Recognition: 1 theorem link
· Lean TheoremAI Harness Engineering: A Runtime Substrate for Foundation-Model Software Agents
Pith reviewed 2026-05-14 18:10 UTC · model grok-4.3
The pith
Software-engineering capability for foundation-model agents emerges from a model-harness-environment system rather than from the model alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
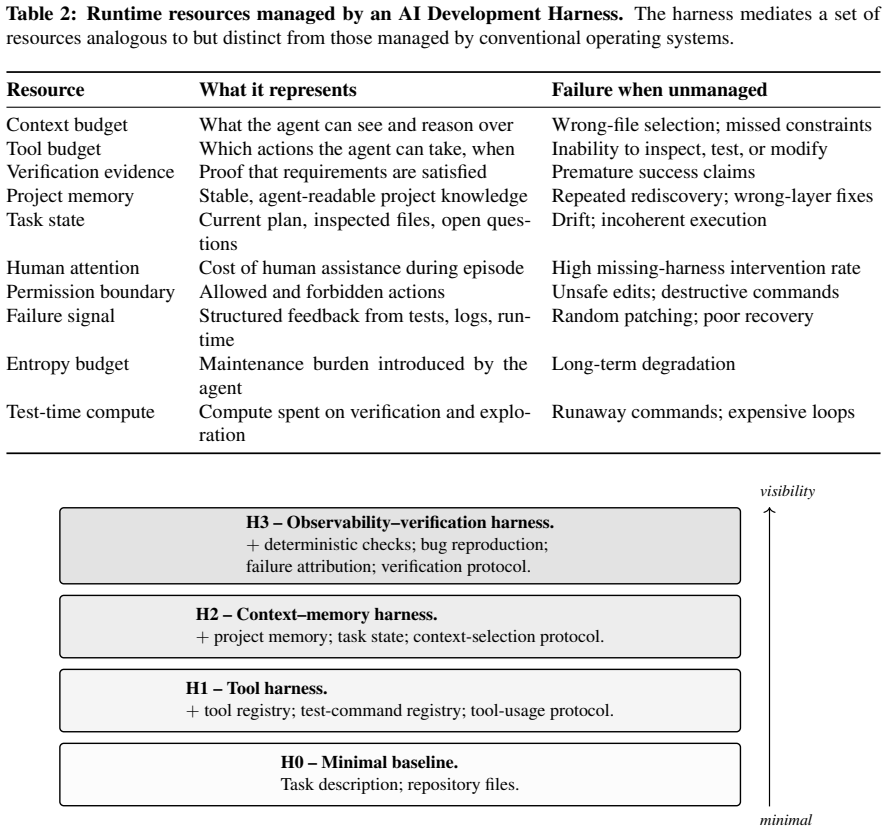
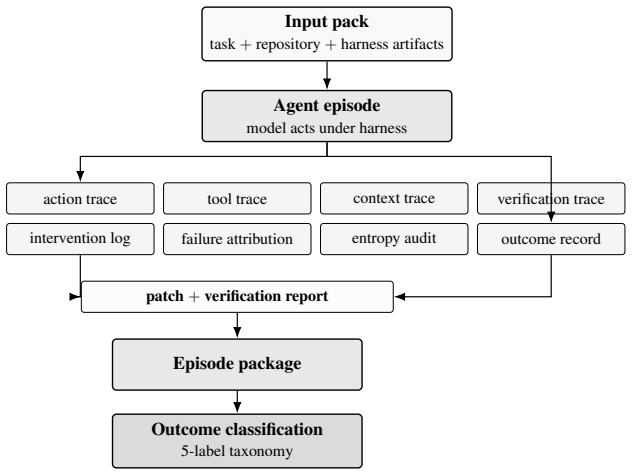
Software-engineering capability emerges from a model-harness-environment system, in which a runtime substrate -- the harness -- mediates how a foundation-model agent observes a project, acts on it, receives feedback, and establishes that a change is complete. The harness is defined by eleven component responsibilities and operationalized through a four-level ladder (H0-H3) that progressively exposes runtime support, together with a trace-based evaluation protocol that converts each agent run into an auditable episode package whose evidence structure scales with harness level.
What carries the argument
The AI Harness: a runtime substrate whose eleven responsibilities (task specification, context selection, tool access, project memory, task state, observability, failure attribution, verification, permissions, entropy auditing, and intervention recording) and four-level ladder (H0-H3) control what the agent can see and prove about its actions.
