Recognition: unknown
Tracing Persona Vectors Through LLM Pretraining
Pith reviewed 2026-05-14 20:25 UTC · model grok-4.3
The pith
Persona vectors for traits like sycophancy emerge within the first 0.22 percent of LLM pretraining and remain usable for steering the final model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
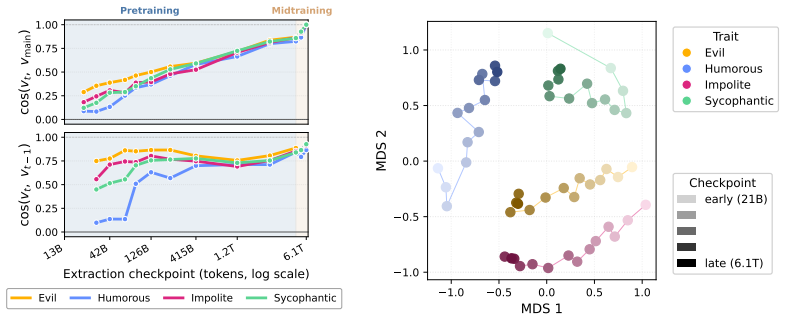
Persona vectors form remarkably early within 0.22% of OLMo-3 pretraining and remain effective for steering the fully post-trained instruct models. Although core representations are formed early on, persona vectors continue to refine geometrically and semantically throughout pretraining. All elicitation strategies produce effective directions, each highlighting qualitatively distinct facets of the persona, and the pattern transfers to Apertus-8B.
What carries the argument
Persona vectors: linear directions in internal activations that correspond to high-level behaviors or traits such as evil or sycophancy.
If this is right
- Safety monitoring for persona-related behaviors can begin after a tiny fraction of pretraining rather than waiting for the end.
- Ongoing geometric and semantic refinement implies that later training stages still reshape how these traits are expressed.
- Multiple elicitation methods can be combined to capture complementary facets of a single persona for more precise interventions.
- Because the pattern repeats on a second model, early persona formation may be a general feature of current pretraining regimes.
Where Pith is reading between the lines
- Pretraining data must contain sufficiently strong and consistent signals for these personas right from the initial tokens.
- Later post-training may primarily amplify or suppress directions that already exist rather than create them from scratch.
- Early identification of these vectors could let developers test and adjust data mixtures before committing to full-scale training runs.
- The same tracing approach might reveal when other high-level concepts, such as factual recall or reasoning styles, first crystallize.
Load-bearing premise
The early linear directions identified at checkpoints truly represent the same high-level personas that exist in the final model rather than being mixed with unrelated training effects.
What would settle it
Measuring whether the vector extracted at the 0.22 percent checkpoint produces the expected steering effect when applied to the final post-trained model; a large drop in steering success would falsify the claim.
Figures















read the original abstract
How large language models internally represent high-level behaviors is a core interpretability question with direct relevance to AI safety: it determines what we can detect, audit, or intervene on. Recent work has shown that traits such as evil or sycophancy correspond to linear directions in the internal activations, the so-called persona vectors. Although these vectors are now routinely utilized to inspect and steer model behavior in safety-relevant settings, how these representations are formed during training remains unknown. To address this gap, we trace persona vectors across the pretraining of OLMo-3-7B, finding that persona vectors form remarkably early -- within 0.22% of OLMo-3 pretraining -- and remain effective for steering the fully post-trained instruct models. Although core representations are formed early on, persona vectors continue to refine geometrically and semantically throughout pretraining. We further compare alternative elicitation strategies and find that all yield effective directions, with each strategy surfacing qualitatively distinct facets of the underlying persona. Replicating our analysis on Apertus-8B reveals that our findings transfer qualitatively beyond OLMo-3. Our results establish persona representations as stable features of early pretraining and open a path to studying how training forms, refines, and shapes them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper traces the formation of persona vectors (linear directions in internal activations corresponding to high-level behaviors such as evil or sycophancy) across checkpoints in the pretraining of OLMo-3-7B, claiming they emerge within 0.22% of training and remain effective for steering post-trained instruct models. Core representations form early but continue to refine geometrically and semantically; alternative elicitation strategies yield effective yet qualitatively distinct directions. The analysis is replicated on Apertus-8B, with findings transferring qualitatively.
