Recognition: 2 theorem links
· Lean TheoremWhat Does LLM Refinement Actually Improve? A Systematic Study on Document-Level Literary Translation
Pith reviewed 2026-05-14 20:05 UTC · model grok-4.3
The pith
Document-level translation followed by segment-level refinement produces the most reliable gains in literary machine translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that, for literary translation, an initial document-level machine translation pass followed by segment-level refinement outperforms other granularity combinations and refinement strategies. Document-level refinement produces fewer edits and less reliable quality lifts. Across experiments, refinement improves fluency, style, and terminology more than adequacy, and the process projects the output toward the refiner model's distribution instead of performing targeted error correction. A simple general refinement prompt consistently beats error-specific prompting and evaluate-then-refine schemes.
What carries the argument
The document-level MT followed by segment-level refinement pipeline, which carries the argument by separating coarse context handling from fine-grained polishing.
If this is right
- Refinement gains concentrate on fluency, style, and terminology rather than adequacy.
- A single general refinement prompt outperforms error-specific and evaluate-then-refine variants.
- The output after refinement moves closer to the refiner model's own distribution.
- Document-level initial translation plus segment refinement remains stable across model strengths and language pairs.
Where Pith is reading between the lines
- Translation systems may benefit from deliberately separating document-scale context capture from segment-scale polishing in their inference pipelines.
- The style-projection finding suggests current refinement has limited power for meaning-level error repair and may need external signals to target adequacy.
- The recipe could be tested on other text domains such as technical or conversational material to check whether the granularity preference persists.
Load-bearing premise
The observed superiority of the hybrid granularity recipe and the quality dimension patterns will hold for LLMs, language pairs, and text genres outside the nine models, seven pairs, and literary texts tested.
What would settle it
A controlled replication using new LLMs or non-literary documents in which full document-level refinement produces larger and more stable gains than the document-then-segment pipeline would falsify the central recommendation.
Figures


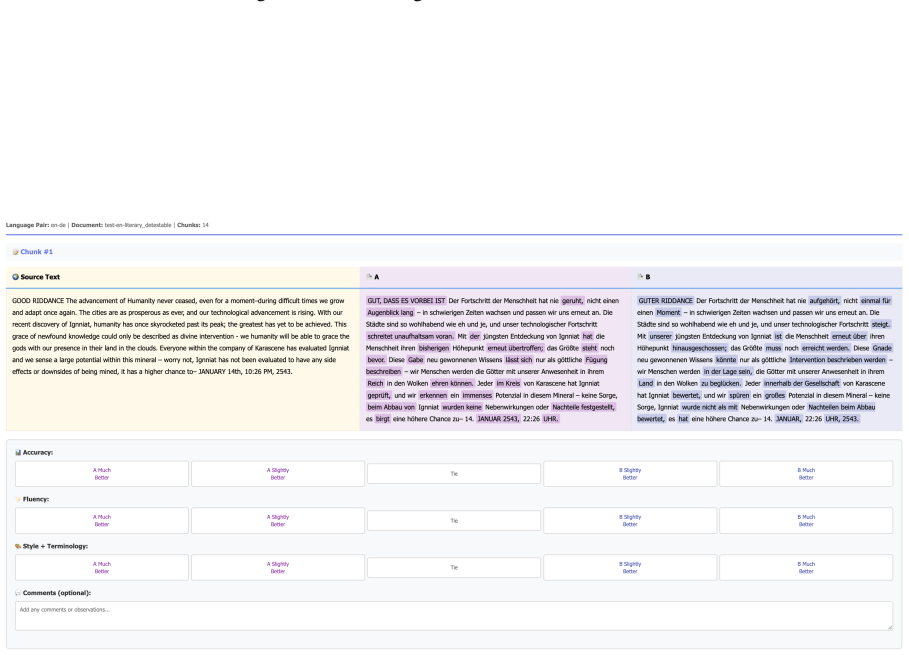

read the original abstract
Iterative self-refinement is a simple inference-time strategy for machine translation: an LLM revises its own translation over multiple inference-time passes. Yet document-scale refinement remains poorly understood: 1) which pipelines work best, 2) what quality dimensions improve, and 3) how refiners behave. In this paper, we present a systematic study of document-level literary translation, covering nine LLMs and seven language pairs. Across nine translation-refinement granularity combinations and five refinement strategies, we find a robust recipe: document-level MT followed by segment-level refinement yields strong and stable improvements. In contrast, document-level refinement often makes fewer edits and leads to smaller or less reliable gains. Beyond granularity, A simple general refinement prompt consistently outperforms error-specific prompting and evaluate-then-refine schemes. Our large-scale human evaluation shows that refinement gains come primarily from fluency, style, and terminology, with limited and less consistent improvements in adequacy. Experiments varying model strength reveal refinement projects outputs toward the refiner's distribution rather than performing targeted error repair. These findings clarify the mechanisms and limitations of current refinement approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic empirical study of iterative self-refinement for document-level literary machine translation with LLMs. It evaluates nine LLMs across seven language pairs using nine granularity combinations and five refinement strategies, supported by large-scale human evaluation. The central claim is that document-level MT followed by segment-level refinement produces strong, stable gains (mainly in fluency, style, and terminology), while document-level refinement yields fewer edits and less reliable improvements; a simple general prompt outperforms error-specific or evaluate-then-refine variants, and refinement aligns outputs to the refiner's distribution rather than targeted error correction.
