Recognition: unknown
Backbone is All You Need: Assessing Vulnerabilities of Frozen Foundation Models in Synthetic Image Forensics
Pith reviewed 2026-05-14 19:08 UTC · model grok-4.3
The pith
Knowledge of only the Vision Transformer backbone in frozen deepfake detectors enables gray-box adversarial attacks that reach near white-box success rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
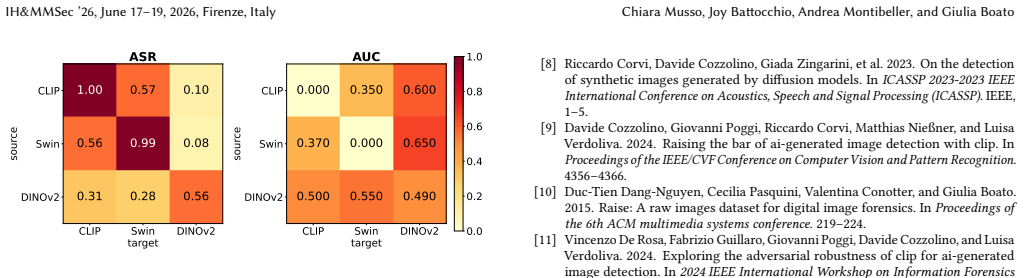
The central claim is that backbone knowledge alone is sufficient to undermine detector reliability. The authors show that a gray-box Surrogate Iterative Adversarial Attack (SIAA) operating entirely within the target detector's feature space produces highly effective adversarial examples, often approaching white-box performance across multiple ViT-based detectors and diverse scenarios such as few-shot learning, complete training misalignment, and attack transferability tests.
What carries the argument
The Surrogate Iterative Adversarial Attack (SIAA), a gray-box method that uses only the frozen ViT backbone to craft adversarial perturbations inside the target detector's feature space.
If this is right
- Detectors that freeze pre-trained backbones remain vulnerable even under partial-knowledge attacks.
- Attack success rates remain high across few-shot learning and training misalignment conditions.
- Adversarial examples crafted from backbone knowledge transfer effectively between different ViT detectors.
- Current synthetic image forensics pipelines require more resilient defense strategies beyond frozen foundation models.
Where Pith is reading between the lines
- Detectors may need to avoid freezing any foundation-model component or must incorporate explicit feature-space randomization during training.
- The result raises the question of whether similar backbone-only vulnerabilities exist in other vision tasks that rely on frozen transformers.
- Practical forensic systems could test resilience by simulating backbone-only gray-box attacks during model development.
Load-bearing premise
An attacker who knows only the backbone can reliably access and manipulate the target detector's internal feature space to generate effective adversarial examples.
What would settle it
A new ViT-based detector in which an attacker limited to backbone knowledge alone consistently fails to produce high success rates on adversarial examples would falsify the claim.
Figures


read the original abstract
As AI-generated synthetic images become increasingly realistic, Vision Transformers (ViTs) have emerged as a cornerstone of modern deepfake detection. However, the prevailing reliance on frozen, pre-trained backbones introduces a subtle yet critical vulnerability. In this work, we present the Surrogate Iterative Adversarial Attack (SIAA), a gray-box attack that exploits knowledge of the detector's ViT backbone alone and operates entirely within the target detector's feature space to craft highly effective adversarial examples. Through our experiments, involving multiple ViT-based detectors and diverse gray-box scenarios, including few-shot learning, complete training misalignment and attack transferability tests, we demonstrate that this vulnerability consistently yields high attack success rates, often approaching white-box performance. By doing so, we reveal that backbone knowledge alone is sufficient to undermine detector reliability, highlighting the urgent need for more resilient defenses in adversarial multimedia forensics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Surrogate Iterative Adversarial Attack (SIAA), a gray-box method that uses only the frozen ViT backbone weights of synthetic-image detectors to craft adversarial examples directly in the target's feature space. Through experiments on multiple ViT-based detectors, it reports high attack success rates (often near white-box levels) across few-shot learning, training misalignment, and transferability scenarios, concluding that backbone knowledge alone suffices to undermine detector reliability.
Significance. If the central claim holds under the stated gray-box assumptions, the work is significant for adversarial multimedia forensics. It provides empirical evidence that frozen foundation-model backbones create a transferable vulnerability exploitable without access to the detector head or training data, motivating the development of defenses that avoid exposing aligned feature spaces or incorporate non-frozen components.
major comments (2)
- [Experimental Setup] Experimental scenarios (few-shot, misalignment, transferability): no ablations or controls are described that test sensitivity to mismatches between surrogate and target backbone, such as differences in patch embedding, positional encoding, or input normalization. Without these, the reported near-white-box ASR cannot be attributed solely to backbone knowledge and may require stronger alignment than claimed.