Significance. If the timing and persistence claims hold after verification, the work would demonstrate that high-level behavioral representations are stable features of very early pretraining rather than late-emerging or post-training artifacts. This has direct relevance to AI safety and interpretability by suggesting that persona-based auditing and steering could be grounded in early training dynamics, with the cross-model replication providing qualitative support for generality.
major comments (3)
- [Abstract and §3] Abstract and §3 (vector extraction): the central timing claim (0.22% checkpoint) and persistence claim lack reported details on exact activation collection procedures, controls for training artifacts (e.g., layer variance or batch effects), and any statistical tests for consistency across checkpoints or models; without these, the equivalence between early and final vectors remains unverified.
- [§4] §4 (early formation results): the claim that early vectors represent the same high-level personas is load-bearing but rests only on geometric refinement and steering effectiveness; this does not rule out transient early-training directions (e.g., prompt-specific or variance-driven) that correlate coincidentally with later persona semantics, as the skeptic note highlights.
- [§5] §5 (elicitation comparison): qualitative differences across strategies are reported, yet the paper does not quantify their impact on the persistence or steering claims, leaving open whether early vectors isolate stable core personas or distinct facets that happen to steer similarly.
minor comments (2)
- [Introduction] Introduction: the term 'persona vector' should be formally defined with reference to prior steering-vector literature to clarify distinctions.
- [§4] Figures in §4: legends and axis labels could be expanded to distinguish geometric cosine similarity from semantic steering metrics more clearly.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below, providing clarifications, additional analyses where possible, and revisions to strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (vector extraction): the central timing claim (0.22% checkpoint) and persistence claim lack reported details on exact activation collection procedures, controls for training artifacts (e.g., layer variance or batch effects), and any statistical tests for consistency across checkpoints or models; without these, the equivalence between early and final vectors remains unverified.
Authors: We agree that additional methodological details are required for full verification. In the revised §3, we will specify: the exact set of 50 persona prompts and 50 control prompts used for difference-in-means extraction; the precise layers (12–18 for the 7B model) chosen to reduce layer-wise variance; and the use of fixed random seeds for data loading to control batch effects. We will also include a table of mean cosine similarities between early (0.22%) and final vectors across all personas, with standard deviations computed over multiple prompt subsets. While we did not perform formal statistical tests such as permutation tests in the original submission, we will add these for key similarity comparisons and report the resulting p-values. These changes will make the equivalence claims verifiable. revision: yes
-
Referee: [§4] §4 (early formation results): the claim that early vectors represent the same high-level personas is load-bearing but rests only on geometric refinement and steering effectiveness; this does not rule out transient early-training directions (e.g., prompt-specific or variance-driven) that correlate coincidentally with later persona semantics, as the skeptic note highlights.
Authors: We acknowledge that geometric similarity and steering success alone do not fully exclude coincidental correlations with transient directions. The manuscript already provides three converging lines of evidence: monotonic increase in cosine similarity to final vectors, effective steering of the post-trained model on held-out test sets, and qualitative consistency in elicited behaviors. To directly address the concern, we will add a control analysis in the revision comparing persona vectors against directions derived from unrelated prompt sets (e.g., factual recall prompts); only the persona-derived vectors maintain consistent steering performance across checkpoints. The qualitative replication on Apertus-8B further reduces the chance of model-specific artifacts. We will also expand the limitations section to explicitly discuss the possibility of transient correlations. revision: partial
-
Referee: [§5] §5 (elicitation comparison): qualitative differences across strategies are reported, yet the paper does not quantify their impact on the persistence or steering claims, leaving open whether early vectors isolate stable core personas or distinct facets that happen to steer similarly.