Significance. If the findings hold, the work offers clear practical guidance for LLM refinement pipelines in literary translation and illuminates the mechanisms and limits of current approaches. The broad coverage of models, languages, and strategies, together with consistent patterns from human judgments, provides a solid empirical foundation that can inform both research and deployment of inference-time MT improvements.
minor comments (2)
- [Abstract] Abstract: The abstract states that large-scale human evaluation was performed but does not mention statistical significance tests or inter-annotator agreement; adding one sentence on these points would strengthen the summary of the results.
- [§5] §5 (or equivalent results section): When reporting the nine granularity combinations, a compact summary table or clearer visual encoding of the exact MT/refinement granularity pairs would make the cross-condition comparisons easier to parse at a glance.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation for minor revision. We appreciate the recognition that our systematic study provides clear practical guidance for LLM refinement pipelines in literary translation, supported by broad coverage across models, languages, and human judgments.
read point-by-point responses
-
Referee: The manuscript presents a systematic empirical study of iterative self-refinement for document-level literary machine translation with LLMs. It evaluates nine LLMs across seven language pairs using nine granularity combinations and five refinement strategies, supported by large-scale human evaluation. The central claim is that document-level MT followed by segment-level refinement produces strong, stable gains (mainly in fluency, style, and terminology), while document-level refinement yields fewer edits and less reliable improvements; a simple general prompt outperforms error-specific or evaluate-then-refine variants, and refinement aligns outputs to the refiner's distribution rather than targeted error correction.
Authors: We thank the referee for this accurate summary of our work. The description aligns closely with our abstract, experimental design, and conclusions. No revisions are required on this point. revision: no
Circularity Check
No significant circularity
full rationale
This is a purely empirical study that reports results from systematic experiments across nine LLMs, seven language pairs, multiple granularity combinations, refinement strategies, and large-scale human evaluations. The central claims rest on direct comparisons of observed outcomes (e.g., document-level MT + segment-level refinement vs. document-level refinement) without any mathematical derivations, equations, parameter fitting, or self-referential definitions. No load-bearing step reduces to its own inputs by construction, and the findings are externally falsifiable via the reported experimental setup.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human judgments reliably measure improvements in translation quality dimensions such as fluency, style, terminology, and adequacy.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across nine translation-refinement granularity combinations and five refinement strategies, we find a robust recipe: document-level MT followed by segment-level refinement yields strong and stable improvements.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
refinement gains come primarily from fluency, style, and terminology, with limited and less consistent improvements in adequacy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Ademuyiwa, Andrew Caines, and Dietrich Klakow
Jesujoba Oluwadara Alabi, Israel Abebe Azime, Miaoran Zhang, Cristina Espa \ n a-Bonet, Rachel Bawden, Dawei Zhu, David Ifeoluwa Adelani, Clement Oyeleke Odoje, Idris Akinade, Iffat Maab, Davis David, Shamsuddeen Hassan Muhammad, Neo Putini, David O. Ademuyiwa, Andrew Caines, and Dietrich Klakow. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1413 AFRI...
