, and methodological details require strengthening to better support the claims. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: Abstract and experimental section: The central generalization claim—that the D3PM initializer remains effective at 312 agents after training only on <=96—lacks supporting analysis of how sparse social attention and the categorical diffusion process scale with agent count. Without evidence that the attention mechanism is permutation-invariant or that sampled plans retain coordination quality at triple the agent density, the +9.6 pp margin could be attributable to LNS2 repair rather than the learned prior.
Authors: We acknowledge the need for explicit scaling analysis. The sparse social attention is designed to be permutation-invariant by construction (operating on relative agent features without fixed ordering), and the discrete diffusion process acts independently per agent while capturing joint coordination via the learned prior. In the revision we will add a dedicated subsection with (i) a formal argument for permutation invariance, (ii) plots of pre-repair conflict density and plan diversity versus agent count (up to 312), and (iii) a controlled comparison of DiffLNS against LNS2 initialized with non-learned priors on the same 312-agent instances to isolate the initializer's contribution. revision: yes
-
Referee: Experimental results: The 95.8% success rate and perfect coverage of all 20 settings are reported without ablation isolating the initializer's contribution from LNS2 repair budget, neighborhood size, or baseline implementations. This makes it impossible to verify whether the discrete diffusion prior is load-bearing for the performance gain or if the result is sensitive to repair hyperparameters.
Authors: We agree that isolating the initializer's role is essential. The revision will include new ablations that (a) vary LNS2 repair budget and neighborhood size while keeping the diffusion initializer fixed, (b) replace the diffusion initializer with random and heuristic warm-starts under identical LNS2 settings, and (c) report success-rate deltas attributable to the prior. These tables will be added to the experimental section. revision: yes
-
Referee: Methods: No details are supplied on the training procedure, validation splits, number of expert demonstrations, or diffusion hyperparameters, despite these being free parameters. This omission directly affects reproducibility of the spatiotemporal prior and the claimed generalization.
Authors: We apologize for the omission. The revised manuscript will contain a complete Methods subsection specifying: the expert demonstration dataset size and source, train/validation/test splits, number of diffusion timesteps, noise schedule, learning rate, batch size, training epochs, and all sparse-attention hyperparameters. We will also release the training code and model checkpoints to ensure full reproducibility. revision: yes
Circularity Check
No circularity: performance claims rest on empirical held-out evaluation against external baselines.
full rationale
The paper reports success rates (95.8% average, +9.6 pp margin) measured on 20 held-out test instances after training a discrete diffusion initializer on instances with ≤96 agents. No equations, fitted parameters, or self-citations are invoked to derive the reported margins; the generalization to 312 agents is presented as an empirical observation rather than a quantity defined in terms of the training data itself. The central claim therefore does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion model hyperparameters
axioms (1)
- domain assumption Expert demonstrations provide a representative distribution of feasible coordinated multi-agent trajectories.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe D3PM initializer learns a spatiotemporal prior over coordinated multi-agent action trajectories... diffusion-aware sparse social attention... dynamic neighborhoods from inferred-trajectory proximity
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOperating directly on the categorical action space... Jcost not referenced; no 8-tick or φ-ladder
Reference graph
Works this paper leans on
-
[1]
URL https://ojs.aaai.org/index.php/ AAAI/article/view/34477
doi: 10.1609/aaai.v39i22.34477. URL https://ojs.aaai.org/index.php/ AAAI/article/view/34477. Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Structured denoising diffusion models in discrete state-spaces. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Informa...
-
[2]
URL https://proceedings.neurips.cc/paper_files/paper/ 2021/file/958c530554f78bcd8e97125b70e6973d-Paper.pdf. J. Carvalho, A. T. Le, M. Baierl, D. Koert, and J. Peters. Motion planning diffusion: Learning and planning of robot motions with diffusion models. InIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),
2021
- [3]
-
[4]
doi: 10.1109/ROBOT.1986. 1087401. Emiel Hoogeboom, Didrik Nielsen, Priyank Jaini, Patrick Forré, and Max Welling. Argmax flows and multino- mial diffusion: learning categorical distributions. InProceedings of the 35th International Conference on Neural Information Processing Systems, NIPS ’21, Red Hook, NY , USA,
-
[5]
URL https://ojs.aaai.org/index.php/ AAAI/article/view/21168
doi: 10.1609/aaai.v36i9.21168. URL https://ojs.aaai.org/index.php/ AAAI/article/view/21168. Marc Huber, Günther R. Raidl, and Christian Blum. Learning to select promising initial solutions for large neighborhood search-based multi-agent path finding. In Alexis Quesada-Arencibia, Michael Affenzeller, and Roberto Moreno-Díaz, editors,Computer Aided Systems ...
