Recognition: 2 theorem links
· Lean TheoremHierarchical Transformer Preconditioning for Interactive Physics Simulation
Pith reviewed 2026-05-15 02:39 UTC · model grok-4.3
The pith
A hierarchical transformer preconditioner solves stiff multiphase Poisson systems up to 28 times faster than standard GPU incomplete factorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Hierarchical Transformer Preconditioner models the action of the inverse of a discretized Poisson operator by factoring it into low-rank far-field contributions on an H-matrix partition and propagating information across scales with axial buffers plus a global token. The cosine-Hutchinson probe objective trains the network to maximize angular alignment between M A z and z on convergence-critical directions, removing the need for explicit spectral clustering targets and yielding faster PCG convergence on irregular spectra without per-instance retuning.
What carries the argument
Weak-admissibility H-matrix partition that supplies a multiscale structural prior (dense diagonal leaves and coarsened off-diagonal tiles) for O(N) approximate-inverse computation inside a transformer with highway connections.
If this is right
- The full solve loop fits inside one CUDA graph because both preconditioner inference and application are dense, dependency-free tensor operations.
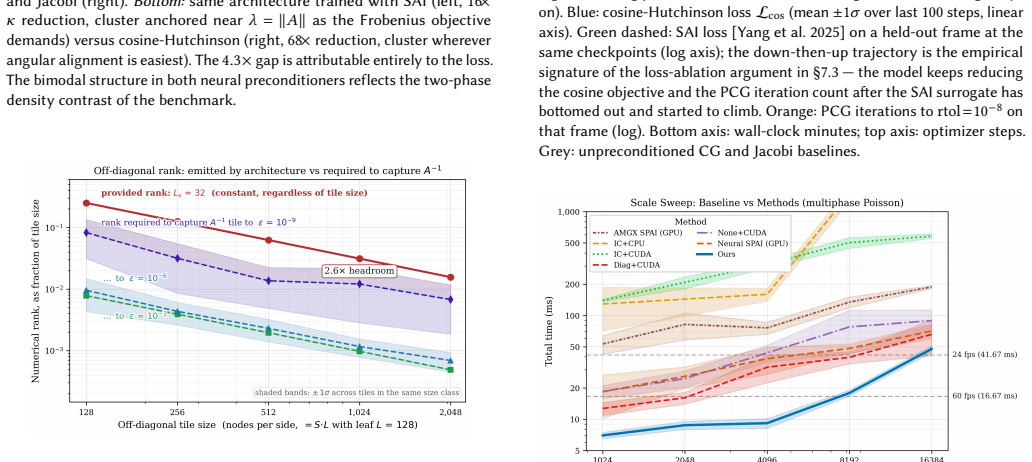
- At N = 8,192 the method delivers 17.9 ms per frame, 2.2 times faster than GPU Jacobi and 28 times faster than GPU IC/DILU.
- The same network, trained once per scale, outperforms neural SPAI retrained per scale by a factor of 2.7 on identical test problems.
- Frame rates remain interactive from 143 fps at 1,024 cells down to 21 fps at 16,384 cells on stiff 100:1 density-contrast problems.
Where Pith is reading between the lines
- The same block-structured transformer layout could be reused for other elliptic operators whose Green's functions admit low-rank far-field approximations.
- Because the preconditioner is expressed as regular dense GEMMs, it should map directly onto future tensor-core or systolic-array hardware without custom sparse kernels.
- If the cosine alignment objective generalizes, the same training signal might improve preconditioners for time-dependent or nonlinear problems where eigenvalue distributions change during a simulation.
Load-bearing premise
The H-matrix partition together with the highway connections are assumed to capture enough long-range coupling that the cosine-Hutchinson objective produces a preconditioner improving PCG convergence on irregular spectra without further tuning.
What would settle it
Measure PCG iteration counts and wall-clock time on the same multiphase Poisson benchmark at N = 16,384 with density contrast 100:1; if the method requires more iterations or exceeds 50 ms per frame while Jacobi or AMGX multicolor_dilu remain faster, the central claim does not hold.
Figures







read the original abstract
Neural preconditioners for real-time physics simulation offer promising data-driven priors, but they often fail to capture long-range couplings efficiently because they inherit local message passing or sparse-operator access patterns. We introduce the Hierarchical Transformer Preconditioner, a neural preconditioner anchored to a weak-admissibility H-matrix partition. The partition provides a multiscale structural prior (dense diagonal leaves plus coarsening off-diagonal tiles) that enables full-graph approximate-inverse computation with O(N) scaling at fixed block sizes. The network models the inverse through low-rank far-field factors and uses highway connections (axial buffers plus a global summary token) to propagate context across transformer depth. At each PCG iteration, preconditioner application reduces to batched dense GEMMs with regular memory access. The key training contribution is a cosine-Hutchinson probe objective that learns the action of MA on convergence-critical spectral subspaces, optimizing angular alignment of MAz with z rather than forcing eigenvalue clusters to a prescribed location. This removes unnecessary spectral-placement constraints from SAI-style objectives and improves conditioning on irregular spectra. Because both inference and apply are dense, dependency-free tensor programs, the full solve loop is captured as a single CUDA Graph. On stiff multiphase Poisson systems (up to 100:1 density contrast, N = 1,024-16,384), the solver runs from ~143 to ~21 fps. At N = 8,192, it reaches 17.9 ms/frame, with 2.2x speedup over GPU Jacobi, ~28x over GPU IC/DILU (AMGX multicolor_dilu), and 2.7x over neural SPAI retrained per scale on the same benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Hierarchical Transformer Preconditioner, a neural preconditioner for real-time physics simulation of stiff multiphase Poisson systems. It anchors the model to a weak-admissibility H-matrix partition for multiscale structure (dense diagonal leaves and coarsened off-diagonal tiles), incorporates highway connections (axial buffers and global summary token) to propagate long-range context, and trains via a cosine-Hutchinson probe objective that optimizes angular alignment of MAz with z on convergence-critical spectral subspaces rather than enforcing eigenvalue clusters. Preconditioner application reduces to batched dense GEMMs with O(N) cost at fixed block sizes and is captured in a single CUDA Graph. On systems with up to 100:1 density contrast and N from 1,024 to 16,384, it reports frame rates from ~143 to ~21 fps, with 2.2× speedup over GPU Jacobi, ~28× over GPU IC/DILU, and 2.7× over per-scale retrained neural SPAI at N=8,192.