If this is right
- Lower harness levels yield only final patches while higher levels produce reproduction logs, failure attributions, requirement checks, and structured verification reports.
- The central question of autonomous software engineering shifts from model patch generation to whether the full system can produce a verifiably correct, attributed, and maintainable change.
- Trace-based evaluation turns every agent run into an auditable episode package whose structure varies systematically with harness level.
- A research program is needed for the runtime systems that foundation-model software agents require.
Where Pith is reading between the lines
- Standardized harness interfaces could allow direct comparison of different foundation models on the same engineering tasks.
- The ladder structure suggests incremental adoption paths where teams start with basic harnesses and add observability and verification layers over time.
- Episode packages might serve as training data for improving the harness itself or for fine-tuning agents on verifiable behavior.
Load-bearing premise
Specifying eleven responsibilities and a four-level ladder will systematically improve agent reliability and verifiability.
What would settle it
A side-by-side run of the same agent on the same validation task at H0 versus H3 that shows no increase in reproduction logs, failure attributions, or deterministic verification reports.
Figures


read the original abstract
Foundation models have transformed automated code generation, yet autonomous software-engineering agents remain unreliable in realistic development settings. The dominant explanation locates this gap in model capability. We propose a different locus: software-engineering capability emerges from a model-harness-environment system, in which a runtime substrate -- the harness -- mediates how a foundation-model agent observes a project, acts on it, receives feedback, and establishes that a change is complete. We formalize this substrate as an AI Harness Engineering and identify eleven component responsibilities: task specification, context selection, tool access, project memory, task state, observability, failure attribution, verification, permissions, entropy auditing, and intervention recording. We operationalize the harness through a four-level ladder (H0-H3) that progressively exposes runtime support to the agent, and we propose a trace-based evaluation protocol that converts each agent run into an auditable episode package. Applied to a controlled validation task, the framework yields episode packages whose evidence structure varies systematically with harness level: lower levels produce only a final patch, higher levels produce reproduction logs, failure attributions, deterministic requirement checks, and structured verification reports. The framework reframes the central question of autonomous software engineering from whether a foundation model can produce a patch to whether the model-harness-environment system can produce a verifiably correct, attributed, and maintainable change. We outline a research program for the runtime systems that foundation-model software agents will require.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that software-engineering capability in foundation-model agents emerges from the model-harness-environment system rather than model capability alone. It formalizes an AI Harness with eleven component responsibilities (task specification, context selection, tool access, project memory, task state, observability, failure attribution, verification, permissions, entropy auditing, and intervention recording) and operationalizes the harness via a four-level ladder (H0-H3) that progressively exposes runtime support. A trace-based evaluation protocol is introduced that converts each agent run into an auditable episode package. On a single controlled validation task, higher harness levels are shown to produce richer episode packages containing reproduction logs, failure attributions, deterministic checks, and structured verification reports. The work reframes the central question from whether a model can produce a patch to whether the full system can produce a verifiably correct, attributed, and maintainable change, and outlines a research program for required runtime systems.
Significance. If the harness framework can be shown to causally improve reliability and verifiability, the contribution would be significant by redirecting research attention from model scaling to runtime substrate design. The eleven responsibilities and H0-H3 ladder supply concrete, reusable abstractions, while the episode-package protocol offers a promising path toward auditable agent evaluations. The reframing itself is a useful conceptual advance even in the absence of new data.
major comments (2)
- [Validation task results] Validation task results: The manuscript reports that higher harness levels produce richer episode packages (reproduction logs, failure attributions, deterministic requirement checks) on one controlled task, but supplies no quantitative metrics comparing task success rates, patch acceptance, error attribution accuracy, or maintainability across H0-H3. This leaves the central claim that the harness is the load-bearing locus for capability emergence as a descriptive observation rather than a demonstrated causal improvement.
- [§3 (AI Harness Engineering)] §3 (AI Harness Engineering): The eleven component responsibilities are introduced by definition without derivation from existing agent architectures or empirical justification; their necessity and completeness for the emergence claim therefore remain ungrounded and load-bearing for the reframing argument.
minor comments (2)
- [Abstract] The abstract lists the eleven responsibilities but does not enumerate them; adding the explicit list would improve immediate readability.