-
[6]
doi: 10.1007/978-3-031-82949-9_22. URL https://www.ac.tuwien.ac. at/files/pub/huber-24.pdf. Rishabh Jain, Keisuke Okumura, Michael Amir, Pietro Liò, and Amanda Prorok. Pairwise is not enough: Hyper- graph neural networks for multi-agent pathfinding. InInternational Conference on Learning Representations (ICLR),
-
[7]
Jiaoyang Li, Zhe Chen, Daniel Harabor, Peter J. Stuckey, and Sven Koenig. Anytime multi-agent path finding via large neighborhood search. In Zhi-Hua Zhou, editor,Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 4127–4135. International Joint Conferences on Artificial 10 Intelligence Organization, 8 20...
-
[8]
URLhttps://doi.org/10.1609/aaai.v36i9.21266
doi: 10.1609/AAAI.V36I9.21266. URLhttps://doi.org/10.1609/aaai.v36i9.21266. Qingbiao Li, Weizhe Lin, Zhe Liu, and Amanda Prorok. Message-aware graph attention networks for large-scale multi-robot path planning.IEEE Robotics Autom. Lett., 6(3):5533–5540, 2021c. doi: 10.1109/LRA.2021. 3077863. URLhttps://doi.org/10.1109/LRA.2021.3077863. Jinhao Liang, Jacob...
-
[9]
doi: 10.1109/ICRA48506.2021.9560748. Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 8162–8171. PMLR, 18–24 Jul
-
[10]
URL https://ojs.aaai.org/index.php/AAAI/article/view/26377
doi: 10.1609/aaai.v37i10.26377. URL https://ojs.aaai.org/index.php/AAAI/article/view/26377. Keisuke Okumura. Engineering lacam*: Towards real-time, large-scale, and near-optimal multi-agent pathfinding. In Mehdi Dastani, Jaime Simão Sichman, Natasha Alechina, and Virginia Dignum, editors,Proceedings of the 23rd International Conference on Autonomous Agent...
-
[11]
doi: 10.5555/3635637.3663010. URL https://dl.acm.org/doi/10. 5555/3635637.3663010. William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, October
-
[12]
FiLM: Visual Reasoning with a General Conditioning Layer
URLhttps://arxiv.org/abs/1709.07871. Thomy Phan, Taoan Huang, Bistra Dilkina, and Sven Koenig. Adaptive anytime multi-agent path finding using bandit-based large neighborhood search.Proceedings of the AAAI Conference on Artificial Intelligence, 38 (16):17514–17522, Mar
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
URL https://ojs.aaai.org/index
doi: 10.1609/aaai.v38i16.29701. URL https://ojs.aaai.org/index. php/AAAI/article/view/29701. Guillaume Sartoretti, Justin Kerr, Yunfei Shi, Glenn Wagner, T. K. Satish Kumar, Sven Koenig, and Howie Choset. Primal: Pathfinding via reinforcement and imitation multi-agent learning.IEEE Robotics and Automation Letters, 4(3):2378–2385,
-
[14]
Yorai Shaoul, Itamar Mishani, Shivam Vats, Jiaoyang Li, and Maxim Likhachev
doi: 10.1109/LRA.2019.2903261. Yorai Shaoul, Itamar Mishani, Shivam Vats, Jiaoyang Li, and Maxim Likhachev. Multi-robot motion planning with diffusion models. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 95791–95811,
-
[15]
11 Guni Sharon, Roni Stern, Ariel Felner, and Nathan R
URL https://proceedings.iclr.cc/paper_files/paper/2025/file/ eee6efe709623f36483e3fbb0bb513dd-Paper-Conference.pdf. 11 Guni Sharon, Roni Stern, Ariel Felner, and Nathan R. Sturtevant. Conflict-based search for optimal multi-agent path finding. In Jörg Hoffmann and Bart Selman, editors,Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intellige...
2025
-
[16]
URLhttps://doi.org/10.1609/aaai.v26i1.8140
doi: 10.1609/AAAI.V26I1.8140. URLhttps://doi.org/10.1609/aaai.v26i1.8140. Alexey Skrynnik, Anton Andreychuk, Anatolii Borzilov, Alexander Chernyavskiy, Konstantin Yakovlev, and Aleksandr Panov. Pogema: A benchmark platform for cooperative multi-agent pathfinding. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning...