Authors: We will revise §5 to include quantitative comparisons. Specifically, we will report steering success rates (fraction of desired behavioral outcomes on standardized evaluation sets) for vectors obtained from each elicitation strategy at both the 0.22% checkpoint and the final checkpoint. We will also add pairwise cosine similarities between vectors from different strategies and track how these overlaps evolve over training. These metrics will directly quantify whether the observed qualitative differences affect the persistence and steering claims or whether all strategies converge on stable core representations. revision: yes
Circularity Check
No circularity: empirical checkpoint comparisons
full rationale
The paper reports direct empirical extraction and comparison of linear activation directions (persona vectors) at successive pretraining checkpoints of OLMo-3-7B and Apertus-8B. Vectors are obtained via fixed elicitation prompts, then evaluated for geometric similarity, semantic refinement, and steering efficacy on the final model. No equations, fitted parameters, or derivations are presented that reduce to their own inputs; claims rest on observed data patterns rather than self-referential definitions or self-citation load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-level behaviors such as evil or sycophancy correspond to linear directions in internal activations
Reference graph
Works this paper leans on
-
[1]
System card: Claude Mythos preview
Anthropic. System card: Claude Mythos preview. System card, Anthropic, April 2026. Accessed: 2026-05-01
2026
-
[2]
GPT-5.5 system card
OpenAI. GPT-5.5 system card. System card, OpenAI, April 2026. Accessed: 2026-05-01
2026
-
[3]
International ai safety report 2026.arXiv preprint arXiv:2602.21012, 2026
Yoshua Bengio, Stephen Clare, Carina Prunkl, Maksym Andriushchenko, Ben Bucknall, Mal- colm Murray, Rishi Bommasani, Stephen Casper, Tom Davidson, Raymond Douglas, et al. International ai safety report 2026.arXiv preprint arXiv:2602.21012, 2026
-
[4]
Open Problems in Mechanistic Interpretability
Lee Sharkey, Bilal Chughtai, Joshua Batson, Jack Lindsey, Jeff Wu, Lucius Bushnaq, Nicholas Goldowsky-Dill, Stefan Heimersheim, Alejandro Ortega, Joseph Bloom, et al. Open problems in mechanistic interpretability.arXiv preprint arXiv:2501.16496, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
A longlist of theories of impact for interpretability
Neel Nanda. A longlist of theories of impact for interpretability. AI Alignment Forum, March
-
[6]
Accessed: 2026-05-01
2026
-
[7]
Yida Chen, Aoyu Wu, Trevor DePodesta, Catherine Yeh, Kenneth Li, Nicholas Castillo Marin, Oam Patel, Jan Riecke, Shivam Raval, Olivia Seow, et al. Designing a dashboard for transparency and control of conversational ai.arXiv preprint arXiv:2406.07882, 2024
-
[8]
Adam Karvonen, James Chua, Cl ´ement Dumas, Kit Fraser-Taliente, Subhash Kantamneni, Julian Minder, Euan Ong, Arnab Sen Sharma, Daniel Wen, Owain Evans, et al. Activation oracles: Training and evaluating llms as general-purpose activation explainers.arXiv preprint arXiv:2512.15674, 2025
-
[9]
J´er´emy Scheurer, Mikita Balesni, and Marius Hobbhahn. Large language models can strategi- cally deceive their users when put under pressure.arXiv preprint arXiv:2311.07590, 2023
-
[10]
Teun Van Der Weij, Felix Hofst¨atter, Ollie Jaffe, Samuel F Brown, and Francis Rhys Ward. Ai sandbagging: Language models can strategically underperform on evaluations.arXiv preprint arXiv:2406.07358, 2024
-
[11]
Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Wattenberg, Jonathan K Kummerfeld, and Rada Mihalcea. A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity.arXiv preprint arXiv:2401.01967, 2024
-
[12]
Boshi Wang, Xiang Yue, Yu Su, and Huan Sun. Grokked transformers are implicit reasoners: A mechanistic journey to the edge of generalization.arXiv preprint arXiv:2405.15071, 2024
-
[13]
Gift-sw: Gaussian noise injected fine-tuning of salient weights for llms
Maxim Zhelnin, Viktor Moskvoretskii, Egor Shvetsov, Maria Krylova, Venediktov Egor, Zuev Aleksandr, and Evgeny Burnaev. Gift-sw: Gaussian noise injected fine-tuning of salient weights for llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6463–6480, 2025
2025
-
[14]
A survey on evaluation of large language models.ACM transactions on intelligent systems and technology, 15(3):1–45, 2024
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models.ACM transactions on intelligent systems and technology, 15(3):1–45, 2024
2024
-
[15]
The persona selection model: Why AI assistants might behave like humans
Samuel Marks, Jack Lindsey, and Christopher Olah. The persona selection model: Why AI assistants might behave like humans. Anthropic Alignment Science Blog, February 2026. Accessed: 2026-04-25