- [Ladder definition] A summary table contrasting the responsibilities exposed at each harness level (H0-H3) is missing and would clarify the ladder progression.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that help sharpen the scope of our framework paper. We address each major point below, clarifying the conceptual nature of the contribution while agreeing to strengthen grounding and evaluation framing where appropriate.
read point-by-point responses
-
Referee: Validation task results: The manuscript reports that higher harness levels produce richer episode packages (reproduction logs, failure attributions, deterministic requirement checks) on one controlled task, but supplies no quantitative metrics comparing task success rates, patch acceptance, error attribution accuracy, or maintainability across H0-H3. This leaves the central claim that the harness is the load-bearing locus for capability emergence as a descriptive observation rather than a demonstrated causal improvement.
Authors: We agree that the single-task validation is illustrative and does not include quantitative metrics on success rates, patch acceptance, or similar measures across H0-H3. The manuscript positions the work as a reframing and framework definition rather than a causal empirical demonstration; the episode-package results show systematic differences in evidence structure to support the conceptual argument. We will revise the evaluation section to explicitly label the results as illustrative, add a limitations paragraph, and outline a planned quantitative research program using the protocol. This constitutes a partial revision focused on clarity rather than new experiments. revision: partial
-
Referee: §3 (AI Harness Engineering): The eleven component responsibilities are introduced by definition without derivation from existing agent architectures or empirical justification; their necessity and completeness for the emergence claim therefore remain ungrounded and load-bearing for the reframing argument.
Authors: The eleven responsibilities were synthesized by examining failure modes and runtime needs across existing foundation-model agent systems for software engineering. We will revise §3 to add a derivation subsection that explicitly maps each component to concrete examples from prior architectures (e.g., context selection and tool access in SWE-agent, verification and observability in Devin-style systems, and entropy auditing as a response to nondeterminism in recent agent papers). This will ground the list in the literature while preserving the consolidated abstraction. revision: yes
Circularity Check
No circularity: framework introduced definitionally with no equations or self-referential reductions
full rationale
The manuscript defines the AI Harness Engineering substrate, its eleven responsibilities, and the H0-H3 ladder by explicit enumeration and progressive exposure. No equations, fitted parameters, or predictive derivations exist that could reduce to their own inputs. The single controlled validation task produces descriptive differences in episode-package structure across levels, but supplies no success-rate metrics or causal claims that would require the framework to validate itself. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Software-engineering capability emerges from a model-harness-environment system rather than model capability alone.
invented entities (2)
-
AI Harness with eleven component responsibilities
no independent evidence
-
Four-level ladder (H0-H3)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 2020
2020
-
[3]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In International Conference on Learning Representations (ICLR), 2024
2024
-
[4]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent–computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[5]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Bowen Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, 15 Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An open platform for AI so...
2025
-
[6]
Agentless: Demystifying LLM-based Software Engineering Agents
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. Agentless: Demystifying LLM-based software engineering agents.arXiv preprint arXiv:2407.01489, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Autocoderover: Autonomous program improvement, 2024
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. AutoCodeRover: Au- tonomous program improvement.arXiv preprint arXiv:2404.05427, 2024
-
[8]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 2023
2023
-
[9]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, 2022
2022
-
[10]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[11]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. In COLM, 2024
2024
-
[12]
Introducing the Model Context Protocol
Anthropic. Introducing the Model Context Protocol. Anthropic blog, 2024
2024
-
[13]
Aios: Llm agent operating system.arXiv preprint arXiv:2403.16971, 2024
Kai Mei, Zelong Li, Shuyuan Xu, Ruosong Ye, Yingqiang Ge, and Yongfeng Zhang. AIOS: LLM agent operating system.arXiv preprint arXiv:2403.16971, 2024
-
[14]
Codex: Lessons from building agent-first software
OpenAI. Codex: Lessons from building agent-first software. OpenAI engineering report, 2026
2026
-
[15]
Building agent harnesses for developer tools
Microsoft. Building agent harnesses for developer tools. Microsoft engineering blog, 2026
2026
-
[16]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InInternational Conference on Learning Representatio...
2024
-
[17]
Addison-Wesley, 2010
Jez Humble and David Farley.Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Addison-Wesley, 2010
2010
-
[18]
IT Revolution Press, 2016
Gene Kim, Jez Humble, Patrick Debois, and John Willis.The DevOps Handbook. IT Revolution Press, 2016. 16
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.