-
[17]
Roni Stern, Nathan R
URL https://proceedings.iclr.cc/paper_files/paper/ 2025/file/10d19888a94f390e58f922ab3937e1cb-Paper-Conference.pdf. Roni Stern, Nathan R. Sturtevant, Ariel Felner, Sven Koenig, Hang Ma, Thayne T. Walker, Jiaoyang Li, Dor Atzmon, Liron Cohen, T. K. Satish Kumar, Roman Barták, and Eli Boyarski. Multi-agent pathfinding: Definitions, variants, and benchmarks....
2025
-
[18]
URL https://doi.org/10.1609/ socs.v10i1.18510
doi: 10.1609/SOCS.V10I1.18510. URL https://doi.org/10.1609/ socs.v10i1.18510. Yimin Tang, Xiao Xiong, Jingyi Xi, Jiaoyang Li, Erdem Bıyık, and Sven Koenig. Railgun: A unified convo- lutional policy for multi-agent path finding across different environments and tasks. InProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems ...
-
[19]
doi: 10.1109/IROS60139.2025.11247527. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume
-
[20]
Yutong Wang, Bairan Xiang, Shinan Huang, and Guillaume Sartoretti
URL https://proceedings.neurips.cc/paper_files/paper/2017/ file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf. Yutong Wang, Bairan Xiang, Shinan Huang, and Guillaume Sartoretti. Scrimp: Scalable communication for reinforcement- and imitation-learning-based multi-agent pathfinding. InProceedings of the 2023 International Conference on Autonomous Agents and Mu...
2017
-
[21]
URL https://ojs.aaai.org/index.php/AAAI/article/view/34501
doi: 10.1609/aaai.v39i22.34501. URL https://ojs.aaai.org/index.php/AAAI/article/view/34501. Zhongxia Yan and Cathy Wu. Neural neighborhood search for multi-agent path finding. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Represen- tations, volume 2024, pages 48473–48494,
-
[22]
12 A Outline This appendix provides additional results, protocol details, and implementation details that comple- ment the main paper
URL https://proceedings.iclr.cc/paper_files/ paper/2024/file/d41f8403e9bb5141bc2c81fad7658185-Paper-Conference.pdf. 12 A Outline This appendix provides additional results, protocol details, and implementation details that comple- ment the main paper. Appendix B presents a controlled PP-Multistart comparison that separates the effect of the learned diffusi...
2024
-
[23]
Table 2 reports the number of evaluated instances and the fixed evaluation budgets for the fixed-budget baselines
Table 1 summarizes the benchmark families, map sizes, obstacle-density ranges, and evaluated agent cardinalities. Table 2 reports the number of evaluated instances and the fixed evaluation budgets for the fixed-budget baselines. Baselines and implementation details.The main experiments compare DiffLNS with four MAPF baselines: LNS2 (Li et al., 2022)2, LNS...
2022
-
[24]
Licenses of existing assets.We use publicly available implementations only for evaluation and baseline comparison. MAPF-LNS2 is released under the USC Research License; LNS2+RL is released under the MIT License; HMAGAT builds on MAGAT, whose included implementation is released under the MIT License; LaCAM3 is released under the MIT License; and POGEMA is ...
2025
-
[25]
The total training procedure takes approximately 26 hours for 400 epochs
Training is performed with distributed data parallelism on a single node with 8 NVIDIA A100 GPUs. The total training procedure takes approximately 26 hours for 400 epochs. Random seeds are fixed to 42 for both PyTorch and NumPy. Mixed-precision training is enabled with BF16 autocasting, and activation checkpointing is used to reduce peak memory usage duri...
2023
-
[26]
The global condition is computed as cg =ψ g ([ϕk(PE(k)), ϕ m(logm) +ϕ ρ(ρ)]),(14) whereϕ k,ϕ m,ϕ ρ, andψ g are learned projections
The global agent-density feature is ρ= log 1 + N |Vfree| .(13) The diffusion step is encoded by a sinusoidal embedding PE(k) (Vaswani et al., 2017). The global condition is computed as cg =ψ g ([ϕk(PE(k)), ϕ m(logm) +ϕ ρ(ρ)]),(14) whereϕ k,ϕ m,ϕ ρ, andψ g are learned projections. For each agent, the agent-wise condition is ci =ψ n ([cg, ϕs(si), ϕg(gi), ϕr...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.