- [Method] SIAA method description: the iterative optimization is stated to operate entirely in the target's feature space using only backbone weights, yet the manuscript provides no verification that the surrogate exactly replicates the target's preprocessing pipeline. Any deviation would break feature-space alignment and collapse transfer success, making this assumption load-bearing for the 'backbone is all you need' conclusion.
minor comments (2)
- [Abstract] Abstract: quantitative ASR values, standard deviations, or number of trials are not reported, making it difficult to assess the consistency of the 'often approaching white-box' claim.
- [Notation and Terminology] Notation: ensure consistent use of 'backbone' versus 'feature extractor' throughout, and define any surrogate-specific hyperparameters in a dedicated table.
Simulated Author's Rebuttal
Thank you for the detailed review. We address the major comments below and will revise the manuscript accordingly to enhance the clarity and rigor of our experimental validation.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental scenarios (few-shot, misalignment, transferability): no ablations or controls are described that test sensitivity to mismatches between surrogate and target backbone, such as differences in patch embedding, positional encoding, or input normalization. Without these, the reported near-white-box ASR cannot be attributed solely to backbone knowledge and may require stronger alignment than claimed.
Authors: We thank the referee for highlighting this important aspect. While our transferability experiments across different ViT-based detectors implicitly test variations in backbone components, we agree that explicit ablations are valuable. In the revised manuscript, we will add ablations that introduce controlled mismatches in patch embedding, positional encoding, and input normalization between surrogate and target. These will show that SIAA remains effective even under such mismatches, further supporting that backbone knowledge is the key factor. revision: yes
-
Referee: [Method] SIAA method description: the iterative optimization is stated to operate entirely in the target's feature space using only backbone weights, yet the manuscript provides no verification that the surrogate exactly replicates the target's preprocessing pipeline. Any deviation would break feature-space alignment and collapse transfer success, making this assumption load-bearing for the 'backbone is all you need' conclusion.
Authors: We appreciate this observation. The SIAA is designed to operate in the feature space using the backbone weights, assuming standard preprocessing as per the detector implementations. To address this, we will include in the revision a detailed verification section, including a comparison table of preprocessing steps and confirmation that the surrogate matches the target's pipeline exactly, as used in our experiments. revision: yes
Circularity Check
No circularity: empirical attack evaluation is self-contained
full rationale
The paper presents SIAA as a gray-box adversarial attack method and validates its effectiveness through direct experiments on multiple ViT-based detectors across few-shot, misalignment, and transfer scenarios. No load-bearing equations, fitted parameters renamed as predictions, self-definitional steps, or self-citation chains appear in the abstract or described methodology; the central claim rests on reported attack success rates rather than any reduction to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adobe. 2023. Adobe Firefly: Generative AI for Content Creation. https://www. adobe.com/sensei/generative-ai/firefly.html. Accessed: 2026-02-09
2023
-
[2]
Irene Amerini, Mauro Barni, Sebastiano Battiato, et al. 2025. Deepfake media forensics: Status and future challenges.Journal of Imaging11, 3 (2025), 73
2025
- [3]
-
[4]
Sebastiano Battiato, Mirko Casu, Francesco Guarnera, et al. 2025. Adversarial Attacks on Deepfake Detectors: A Challenge in the Era of AI-Generated Me- dia (AADD-2025). InProceedings of the 33rd ACM International Conference on Multimedia. 13714–13719
2025
-
[5]
Joy Battocchio, Stefano Dell’Anna, Andrea Montibeller, and Giulia Boato. 2025. Advance Fake Video Detection via Vision Transformers. InProceedings of the 2025 ACM Workshop on Information Hiding and Multimedia Security
2025
-
[6]
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Jian, Chelsea Voss, Alec Radford, Aditya Chen, and Mark Ramesh. 2023. Improving Image Generation with Better Captions.Computer Science. https://cdn.openai.com/papers/dall-e-3.pdf (2023)
2023
- [7]
-
[8]