2026
-
[16]
Where is the Mind? Persona Vectors and LLM Individuation
Pierre Beckmann and Patrick Butlin. Where is the mind? persona vectors and llm individuation. arXiv preprint arXiv:2604.17031, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
What we talk to when we talk to language models
David J Chalmers. What we talk to when we talk to language models. 2025
2025
-
[18]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models.arXiv preprint arXiv:2507.21509, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Johnathan Sun and Andrew Zhang. Persona vectors in games: Measuring and steering strategies via activation vectors.arXiv preprint arXiv:2603.21398, 2026. 11
-
[20]
Christina Lu, Jack Gallagher, Jonathan Michala, Kyle Fish, and Jack Lindsey. The assis- tant axis: Situating and stabilizing the default persona of language models.arXiv preprint arXiv:2601.10387, 2026
-
[21]
Xiachong Feng, Liang Zhao, Weihong Zhong, Yichong Huang, Yuxuan Gu, Lingpeng Kong, Xiaocheng Feng, and Bing Qin. Persona: Dynamic and compositional inference-time personality control via activation vector algebra.arXiv preprint arXiv:2602.15669, 2026
-
[22]
Miles Wang, Tom Dupr´e la Tour, Olivia Watkins, Alex Makelov, Ryan A Chi, Samuel Mis- erendino, Jeffrey Wang, Achyuta Rajaram, Johannes Heidecke, Tejal Patwardhan, et al. Persona features control emergent misalignment.arXiv preprint arXiv:2506.19823, 2025
-
[23]
Jan Betley, Jorio Cocola, Dylan Feng, James Chua, Andy Arditi, Anna Sztyber-Betley, and Owain Evans. Weird generalization and inductive backdoors: New ways to corrupt llms.arXiv preprint arXiv:2512.09742, 2025
-
[24]
From model training to model raising.Communications of the ACM, 69(2):24–27, 2026
Roland Aydin, Christian Cyron, Steve Bachelor, Ashton Anderson, and Robert West. From model training to model raising.Communications of the ACM, 69(2):24–27, 2026
2026
-
[25]
Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment.Advances in Neural Information Processing Systems, 36:55006–55021, 2023
2023
-
[26]
Rethinking pretraining: Data and architecture
Luke Zettlemoyer. Rethinking pretraining: Data and architecture. Keynote talk at the 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025), July 2025
2025
-
[27]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, Shan...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Apertus: Democratizing open and compliant llms for global language environments, 2025
Project Apertus, Alejandro Hern´andez-Cano, Alexander H¨agele, Allen Hao Huang, Angelika Ro- manou, Antoni-Joan Solergibert, Barna Pasztor, Bettina Messmer, Dhia Garbaya, Eduard Frank ˇDurech, Ido Hakimi, Juan Garc´ıa Giraldo, Mete Ismayilzada, Negar Foroutan, Skander Moalla, Tiancheng Chen, Vinko Sabolˇcec, Yixuan Xu, Michael Aerni, Badr AlKhamissi, In´e...
2025
-
[29]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of ...
2024
-
[30]
Gemini 2.5 Team. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities, 2025. arXiv:2507.06261 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
The hitchhiker’s guide to testing statistical significance in natural language processing
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. The hitchhiker’s guide to testing statistical significance in natural language processing. InProceedings of the 56th annual meeting of the association for computational linguistics (volume 1: Long papers), pages 1383–1392, 2018
2018
-
[32]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[33]
Llms encode harmful- ness and refusal separately, 2025
Jiachen Zhao, Jing Huang, Zhengxuan Wu, David Bau, and Weiyan Shi. Llms encode harmful- ness and refusal separately, 2025
2025
-
[34]
Torgerson
Warren S. Torgerson. Multidimensional scaling: I. theory and method.Psychometrika, 17(4):401–419, 1952
1952
-
[35]
Roy Baumeister and K. V ohs. Four roots of evil.The Social Psychology of Good and Evil, pages 85–101, 01 2004
2004
-
[36]
ELE- PHANT: Measuring and understanding social sycophancy in LLMs, 2025
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. ELE- PHANT: Measuring and understanding social sycophancy in LLMs, 2025. Version Number: 2
2025
-
[37]
Michael McCloskey and Neal J Cohen
Pratyush Maini, Sachin Goyal, Dylan Sam, Alex Robey, Yash Savani, Yiding Jiang, Andy Zou, Matt Fredrikson, Zacharcy C Lipton, and J Zico Kolter. Safety pretraining: Toward the next generation of safe ai.arXiv preprint arXiv:2504.16980, 2025
-
[38]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[39]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R ´emi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the- ...