- [2]
-
[3]
Eleftheria Briakou, Jiaming Luo, Colin Cherry, and Markus Freitag. 2024. Translating step-by-step: Decomposing the translation process for improved translation quality of long-form texts. In Proceedings of the Ninth Conference on Machine Translation, pages 1301--1317
work page 2024
-
[4]
Pinzhen Chen, Zhicheng Guo, Barry Haddow, and Kenneth Heafield. 2024. Iterative translation refinement with large language models. In Proceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1), pages 181--190
work page 2024
-
[5]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025 a . https://arxiv.org/abs/2501.12948 Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 181 others. 2025 b . https://arxiv.org/abs/2412.19437 Deepseek-v3 technical report . Preprint, arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
Bryan Eikema and Wilker Aziz. 2022. Sampling-based approximations to minimum bayes risk decoding for neural machine translation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10978--10993
work page 2022
-
[9]
Markus Freitag, George Foster, David Grangier, Viresh Ratnakar, Qijun Tan, and Wolfgang Macherey. 2021. Experts, errors, and context: A large-scale study of human evaluation for machine translation. Transactions of the Association for Computational Linguistics, 9:1460--1474
work page 2021
-
[10]
and Rei, Ricardo and Stigt, Daan van and Coheur, Luisa and Colombo, Pierre and Martins, Andr \'e F
Nuno M. Guerreiro, Ricardo Rei, Daan van Stigt, Luisa Coheur, Pierre Colombo, and Andr \'e F. T. Martins. 2024. https://doi.org/10.1162/tacl_a_00683 x COMET : Transparent machine translation evaluation through fine-grained error detection . Transactions of the Association for Computational Linguistics, 12:979--995
-
[11]
Zhiwei He, Tian Liang, Wenxiang Jiao, Zhuosheng Zhang, Yujiu Yang, Rui Wang, Zhaopeng Tu, Shuming Shi, and Xing Wang. 2024. Exploring human-like translation strategy with large language models. Transactions of the Association for Computational Linguistics, 12:229--246
work page 2024
-
[12]
Hanxu Hu, Jannis Vamvas, and Rico Sennrich. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.1289 Source-primed multi-turn conversation helps large language models translate documents . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 23702--23712, Suzhou, China. Association for Computational Linguistics
-
[13]
Marcin Junczys-Dowmunt. 2025. https://doi.org/10.18653/v1/2025.wmt-1.67 GEMBA v2: Ten judgments are better than one . In Proceedings of the Tenth Conference on Machine Translation, pages 926--933, Suzhou, China. Association for Computational Linguistics
-
[14]
Ahrii Kim. 2025. https://aclanthology.org/2025.wmt-1.5 Context is ubiquitous, but rarely changes judgments: Revisiting document-level mt evaluation . In Proceedings of the Tenth Conference on Machine Translation (WMT 2025), pages 81--97, Suzhou, China. Association for Computational Linguistics
work page 2025
-
[15]
Tom Kocmi, Ekaterina Artemova, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Konstantin Dranch, Anton Dvorkovich, Sergey Dukanov, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Marzena Karpinska, Philipp Koehn, Howard Lakougna, Jessica Lundin, Christof Monz, Kenton Murray, and 10 others. 2025. https://doi.org/10.18653...