Riccardo Corvi, Davide Cozzolino, Giada Zingarini, et al. 2023. On the detection of synthetic images generated by diffusion models. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5
2023
-
[9]
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nießner, and Luisa Verdoliva. 2024. Raising the bar of ai-generated image detection with clip. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4356–4366
2024
-
[10]
Duc-Tien Dang-Nguyen, Cecilia Pasquini, Valentina Conotter, and Giulia Boato
-
[11]
InProceedings of the 6th ACM multimedia systems conference
Raise: A raw images dataset for digital image forensics. InProceedings of the 6th ACM multimedia systems conference. 219–224
-
[12]
Vincenzo De Rosa, Fabrizio Guillaro, Giovanni Poggi, Davide Cozzolino, and Luisa Verdoliva. 2024. Exploring the adversarial robustness of clip for ai-generated image detection. In2024 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 1–6
2024
-
[13]
Stefano Dell’Anna, Andrea Montibeller, and Giulia Boato. 2025. TrueFake: A Real World Case Dataset of Last Generation Fake Images also Shared on Social Networks. In2025 International Joint Conference on Neural Networks (IJCNN). 1–8. doi:10.1109/IJCNN64981.2025.11228911
-
[14]
Nicolas Göller, Lukas Graner, Raphael Antonius Frick, and Niklas Bunzel. 2025. Team RoMa@ AADD-2025: On the Generation of Transferable and Visually Imperceptible Adversarial Attacks Against Deepfake Detectors. InProceedings of the 33rd ACM International Conference on Multimedia
2025
-
[15]
Francesco Guarnera, Luca Guarnera, Alessandro Ortis, Sebastiano Battiato, and Giovanni Puglisi. 2025. A Novel Adversarial Gray-Box Attack on DCT-Based Face Deepfake Detectors.IEEE Access(2025)
2025
-
[16]
Federica Lago, Cecilia Pasquini, Rainer Böhme, et al. 2021. More real than real: A study on human visual perception of synthetic faces [applications corner].IEEE Signal Processing Magazine39, 1 (2021), 109–116
2021
-
[17]
Francesco Laiti, Benedetta Liberatori, Thomas De Min, and Elisa Ricci. 2025. Conditioned Prompt-Optimization for Continual Deepfake Detection. InPattern Recognition. Springer Nature Switzerland, Cham, 64–79
2025
-
[18]
Binh M Le, Jiwon Kim, Simon S Woo, et al . 2025. Sok: Systematization and benchmarking of deepfake detectors in a unified framework. In2025 IEEE 10th European Symposium on Security and Privacy (EuroS&P). IEEE, 883–902
2025
-
[19]
Tsung-Yi Lin, Michael Maire, Serge Belongie, et al. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
2014
-
[20]
Ze Liu, Yutong Lin, Yue Cao, et al. 2021. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision. 10012–10022
2021
-
[21]
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, et al. 2018. Towards Deep Learning Models Resistant to Adversarial Attacks. InInternational Confer- ence on Learning Representations. https://openreview.net/forum?id=rJzIBfZAb
2018
-
[22]
Sara Mandelli, Paolo Bestagini, and Stefano Tubaro. 2024. When synthetic traces hide real content: Analysis of stable diffusion image laundering. In2024 IEEE International Workshop on Information Forensics and Security (WIFS). IEEE, 1–6
2024
-
[23]
Midjourney. 2023. Midjourney V5 Release. https://www.midjourney.com/. Ac- cessed: 2026-02-09
2023
-
[24]
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, et al. 2022. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. InProceedings of the 39th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 162), Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Ga...
2022
-
[25]
Maxime Oquab, Timothée Darcet, Huy Vo, et al. 2024. DINOv2: Learning Robust Visual Features without Supervision.Transactions on Machine Learning Research Journal(2024). doi:10.48550/arxiv.2304.07193
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2304.07193 2024
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[27]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen
-
[28]
Hierarchical Text-Conditional Image Generation with CLIP Latents.arXiv preprint arXiv:2204.06125(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, et al . 2022. High- Resolution Image Synthesis with Latent Diffusion Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10684–10695
2022
-
[30]
Zeyang Sha, Zheng Li, Ning Yu, and Yang Zhang. 2023. De-fake: Detection and attribution of fake images generated by text-to-image generation models. In Proceedings of the 2023 ACM SIGSAC conference on computer and communications security. 3418–3432
2023
-
[31]
Jiaming Zhang, Lingyu Qiu, Qi Yi, Yige Li, Jitao Sang, Changsheng Xu, Dit-Y Yeung, et al. 2025. MF-CLIP: Leveraging CLIP as Surrogate Models for No-Box Adversarial Attacks.IEEE Transactions on Information Forensics and Security20 (2025), 9195–9206. doi:10.1109/TIFS.2025.3599257
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.