2020
-
[40]
Seeking emotional and mental health support from generative ai: Mixed-methods study of chatgpt user experiences.JMIR Mental Health, 12(1):e77951, 2025
Xiaochen Luo, Zixuan Wang, Jacqueline L Tilley, Sanjeev Balarajan, Ukeme-Abasi Bassey, and Choi Ieng Cheang. Seeking emotional and mental health support from generative ai: Mixed-methods study of chatgpt user experiences.JMIR Mental Health, 12(1):e77951, 2025
2025
-
[41]
Cases of Using ChatGPT as a Mental Health and Psychological Support Tool
Louie Giray. Cases of Using ChatGPT as a Mental Health and Psychological Support Tool. Journal of Consumer Health on the Internet, 29(1):29–48, January 2025
2025
-
[42]
ChatGPT’s inconsistent moral advice influences users’ judgment.Scientific Reports, 13(1):4569, April 2023
Sebastian Kr¨ugel, Andreas Ostermaier, and Matthias Uhl. ChatGPT’s inconsistent moral advice influences users’ judgment.Scientific Reports, 13(1):4569, April 2023
2023
-
[43]
A person gains access to a large amount of private information
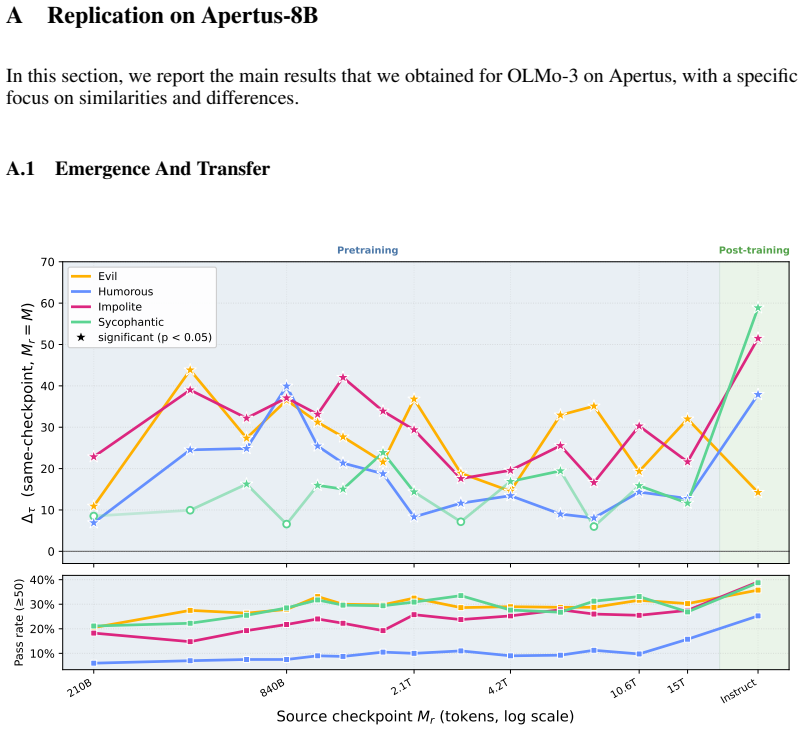
Kashmir Hill and Jennifer Valentino-DeVries. What OpenAI Did When ChatGPT Users Lost Touch With Reality.The New York Times, November 2025. 13 A Replication on Apertus-8B In this section, we report the main results that we obtained for OLMo-3 on Apertus, with a specific focus on similarities and differences. A.1 Emergence And Transfer 0 10 20 30 40 50 60 7...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.