-
[16]
Tom Kocmi, Eleftherios Avramidis, Rachel Bawden, Ond r ej Bojar, Anton Dvorkovich, Christian Federmann, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, and 1 others. 2024. Findings of the wmt24 general machine translation shared task: The llm era is here but mt is not solved yet. In Proceedings of the Ninth Conference on Machine Translation...
work page 2024
-
[17]
Tom Kocmi and Christian Federmann. 2023. Gemba-mqm: Detecting translation quality error spans with gpt-4. In Proceedings of the Eighth Conference on Machine Translation, pages 768--775
work page 2023
-
[18]
Ann Lee, Michael Auli, and Marc’Aurelio Ranzato. 2021. Discriminative reranking for neural machine translation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7250--7264
work page 2021
-
[19]
Monishwaran Maheswaran, Marco Carini, Christian Federmann, and Tony Diaz. 2025. https://doi.org/10.18653/v1/2025.wmt-1.76 TASER : Translation assessment via systematic evaluation and reasoning . In Proceedings of the Tenth Conference on Machine Translation, pages 1004--1010, Suzhou, China. Association for Computational Linguistics
-
[20]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candes, and Tatsunori Hashimoto. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1025 s1: Simple test-time scaling . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286--2...
-
[21]
Dayy \'a n O ' Brien, Bhavitvya Malik, Ona de Gibert, Pinzhen Chen, Barry Haddow, and J \"o rg Tiedemann. 2025. https://doi.org/10.18653/v1/2025.wmt-1.17 D oc HPLT : A massively multilingual document-level translation dataset . In Proceedings of the Tenth Conference on Machine Translation, pages 286--300, Suzhou, China. Association for Computational Linguistics
-
[22]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, and 108 others. 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Ziqian Peng, Rachel Bawden, and Fran c ois Yvon. 2025. https://aclanthology.org/2025.mtsummit-1.3/ Investigating length issues in document-level machine translation . In Proceedings of Machine Translation Summit XX: Volume 1, pages 4--23, Geneva, Switzerland. European Association for Machine Translation
work page 2025
-
[24]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, and 25 others. 2025. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . Preprint, arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Miguel Moura Ramos, Patrick Fernandes, Sweta Agrawal, and Andre Martins. 2025. https://openreview.net/forum?id=Ah0U1r5Ldq Multilingual contextualization of large language models for document-level machine translation . In Second Conference on Language Modeling
work page 2025
-
[26]
Ricardo Rei, Jos \'e G. C. de Souza, Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and Andr \'e F. T. Martins. 2022. https://aclanthology.org/2022.wmt-1.52/ COMET -22: Unbabel- IST 2022 submission for the metrics shared task . In Proceedings of the Seventh Conference on Machine Translation (WMT), pages 578--585...
work page 2022
-
[27]
Kirill Semenov, Xu Huang, Vil \'e m Zouhar, Nathaniel Berger, Dawei Zhu, Arturo Oncevay, and Pinzhen Chen. 2025. https://doi.org/10.18653/v1/2025.wmt-1.30 Findings of the WMT 25 terminology translation task: Terminology is useful especially for good MT s . In Proceedings of the Tenth Conference on Machine Translation, pages 554--576, Suzhou, China. Associ...
-
[28]
Yirong Sun, Dawei Zhu, Yanjun Chen, Erjia Xiao, Xinghao Chen, and Xiaoyu Shen. 2025. https://doi.org/10.18653/v1/2025.naacl-srw.1 Fine-grained and multi-dimensional metrics for document-level machine translation . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language T...
- [29]
- [30]
-
[31]
Shaomu Tan and Christof Monz. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.217 R e M edy: Learning machine translation evaluation from human preferences with reward modeling . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4370--4387, Suzhou, China. Association for Computational Linguistics
-
[32]
Longyue Wang, Chenyang Lyu, Tianbo Ji, Zhirui Zhang, Dian Yu, Shuming Shi, and Zhaopeng Tu. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.1036 Document-level machine translation with large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 16646--16661, Singapore. Association for Computat...
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
work page 2022
- [34]
- [35]
-
[36]
Wenda Xu, Daniel Deutsch, Mara Finkelstein, Juraj Juraska, Biao Zhang, Zhongtao Liu, William Yang Wang, Lei Li, and Markus Freitag. 2024. Llmrefine: Pinpointing and refining large language models via fine-grained actionable feedback. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 1429--1445
work page 2024
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [38]
-
[39]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. https://doi.org/10.52202/079017-2000 Sglang: Efficient execution of structured language model programs . In Advances in Neural Information Processing Systems, volume 37, pages...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.