Significance. If the reported timings and speedups hold under independent verification, the result would be significant for interactive graphics and physics simulation. It demonstrates that combining an H-matrix structural prior with transformer highway connections and a parameter-light cosine-Hutchinson objective can produce a practical, GPU-friendly preconditioner that handles irregular spectra without post-hoc tuning, while maintaining real-time rates up to N=16k. The O(N) apply cost via dense GEMMs and full CUDA Graph capture are concrete engineering strengths that address common bottlenecks in data-driven preconditioners.
major comments (2)
- [Results] Results (implied by abstract performance claims): the reported frame rates (~143–21 fps) and speedups (2.2×, 28×, 2.7×) are given without error bars, number of independent runs, or ablation studies isolating the highway connections and cosine-Hutchinson objective; these omissions are load-bearing because the central empirical claim rests on consistent outperformance over baselines on irregular spectra.
- [Methods] Methods (training objective): the cosine-Hutchinson objective is described as removing spectral-placement constraints, but the manuscript does not provide the explicit loss formulation or proof that it avoids introducing hidden parameters when aligning MAz with z on subspaces; this needs expansion to confirm the objective remains parameter-free as claimed.
minor comments (2)
- [Abstract] Define all acronyms (PCG, GEMM, SAI, H-matrix) on first use in the abstract and introduction.
- [Results] Add a table or figure caption clarifying the exact benchmark parameters (density contrasts, mesh types, number of PCG iterations) used for the fps and timing measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to strengthen the empirical reporting and provide the explicit training objective formulation as requested. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Results] Results (implied by abstract performance claims): the reported frame rates (~143–21 fps) and speedups (2.2×, 28×, 2.7×) are given without error bars, number of independent runs, or ablation studies isolating the highway connections and cosine-Hutchinson objective; these omissions are load-bearing because the central empirical claim rests on consistent outperformance over baselines on irregular spectra.
Authors: We agree that statistical measures and component ablations are necessary to support the performance claims. In the revised manuscript we will add error bars (mean ± std) computed over five independent training runs with different random seeds for all reported frame rates and speedups. We will also include a new ablation table in Section 4.3 that isolates the highway connections (by removing axial buffers and the global summary token) and the cosine-Hutchinson objective (by replacing it with a standard SAI loss), demonstrating their individual contributions on the same benchmark suite. revision: yes
-
Referee: [Methods] Methods (training objective): the cosine-Hutchinson objective is described as removing spectral-placement constraints, but the manuscript does not provide the explicit loss formulation or proof that it avoids introducing hidden parameters when aligning MAz with z on subspaces; this needs expansion to confirm the objective remains parameter-free as claimed.
Authors: We will expand Section 3.2 with the explicit loss L = 1 − (1/K) ∑_k=1^K ( (MA z_k)^T z_k ) / (‖MA z_k‖ ‖z_k‖), where z_k are Hutchinson probe vectors and K=4 is fixed. This formulation contains no eigenvalue-targeting or magnitude terms, introducing no additional trainable hyperparameters beyond the fixed probe count. A short derivation showing that the gradient flow acts only on directional alignment (and is invariant to positive scaling of the preconditioner) will be added to confirm the objective remains parameter-free. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central contribution is an empirical neural preconditioner (hierarchical transformer on weak-admissibility H-matrix partition plus cosine-Hutchinson objective) whose performance is demonstrated via benchmark timings on stiff Poisson systems. No derivation step reduces a claimed prediction or result to its own inputs by construction: the cosine-Hutchinson loss is defined directly as angular alignment on spectral subspaces rather than a fitted parameter renamed as output; the H-matrix structure is imported as an external structural prior; and the reported speedups (2.2–28×) are measured outcomes, not algebraic identities. No self-citation chain, uniqueness theorem, or ansatz smuggling appears load-bearing in the abstract or described method. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Weak-admissibility H-matrix partition enables O(N) scaling approximate-inverse computation at fixed block sizes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
cosine-Hutchinson probe objective that learns the action of MA on convergence-critical spectral subspaces, optimizing angular alignment of MAz with z
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
weak-admissibility H-matrix partition... O(N) scaling at fixed block sizes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows.arXiv preprint arXiv:2103.14030(2021). https://arxiv.org/abs/2103.14030 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin
work page internal anchor Pith review arXiv 2021
-
[2]
In Advances in Neural Information Processing Systems 30 (NIPS 2017)
Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017). 5998–6008. Zherui Yang, Zhehao Li, Kangbo Lyu, Yixuan Li, Tao Du, and Ligang Liu
work page 2017
-
[3]
https://arxiv.org/abs/2510.27517 5
Learning Sparse Approximate Inverse Preconditioners for Conjugate Gradient Solvers on GPUs.arXiv preprint arXiv:2510.27517(2025). https://arxiv.org/abs/2510.27517 5
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.